최근 진행했던 프로젝트의 API 개발 과정에서 데이터 조회 성능에 대한 고민을 했던 적이 있다.
그 때는 DB 반정규화, 인덱스 설정 등 DB 조회 성능만을 고려해 봤었는데, 최근 Redis를 활용한 Caching 개념을 접하게 되어 한번 적용해 보았다.
👉 DB 조회 성능 고민했던 기록
👉 SpringBoot Redis Caching 정리 기록
개선시켜 볼 API
우선 진행했던 프로젝트는 여행 플랜 생성을 도와주는 웹 서비스였고, SpringBoot, MySQL, MyBatis 기술이 활용되었다.
고민은 플랜 상세 정보 데이터를 조회하는 과정에서 시작되었다.
플랜 데이터를 저장하는 테이블 구조는 다음과 같았다.
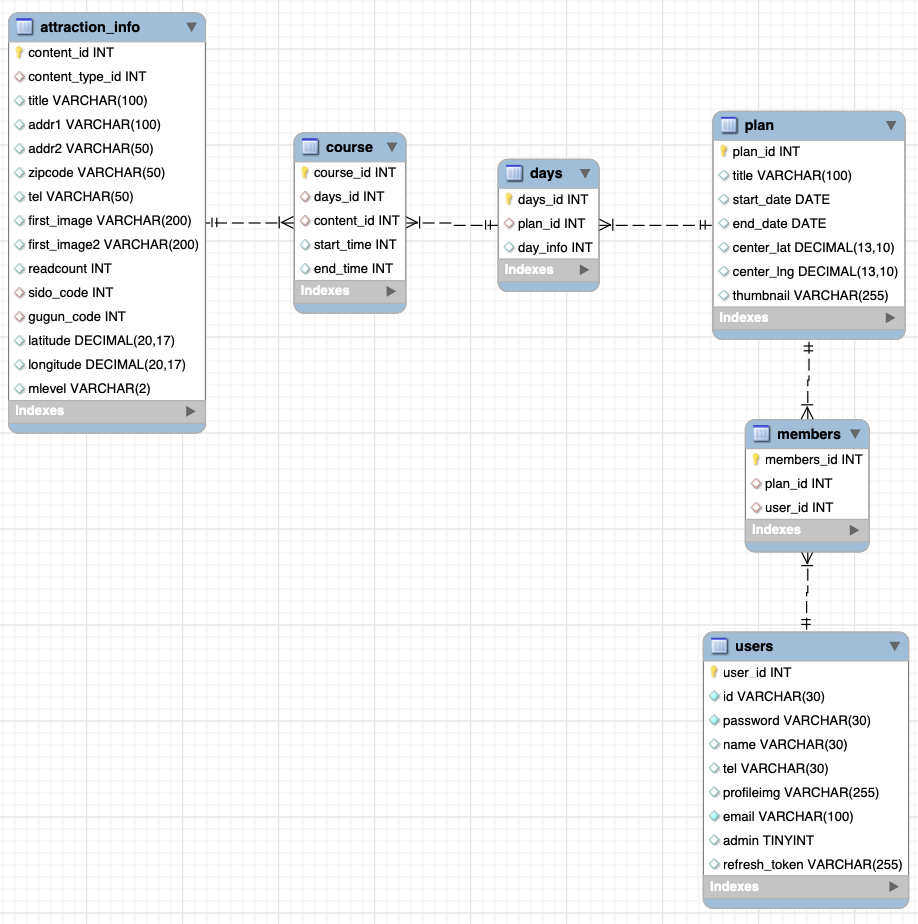
해당 테이블들은 다음과 같은 구조였다.
- 하나의 플랜을 생성할 때, 일자별로 코스를 설정할 수 있다. (1일차, 2일차, ...)
-> 플랜(plan)은 N개의 일자(days) 데이터를 가질 수 있다.- 하나의 일자 내에는 시간 별로 코스를 설정할 수 있다. (1~3시는 해운대, 4~5시는 광안리, ...)
-> 일자(days)는 N개의 코스(course) 데이터를 가질 수 있다.- 각 코스(
course)는 하나의 여행지 정보(attraction_info)를 가리키고, 시간 정보를 담고 있다. (start_time,end_time)
여기서 플랜 상세 정보를 조회할 때 dyas, course, attraction_info 3개의 테이블에 걸쳐 조회하게 된다.
MyBatis로 조금 급하게 개발하다보니 플랜 상세 정보 데이터를 조회할 때마다 DB로 쿼리가 줄줄 나갔었는데, Redis Caching을 접하고 해당 데이터들을 캐싱해보면 어떨까 생각되어 궁금한 마음에 적용해보게 되었다.
Redis Caching 적용
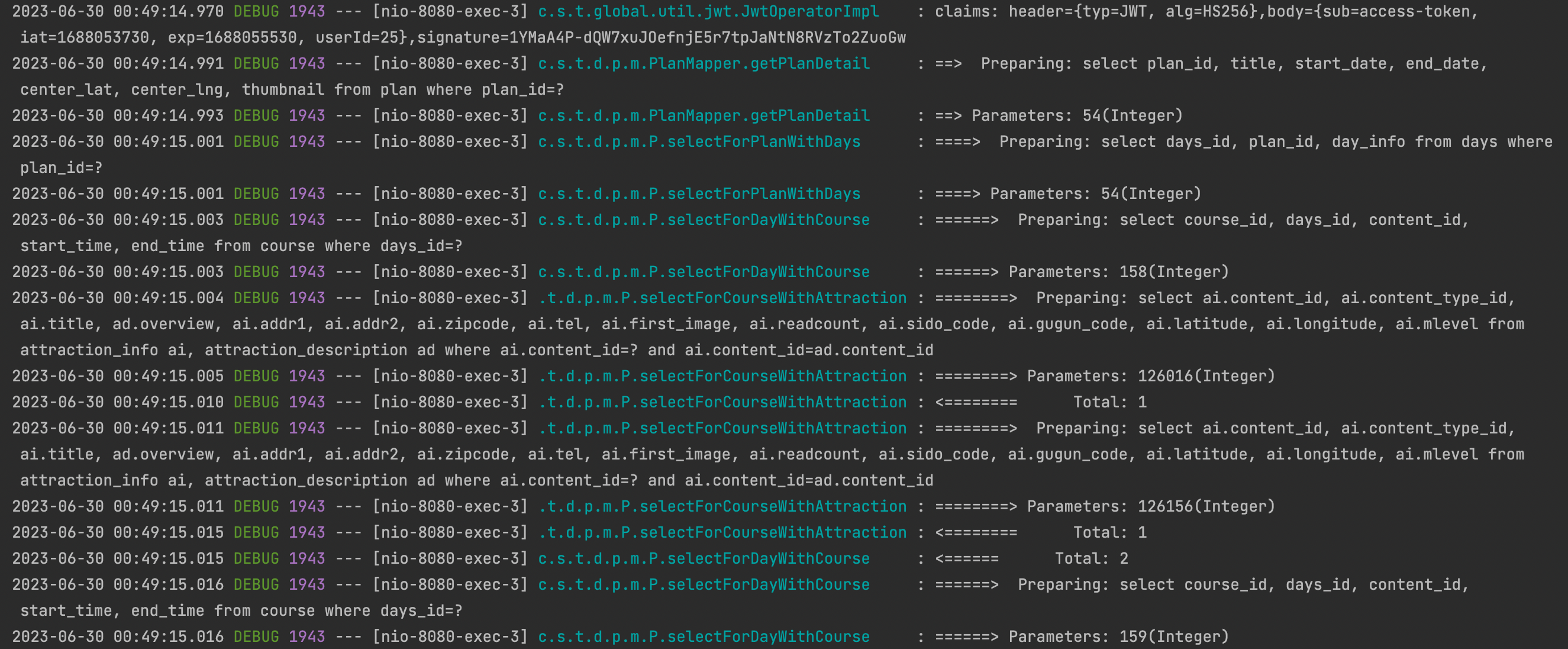
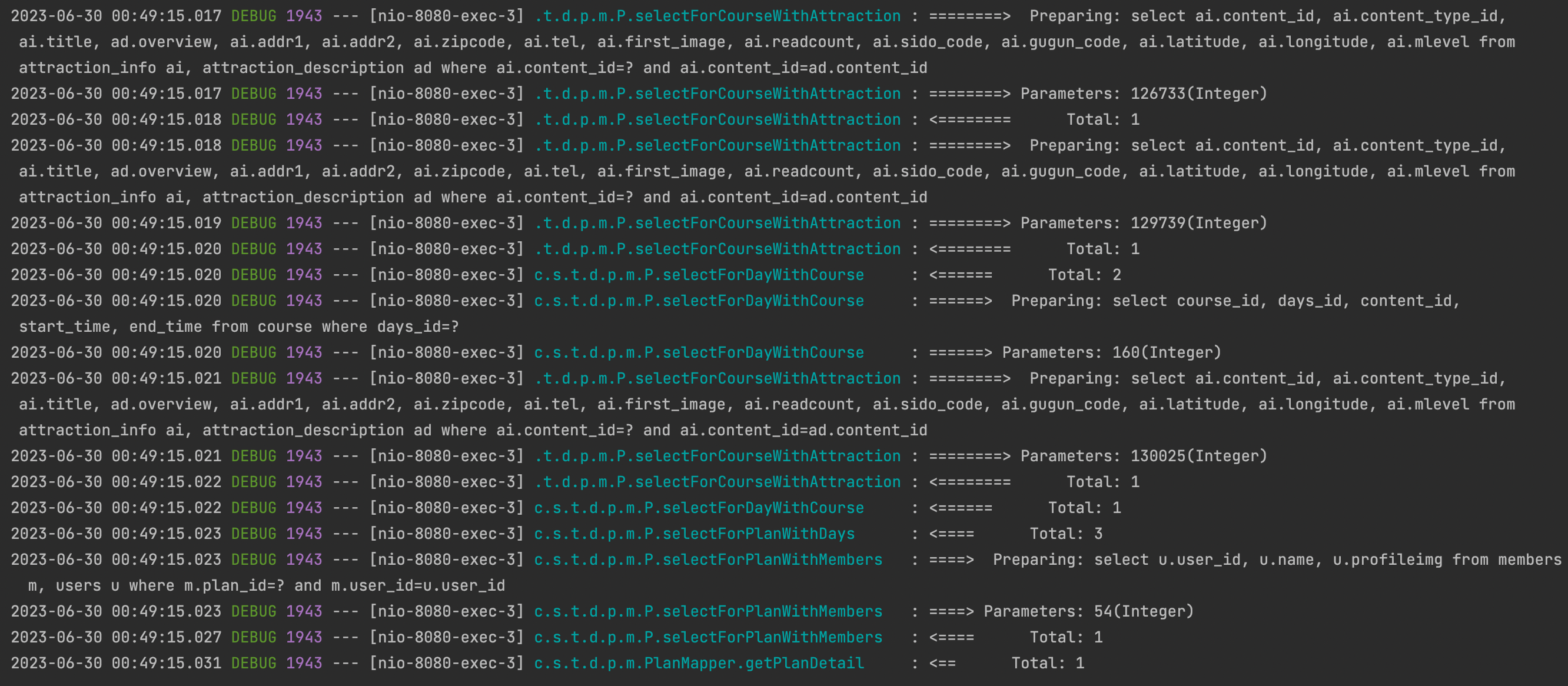
적용 전에는 다음 사진과 같이 조회할 때 쿼리가 줄줄이 나간다.
<플랜 데이터 쿼리 로그>
여기서 Redis Caching 기본 설정을 모두 적용하고 다음과 같이 플랜 조회 메서드에 @Cacheable 어노테이션을 적용했다.
@Override
@Transactional(readOnly = true)
@Cacheable(value = "Plan", key = "#planId", cacheManager = "cacheManager", unless = "#result == null")
public PlanDto getPlanDetail(int planId) throws Exception {
return planMapper.getPlanDetail(planId);
}그리고 다시 조회해보니 다음과 같이 쿼리가 하나도 안나가는 것을 확인할 수 있었다.
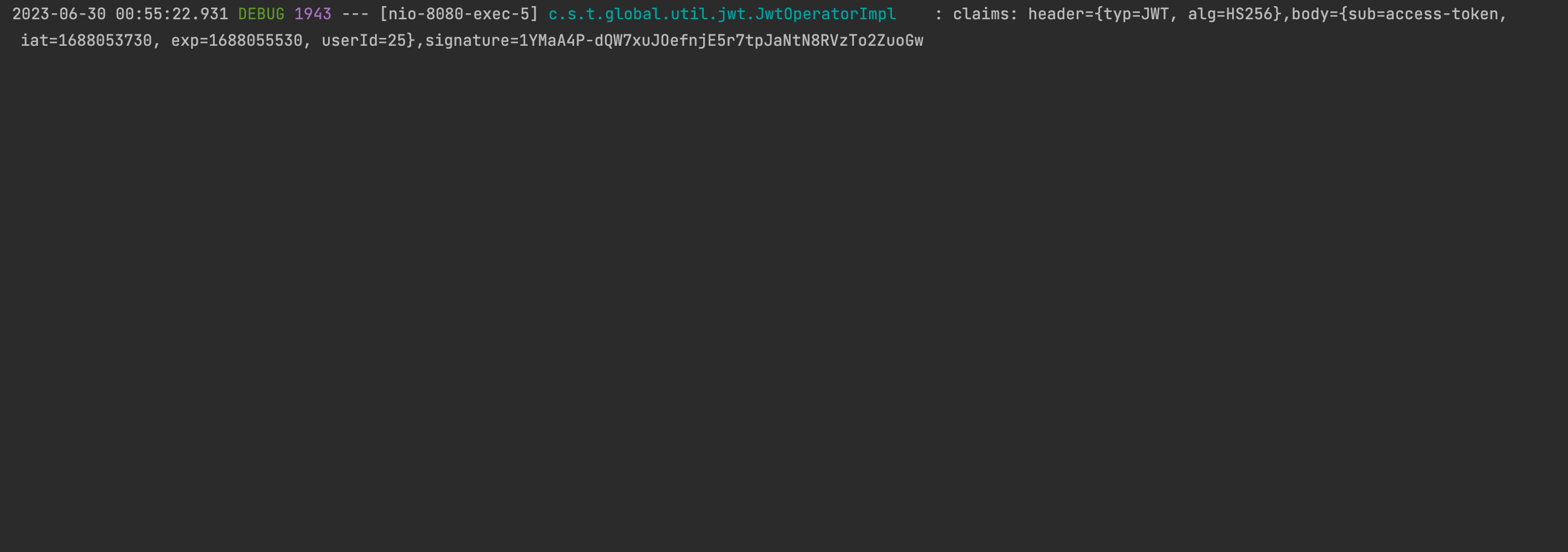
(깨끗하다..!!)
간단한 설정 조금과 어노테이션 하나 붙인 것만으로 하나의 API 응답을 위해 DB로 쿼리를 줄줄이 날리던 과정이 모두 사라졌다.
DB 커넥션 생성하고 쿼리보내고 조회하고 받아오고... 매번 이런 과정들을 수행하는 것이 아니라, 처음 조회할 때만 DB 조회하고 서버 메모리에 저장해놨다가 동일한 데이터 요청이 오면 그대로 반환해 주는 것이다.
이전에 개발할 때 계속 신경쓰였던 점이 설정 조금으로 사라지니 매우 신기했다.
본 글에서는 개인적인 호기심으로 비교적 쿼리가 많이 나가는 API에 대해서 적용해 보았지만, 실제 프로젝트에 적용할 때는 이전 글에서 정리했듯 캐싱를 적용할 데이터와 캐싱 전략에 대해 명확히 설정한 후에 활용해야 할 것이다.
이번에 간단하게 써봤으니 다음 프로젝트 때 제대로 적용해 보면 좋을 것 같다.
