
- HW를 효율적으로 사용할 수 있는 추상화 기법 제공
- 추상화: 실제로는 존재 X, 잘 사용하기 위한 자료구조 제공
- CPU - 프로세스, 메모리 - 주소 공간, 네트워크 - 포트, 디스크 - 파일
- 자원 공유/분배 정책: FIFO, LRU 등, 디자인 결정 필요(디바이스마다 서로 다른 정책)
각 HW가 어떤 abstraction을 "왜" 가지는지 생각해보자!
1. OS - HW
1. CPU
- 연산 담당 HW
- 인스트럭션 → CPU가 연산하는 명령어
- 레지스터: CPU 내 다목적 저장공간, 데이터 + 명령어 저장(현재 수행 중인 데이터)
- 캐시: 메모리와 CPU 처리 속도 차이를 최소화하기 위한 고속 저장 공간(현재 또는 추후 사용되는 데이터 저장)
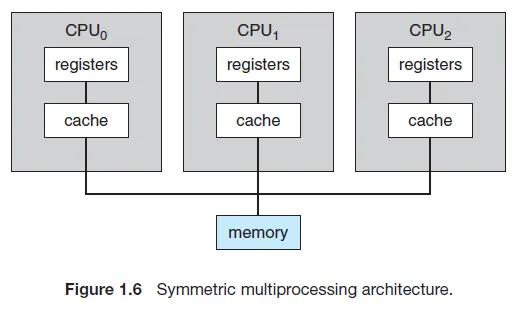
- 멀티 프로세서 디자인
- 메인 메모리에서 각 CPU의 캐시에 접근 가능
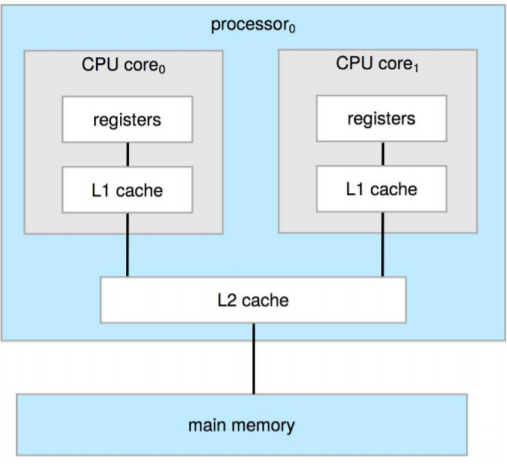
- 듀얼 코어 디자인: 각 L1 캐시는 각 코어 0 또는 코어 1만 사용 가능, L2 캐시는 메인 메모리에서 접근하기 때문에 L1 캐시 모두 접근 가능
- 코어: 하나의 프로세서 내 연산을 담당하는 서로 다른 CPU의 장치, 별도로 레지스터 및 캐시 존재
멀티 프로세서와 듀얼 코어 디자인이 물리적으로 아예 다른 게 아니다! 멀티 프로세서 내에서도 듀얼 코어가 사용될 수도 있다!
- 디자인 구조가 아니라 CPU 사이클에 따라서 연산 속도가 결정된다. 위 디자인 구조는 CPU 사이클을 통한 연산 처리와 함께 부수적으로 연산 처리 효과를 높임
2. 메모리
- 메인 메모리, RAM: 컴퓨터 종료 시 저장된 데이터 소멸
3. 네트워크
- 두 개 이상의 시스템이 통신하는 E2E
- TCP/IP 등 프로토콜, 네트워크 어댑터, SW 등 필요
- 추상화된 네트워크 레이어 사용(어플리케이션, 전송, 네트워크, 링크 레이어 등)
4. 디스크
- 비휘발성 메모리: 하드 디스크, 지속적으로 보관할 데이터
- HDD(기계적, 낮은 속도), SSD(전자적, 빠른 속도)
2. OS - Abstraction
1. 프로세스
- 프로그램: 명령어 모음, 바이너리 형태 저장
- 프로세스: 실행 중인 프로그램의 추상화 단계, PC, 스택, 데이터 등 포함
- 주소 공간: 프로세스가 차지하는 메모리 공간 - 각 프로세스는 상대방의 주소 공간을 침범할 수 없음(protection domain)
2. 주소 공간
- 주소: 메모리 공간, 1 바이트마다 1씩 증가 → CPU가 주소 공간을 참조해서 데이터를 가져옴
3. 포트
- 네트워크를 사용하기 위한 추상화 단계
- E2E 통신을 위한 endpoint
4. 파일
- 프로세스가 read/write 가능한 비휘발성 메모리
- 바이트의 연속 배열: 다차원 X, 중간에 비어 있지 않은 상태(not sparse), 바이트 단위 주소 공간 접근 가능(물리적 메모리가 word 단위 정렬되어 있다 하더라도 파일은 1바이트 단위) ↔️ 주소 공간은 sparse
- 주소 공간, 파일: 모두 프로세스 간 공유 가능
- 주소 공간: 자식 프로세스를 통해서도 공유 가능, 메모리 공간이 동적으로 할당 가능 → 가변 길이, 휘발성, 비연속적(sparse)
- 파일: 프로세스 간 공유 가능, 고정된 길이, 비휘발성, 연속적(linear)
- 파일 시스템: 파일과 물리 디스크 블록 간의 매핑 제공(디스크 위치, 배치를 관리하는 매니저 역할, "어디"에 실제로 저장되어 있는지 테이블로 매핑)
3. 커널 동작 과정
- 부트스트랩 프로그램 → 전원을 켤 때 바로 시작: ROM → 메인 메모리 적재
- 커널 초기화: start_kernel(OS를 실행하기 위한 설정, 초기화 등), trap_init, init_IRQ, shed_init, rest_init → kernel_thread 생성

JUST DO IT