
> 과제 요구사항
word tree를 만드는 코드를 작성한다.
예시로, 단어가 다음과 같이 있다고 할 때 word tree는 그림과 같다.
[예시 단어들 - application, app, orange, apple, applet, apple]
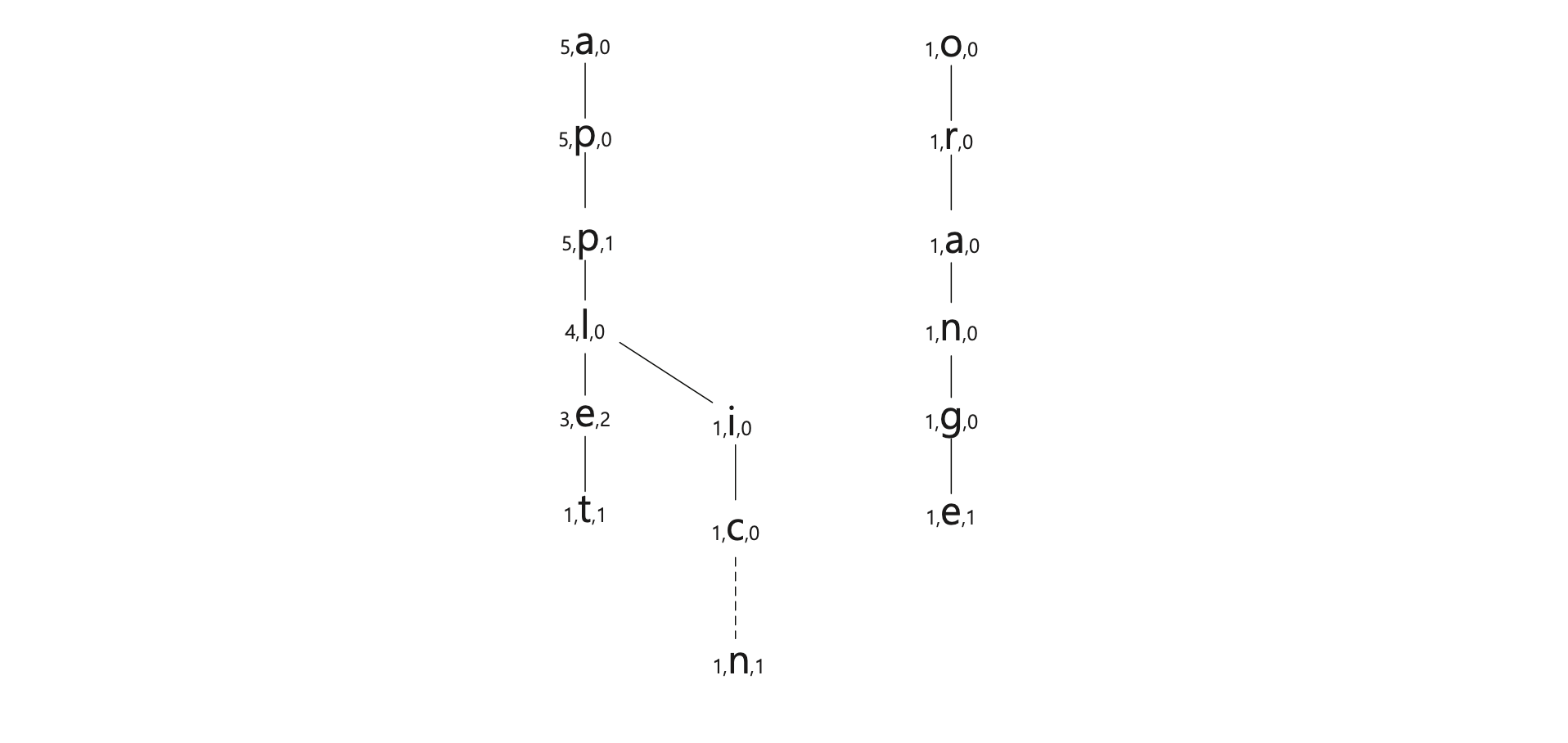
tree에서 알파벳의 왼쪽 숫자는 단어들에서 해당 알파벳이 등장한 횟수를, 오른쪽 숫자는 해당 알파벳으로 끝나는 단어의 개수를 나타낸다.
입력으로는 아무 알파벳이나 받는다. 
출력으로는 입력한 알파벳들로 시작하는 단어 중 가장 빈도가 높은 세 단어를 출력한다.
위의 단어 예시를 가지고 입력을 반복했을 때 다음과 같은 결과가 나오게 된다.
> 출력 예시
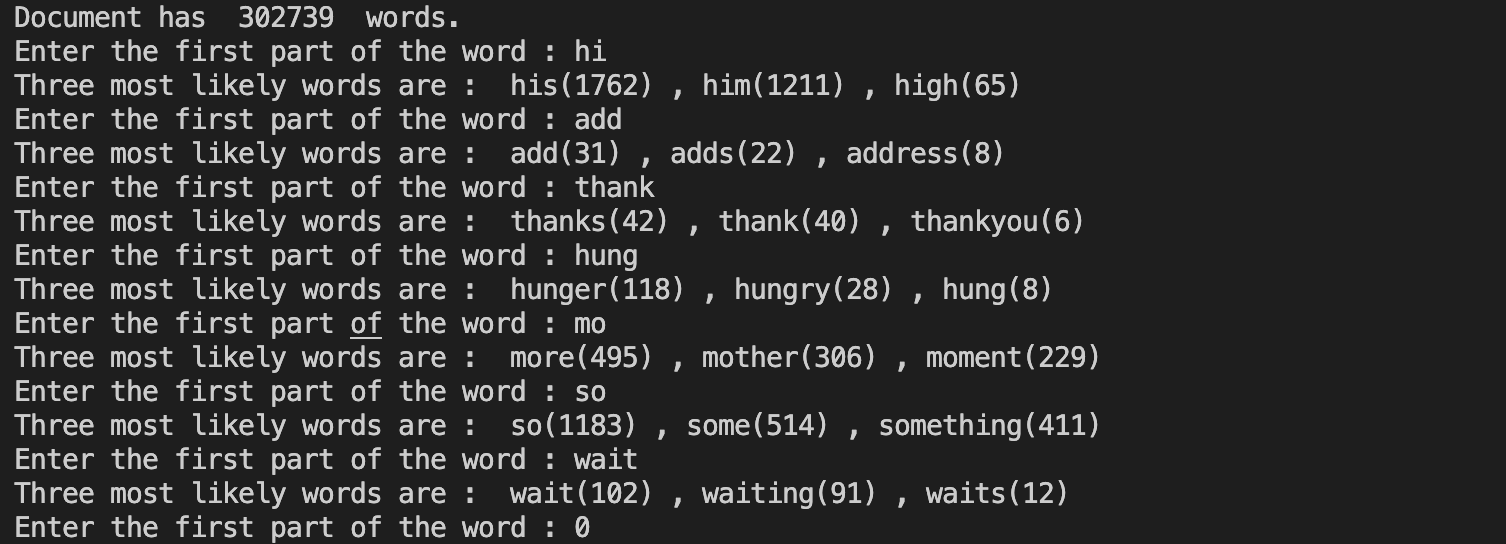
내가 작성한 코드는 novel.txt 파일에 속한 단어들을 가지고 word tree를 만든다.
출력 예시는 다음과 같게 된다.
> 코드
파이썬의 딕셔너리를 이용하면 쉽게 만들어낼 수 있다.
import string
import operator
def get_word_list(document):
"""
Given a path to a document, return a list version of all of the words in the document.
Example:
"Hello. My name is John Smith." -> ["hello", "my", "name", "is", "john", "smith"]
"""
file = open(document, 'r')
line = file.read()
file.close()
line = line.strip().lower()
for char in string.punctuation:
line = line.replace(char, "")
return line.split()
alpha=['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z']
def make_child(i,w_list):
if len(w_list)==i+1:
dct={w_list[i]:[1,1]}
return dct
else:
i=i+1
tmp=make_child(i,w_list)
dct={w_list[i-1]:[1,0,tmp]}
i=i-1
return dct
def compare(dct,i,w_list):
if len(w_list)==i+1: #last alphabet
chr=w_list[i]
if chr in dct:
dct[chr][0]=dct[chr][0]+1
dct[chr][1]=dct[chr][1]+1
return dct
else:
x=make_child(i,w_list)
dct.update(x)
return dct
else:
chr=w_list[i]
i=i+1
if chr in dct:
dct[chr][0]=dct[chr][0]+1
if len(dct[chr])<=2:
k=make_child(i,w_list)
dct[chr].append(k)
return dct
else:
k=compare(dct[chr][2],i,w_list)
dct[chr][2].update(k)
return dct
else:
x=make_child(i-1,w_list)
dct.update(x)
return dct
def make_tree(document):
"""
Given a path to a document, make and return a word tree for the words in the document.
"""
word_list = get_word_list(document)
print("Document has ", len(word_list), " words.")
tree={}
flag=0
for word in word_list:
word=list(word)
if len(word)<=0:
continue
if flag==0:
i=0
tree.update(make_child(i,word))
flag=1
else:
i=0
tree=compare(tree,i,word)
return tree
# Add your functions here
res={}
def check_first(dct,i,word):
if word[i] in dct:
chr=word[i]
i=i+1
if len(word)==i:
if dct[chr][1]!=0:
tmp=word
tmp=''.join(tmp)
res[tmp]=dct[chr][1]
if len(dct[chr])<=2:
pass
elif len(dct[chr])>2:
return dct[chr][2]
else:
k=check_first(dct[chr][2],i,word)
return k
else:
pass
def check(dct,word):
if dct==None:
return
else:
for al in dct:
if len(dct[al])<=2:
if dct[al][1]!=0:
tmp=word.copy()
tmp.append(al)
tmp=''.join(tmp)
res[tmp]=dct[al][1]
else:
send=word.copy()
send.append(al)
check(dct[al][2],send)
if dct[al][1]!=0:
tmp2=word.copy()
tmp2.append(al)
tmp2=''.join(tmp2)
res[tmp2]=dct[al][1]
if __name__ == "__main__":
word_tree = make_tree('novel.txt')
while True :
input_text = input('Enter the first part of the word : ')
if input_text == '0' : break
w=list(input_text)
x=check_first(word_tree,0,w)
check(x,w)
res=sorted(res.items(),key=operator.itemgetter(1),reverse=True)
res=res[0:3]
res=dict(res)
save=[]
for i in res:
num=res[i]
i=list(i)
i.append('(')
i.append(str(num))
i.append(')')
i=''.join(i)
save.append(i)
if len(save)==0:
print('Three most likely words are : Nothing more')
elif len(save)==1:
print('Three most likely words are : ',save[0],', Nothing more')
elif len(save)==2:
print('Three most likely words are : ',save[0],',', save[1],', Nothing more')
elif len(save)==3:
print('Three most likely words are : ',save[0],',', save[1],',', save[2])
res={}> 추가 첨부파일
코드에 쓰인 novel.txt이다.
https://drive.google.com/file/d/1Rzh-R9LV1QK-SMTjN0yDuIvvTCqL8Pmn/view?usp=share_link
단어 302739개가 속해있는 파일이다.

매일 공부하기 목표 👨💻