출처
본 글은 인프런의 김영한님 강의 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 을 수강하며 기록한 필기 내용을 정리한 글입니다.
-> 인프런
-> 실전! 스프링 부트와 JPA 활용2 - API 개발과 성능 최적화 강의
간단한 주문 조회 API V1 : 엔티티 직접 노출
- 정말 간단하게 다음과 같이 짠다. (이렇게 짜면 안됨)
@GetMapping("/simpleorder/v1")
public List<Order> ordersV1() {
List<Order> allOrders = orderService.findOrders(new OrderSearch());
return allOrders;
}- 이렇게 짤 경우, Order에서 Member를 join하고, Member에서 또 Order를 join하고.. 계속 무한루프 돌게 됨.
- 그래서 반환되는 데이터가 폭발적으로 늘어나게 된다.
- Member와 Order가 서로 양방향 연관관계를 맺고 있기 때문이다.
@JsonIgnore어노테이션을 활용하면 끊어낼 수 있다.
- 또한 모든 엔티티 정보가 노출되기 때문에 본 방식은 활용하면 안된다.
간단한 주문 조회 API V2 : 엔티티 → Dto 변환
- 다음과 같이 응답 Dto와 간단한 주문 조회 API 스펙에 맞춘 Dto를 생성해서 반환한다.
...
@GetMapping("/simpleorder/v2")
public OrderResult<List<SimpleOrderDto>> ordersV2() {
List<SimpleOrderDto> orderDtos = orderService.findOrders(new OrderSearch())
.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());
return new OrderResult<>("주문 조회 완료", orderDtos);
}
@Data
static class SimpleOrderDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
public SimpleOrderDto(Order order) {
this.orderId = order.getId();
this.name = order.getMember().getName();
this.orderDate = order.getOrderDate();
this.orderStatus = order.getStatus();
this.address = order.getDelivery().getAddress();
}
}
@Data
@AllArgsConstructor
static class OrderResult<T> {
private String message;
private T data;
}
...- 이렇게 하면 다음과 같이 적절한 스펙으로 필요한 정보만 담아서 응답으로 반환할 수 있게 된다.
{
"message": "주문 조회 완료",
"data": [
{
"orderId": 4,
"name": "userA",
"orderDate": "2023-06-29T19:19:31.615095",
"orderStatus": "ORDER",
"address": {
"city": "서울",
"street": "1",
"zipcode": "1111"
}
},
{
"orderId": 11,
"name": "userB",
"orderDate": "2023-06-29T19:19:31.644563",
"orderStatus": "ORDER",
"address": {
"city": "진주",
"street": "2",
"zipcode": "2222"
}
}
]
}- 하지만 그냥 이렇게만 해두면 N + 1 문제가 발생한다.
- 위 코드를 다시 보면 먼저 Order 테이블을 대상으로 조회한다.
- 이후 조회된 Order 데이터 목록만 가져와서
orderDtos에 담기게 되고, Controller 단에서 다음 과정을 거친다.
List<SimpleOrderDto> orderDtos = orderService.findOrders(new OrderSearch())
.stream()
.map(SimpleOrderDto::new)
.collect(Collectors.toList());- 여기서
SimpleOrderDto의 생성자를 자세히 보면
public SimpleOrderDto(Order order) {
this.orderId = order.getId();
this.name = order.getMember().getName(); // LAZY 초기화
this.orderDate = order.getOrderDate();
this.orderStatus = order.getStatus();
this.address = order.getDelivery().getAddress(); // LAZY 초기화- 이렇게 Order 엔티티 내 Member와 Delivery 엔티티에 접근해서 각각 Name과 Address를 가져온다.
- 이 때 LAZY Loading으로 인해 해당 데이터를 채우기 위한 쿼리를 DB로 보내게 된다.
- 여기서 각 Order 데이터마다 해당 과정이 이루어지게 되고, 결국 Order 엔티티를 채우기 위한 쿼리 1번, 그 결과 N개의 Order 데이터에 대해 각각 Member, Delivery 데이터를 조회하기 위한 쿼리들이 전송된다. ⇒ N + 1 문제
- 따라서 이를 보완하기 위해서는 Fetch Join을 써야한다.
간단한 주문 조회 API V3 : Fetch Join 활용
- OrderRepositoryImpl 에서 Order 엔티티를 조회하는 메서드를 다음과 같이 수정한다.
@Override
public List<Order> findAll(OrderSearch orderSearch) {
return em.createQuery("SELECT o FROM Order o JOIN FETCH o.member JOIN FETCH o.delivery", Order.class)
.getResultList();
}- JPQL을 보면
SELECT o FROM Order o JOIN FETCH o.member JOIN FETCH o.delivery- Fetch Join을 활용하는 것을 확인할 수 있다.
- 이렇게 Fetch Join을 활용하면 한번의 쿼리로 각 Order 데이터와 연관된 Member, Delivery 데이터를 한번에 다 join 해서 가져와서 객체에 값들을 모두 채우게 된다.
- DB로 전송된 쿼리를 보면
select
order0_.order_id as order_id1_9_0_,
member1_.member_id as member_i1_6_1_,
delivery2_.delivery_id as delivery1_3_2_,
order0_.created_at as created_2_9_0_,
order0_.modified_at as modified3_9_0_,
order0_.delivery_id as delivery6_9_0_,
order0_.member_id as member_i7_9_0_,
order0_.orderdate as orderdat4_9_0_,
order0_.status as status5_9_0_,
member1_.created_at as created_2_6_1_,
member1_.modified_at as modified3_6_1_,
member1_.city as city4_6_1_,
member1_.street as street5_6_1_,
member1_.zipcode as zipcode6_6_1_,
member1_.name as name7_6_1_,
delivery2_.created_at as created_2_3_2_,
delivery2_.modified_at as modified3_3_2_,
delivery2_.city as city4_3_2_,
delivery2_.street as street5_3_2_,
delivery2_.zipcode as zipcode6_3_2_,
delivery2_.status as status7_3_2_
from
orders order0_
inner join
member member1_
on order0_.member_id=member1_.member_id
inner join
delivery delivery2_
on order0_.delivery_id=delivery2_.delivery_id- 이렇게 모든 데이터를 한번에 받아오는 것을 확인할 수 있다.
- 여기서 좀 더 최적화 시킬 수 있는데, 위 쿼리를 보면 각 엔티티의 모든 필드들을 싹다 조회하고 있는 것을 볼 수 있다.
- 여기서 필요한 필드들만 골라서 SELECT 절에 해당 컬럼들만 포함시키는 방식으로 얻어오면 좀 더 최적화가 될 수 있다.
간단한 주문 조회 API V4 : DTO로 바로 조회
- 다음과 같이
SimpleOrderQueryDto파일을 생성하고 다음 내용으로 구성한다.
@Data
@AllArgsConstructor
public class SimpleOrderQueryDto {
private Long orderId;
private String name;
private LocalDateTime orderDate;
private OrderStatus orderStatus;
private Address address;
}- 그리고
OrderRepositoryImpl에서 다음과 같이 활용한다.
@Override
public List<SimpleOrderQueryDto> findOrderDtos(OrderSearch orderSearch) {
return em.createQuery("SELECT "
+ "new jpabook.jpashop.domain.order.dto.SimpleOrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)"
+ " FROM Order o JOIN o.member m JOIN o.delivery d", SimpleOrderQueryDto.class)
.getResultList();
}- 이후
OrderServiceImpl에서도 다음과 같이 반환해주고,
@Override
public List<SimpleOrderQueryDto> findOrderDtos(OrderSearch orderSearch) {
return orderRepository.findOrderDtos(orderSearch);
}- 이를
OrderSmpleApiController에서 활용해준다.
@GetMapping("/simpleorder/v4")
public OrderResult<List<SimpleOrderQueryDto>> orderV4() {
return new OrderResult<>("주문 조회 완료", orderService.findOrderDtos(new OrderSearch()));
}- 본 방식에서 활용된 JPQL을 보면,
SELECT
new jpabook.jpashop.domain.order.dto.SimpleOrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)
FROM Order o JOIN o.member m JOIN o.delivery d- 위와 같이
SimpleOrderQueryDto의 생성자를 활용해서 조회한 데이터들을 곧바로 넣어서 반환하는 것을 확인할 수 있다.- 여기서 JPQL이 Fetch Join이 아닌, 그냥 Join으로 조회하는 것에 유의해야 한다.
- 해당 기능은 Fetch Join이 아닌, Dto 생성자에 맞춰 JPA가 자동으로 값을 넣어주기 위해 자동으로 join 쿼리를 생성해서 DB로부터 데이터를 받아오는 기능인 것.
- DB로 전송된 쿼리를 보면,
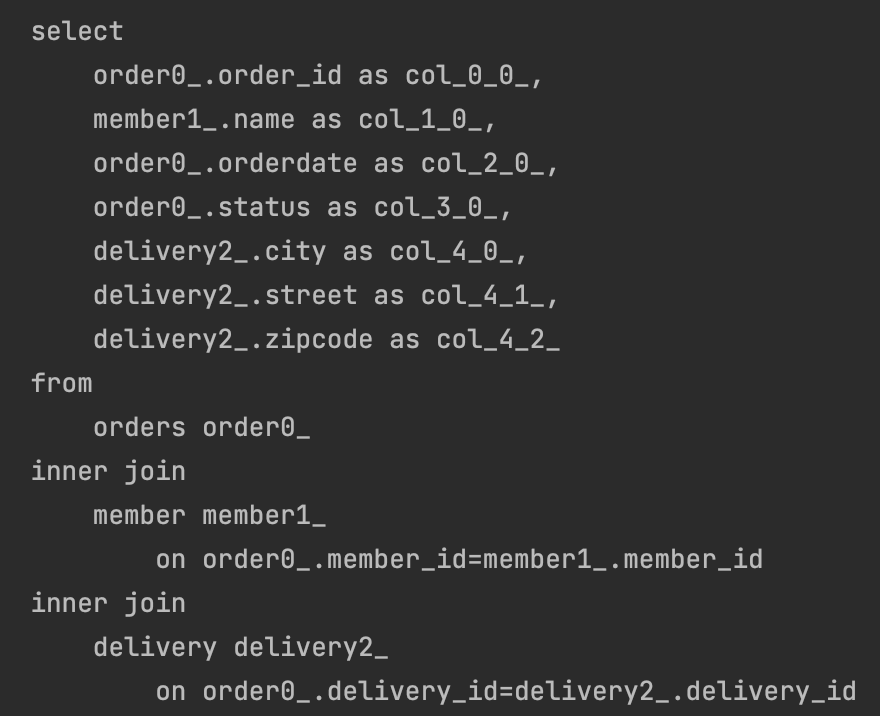
- 이렇게 필요한 컬럼만 SELECT 절에 포함시키는 것을 확인할 수 있다.
- 마치 DB에서 SQL로 데이터를 조회하듯이 필요한 필드만 골라서 가져올 수 있다.
V3 (엔티티 반환, Fetch Join) vs V4 (new DTO로 바로 반환)
- 언뜻 보면 필요한 컬럼들에 대해서만 쿼리를 작성하는 V4가 더 좋아보이지만, 꼭 그런건 아니다.
- V4가 확실히 조회 과정 자체에서 필요한 컬럼만 조회하다보니 성능 측면에서 좀 더 좋지만, 사실 큰 차이는 없다. (미비하다.)
- 보통 DB를 조회할 때 성능적으로 문제가 되는 원인은 Join이지, 컬럼 개수가 늘어나는 것은 전체적인 어플리케이션 관점에서 봤을 때 미비하다고 볼 수 있다.
- 보통 너무 많은 테이블을 join하거나, join 조건 컬럼에 인덱스가 적용되어 있지 않아 full-scan이 일어나거나 인덱스가 잘못 잡혀있거나 이러한 원인으로 인해 DB 조회 성능이 악화된다.
- 해당 부분에서 성능이 충분히 개선된 상태에서 컬럼 개수는 크게 문제되지 않는 경우가 많다.
- 보통 컬럼 개수가 많아서 문제가 되는 경우는 조회되는 데이터 수가 매우 많을 때 발생한다.
- 그리고 V4는 Repository에 정의된 메서드를 재활용하기에 까다롭다.
- 특정 Dto 전용으로 JPQL이 작성되기 때문에 해당 Dto를 활용하는 로직이 많으면 재사용 될 수 있겠지만, 그럴 일은 드물다.
- 따라서 다른 로직에서는 해당 메서드를 활용하기 어려워진다.
- 또한 V4는 JPQL을 통해 엔티티를 반환하는 것이 아닌, Dto의 생성자를 통해 Dto 객체를 만들어 반환하는 것이기 때문에 이후 수정, 삭제 등의 로직에 활용될 수 없다.
- 반면 V3는 엔티티 자체를 반환하기 때문에 재사용성이 보장된다. (다른 로직에서도 활용할 수 있다.)
- 또한 엔티티에 대한 수정, 삭제 등의 로직에 활용될 수 있다.
- 그리고 V4는 코드가 좀 지저분해진다. (앞에 package를 모두 써줘야하기 때문)
- 또한 V4 방식은 Repository가 API 스펙에 맞춰진 것이다.
- Repository는 DB로부터 엔티티를 조회하고 관리하는 용도로 한정되어야 한다.
- 특수한 경우를 제외하고는 다른 계층으로부터 영향을 받으면 안된다.
- V4 방식은 API 스펙이 Repository에 까지 영향을 미친 것이다.
- 따라서 V3 방식의 경우, API 스펙이 달라져도 Repository 로직에는 큰 영향이 없지만, V4 방식의 경우, 특정 API 스펙에 맞춰진 형태로 개발되었기 때문에 API 스펙이 바뀔 때마다 수정되어야 한다.
⇒ ⭐ 따라서 V3 방식으로 개발했을 때 얻을 수 있는 장점들(재사용성, Repository 독립 등)과 V4 방식으로 개발했을 때 얻을 수 있는 장점들(컬럼 개수 절감을 통한 성능 개선)을 비교해서 상황에 맞추어 적절히 활용해야 한다. ⭐
V4 방식 보완
- V4 방식으로 개발된 메서드끼리 모아두는 Repository 계층을 따로 두는 방식을 통해 V4 방식의 단점을 보완할 수 있다.
- 즉, repository 패키지 내에 추가 repository 패키지를 만들고, 그 내에 RepositoryImpl 파일을 만들어서 V4 방식 메서드들을 모아두는 것이다.
@Repository
@RequiredArgsConstructor
public class OrderSimpleQueryRepositoryImpl implements OrderSimpleQueryRepository {
private final EntityManager em;
@Override
public List<SimpleOrderQueryDto> findOrderDtos(OrderSearch orderSearch) {
return em.createQuery("SELECT "
+ "new jpabook.jpashop.domain.order.dao.dtorepository.SimpleOrderQueryDto(o.id, m.name, o.orderDate, o.status, d.address)"
+ " FROM Order o JOIN o.member m JOIN o.delivery d", SimpleOrderQueryDto.class)
.getResultList();
}
}- 따라서 본 repository 계층에는 엔티티를 관리하는 로직 메서드들만 모아두고, Dto로 직접 조회해서 API 스펙에 맞춰진 로직 메서드들은 또 다른 repository 계층에 모아두는 것이다.
정리
- 엔티티를 조회한 후에 DTO로 변환하거나(V3), DTO로 바로 조회하거나(V4) 두 방법은 각각 장단점이 있다.
- 둘 중 상황에 따라 더 적합한 방법을 선택하면 된다.
- V3는 Repository 재사용성도 좋고, 개발도 단순해진다.
- 권장하는 방식은 다음과 같다.
<쿼리 방식 선택 권장 순서>
- 우선 엔티티를 DTO로 변환하는 방식을 선택한다.
- 필요한 경우 Fetch Join으로 성능을 최적화한다. V3
- 대부분의 성능 이슈가 해결된다.
- 성능 개선이 더 필요한 경우 DTO로 직접 조회하는 방식을 사용한다. V4
- 그래도 성능 개선이 더 필요한 경우 최후의 방법으로 JPA가 제공하는 Native SQL이나 Spring JDBC Template을 사용해서 SQL을 직접 사용한다.
- 이 경우는 드물다!

경험과 기록으로 성장하기