⬇️ Main Note
https://docs.google.com/document/d/17KKtCXe_nuQsuk9E_6050v01H_IAHBfYQtG11G06jas/edit
⚠️ Warning ⚠️ Today's post contains a lot of images
🌿 Inverted Text
(역색인)
"Hello this is Monstershop. We are the best shop"
➤ Every single words are tokenized, and they are now tokens.
By tokenizing, elasticsearch can quickly search the words from the context.
➤ Faster than mysql (mysql searches in this format : "title":%Hello%)
➤ Full-text search (efficient for searching a sentence)
➤ "Hello" is saved as a token, so only need to get that "Hello" token.
🌿 Analyzer
➤ Analyzes how the searching works
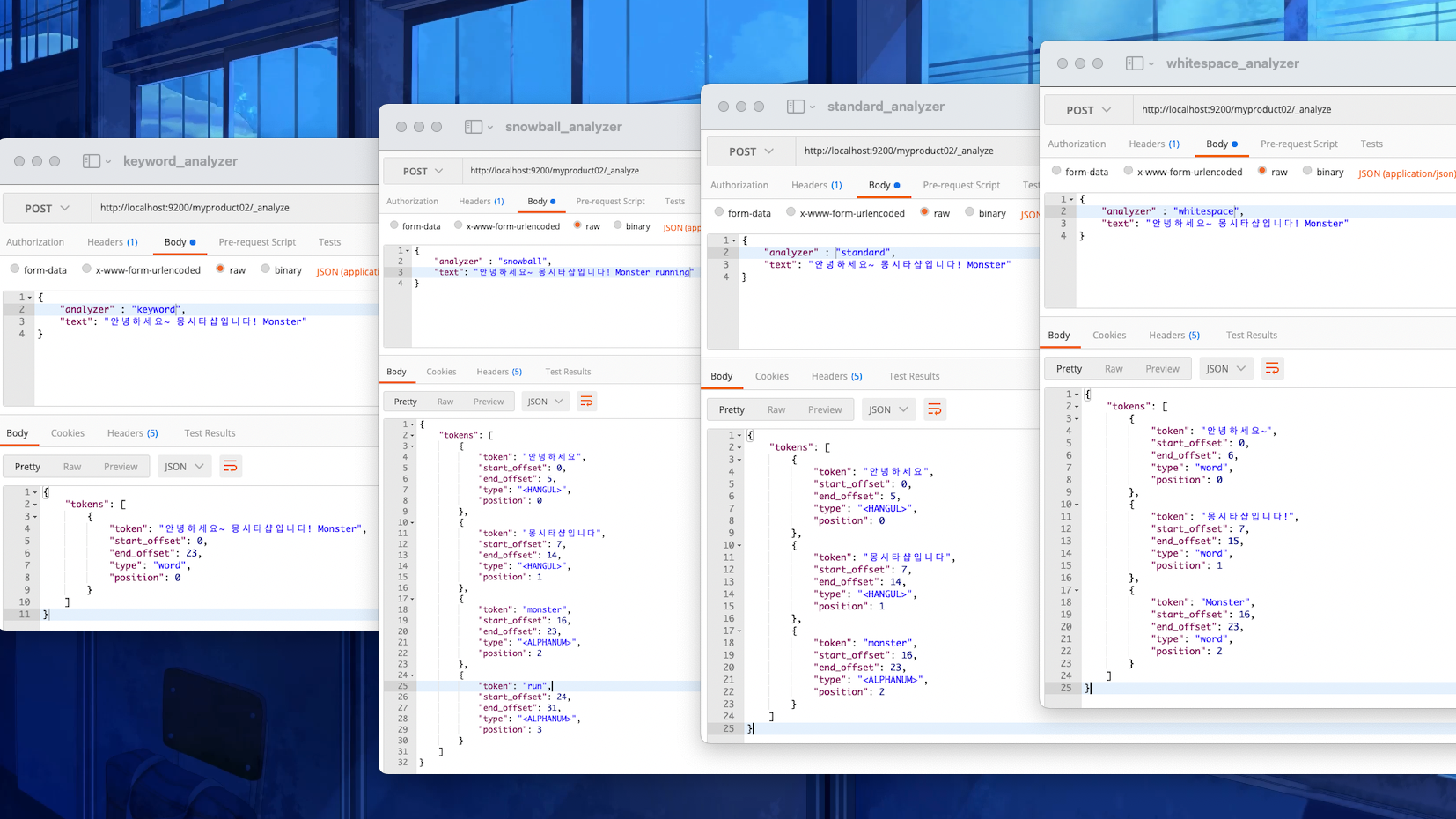
Default Anlayzers
< Character-Filter > ➤ removes things like ["!","~","@", "#"]
< Tokenizer > ➤ splits by spaces
< Token-Filter > ➤ Uppercase to lowercase
🌿 Elasticsearch Settings vs. Mappings
Settings:Analyzer, Tokenizer, Token-filter settings
Mappings: Set which analyzer the devloper wants to use for analyzing column
- For mappings, once the change is set, developer cannot commit any changes.
- But developer can add mappings.
🌿 Query [match / prefix]
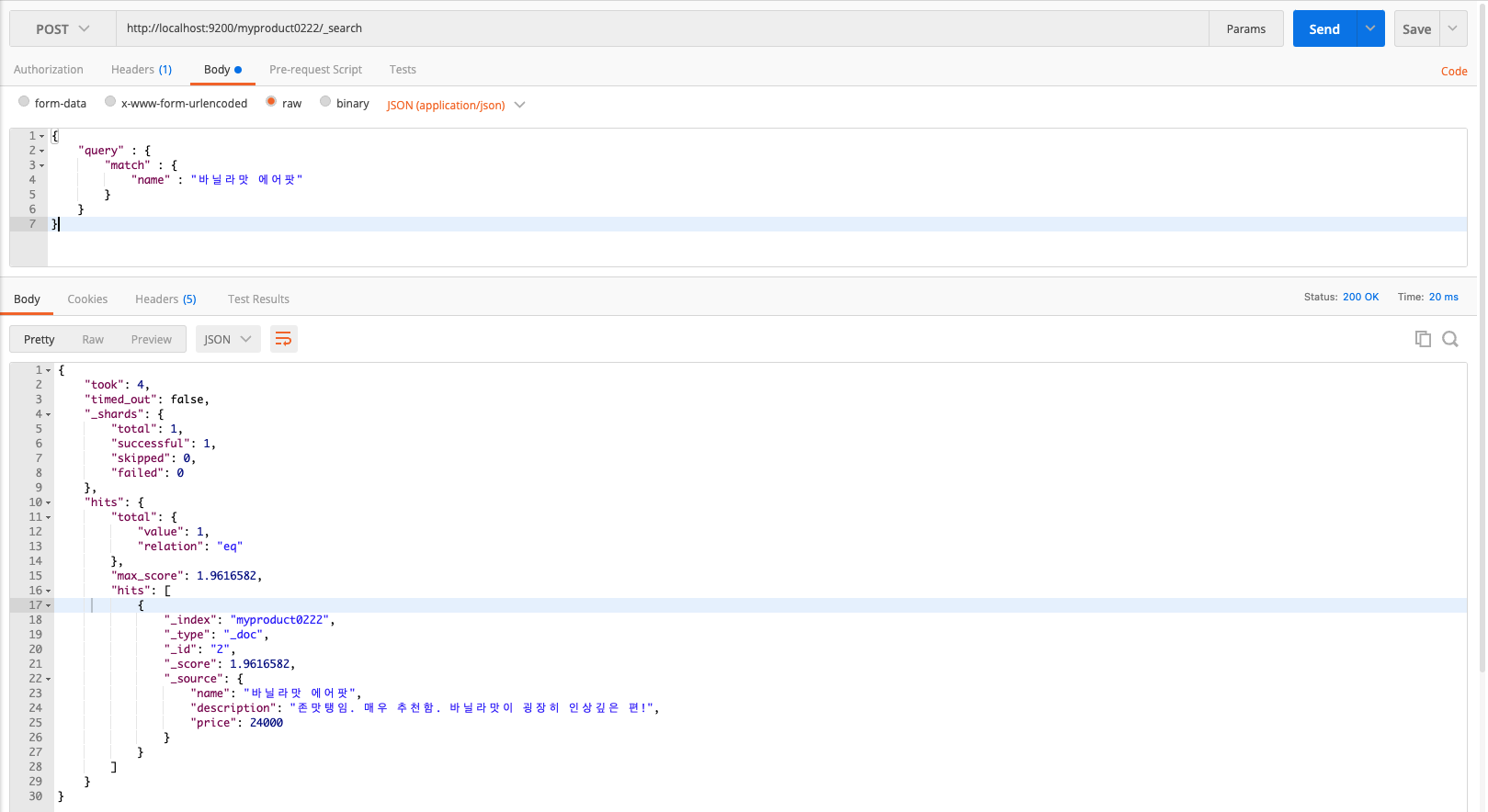
⬇️ Match: Get the result that literally matches the user input(search word the use types in).
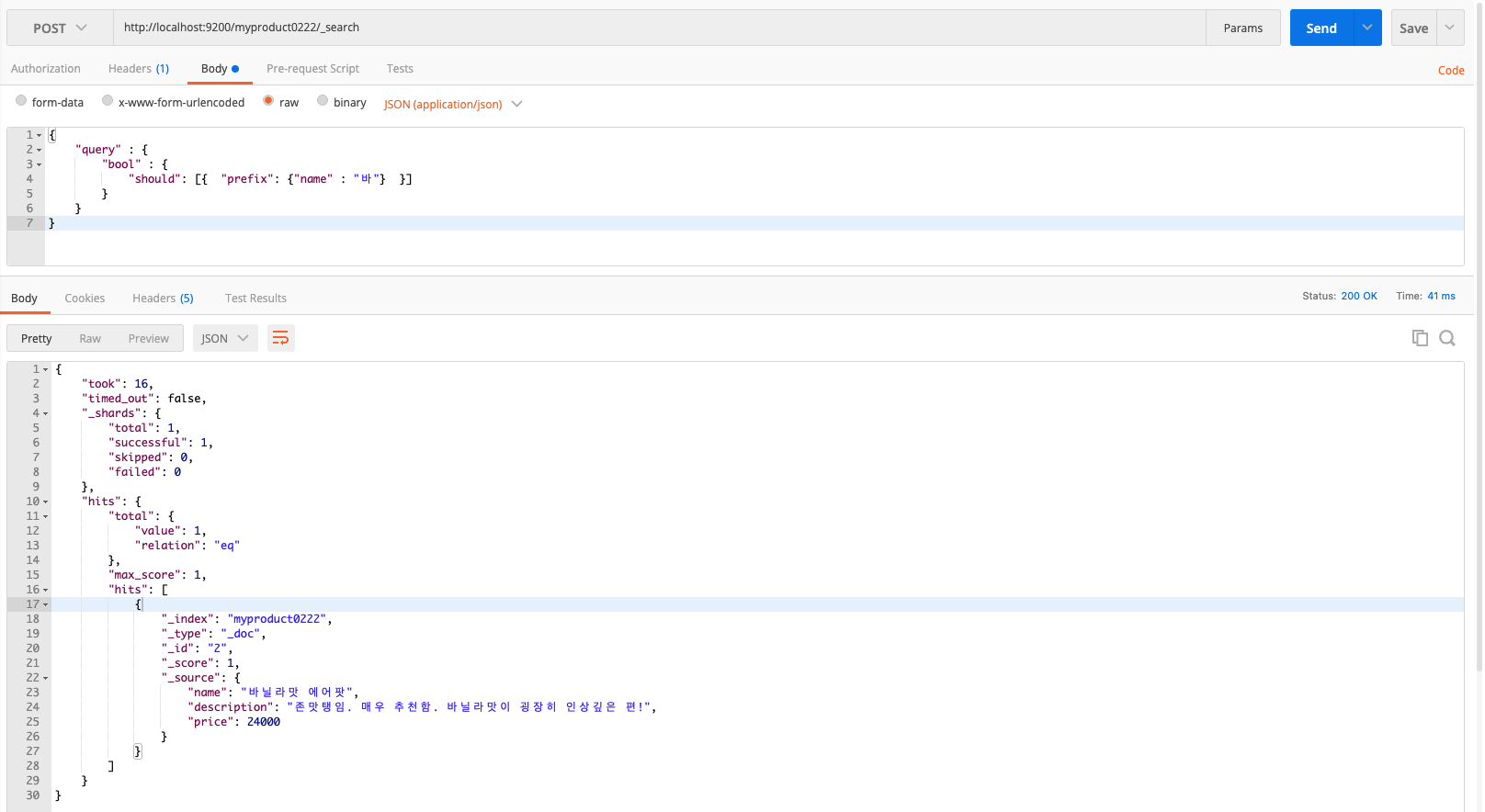
⬇️ Prefix: More like automatic complete search.
🌿 VS Code Practice
{
"template": "*",
"settings": {
"analysis": {
"analyzer": {
"tattoo_ngram_analyzer": {
"type": "custom",
"tokenizer": "tattoo_ngram_tokenizer",
"filter": ["lowercase", "my_stop_filter"]
}
},
"tokenizer": {
"tattoo_ngram_tokenizer": {
"type": "nGram",
"min_gram": "1",
"max_gram": "10"
}
},
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": ["the", "in", "..."]
}
}
},
"max_ngram_diff": "20"
},
"mappings": {
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"analyzer": "tattoo_ngram_analyzer"
},
"price": {
"type": "long"
}
}
}
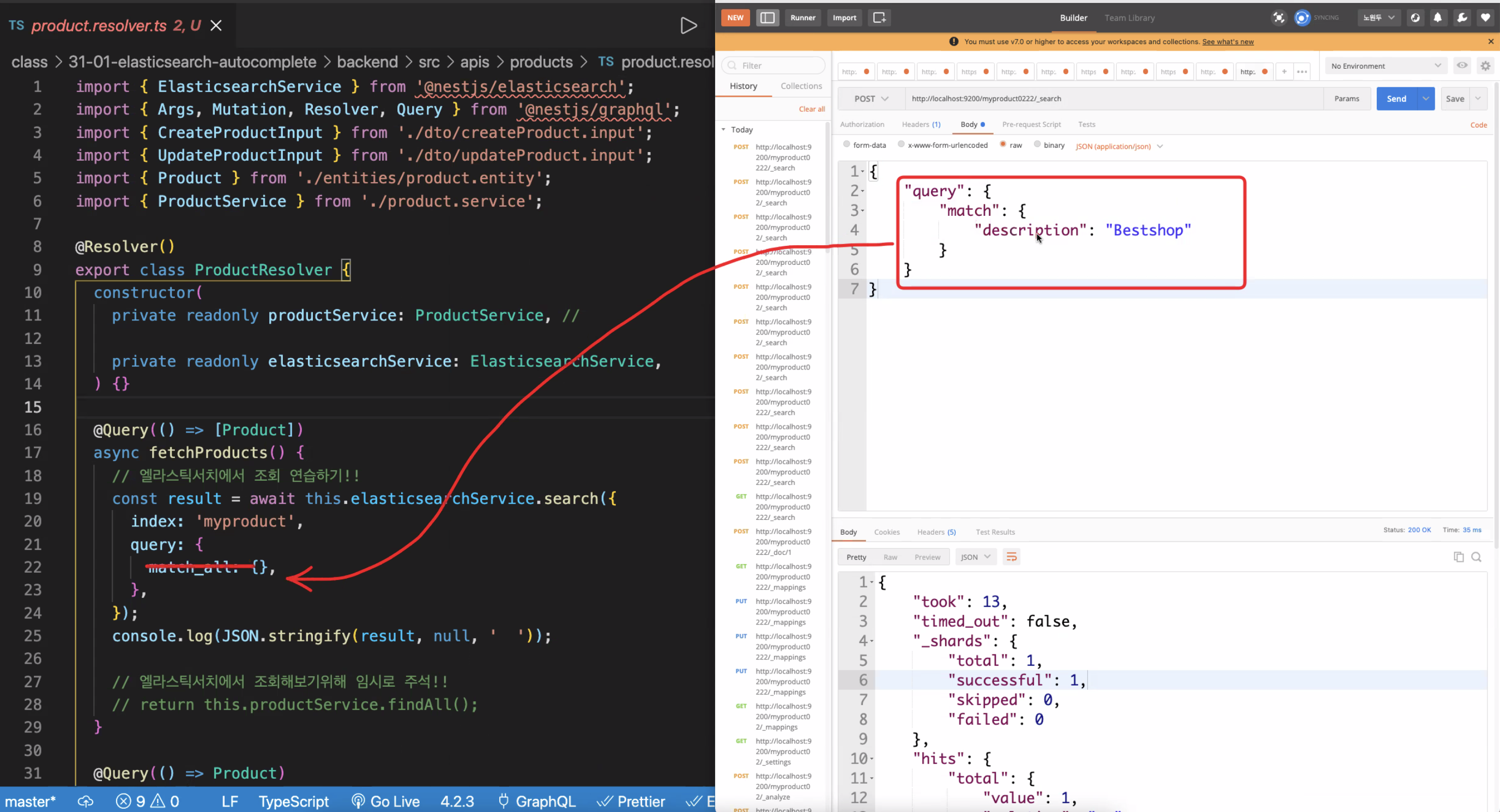
}🌿 Applying to Nest.js

6개의 댓글

I assumed it is usually a preview to post in case others appeared to be having problems getting acquainted with nonetheless We're a little bit hesitant merely i'm permitted to decide to put companies plus covers for listed here. https://jrpromotions.co.za/

Wonderful article. Fascinating to read. I love to read such an excellent article. Thanks! It has made my task more and extra easy. Keep rocking.양산 급전 대출

This article was written by a real thinking writer without a doubt. I agree many of the with the solid points made by the writer. I’ll be back day in and day for further new updates. olxtoto Today, I was just browsing along and came upon your blog. Just wanted to say good blog and this article helped me a lot, due to which I have found exactly I was looking. olxtoto I know this is one of the most meaningful information for me. And I'm animated reading your article. But should remark on some general things, the website style is perfect; the articles are great. Thanks for the ton of tangible and attainable help. Siaran Langsung Bola It is a fantastic post – immense clear and easy to understand. I am also holding out for the sharks too that made me laugh. Siaran Langsung Bola Your articles are inventive. I am looking forward to reading the plethora of articles that you have linked here. Thumbs up! SCORE808 Prediksi Sepak Bola Hari Ini
Efficiently written information. It will be profitable to anybody who utilizes it, counting me. Keep up the good work. For certain I will review out more posts day in and day out.

What a sensational blog! This blog is too much amazing in all aspects. Especially, it looks awesome and the content available on it is utmost qualitative.situs mawartoto
If more people that write articles involved themselves with writing great content like you, more readers would be interested in their writings. I have learned too many things from your article. blue mosque entrance