
1. 컴퓨터 구조
- HW, OS, 어플리케이션 프로그램, 사용자
1. Single bus-based architecture
- 시스템 버스는 1개
- 여러 주변 기기를 연결하는 형태 → CPU, 메모리, I/O 속도가 비슷하다면 문제 없이 정보 전송 가능
- 병목 현상(Bottleneck): CPU의 속도 ↔️ I/O 속도 차이, 전체 속도는 I/O의 속도(최저 속도)로 제한되는 현상
2. Double bus-based architecture
- 보틀넥 해결: I/O 버스를 하나 더 연결
3. North and South-bridges
- 빠른 속도의 기기를 제어하는 North ↔️ 느린 속도의 기기를 제어하는 South
Memory Hierarchy
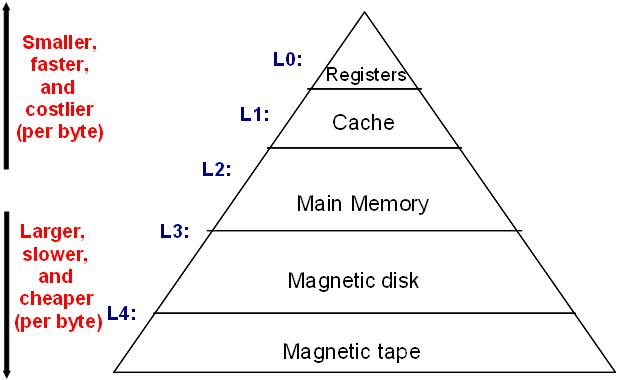
"경제적" 이유로 모든 장치에 레지스터를 달 순 없다!
- 데이터 이동 경로: 하드 디스크 → 메모리 → 캐시 → 레지스터
- 레지스터: 인스트럭션/데이터를 저장하기 위해 I/O에도 저장되는 레지스터
2. 컴퓨터 시스템 내 OS 컨셉
1. 유저 모드 ↔️ 커널 모드
- CPU의 두 가지 실행 모드: 시스템 보호용
- 권한에 따라 접근 가능한 메모리 및 명령어 제한, 권한(Privilege) 설정
커널 모드
- 모든 권한의 실행 모드
- OS가 실행되는 모드
- Privilege 명령 O + 레지스터 접근 O
유저 모드
- 낮은 권한의 실행 모드
- 어플리케이션이 실행되는 모드
- Privilege 명령 X
Execution mode switch
- 실행 모드 전환이 발생하는 스위칭 현상
- 실행 권한이 없는 어플리케이션이 실행 권한을 필요로 하는 작업 요구 → 실행 권한이 있는 모드로 변경, 즉 커널 모드로 들어가기 위한 시스템 콜 호출
2. Trap
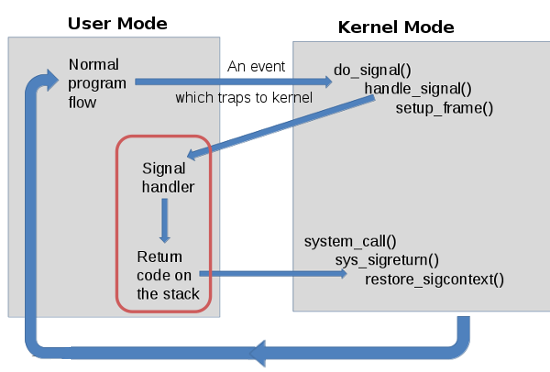
- 동기적 이벤트(Divide by zero 등 프로그램 에러) 처리 기법
- 현재 동작 중인 작업 → 실행 상태를 저장/복원 X
3. Interrupt
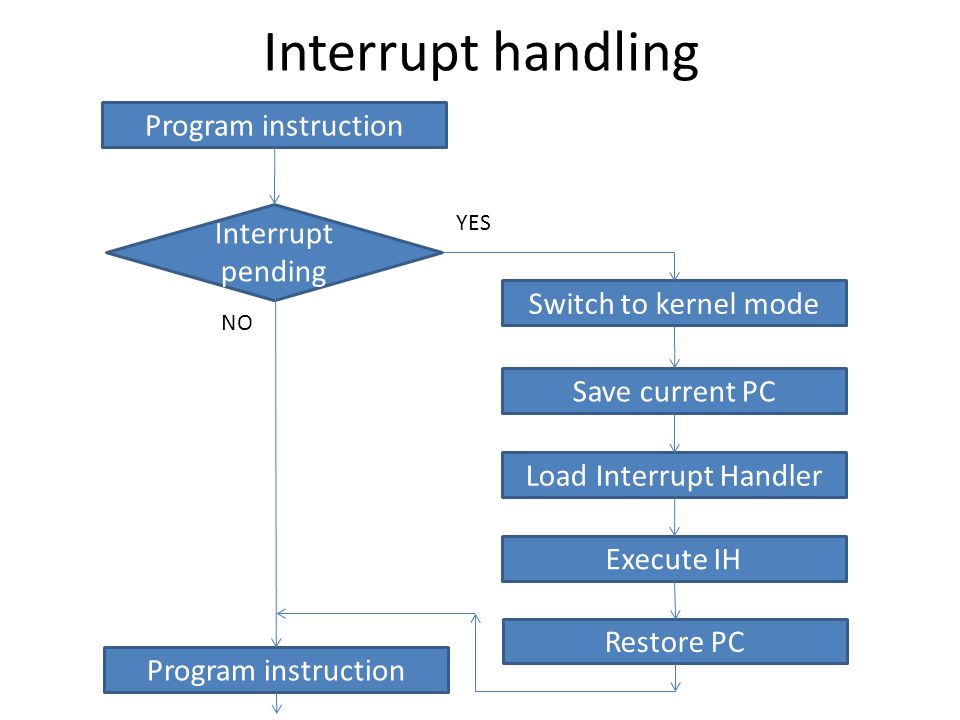
- 비동기적 이벤트(네트워크 패킷 도착, I/O 요청 등) 처리 기법
- 현재 실행 상태 저장 → ISR 점프 → 저장한 상태 복원 → 인터럽트로 중단한 시점부터 다시 복원
- 우선순위가 있는 인터럽트는 이미 OS 내부적으로 어떻게 처리하는지 루틴이 존재
- 짧은 ISR을 통해 다른 인터럽트가 너무 길게 지연되지 않도록 함
- Timesharing 기법: 타이머 인터럽트를 통해 가능
3. I/O 디바이스
- 버스: 데이터 전송 통로
- 디바이스 레지스터: 메인 메모리에 매핑된 레지스터를 통해 빠른 속도로 CPU 접근
- 컨트롤러: I/O 요청을 담당, 장치와 직접 상호작용
1. I/O 접근 방법
1. I/O Instructions
- I/O 기기를 담당하기 위한 별도의 인스트럭션 존재
- 컨트롤러 레지스터 → 데이터, 컨트롤 시그널 관리, 비트 패턴으로 작성 및 통신 → 명령어 제공, CPU와 통신
2. Memory-mapped I/O
- 장치 레지스터 → 시스템 메모리 공간 매핑(주소 공간의 일부화)
- CPU와 일반적 명령어를 통해 I/O 작업 수행
2. I/O 요청 처리 방법
1. Polling
- Programmed I/O - PIO
- loop, time-delayed loop 내 특정한 이벤트가 도착했는지 체크(매 순간 이벤트가 발생했는지를 확인해야 함)
- I/O 작업이 끝났는지 곧바로 확인 및 처리 가능
- 이벤트가 도착하는 시간이 길다면 CPU 낭비
2. Interrupt
- I/O 요청 후 CPU는 작업 수행 → I/O 종료 메시지를 장치로부터 수신 → ISR 수행 → I/O 종료 작업 수행
- CPU 활용도가 Polling보다 높음
- I/O 작업 바로 확인 불가능
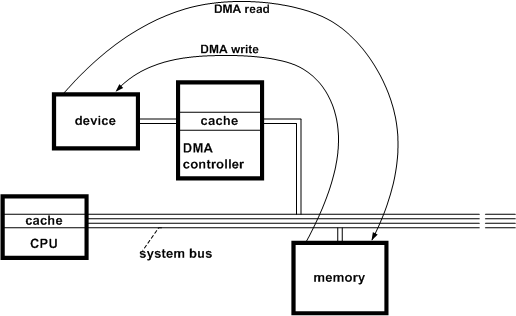
3. DMA
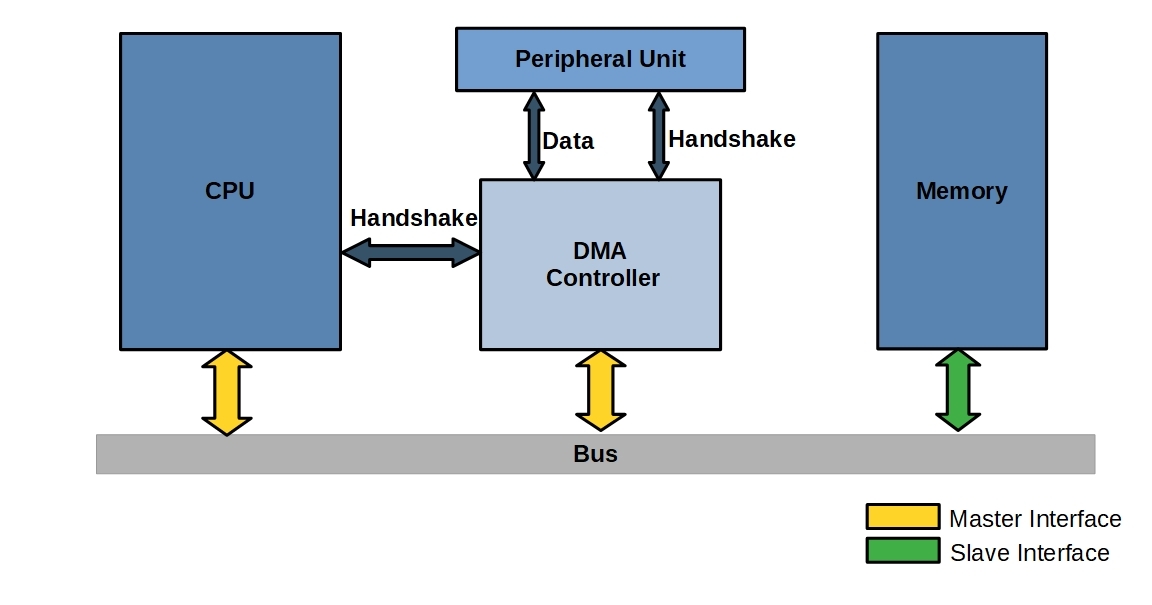
- Polling, Interrupt 간의 trade-off 존재: CPU 활용도 이슈 + 결국 데이터 전송이 CPU에 의해 이루어짐
- 데이터가 크다면 CPU가 데이터 전송 행위에 사용되면 낭비
"I/O 요청만을 처리하는 프로세서"를 따로 만들자!
- 메모리 → I/O 장치로 데이터를 직접 전송하는 HW - DMA Controller
- DMA Controller + CPU 동시 사용: CPU 활용도 상승
- 추가적인 HW - 비용 증가
- ISR로 인한 약간의 속도 이슈
- 적절한 병렬성(parallelism) + DMA 작업 중 CPU 활용률이 높아야 함
DMA read process
- DMA 컨트롤러 초기화, 전송모드 Read
- 버퍼의 주소 + 크기 → DMA 컨트롤러
- DMA 컨트롤러 → 디스크 컨트롤러 데이터 read 요청
- 디스크 컨트롤러 → 바이트 단위 read 데이터를 DMA 컨트롤러에게 전송
- DMA 컨트롤러 → 전송 데이터를 버퍼 주소 기록 / 크기 0까지 감소시키면서 모든 데이터 전송
- DMA 컨트롤러 → 인터럽트 → CPU에게 전송 완료 체크
DMA write process
- DMA 컨트롤러 초기화, 전송모드 Write
- 버퍼의 주소 + 크기 → DMA 컨트롤러
- DMA 컨트롤러 → 디스크 컨트롤러 데이터 write 요청
- DMA 컨트롤러 → 바이트 단위 write 데이터를 디스크 컨트롤러에게 전송
- DMA 컨트롤러 → 전송 데이터를 버퍼 주소 기록 / 크기 0까지 감소시키면서 모든 데이터 전송
- DMA 컨트롤러 → 인터럽트 → CPU에게 전송 완료 체크
DMA 컨트롤러가 디스크와 CPU 사이에서 데이터를 읽고/쓰는 작업을 중재한다!

JUST DO IT