
동기화
Dining Philosopher's Problem
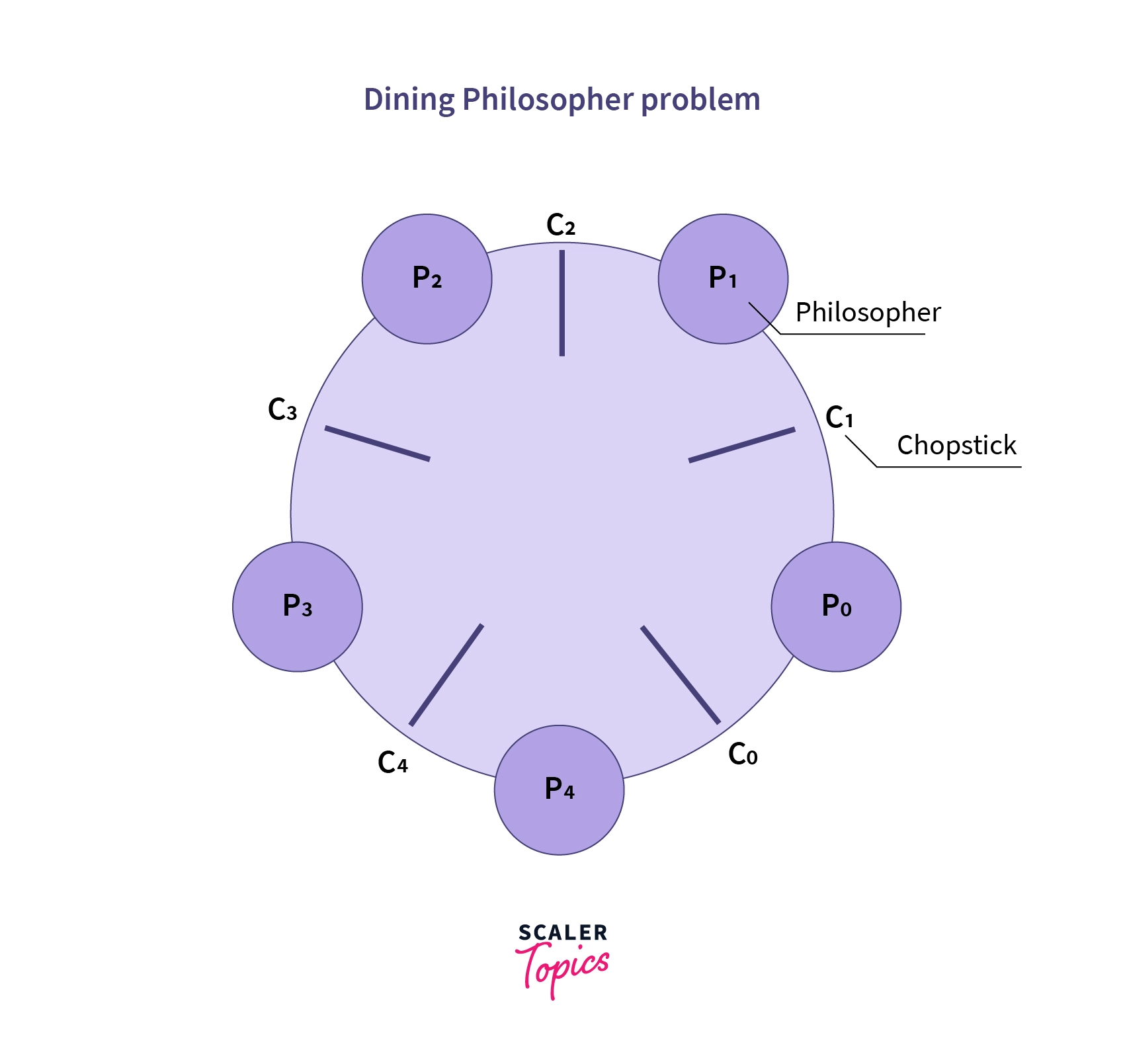
- 5명의 철학자가 한 식탁에서 함께 식사를 할 때 젓가락을 어떻게 들지 해결하는 문제
- deadlock, starvation 모두 발생 가능한 문제
- 자신의 바로 옆 젓가락만 집을 수 있다. 두 젓가락이 식사에 필요하다. 식사를 한 뒤에는 두 젓가락을 모두 내려놓는다.
Solution1
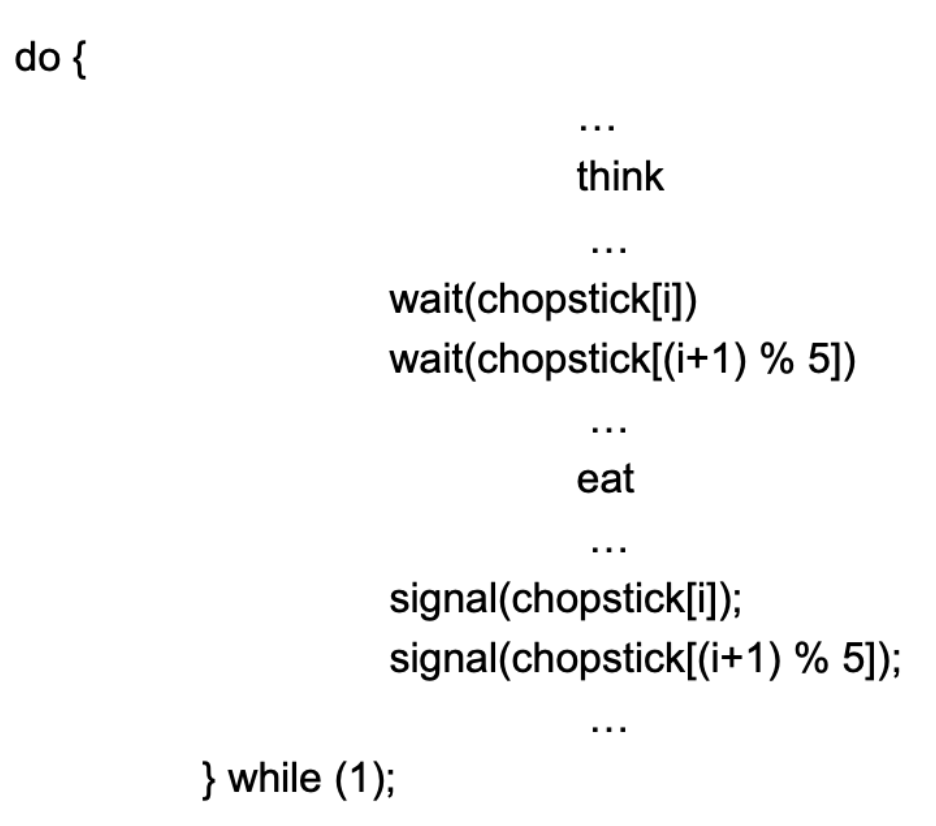
- 젓가락을 집을 때 동기화를 사용하기
- 자신의 왼쪽 또는 오른쪽을 집는다.
- Semaphore:
chopstick = [1, 1, 1, 1, 1]- 각 젓가락에 대한 동기화 조건 제공인덱스
i,i+1의 젓가락 사용 여부를 생각하는think, 사용 뒤에는 젓가락을 놓는eat이후의 시그널
Solutions for deadlock
- 한 번에 최대 4명만 식탁에 앉게 한다.
- 젓가락 상태를 미리 검사한다. 양 쪽의 젓가락이 모두 사용할 때에만 젓가락을 드는 게 허용된다.
- 철학자에게 번호를 부여, 홀수는 왼쪽, 짝수는 오른쪽을 먼저 집게 한다.
starvation은 해결할 수 없다. 각각의 방안에 대해서는 고려를 추가할 수도 있다. 한 차례 굶는다면 먼저 우선권을 준다거나 하는 방식!
Solution2
- 양쪽 젓가락을 '한 번에' 집는 방법
- Semaphore:
state - [THINK, HUNGRY, EATING] - mutex: 젓가락을 집거나 놓는 수행을 Critical Section으로 관리하기 위한 semaphore
- self[5]: 각각 젓가락 두 개를 집기를 원하는 철학자 semaphore.
self[i]는 곧 i번째 철학자가 배고픈 상태더라도 다른 젓가락 하나를 사용할 수 없을 때 대기하기 위한 자료구조

- Mutex를 통해 진입. test[i]를 통해서 양쪽의 상태를 검사하고 자신이 먹을 차례를 대기한다.
- Mutex를 통해 진입. test[left], test[right]를 통해 양쪽의 상태를 검사. 먹을 차례를 기다리는 철학자에게 시그널을 보내준다.
유한한 시간 동안 철학자는 기다리기 때문에 starvation을 해결할 수 있다!

3. Test를 수행한 철학자 i가 배가 고프고 양쪽 철학자 모두 젓가락을 집지 않았다면 take_chopsticks()에서 wait했던 세마포어 self[i]에 시그널을 보내어 먹는 상태로 진행한다.
동기화 알고리즘 고려 사항
- Data Consistency 확보
- Deadlock 발생 여부
- Starvation 가능성
- Concurrency 제공
global lock 사용 시 문제는 간단하게 풀린다!
Linux 동기화
- 스핀락:
busy waiting. P, V와 같이 사용된다. 스핀락을 잡으면 다른 프로세스는 사용 X
Memory Management
- 범용 컴퓨터 시스템: CPU 사용률 극대화, 멀티 프로그래밍. 동시 실행 스케줄링 기법 등장
- 메모리 관리: 여러 프로그램 동시 메모리 실행 → 메모리 공유 필요, 메모리는 매우 중요한 자원. 한정되어 있기 때문!
- 디스크 → 메모리 → 프로세스
- CPU → 메인 메모리 및 레지스터 직접 접근 가능
- 메모리 유닛: 주소 + 읽기 요청 / 주소 + 데이터, 쓰기 요청
- 레지스터: CPU 사이클 1개만에 접근 가능
- 메인 메모리 접근: 많은 사이클에 걸쳐 발생, stall 일으킴
- 캐시: 메인 메모리, CPU 레지스터 사이 위치
- 메모리 프로텍션: 올바른 연산을 보장하기 위해 사용됨
주소 공간
- 프로세스 참조 주소 범위
- 프로세스와 일 대 일 관계
- 사용자 스레드: 주소 공간 공유
- CPu 주소 버스 크기 의존
- 주소 버스가 32bit인 시스템에서의 주소 공간 크기 - (0 ~ 2^32 - 1)까지의 주소 범위 생성 및 접근 가능
여러 개의 주소 공간이 CPU 상에 적재되는 게 곧 "멀티 프로그래밍" 개념이다!
- 물리 주소: 실제 컴퓨터의 물리 메모리에 접근할 때 사용되는 주소
- 가상 주소: 물리 주소가 아닌 주소. 프로세스가 사용하는 주소. 필요에 따라 의미가 다르게 사용됨
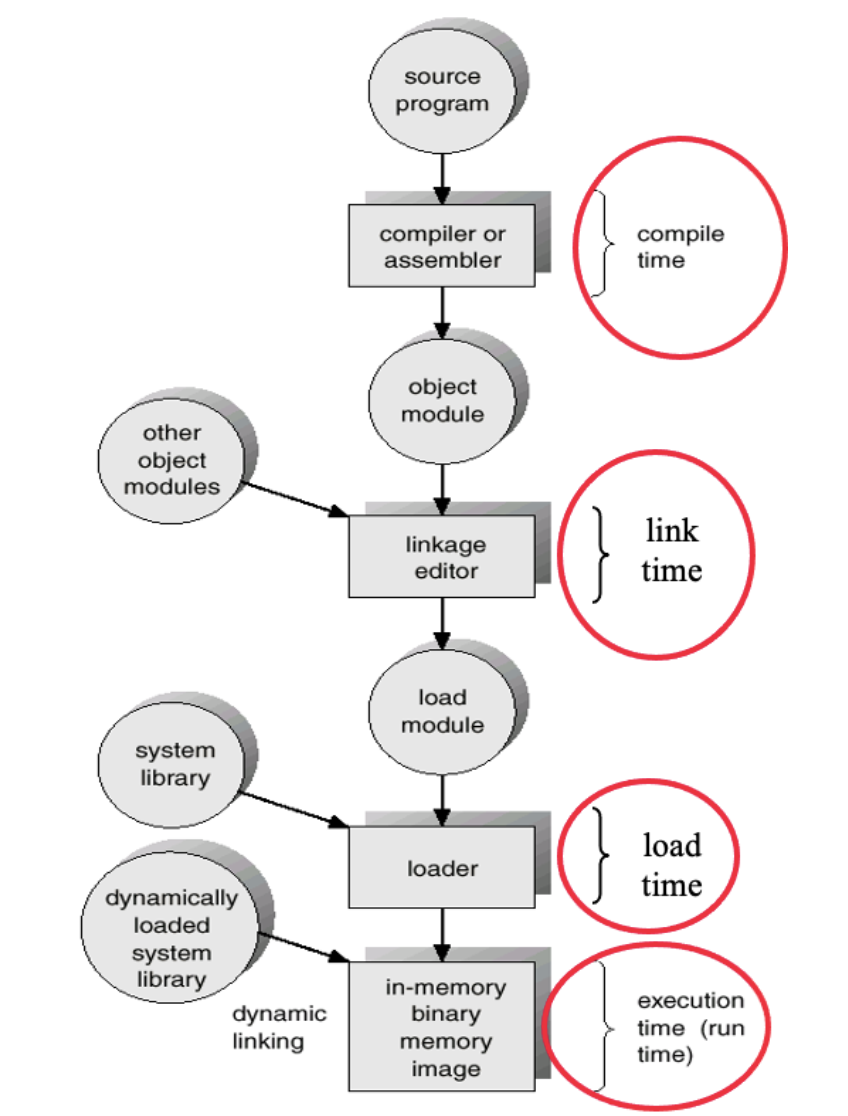
1. 컴파일
- 컴파일: 컴파일러가 심볼 테이블 생성, 주소는 심볼 테이블 상대적 주소로 구성된다. 컴파일한 오브젝트 파일은 주소 0부터 시작
- 컴파일 당시 물리주소를 생성, 프로그램과 매핑해버린다면 주소와 프로그램이 일 대 일 매칭이 되기 때문에 멀티 프로그래밍 불가능 → 시작 주소의 위치가 바뀐다면 다시 컴파일해버리는 비효율적인 사건 발생
컴파일 시간에 결정된 주소는 다른 프로그램과 함께 메모리에 적재하기 어려움. 가상 주소를 생성하기 시작.
2. 링크
- 링크: 오브젝트 파일 + 라이브러리를 통해 심볼 테이블에 의존적이지 않은 주소를 만들어내는 address resolution. 링크 결과로 하나의 실행 가능한 파일 생성 + 시작 주소는 0부터 시작. 즉 이
executable로 프로세스를 만들 때 주소 공간을 생성함
3. 로드
- 로드: 실제 메모리에 로드하는 바인딩 과정.
- 주소 공간 전체가 메모리에 올라간다면, 로드 시에 물리 주소에 대한 바인딩 발생.
executable은relocatable주소로 되어 있기 때문에 베이스 레지스터를 통해서 물리 주소로 변환해야 함. 가상 주소에 물리 주소가 매핑.
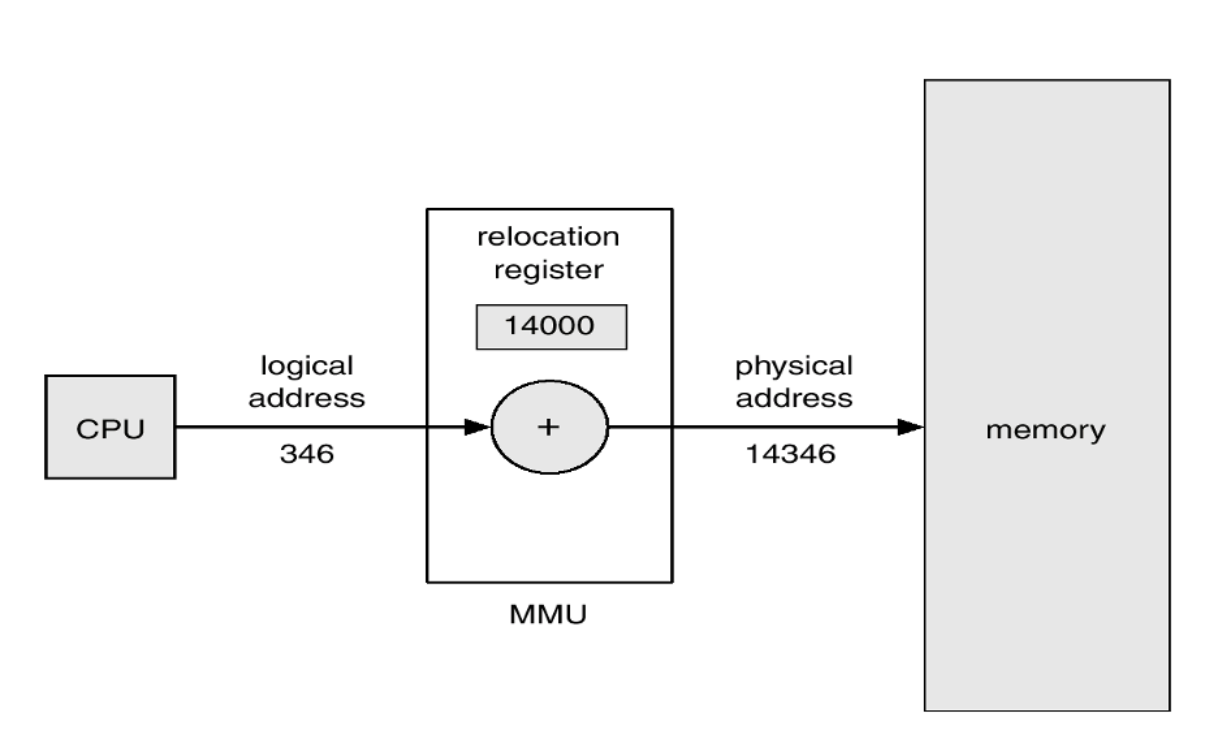
- 링킹 중 가상 주소 346 할당 + 재할당 레지스터에서 14000 주솟값 생성 + 물리 메모리에 두 값을 더한 14346 할당
relocation register가 현재 MMU 프로세서로 합쳐지게 되었기 때문에, 지금은 사용하지 않는다!
4. 실행
- 프로세스가 실행될 때 물리 주소를 바꾸는 게 가능함:
paging을 통해 가상 주소가 바뀔 수 있기 때문 - 동적 주소 변경이 가능:
Address translation
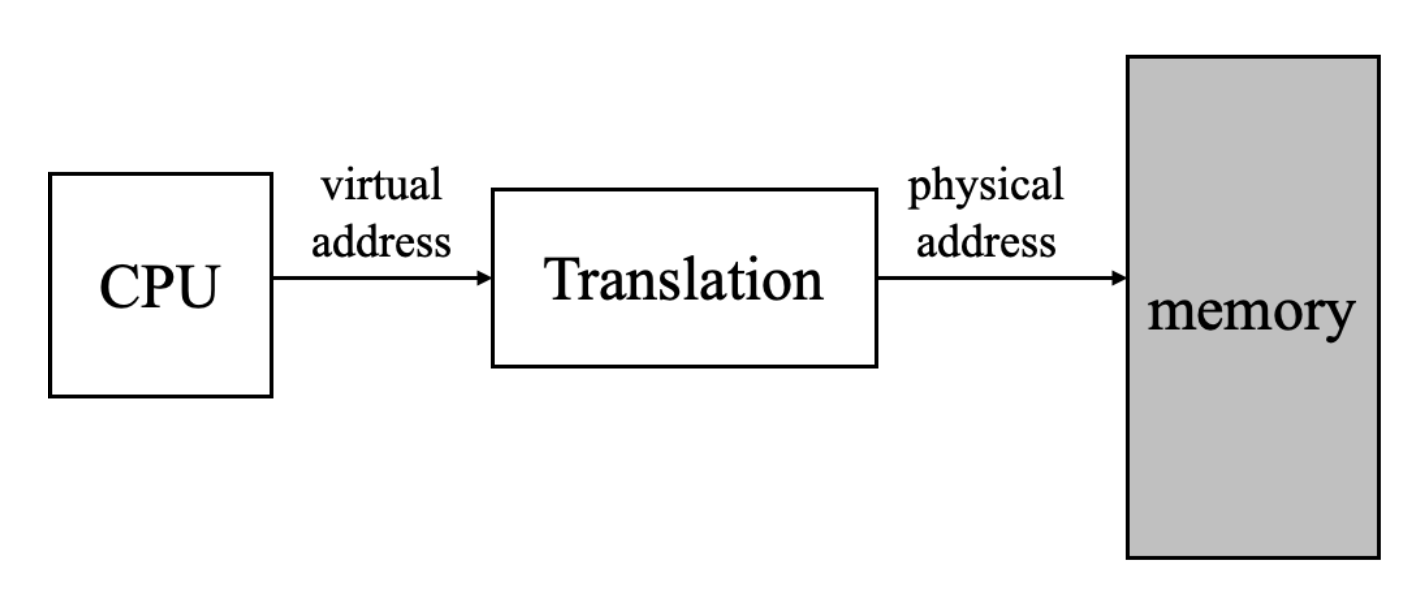
- translation을 통해 CPU가 전달한 가상 주소를 물리 주소에 매핑하는 과정
프로세스가 실행되는 과정에서 실행 주소를 매핑하기 때문에
translation이 이루어지는 속도가 전체 프로그램 실행 속도와 직결된다! 따라서 이후 MMU를 통해 실행된다.
가상 주소 공간
- 프로세스가 메모리에 적재되는 방법을 보여주는 논리적 뷰(주소 0번부터 시작, 마지막 공간까지 연속적인 주솟값으로 이루어짐) MMU는 논리 주소를 물리 주소에 매핑함
- 유저 프로그램은 논리적 주소를 다루고, 물리적 주소는 보지 않는다.
- 실행 시간의 바인딩 과정은 메모리 내 참조가 일어날 때 발생한다. 즉 논리적 주소가 물리적 주소에 매핑된다.
- 가상 메모리는 페이징 및 세그멘테이션을 요청할 때 실행된다.
MMU
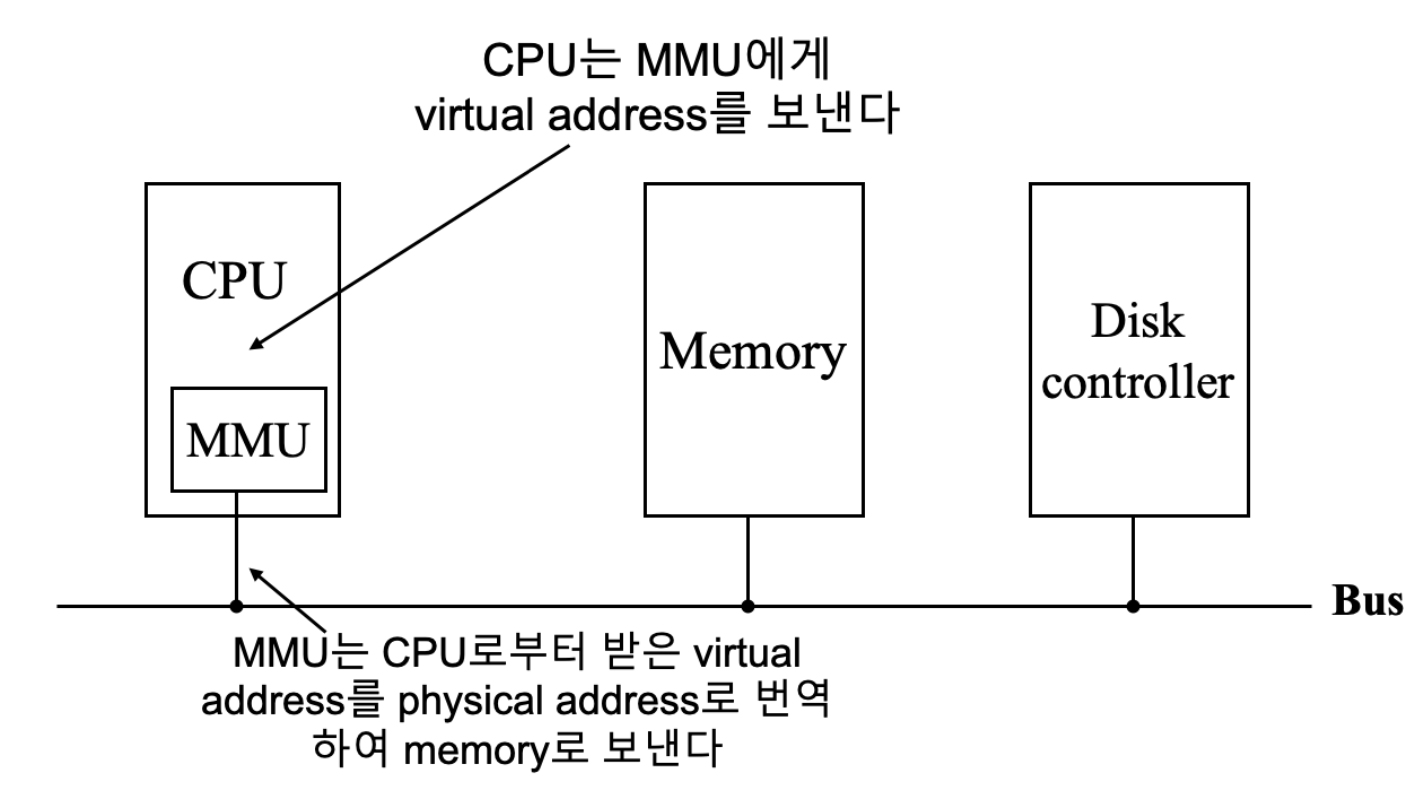
- 가상 주소 - 물리 주소 간의 메모리 매핑을 실행하는 별도의 HW
- CPU가 담당하는 메모리 관리의 부담을 MMU가 떠맡기 때문에 오버헤드 감소
DMA라는 별도의 HW를 통해 polling, interrupt의 한계를 극복했던 것처럼 MMU라는 별도의 HW를 사용한다!

JUST DO IT