출처
본 글은 인프런의 김영한님 강의 자바 ORM 표준 JPA 프로그래밍 - 기본편 을 수강하며 기록한 필기 내용을 정리한 글입니다.
-> 인프런
-> 자바 ORM 표준 JPA 프로그래밍 - 기본편 강의
0. 예시 설정
- 다음과 같은 구조를 예시로 설정한다.
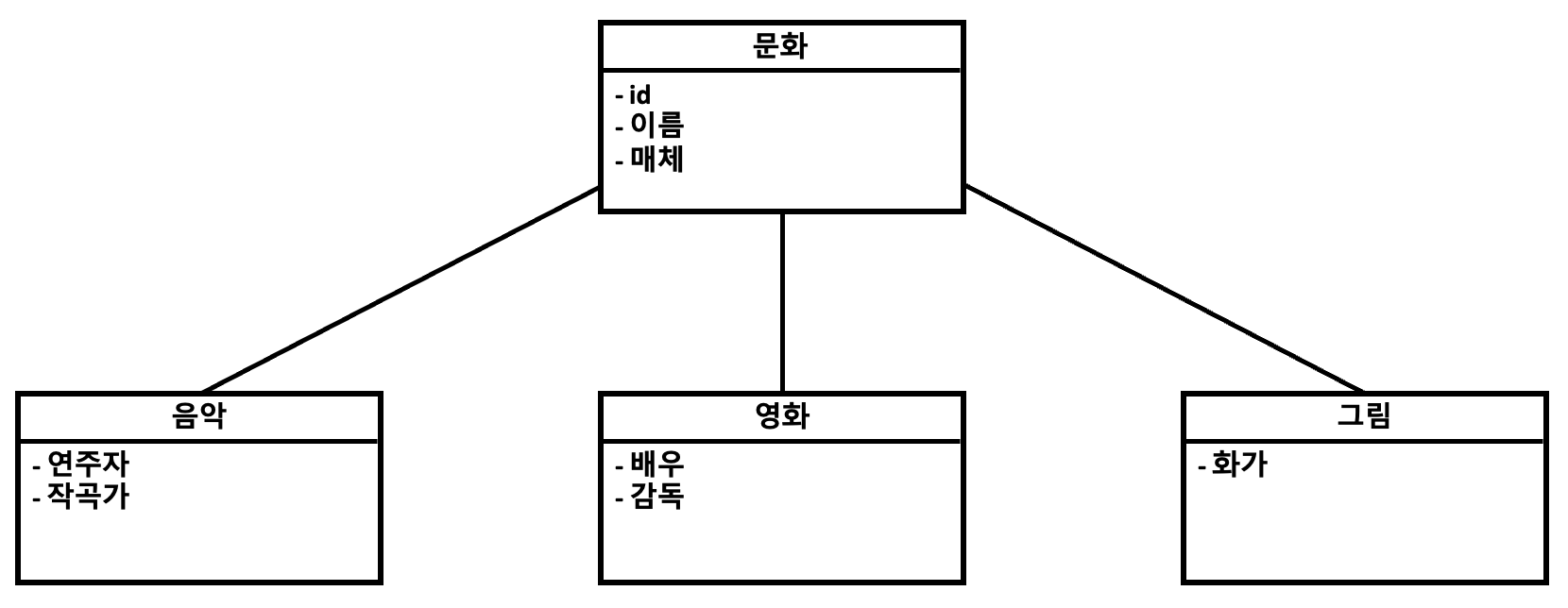
- 음악, 영화, 그림은 모두 문화의 일종이며, 각각 모두 이름과 매체를 갖는다.
- 하지만 각자 서로 다른 정보도 갖는다.
-> 음악 : 연주자, 작곡가
-> 영화 : 배우, 감독
-> 그림 : 화가
1. DB와 Java의 상속관계
- Java는 당연히 상속관계가 존재한다.
- 관계형 데이터베이스는 상속관계가 지원되지 않는다.
- 하지만 상속관계와 유사한 모델링 기법이 존재한다.
->슈퍼타입 - 서브타입 - 예시에서 음악, 영화, 그림은 모두 문화라는 큰 분류에 속한다.
- 큰 분류를 슈퍼타입, 작은 분류를 서브 타입으로 설정할 수 있다.
슈퍼타입 - 서브타입은 논리적으로 설계되는 모델이며, 이를 실제 DB 상에서 물리적으로 구현되는 방법에는 3가지가 있다.
-> 공통 필드 묶은 후 join
-> 하나의 테이블로 구현
-> 묶지 않고 각자 갖도록 구현- 상속관계 매핑은 Java의 상속 구조와 DB의 슈퍼타입-서브타입 관계를 매핑하는 것이다.
2. DB 상속관계 구현 전략
2-1. 공통 필드 묶은 후 join
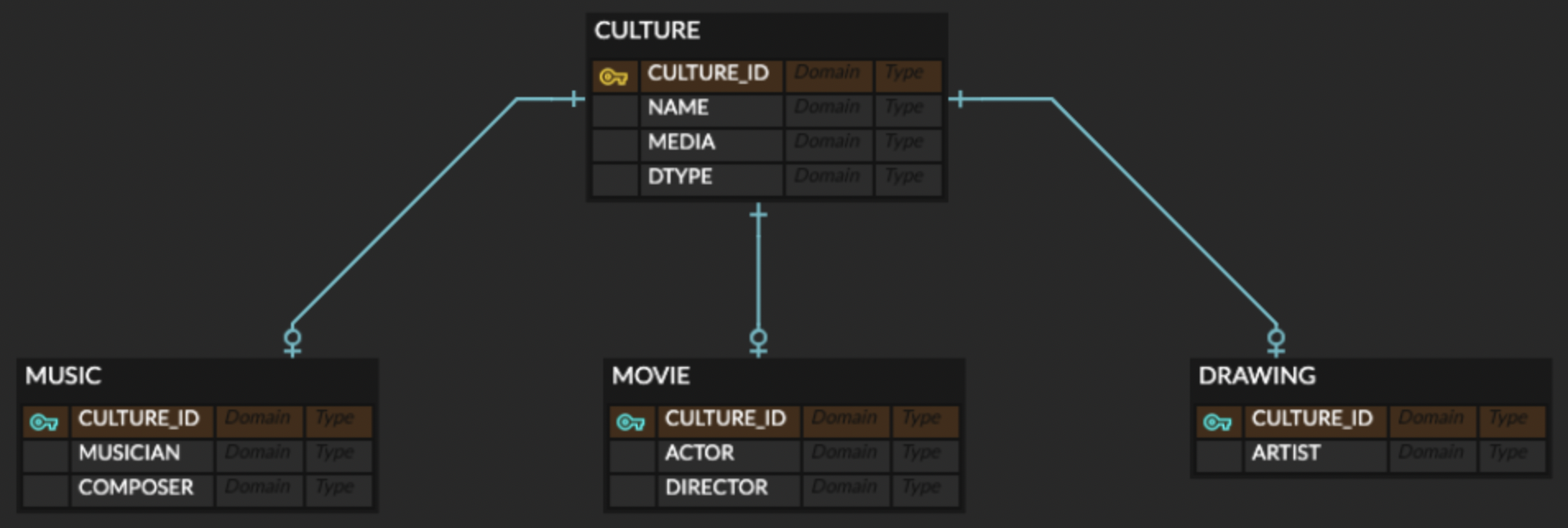
-> 노란색 열쇠모양 : PK
-> 파란색 열쇠모양 : PK, FK
- 본 전략은 위 사진과 같이 문화(CULTURE), 음악(MUSIC), 영화(MOVIE), 그림(DRAWING) 각각의 테이블을 모두 생성한 후, FK로 엮는다.
- 음악, 영화, 그림 테이블 각각은 모두 문화 테이블의 컬럼을 활용할 수 있어야 한다.
- 따라서 음악 테이블을 예로 들면, 본 전략은 다음과 같이 활용될 수 있다.
- 저장해야 하는 음악 정보 데이터 : 이름, 매체, 연주자, 작곡가
- 데이터 저장
- 연주자와 작곡가 데이터는 음악 테이블에, 이름과 매체 데이터는 문화 테이블에 저장하고 FK로 연결한다.
- 문화 테이블의 DTYPE 컬럼에 본 데이터가 음악 정보임을 저장한다.
(ex. "MUSIC")- 데이터 조회
- 음악 테이블의 FK 값을 통해 문화 테이블과 join하여 조회한다.
- DTYPE 컬럼 없이 FK 만으로도 데이터 CRUD가 가능하지만, 문화 테이블 관리를 위해 꼭 필요하다.
(DTYPE 컬럼이 없으면 문화 테이블만 봤을 때 저장된 많은 데이터들이 음악, 영화, 그림 중 어느 테이블에 해당하는 데이터인지 확인할 수 없다.)
2-2. 하나의 테이블로 구현
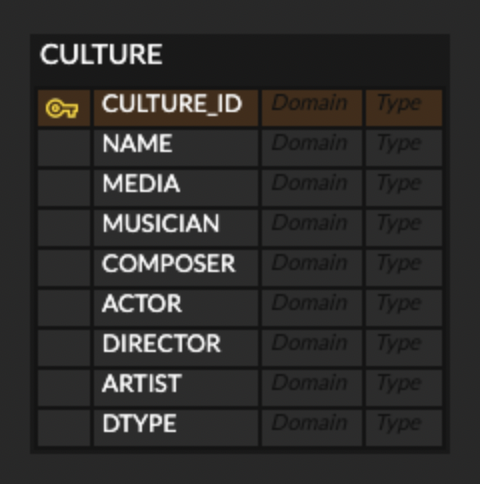
- 본 전략은 논리 모델을 아예 하나의 테이블로 통합시키는 방식이다.
- 문화, 음악, 영화, 그림을 각각 테이블로 나누어 관리하는 join 방식과 달리, 그냥 하나의 테이블에
다 때려 박아서관리하는 것이다. - DTYPE 컬럼을 통해 각 데이터들이 음악, 영화, 그림 중 어느 것에 해당하는지 구분한다.
2-3. 묶지 않고 각자 갖도록 구현

- 본 전략은
슈퍼타입에 해당하는 컬럼들이서브타입테이블에서 모두 중복되더라도 그냥 각자가 갖고 있는 방식이다.
3. 상속관계 매핑
2. DB 상속관계 구현 전략에서 다루었던 3가지 전략 모두 JPA 상에서 매핑할 수 있다.- 매핑 과정에서 다음 어노테이션들이 활용된다.
@Inheritance: 상속관계 매핑@DiscriminatorColumn: DTYPE 컬럼 관리@DiscriminatorValue: DTYPE에 저장되는 데이터 관리
- 매핑 과정에 앞서, JPA 상에서 먼저 다음과 같이 상속 관계를 설정해 둔다.
< Culture >
@Entity
public class Culture {
@Id @GeneratedValue
@Column(name = "CULTURE_ID")
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "MEDIA")
private String media;
}< Music >
@Entity
public class Music extends Culture {
@Column(name = "MUSICIAN")
private String musician;
@Column(name = "COMPOSER")
private String composer;
}< Movie >
@Entity
public class Movie extends Culture {
@Column(name = "ACTOR")
private String actor;
@Column(name = "DIRECTOR")
private String director;
}< Drawing >
@Entity
public class Drawing extends Culture {
@Column(name = "ARTIST")
private String artist;
}3-1. 공통 필드 묶은 후 join 방식 매핑
- 본 방식이 JPA의 상속 관계와 가장 유사한 구조로 데이터를 저장할 수 있다.
- 본 방식으로 매핑하기 위해서는 부모 클래스에 다음 두가지 어노테이션만 추가해 주면 된다.
@Inheritance(strategy = InheritanceType.JOINED)@DiscriminatorColumn
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn
public class Culture {
@Id @GeneratedValue
@Column(name = "CULTURE_ID")
private Long id;
@Column(name = "NAME")
private String name;
@Column(name = "MEDIA")
private String media;
}- 그럼 다음과 같이 DB가 구성된다. (H2 DB 활용)
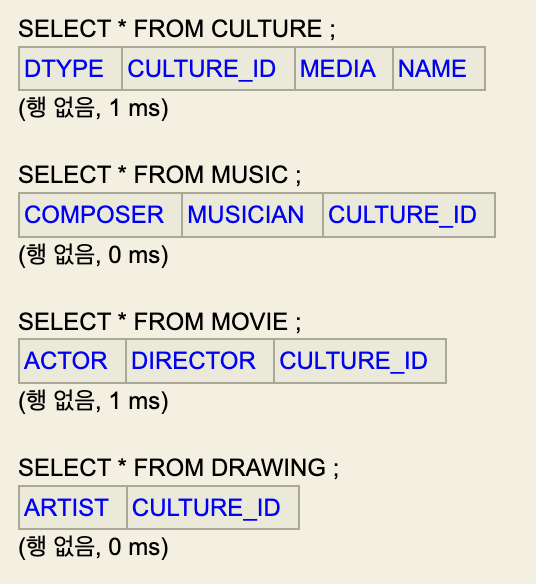
- 여기서 데이터를 한번 저장해 보자.
Music music = new Music();
music.setName("music1");
music.setMedia("Television");
music.setMusician("10cm");
music.setComposer("10cm");
entityManager.persist(music);
entityTransaction.commit();- 본 과정을 통해 저장하면 다음과 같이 CULTURE, MUSIC 테이블에 각각 1번씩 INSERT 쿼리가 전달되는 것을 확인할 수 있다.
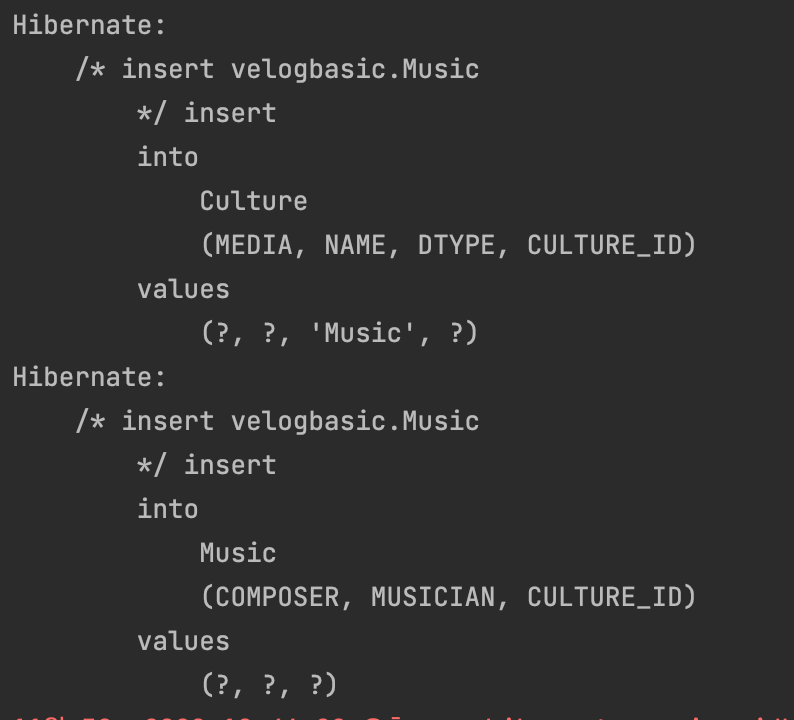
- DB에는 다음과 같이 저장된다.
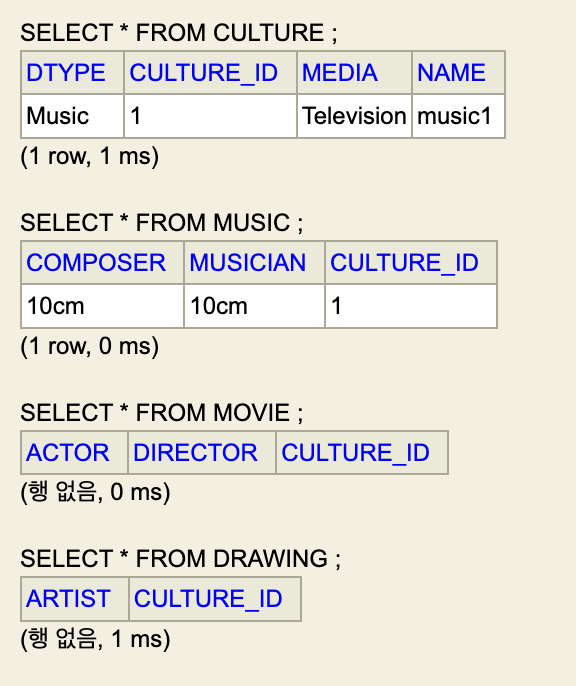
- 여기서 조회 과정도 해보자.
Music music = new Music();
music.setName("music1");
music.setMedia("Television");
music.setMusician("10cm");
music.setComposer("10cm");
entityManager.persist(music);
entityManager.flush();
entityManager.clear();
Music findMusic = entityManager.find(Music.class, music.getId());- 그럼 다음과 같이 CULTURE 테이블과 MUSIC 테이블을 join 하는 것을 확인할 수 있다.
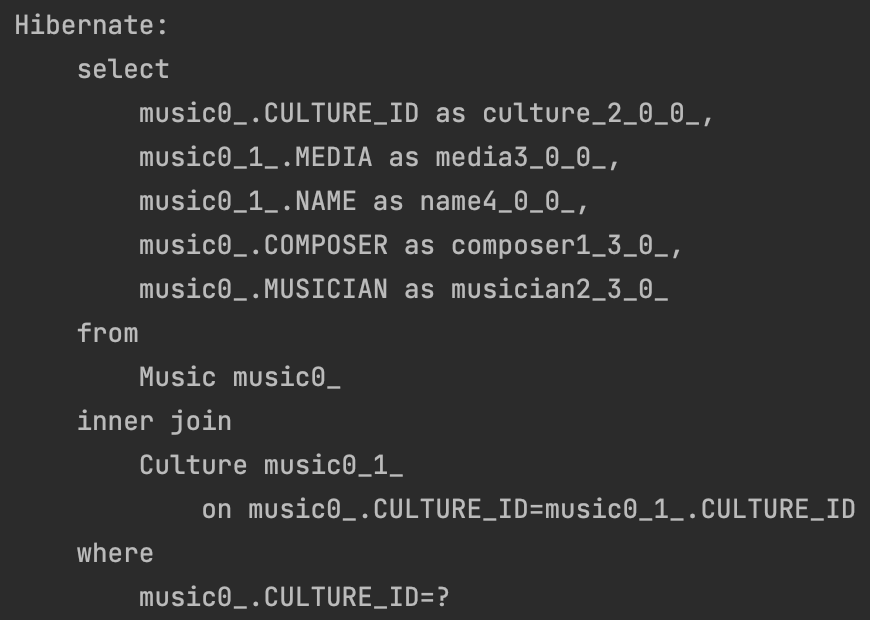
3-2. 하나의 테이블로 구현 방식 매핑
- JPA 상에서 그냥 상속관계만 만들어 두고 아무런 설정을 하지 않으면 하나의 테이블로 구현된다.
- 본 방식이 Default인 것.
- 직접 설정해 주는 방법은
3-1. 공통 필드 묶은 후 join 방식 매핑에서 부모 클래스의 어노테이션 내용만 바꿔주면 된다.
(이렇게 간단하게 DB 구조를 바꿔버릴 수 있다는게 놀랍다..!)@Inheritance(strategy = InheritanceType.SINGLE_TABLE)@DiscriminatorColumn
- 사실
@DiscriminatorColumn어노테이션은 생략해도 된다.- 하나의 테이블로 구현할 경우, DTYPE 컬럼은 필수라 어노테이션을 넣지 않아도 자동으로 추가된다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn
public class Culture {
...3-1. 공통 필드 묶은 후 join 방식 매핑에서 활용했던 main 코드를 그대로 돌려보면, 다음과 같이 CULTURE 테이블로만 동작하는 것을 확인할 수 있다.

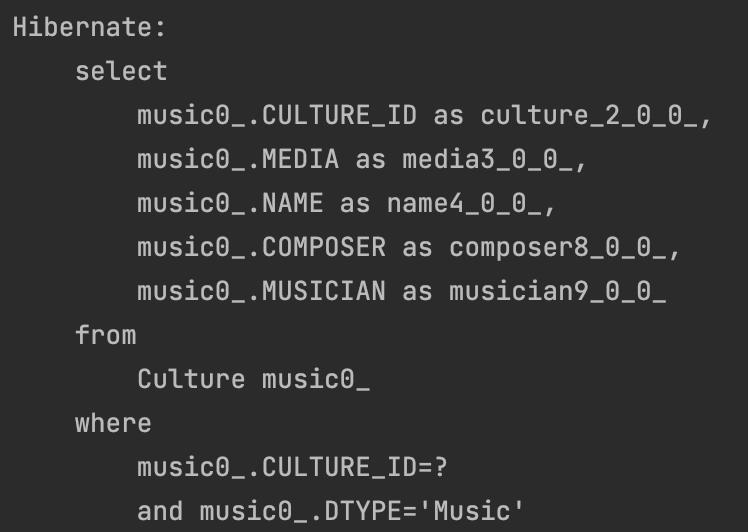
3-3. 묶지 않고 각자 갖도록 구현 방식 매핑
- 본 방식도 동일하게 어노테이션 내용만 바꿔주면 된다.
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)@DiscriminatorColumn제거- 어차피 본 방식은 DTYPE 컬럼이 필요없다.
@Entity
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
public class Culture {
...- 동일하게 음악 데이터 저장 및 조회를 해보면 다음과 같이 동작한다.


3-4. DTYPE 컬럼 설정
- 만약 DTYPE 컬럼명을 바꾸고 싶을 경우,
@DiscriminatorColumn어노테이션에 name 속성을 추가해 주면 된다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn(name = "CATEGORY")
public class Culture {
...- DTYPE 컬럼에 저장되는 데이터를 바꾸고 싶을 경우,
@DiscriminatorValue어노테이션을 자식 클래스에 적용하면 된다.
@Entity
@DiscriminatorValue("MUSIC_CATEGORY")
public class Music extends Culture {
...4. 장단점
- 우선
3-3. 묶지 않고 각자 갖도록 구현 방식 매핑방식은 최대한 쓰지 않도록 한다. - 그 이유는 다음 문제점 때문이다.
< 3-3 방법의 문제점 >
- 만약 음악, 영화, 그림 중 어느 데이터인지 모르는 상황에서 id값만 알고 있다고 가정해 보자
- 그렇다면 다음과 같이 코드를 짤 수 있다.
Culture findCulture = entityManager.find(Culture.class, id);- 그럼 여기에 다 못담을 만큼 무시무시한 쿼리가 나간다.
- MUSIC, MOVIE, DRAWING 싹다 UNION으로 묶어서 조회한다.
- id값만으로 찾아야 하기 때문에 음악, 영화, 그림 모든 테이블을 다 뒤져봐야 하기 때문이다.
- 즉, 부모 클래스가 갖는 필드의 정보만으로 찾으려 할 경우, 음악, 영화, 그림으로 특정되지 않아 결국 싹다 뒤지는 것이다.
- 그렇다면
3-1. 공통 필드 묶은 후 join 방식 매핑,3-2. 하나의 테이블로 구현 방식 매핑둘 중 하나를 활용하게 될 텐데, 각각의 장단점은 다음과 같다.
3-1. 공통 필드 묶은 후 join 방식 매핑장단점
- 장점
- 일단 본 방식이 가장 정석이라고 볼 수 있다.
- 테이블이 정규화 되어 있다.
- FK 참조 무결성 제약조건을 활용할 수 있다.
- CULTURE 테이블의 CULTURE_ID와 MUSIC 테이블의 CULTURE_ID가 동일한 값을 갖는다.
- 따라서 만약 MUSIC 데이터 중 CULTURE 테이블에 있는 데이터만 조회해야 할 경우, 다른 테이블들 볼 필요 없이 CULTURE 테이블에서 CULTURE_ID 값만으로 조회가 가능하다.
- 저장 공간의 효율화가 가능하다.
- 테이블이 정규화 되어 있으므로 저장 공간 활용 자체가 효율적이다.
- 단점
- 조회 과정에서 join이 많이 사용된다. 성능이 저하될 수 있다.
- 하지만 join도 잘 맞추면 성능이 저하되지 않고, 일단 저장공간에서 효율성을 가져가기 때문에 프로젝트 구조에 따라 성능이 더 좋아질 수도 있다. (큰 그림을 보자)
- 조회 쿼리가 복잡하다.
- 데이터 저장 과정에서 INSERT 쿼리가 2번 나간다.
- 슈퍼타입과 서브타입 테이블에 나눠서 저장해야 하므로
- 사실 하나의 테이블로 구현하는 방식에 비해 많이 복잡하다는 것 자체가 하나의 단점이 된다.
3-2. 하나의 테이블로 구현 방식 매핑장단점
- 장점
- join이 필요 없으므로, 일반적으로 조회 성능이 빠르다.
- 조회 쿼리가 단순하다.
- 단점
- 자식 엔티티가 매핑할 컬럼들은 모두 null이 허용되어야 한다.
- 만약 MUSIC 데이터가 저장되면, 나머지 MOVIE, DRAWING에 해당하는 컬럼들은 모두 null이 되어야 하므로.
- 이는 치명적인 단점이다.
- 하나의 테이블에 모든 데이터를 저장하기 때문에 테이블이 매우 커질 수 있고, 상황에 따라 조회 성능이 오히려 느려질 수 있다.
- 하지만 일반적으로는 성능이 빠르다.
- 상황에 따라 알맞은 방식을 활용하면 될 것 같다!

경험과 기록으로 성장하기