⬇️ Main Note
https://docs.google.com/document/d/15YmPjPJjduQp0oSms3yc2mGAMXHc16IDyyxFp7jnL0E/edit
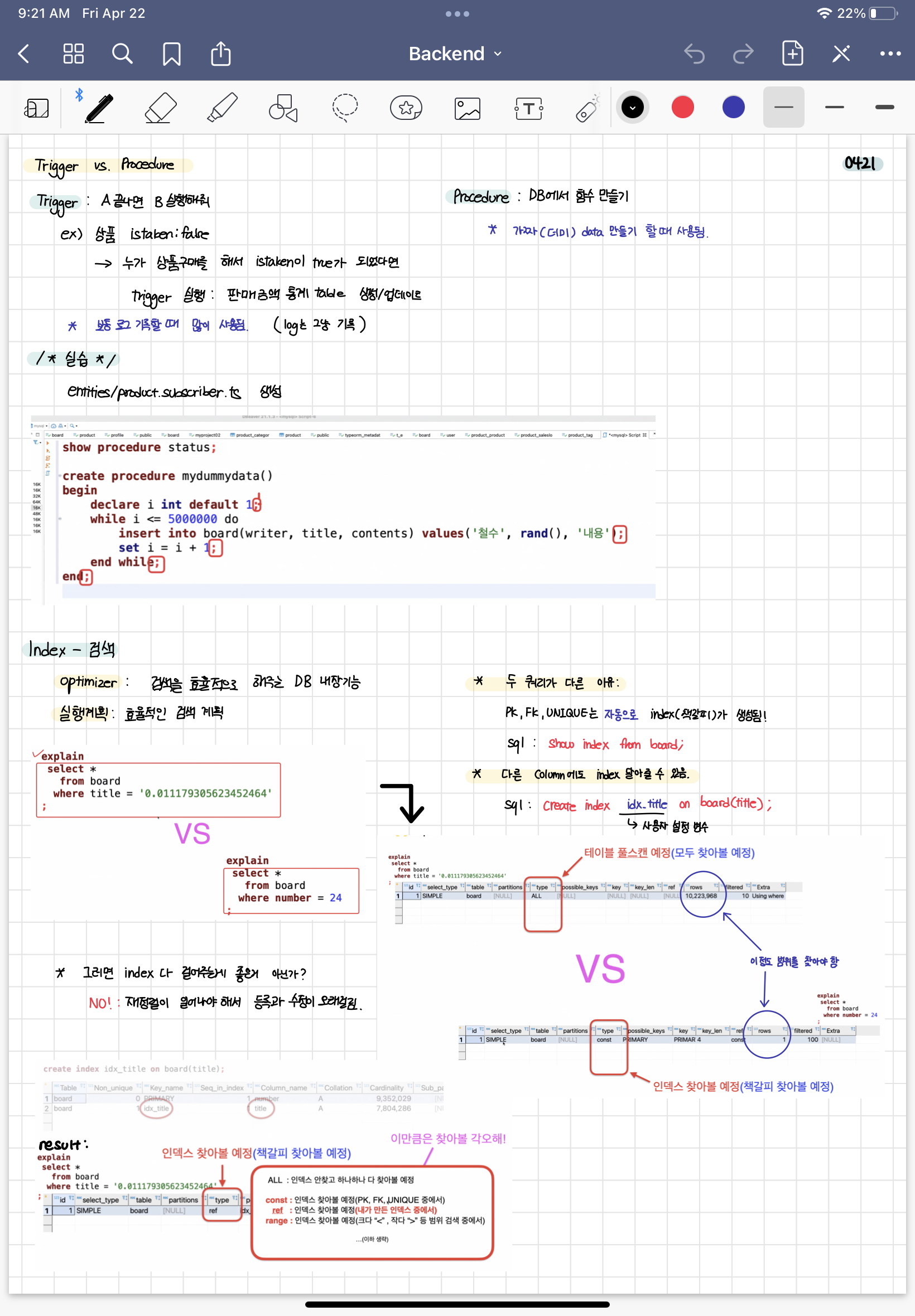
🐚 Trigger / Procedure
Trigger: After A, execute B
Procedure: Making a function inside database
Trigger Practice
file location: backend/apis/products/entity/product.subscriber.ts
import {
Connection,
EntitySubscriberInterface,
EventSubscriber,
InsertEvent,
} from 'typeorm';
import { Product } from './product.entity';
import { BigQuery } from '@google-cloud/bigquery';
@EventSubscriber()
export class ProductSubscriber implements EntitySubscriberInterface<Product> {
constructor(connection: Connection) {
connection.subscribers.push(this);
}
// <Product> table에 입력할거야 라고 알려주는것
listenTo() {
return Product;
}
afterInsert(event: InsertEvent<Product>) {
console.log(event); // 방금 전에 한줄 insert 한게 event로 출력 됨
const bigQuery = new BigQuery({
keyFilename: process.env.CLASS_KEY_FILE_NAME,
projectId: 'wise-invention-347011',
});
bigQuery
.dataset('mybigquery02')
.table('productlog')
.insert([
{
id: event.entity.id,
name: event.entity.name,
description: event.entity.description,
price: event.entity.price,
isSoldout: event.entity.isSoldout,
},
]);
}
}In nest.js, trigger file is called subscriber.
The data that's randomly made is stored in big query.
--> data that comes out from an event.
Trigger shouldn't be used for important data.
--> If one purchased something and increases the amount of money, we can use trigger for userTable. However for working as a group for a project, using trigger for these things could be dangerous since others could forget about the trigger.
--> Some might just forget about distributing the table data without thinking of trigger table.
🐚 Index
책갈피 기능
select COUNT * from board
Optimizer: Inner function in database that makes searching efficient.
Execute Plan(실행계획): efficient searching method planning (planning great algorithm)
Explain (# command) : Show the execution plan that the optimizer made.
// ========== DBeaver sql ==========
show procedure status;
create procedure mydummydata()
begin
declare i int default 1;
while i <= 5000000 do
insert into board(writer, title, contents) values('철수', rand(), '내용');
set i = i + 1;
end while;
end;
show procedure status;
call mydummydata();
select count(*) from board;
select *
from board
where title = '0.2806090063234875'
;
select *
from board
where number = 6
;
explain
select *
from board
where title = '0.2806090063234875'
;
explain
select *
from board
where number = 6
;
show index from board;
create index idx_title on board(title);
show index from board;
explain
select *
from board
where title = '0.2806090063234875'
;
select *
from board
where title = '0.2806090063234875'
;🐚 Redis
➤ Memory based database
For fast searching of data, we're cashing the data.
Caching : temporarily saving the data.
➤ TTL(time to live) ex_ for 10 seconds, temporarily saved(cached) and disappears.
Cache-Aside Pattern vs. Write-Back Pattern
Cache-Aside Pattern: Faster Searching
Write-Back Patter: Temporarily savind / faster than MySQL --> saving into Redis
➤ Cache-Aside literally just searches from Redis while Write-Back Pattern temporarily saves to Redis.
Redis Practice
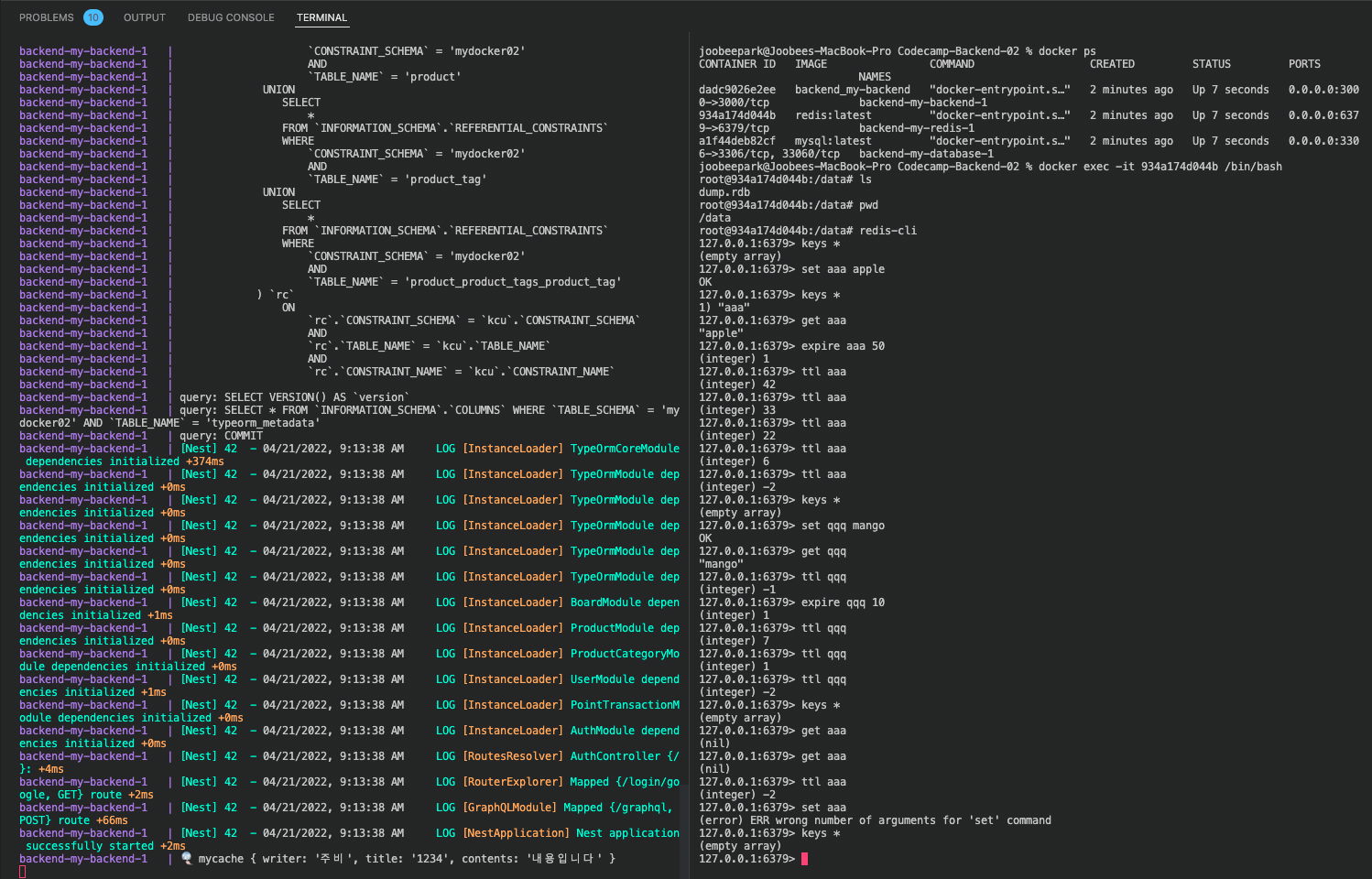
--> Right side is Redis
📄 Good Note