1. 웹의 이해.
- 웹의 이해.
- 월드 와이드 웹(world wide web) 은 인터넷에 연결된 컴퓨터를 이용하여 사람들과 정보를 공유할 수 있도록 거미줄처럼 엮인 공간.
- 웹 컴포넌트 : HTML과 HTTP : HTML
- HTML(Hyper Text Markup Language)은 웹상의 정보를 구조적으로 표햔하기 위한 언어.
- HTTP 프로토콜 : 데이터 송수신을 위해.
- HTML 형식 : 데이터를 표시하기 위해.
- HTML(Hyper Text Markup Language)은 웹상의 정보를 구조적으로 표햔하기 위한 언어.
- 웹 컴포넌트 : HTML과 HTTP : HTML.
- 태그는 꺾쇠 괄호 < >로 둘러싸여 있고, 그 안에 정보르에 대한 의미를 적음. 그리고 그 의미가 끝나는 부분에 슬래시(/) 를 사용하여 해당 태그를 종료.
<title> Hello, World</title> # 제목 요소, 값은 Hello, World- 웹 컴포넌트 : HTML과 HTTP : HTTP
- HTTP(Hypertext Transaction Protocol)는 인터넷에서 컴퓨터 간에 정보를 주고 받을 때 사용하는 일종의 약속을 말하며, 일반적으로 컴퓨터 과학에서는 이러한 약속을 프로토콜(protocol)이라고 함.
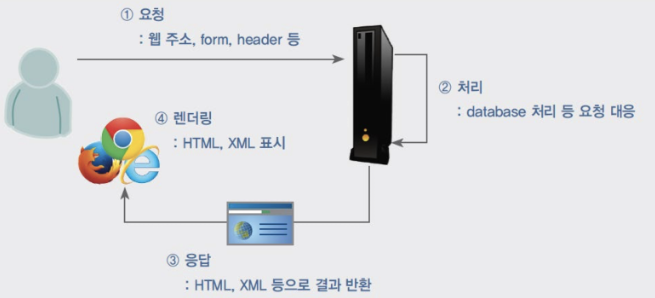
- 웹의 동작 순서.
- 웹에 있는 정보를 보기 위해 먼저 하는 일은 웹 브라우저를 시작하고, 거기에 주소 정보를 입력하는 것. 주소 정보의 공식 이름은 URL(Uniform Resource Locator)이라고 함.
- URL에는 해당 서버가 위치한 인터넷 주소 정보인 도메인 네임이 있다. 흔히 도메인 정보 또는 서버 주소라고도 하는 이 주소를 통해 웹의 정보를 제공하는 서버에 접속.
- 일반적으로 컴퓨터는 인터넷 프로토콜 주소(Internet Protocol address), 즉 IP주소라고 부르는 주소값을 가짐.
- IP주소를 컴퓨터의 주소로 생각하면 이 주소에 접속하기 위해 사용하는 도메인 네임과 연결하기 위한 도메인 네임 서버(Domain Name Server, DNS)가 운영됨.- 웹의 이해.
- 웹의 동작 순서.
- 웹 스크래핑
- 모든 웹은HTML로 구성되어 있으므로, HTML의 규칙을 파악한다면 얼마든지 HTML에서 필요한 정보를 가져올 수 있다.
- 이러한 과정을 일반적으로 웹 스크래핑 이라고 함.
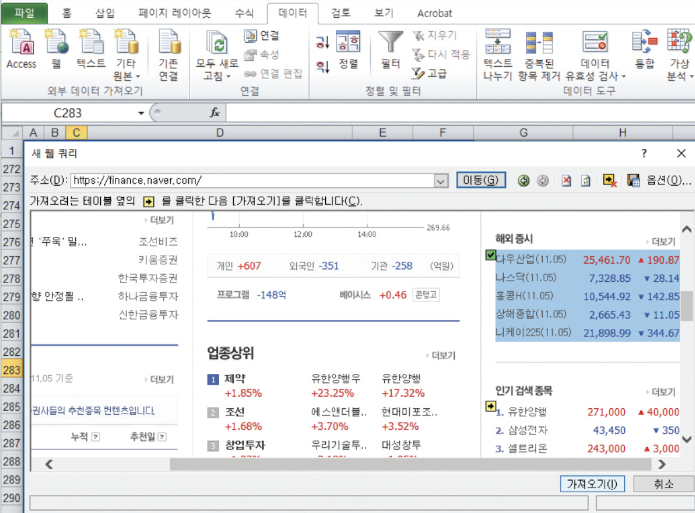
엑셀에서 웹의 정보 가져오기.
- 꼭 파이썬을 사용하지 않더라도 엑셀에서 간단하게 웹의 정보를 가져올 수 있다. 먼저 엑셀을 실행하여 [데이터] - [웹] 메뉴 선택. 대화상자가 열리면 추출하고 싶은 데이터가 있는 웹 주소를 입력. 추출하고자 하는 테이블을 선택하면 데이터가 출력되어 엑셀에 기록되는 것을 확인.
HTML 데이터 다루기.
- 웹에서 데이터 다운로드.
import urllib.request #urllib 모듈 호출.
url = "http://storage.googleapis.com/patents/grants_full_text/2014/ipg140107.zip"
# 다운로드 URL 주소.
print("Start Download")
fname.header = urllib.request.urlretrieve(url, 'ipg140107.zip')
print('End Download')웹에서 데이터 다운로드.
- 1행에서는 파이썬의 웹 페이지 연결 모듈인 urllib 모듈을 호출. 2행에서 파일이 있는 다운로드 URL 주소를 지정하고, 5행에서 urlretrieve() 함수와 URL 주소, 파일명을 입력하여 특정 파일을 저장.
- 특정 그림이나 강의 자료 같은 데이터를 자동화하여 다운로드할 때 매우 유용하다. 예를 들어, 구글 검색을 통해 특정 인물의 사진만 다운로드 할 수 있는 프로그램을 작성하여 이를 실행하면 효율적으로 특정 인물의 사진을 다운로드 할 수 있음.
HTML 데이터 다루기.
- HTML파싱.
-
웹 페이지의 HTML을 분석하여 데이터를 추출하는 작업.
-
특정 텍스트를 분석하여 그 데이터로부터 필요한 정보 추출.
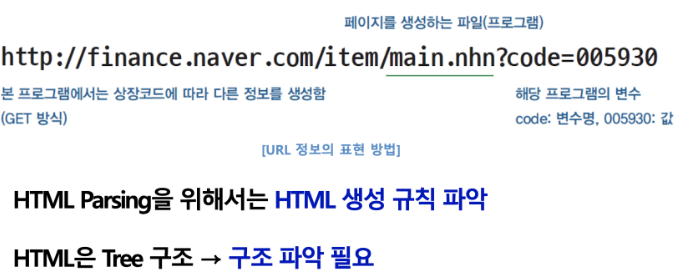
http://finance.naver.com/item/main--nhn?code=005930
-
HTML파싱.
- 다음으로 웹 페이지에서 필요한 정보만 추출하는 방법은 무엇일까? 아래의 테이블에서 필요한 주식 정보를 이떻게 가져올 수 있을까?
→ 가장 좋은 방법은 데이블을 구성하는 HTML 페이지를 찾아 그 정보를 가져오는 것. 먼저 해당 웹 페이지를 열고 마우스 오른쪽 버튼을 누른 후, ‘페이지 소스 보기’를 클릭. 웹페이지의 정보가 있는 HTML 코드를 확인할 수 있다. 이 코드를 분석하여 원하는 정보만 따로 추출할 수 있는데, 이를 위해 해당 정보를 표현하는 코드의 패턴을 찾아 HTML 생성 규칙을 파악, 이를 추출하는 프로그램을 만들어야 함.
정규 표현식.
- 정규 표현식의 개념.
- 정규 표현식은 일종의 문자를 표현하는 공식으로, 특정 규칙이 있는 문자열 집합을 추출할 때 자주 사용하는 기법.
- 정규 표현식, regexp 또는 regex 등으로 불림.
- 복잡한 문자열 패턴을 정의하는 문자 표현 공식.
- 특정한 규칙을 가진 문자열의 집합을 추출.
| 일반 문자 | 정규 표현식. |
|---|---|
| 010-0000-0000 | ^\d{3}-\d{4}-\d{4}$ |
| 203.252.101.40 | ^\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}$ |
- 주민등록 번호, 전화번호, 도서 ISBN 등 형식이 있는 문자열을 원본 문자열로 부터 추출함.
- HTML역시 tag를 사용한 일정한 형식이 존재하여 정규식으로 추출.

정규 표현식 문법.
- 정규 표현식을 배우기 위해 기본으로 알아야 하는 개념은 메타문자.
- 메타문자는 문자를 설명하기 위한 문자로 문자의 구성을 설명하기 위해 원래의 의미가 아니라 다른 의미로 쓰이는 문자를 뜻함.
. ^ $ * + ? { } [ ] / | ( )기본 메타문자 []
- 먼저 대괄호 []는 [ 와 ] 사이의 문자와 매칭하라는 뜻.
ex) [abc]는 어떤 텍스트에 a 또는 b 또는 c라는 텍스트가 있는지 찾으라는 뜻.
- 에는 or의 의미가 있다.
- 만약 [abc]라는 정규 표현식을 쓴다면 다음과 같은 텍스트에서 검색되는 텍스트는 어떤 것이 있을까? 여기서는 ‘a’의 a, ‘before’의 b와 같은 방식으로 검색될 것이다.
a, before, deep, dud, sunset- “-”를 사용 범위를 지정할 수 있음.
Ex) [A-Za-z]나 [가-힣]과 같은 기호로 문자열에서 알파벳과 한글을 추출할 수 있음.
[0-9]은 숫자 전체를 추출.
반복 관련 메타문자 -, +, *, ?, { }
- 앞에서 배운 [ ]는 매우 유용하지만, 한 번에 여러 개의 글자를 표현할 수 없다. 예를 들어, 휴대전화번호를 찾고 싶다면 다음과 같이 정규 표현식을 작성해야 한다.
[0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9][0-9]- 하지만 이렇게 하면 몇 가지 문제점이 있다. 먼저 텍스트를 너무 많이 적는다. 이럴 때 쓸 수 있는 메타문자가 + 이다. + 는 해당 글자가 1개 이상 출현하는 것을 뜻한다.
[0-9]+-[0-9]+-[0-9]+반복 관련 메타문자 -, +, *, ?, { }
- 출현 획수를 조정해야 할 때 사용하는 메타문자는 중괄호 { } 이다.
ex) [a-zA-Z]{3, 4} 이면 알파벳이 3자부터 4자까지 출현할 수 있다는 뜻.
- 반복 횟수는 {1,}, {0,}, {1,3}처럼 시작값이나 끝값은 지정하지 않고 오픈할 수 있음. 만약 {1,}라고 쓴다면 한번 이상 출현해야 한다는 제약이 있다.
[0-9]{3}-[0-9]{3,4}-[0-9]{4}- {m-n} - 반복 횟수를 지정.
그 외 메타문자 ( ), ., |, ^, $, \
- 메타문자 ()는 묶음을 표시하는 것으로, 좀 더 쉽게 메타문자의 묶음을 표시하는 역할.
- [.] - 줄바꿈 문자인 \n를 제외한 모든 문자와 매치.
- |는 or의 의미.
- ^은 not의 의미.
- 정규 표현식의 처음과 끝에느메타문자 ^과 $를 주로 붙임.
import re
text = "문의사항이 있으면 032-232-3245 으로 연락주시기 바랍니다."
regex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
matchobj = regex.search(text)
phonenumber = matchobj.group()
print(phonenumber)- 파이썬에서 정규표현식을 사용하기 위해서는 Regex를 위한 모듈인 re 모듈 사용.
- re 모듈의 compile 함수는 정규식 패턴을 입력으로 받아들여 정규식 객체를 리턴하는데, 즉, re.compile(검색할문자열) 와 같이 함수를 호출하면 정규식 객체(re.RegexObjcet 클래스 객체)리턴.
Lab : 웹스크래핑 실습.
아이디 추출.
- 먼저 특정 아이디를 추출하는 Lab이다. 다음 웹 사이트에는 이벤트 당첨자의 아이디를 발표한 웹 페이지가 있는데, 이 웹 페이지에서 필욯ㄴ 아이디만 추출.
import re
import urllib.request
url = "http://goo.gl/U7mSQI"
html = urllib.request.urlopen(url)
html_contents = str(html.read())
id_results = re.findall("([A-Za-z0-9]+\*\*\*)", html_contents)
# findall 전체 찾기, 정규 표현식 패턴 대로 데이터 찾기.
for result in id_results: # 찾은 정보를 화면에 출력.
print(result)아이디 추출.
→ 4행 접속할 웹 페이지의 링크 작성.
→ 5행 웹 페이지에 접속
→ 6행 해당 웹 페이지의 HTML 코드를 문자열로 가져옴.
→ HTML코드를 findall() 함수를 사용하여 정규 표현식 패턴에 넣어주면 패턴대로 데이터 추출 → id_results 변수에 넣어줌. 해당 변수는 튜플 형태로 반환되기 때문에 각각을 출력하기 위해서는 10행과 같이 for문 사용.
파일 자동 다운로드.
import urllib.request
import re
url = "http://www.google.com/googlebooks/uspto-patents-grants-text.html"
html = urllib.request..urlopen(url)
html_contents = str(html.read().decode("utf8"))
url_list = re.findall(r"(http)(.+)(zip)", html_contents)
for url in url_list:
full_url = "".join(url)
print(full_url)
fname,header = urllib.request.urlretrieve(full_url, file_name)
print("End Download")HTML 파싱.
- 코드는 크게 두 가지 부분으로 구성.
- ~에 정보가 있음.
- ~정보를 추출.
(\)[\s\S]+?)(\<\/dl>)
(\)([\s\S]+?(\<\/dd>)코드
import urllib.request
import re
url = "http://finance.naver.com/item/main.nhn?code=005930"
html = urllib.request.urlopen(url)
html_contents = str(html.read().decode("ms949"))
# 첫 번째 HTML 패턴.
stock_results = re.findall("(\<dl class = \"blind\"\>)([\s\S]+?)(\<\/d'\>)",
html_contents)
samsung_stock = stock_results[0]
samsung_index = samsung_stock[1]
print(type(stock_results))
print(type(samsung_stock))
print(type(samsung_index))
idex_list = re.findall("(\<dd\>)([\s\S]+?)(\<\/dd\>)", samsung_index)
for index in index_list:
print(index[1])
Data Science. DevOps.