출처
본 글은 인프런의 김영한님 강의 자바 ORM 표준 JPA 프로그래밍 - 기본편 을 수강하며 기록한 필기 내용을 정리한 글입니다.
-> 인프런
-> 자바 ORM 표준 JPA 프로그래밍 - 기본편 강의
0. 예제 설정
- 다음과 같이 예제를 설정한다.
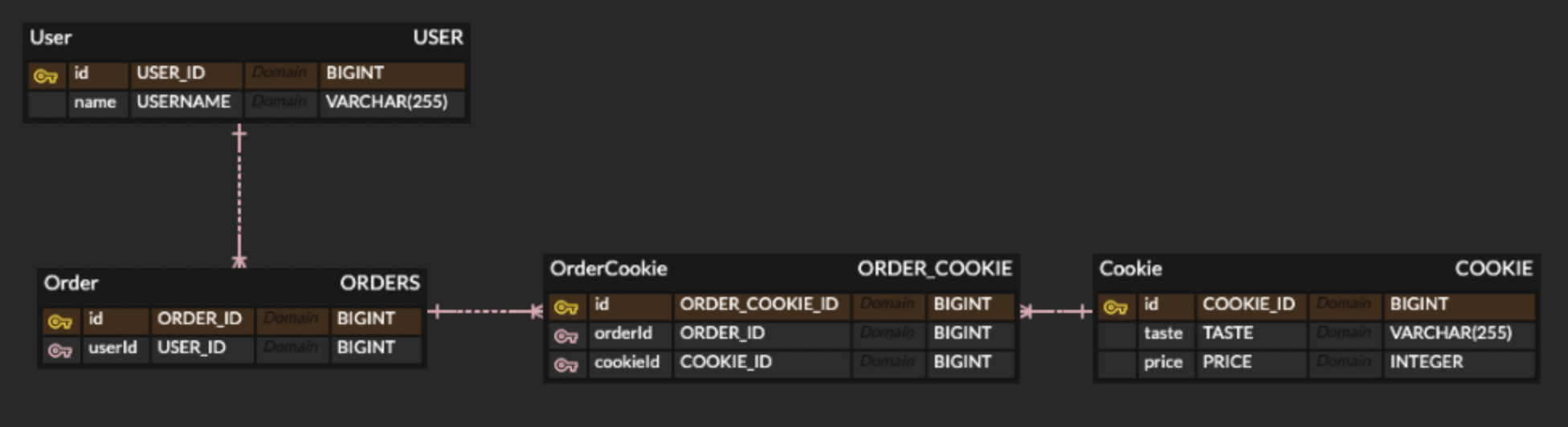
- USER, ORDERS, ORDER_COOKIE, COOKIE 4가지 테이블이 있다.
- 각 테이블마다 상단 양쪽에 이름이 두개 적혀있는데, 각각은 아래와 같다.
-> 좌측 파스칼 표기 : JPA 상에서 구현되는 엔티티의 이름
-> 우측 모두 대문자로 표기 : DB에 생성되는 테이블 이름 - 각 필드마다 두가지 이름이 있는데, 각각은 아래와 같다.
-> 좌측 카멜 케이스 표기 : JPA 상에서 구현되는 엔티티의 필드 이름
-> 우측 모두 대문자로 표기 : DB 테이블 내 컬럼 이름 - 노란색 열쇠가 표기된 컬럼은 PK를, 분홍색 열쇠가 표기된 컬럼은 FK이다.
- 테이블 간에 연결된 분홍색 점선은 비식별 연관관계를 의미하며, 각 테이블 간의 연관관계는 다음과 같다.
- USER : ORDERS = 1 : N
- 한 명의 유저가 여러 주문을 할 수 있다. (이것도 사고 저것도 사고..)
- 하나의 주문을 여러 유저가 할 수는 없다. (여러명이 모여 하나의 주문을 할 수 없다.)
- ORDERS : COOKIE = N : M 관계이며, 중간에 'ORDER_COOKIE'를 두어 1 : N, N : 1 관계로 구현한다.
- 하나의 주문에 여러 쿠키들이 주문될 수 있다.
- 하나의 쿠키가 여러 주문에 의해 팔릴 수 있다.
1. JPA 내 연관관계 매핑의 필요성
- 예제 중 USER - ORDERS 관계만 보도록 한다.
- 만약 JPA 상에서 예제의 테이블을 그대로 매핑하게 될 경우, 아래와 같이 구현될 수 있다.
<테이블 위주 매핑>
(User class)
@Entity
public class User{
@Id @GeneratedValue
@Column(name = "USER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
}(Order class)
@Entity
@Table(name = "ORDERS")
public class Order{
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@Column(name = "USER_ID")
private Long userId;
}- 이렇게 테이블 구조처럼 Order class 내에 User 객체의 id 값을 갖게 되면, 객체 지향적인 개발이 이루어지기 어렵다.
<데이터 삽입 과정>
User oneUser = new User();
oneUser.setName("user1");
entityManager.persist(oneUser);
Order oneOrder = new Order();
oneOrder.setUserId(oneUser.getId());
entityManager.persist(oneOrder);- User의 객체 자체를 Order에 셋팅하는게 아닌, User의 Id값을 받아와 셋팅한다.
-> 방식이 좀 애매하다. User 객체 자체가 저장되어야 좀 더 객체 지향적일 것이다.
<데이터 조회 과정>
- 특정 주문으로부터 유저를 찾아 작업을 수행해야 할 때, 아래와 같은 과정으로 수행될 수 있을 것이다.
Order oneOrder = entityManager.find(Order.class, orderId); // '특정 주문' 데이터를 받아온다.
User oneUser = entityManager.find(User.class, oneOrder.getUserID()); // 주문한 유저의 데이터를 받아온다.- 코드를 보면 find() 과정이 다음과 같이 두번 이루어진다.
-> Order 데이터 find : oneOrder에 저장.
-> User 데이터 find : oneOrder의 userId를 get해와서 다시한번 User를 find - 이는 객체 지향적인 JPA 개발 방식에 맞지 않는다.
- oneOrder 객체 내에 'userId'가 아닌, User 객체 자체가 들어가 있어야 할 것이다. : 연관관계 매핑
2. 단방향 연관관계
- 앞서 언급한 내용처럼 Order 객체 내에 User 객체를 넣기 위해서는 두가지 어노테이션이 활용된다.
-> @ManyToOne, @JoinColumn - @ManyToOne : JPA에게 일대다 연관관계 매핑임을 알린다. 일대다(1:N) 관계에서 다(N) 쪽에 걸어주어야 한다.
- @JoinColumn : DB에서 조회할 때, 어느 Column을 기준으로 join되는지 설정한다. : FK
-> DB의 join 쿼리를 살펴보면 알 수 있다.
-> DB에서 join시킬 때, FK Column의 데이터를 기준으로 한다. (예제에서는 USER_ID)SELECT * FROM ORDERS O JOIN USER U ON O.USER_ID = U.USER_ID
-> 따라서 해당 Column의 이름을 @JoinColumn 어노테이션의 name 속성으로 전달해주면 된다.
<단방향 연관관계 매핑 적용>
@Entity
@Table(name = "ORDERS")
public class Order{
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "USER_ID")
private User user;
}- 테이블처럼 userId를 갖고 있는게 아닌, user 객체 자체를 가질 수 있게 된다.
<데이터 삽입 과정>
User oneUser = new User();
oneUser.setName("user1");
entityManager.persist(oneUser);
Order oneOrder = new Order();
oneOrder.setUser(oneUser);
entityManager.persist(oneOrder);- oneUser 객체의 id 값을 저장하는게 아닌, oneUser 객체 자체를 저장한다.
<데이터 조회 과정>
Order oneOrder = entityManager.find(oneOrder.class, orderId);
User oneUser = oneOrder.getUser();- oneOrder에 저장되어 있는 userId를 토대로 다시 find() 하는게 아닌, 바로 user 객체에 접근할 수 있다.
3. 양방향 연관관계
- 양방향 연관관계에 앞서, DB의 테이블 연관관계와 Java의 객체 연관관계 사이에 차이점이 있다는 것을 알아야 한다.
<테이블 vs 객체>
(1) 테이블
- 테이블의 경우, FK 만으로 두 테이블 간의 일대다(1:N) 혹은 다대일(N:1) 연관관계가 성립된다.
- 이렇게 설정된 FK를 통해 일(1) 혹은 다(N) 어느 테이블에서든 join시켜 조회할 수 있다.
SELECT * FROM ORDERS O JOIN USER U ON O.USER_ID = U.USER_IDSELECT * FROM USER U JOIN ORDERS O ON U.USER_ID = O.USER_ID- 즉, 테이블에서는 다(N) 쪽에 FK 필드만 추가해두면, 일(1)->다(N), 다(N)->일(1) 양방향으로 자유롭게 조회가 가능하다.
(2) 객체
- 객체의 경우, 참조를 통해 연관관계를 설정할 수 있다.
- 만약 테이블처럼 양방향으로 데이터를 조회하기 위해서는, 두 객체 모두 서로를 참조할 수 있어야 한다.
@Entity
@Table(name = "ORDERS")
public class Order{
@Id @GeneratedValue
@Column(name = "ORDER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "USER_ID")
private User user;
}- 앞서 단방향 연관관계 매핑을 적용한 Order class를 보면, Order class의 객체는 아래와 같이 참조를 통해 user 객체의 데이터에 접근할 수 있다.
Order oneOrder = entityManager.find(Order.class, orderId);
System.out.println("User Name : "+oneOrder.getUser().getName());- 만약 User class 객체에서도 참조를 통해 Order class 객체의 데이터를 가져오고 싶다면, 다음과 같이 설정해주어야 할 것이다.
(주문 목록을 추가해보자)
@Entity
public class User{
@Id @GeneratedValue
@Column(name = "USER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
private List<Order> orderList = new ArrayList<>();
}(JPA 상에서 활용되기 위해서는 어노테이션이 추가되어야 한다. 이는 후에 다룬다.)
- 위와 같이 User class 내에 Order class 객체를 담을 수 있도록 필드를 설정해두면, 아래와 같이 참조로 접근할 수 있을 것이다.
User oneUser = entityManager.find(User.class, userId);
List<Order> orderList = oneUser.getOrderList();
for(Order o : orderList){
System.out.println("Order Id : "+o.getId());
}- 즉, 두 객체가 연관관계를 가질 때, 서로의 데이터에 접근(양방향으로)하기 위해서는 참조로 접근할 수 있도록 서로의 객체 필드를 갖고 있어야 한다.
-> Order class는 User class 객체의 필드를 갖고 있다.
-> User class는 Order class 객체 리스트 필드를 갖고 있다.
<차이점 정리 및 연관관계 매핑 방식>
- 상기 내용에 따르면 양방향 연관관계를 설정할 때 객체와 테이블은 각각 다음과 같이 설정되어야 할 것이다.
-> 테이블 : 다(N) 쪽에 FK 컬럼만 추가하면 된다. : 1개 추가
-> 객체 : 서로 참조할 수 있도록 각자 필드를 추가해야 한다. : 2개 추가 - JPA 에서는 어쨌든 DB의 테이블과 매핑시켜야 하는데, 테이블은 FK 컬럼 하나가 추가되고, 객체는 두 개의 필드가 추가된다.
-> 둘 중 어느 필드와 매핑을 시키는게 좋을지 애매할 수 있다. - 객체의 두 필드(일 쪽에 하나, 다 쪽에 하나) 중, 실제로 테이블 FK 컬럼과 매핑되는 필드는 다(N) 쪽 class의 필드가 되어야 한다.
-> 예제에서 Order class의 user 필드
-> 해당 필드가 연관관계의 주인이 된다. - User class의 orders 필드와 매핑시킬 수도 있지만, 복잡하고 권장되지 않는다.
-> 이렇게 매핑시키면, USER 테이블에 저장하는데 ORDERS 테이블에도 쿼리가 날아갈 것이다.
-> 상황에 따라 다르겠지만, 웬만하면 다수 쪽과 매핑시키는게 맘편하다.
<양방향 연관관계>
- 앞서 단방향 연관관계를 구현하면서 Order -> User 방향(다 -> 일)은 구현이 되었으므로, 반대 방향인 User -> Order(일 -> 다)만 구현하면 된다.
- 해당 방향의 연관관계를 구현하기 위해서는 @OneToMany 어노테이션이 활용된다.
@Entity
public class User{
@Id @GeneratedValue
@Column(name = "USER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@OneToMany(mappedBy = "user")
private List<Order> orderList = new ArrayList<>();
}- 아까 다(N) 쪽에서 매핑할 때는 @ManyToOne이 쓰였지만, 일(1) 쪽에서 매핑할 때는 반대로 @OneToMany 가 쓰인다.
- 그리고 상대방 측에서 본인과 연결된 필드 이름을 mappedBy 속성으로 전달한다.
-> 즉, 연관관계 주인이 전달된다.
-> 예제에서 연관관계 주인은 Order class의 user 이므로, user를 전달한다.
<데이터 삽입>
public void addOrder(Order order){
this.orders.add(order);
}- addOrder 메소드가 SETTER 역할을 수행할 것이다.
User oneUser = new User();
oneUser.setName("user1");
entityManager.persist(oneUser);
Order oneOrder = new Order();
oneOrder.setUser(oneUser);
entityManager.persist(oneOrder);
oneUser.addOrder(oneOrder);- 두 객체가 persist() 된 후, oneUser의 orders 필드에 oneOrder 객체를 추가한다.
- 사실 oneUser 쪽에서는 굳이 추가하지 않아도 쿼리는 잘 나가지만, 추가해주는게 좋다.
-> 추가하지 않으면 영속성 컨텍스트 1차 캐시에 저장되는 JPA 동작 과정에 의해 빈 껍데기에 접근하게 된다거나, 후에 테스트 케이스를 작성할 때도 문제가 될 수 있다.
-> 영속성 컨텍스트 - 매번 이렇게 직접 추가하게 되면 잊어버리거나 귀찮으니, 아래와 같이 SETTER를 수정하는 방법도 있다.
(기존 Order class의 setUser)
public void setUser(User user){
this.user = user;
}(수정한 Order class의 setUser)
public void setUserAndAddToOrders(User user){
this.user = user;
user.getOrders().add(this);
}- 만약 이렇게 SETTER를 수정할 경우, 함수 이름을 알아볼 수 있게 설정해두는게 좋다.
4. 정리
<단방향 연관관계 매핑>
- @ManyToOne : 일대다, 다대일 매핑. 해당 어노테이션이 쓰인 곳이 다수(N).
- @JoinColumn : DB에서 join할 때 기준이 되는 컬럼 명 설정. FK.
<양방향 연관관계 매핑>
- @OneToMany : 양방향 매핑. 해당 어노테이션이 쓰인 곳이 일(1).
-> mappedBy 속성으로 본인과 연결된 상대방의 필드(연관관계 주인)명 설정.
<웬만하면 단방향으로>
- 양방향 연관관계는 복잡해질 수 있으므로, 웬만하면 모든 연관관계를 단방향으로 짓는게 좋다.
-> 양방향은 사실 단방향 연관관계 매핑 되어 있는 거에 반대 방향으로 조회할 수 있는 기능을 추가한 것 뿐이지만, 복잡해진다.
-> JPQL과 같이 대체할 수 있는 방안은 충분히 많을 것이다. - 양방향 연관관계 매핑은 나중에 추가해도 된다.
-> 사실 단방향으로 개발 다 해놓고 나중에 양방향을 추가해도 DB 상에서는 달라진게 없다.
-> JPA 상에서 양방향 매핑 추가한다고 DB에 컬럼이 추가되거나 그러진 않기 때문.

경험과 기록으로 성장하기