문제 바로가기
문자열 s가 주어졌을 때, s의 각 위치마다 자신보다 앞에 나왔으면서, 자신과 가장 가까운 곳에 있는 같은 글자가 어디 있는지 알고 싶습니다.
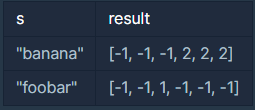
예를 들어, s="banana"라고 할 때, 각 글자들을 왼쪽부터 오른쪽으로 읽어 나가면서 다음과 같이 진행할 수 있습니다.
b는 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
a는 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
n은 처음 나왔기 때문에 자신의 앞에 같은 글자가 없습니다. 이는 -1로 표현합니다.
a는 자신보다 두 칸 앞에 a가 있습니다. 이는 2로 표현합니다.
n도 자신보다 두 칸 앞에 n이 있습니다. 이는 2로 표현합니다.
a는 자신보다 두 칸, 네 칸 앞에 a가 있습니다. 이 중 가까운 것은 두 칸 앞이고, 이는 2로 표현합니다.
따라서 최종 결과물은 [-1, -1, -1, 2, 2, 2]가 됩니다.
문자열 s이 주어질 때, 위와 같이 정의된 연산을 수행하는 함수 solution을 완성해주세요.
입출력 조건 및 예시
1 ≤ s의 길이 ≤ 10,000
s은 영어 소문자로만 이루어져 있습니다.
접근 방법
list형 자료 구조를 이용
append() : 맨 뒤에 요소 추가
insert(a,b) : index a에 b 요소 추가 (a = 0으로 설정하면 맨 앞에 요소를 추가)
insert를 이용해서 for loop를 돌 때 마다 주어진 문자열을 반대로 하나씩 추가하면서 현재 문자와 공통된 문자까지의 거리를 string.index(a)로 표현해서 answer에 append시켰다.
내 풀이
def solution(s): answer = [] check = [] for i in list(s): if i in check: answer.append(check.index(i)+1) check.insert(0,i) else: answer.append(-1) check.insert(0,i) return answer
다른 사람 풀이
def solution(s): answer = [] dic = dict() for i in range(len(s)): if s[i] not in dic: answer.append(-1) else: answer.append(i - dic[s[i]]) dic[s[i]] = i return answer
- dictionary 자료형을 이용
