알고리즘 설계 Tip
- python의 경우 1억번의 연산 횟수 당 1초 정도, 시간초과의 경우 1억 이상의 연산 횟수를 가지면 시간초과가 걸린다고 생각하면 된다.
- 예를 들어 주어진 수가 1~10000이라고 할 때 이중 for문 ( O(n^2) )의 시간 복잡도를 가질 경우 시간 초과가 일어날 거라고 생각하고 풀면 된다.
- 기업 코테의 경우 일반적으로 제한 시간은 5초라고 생각하고 풀면 좋다.
- 제한 시간 5초가 기준일 때
- N의 범위가 500 : O(n^3)가능
- N의 범위가 2000 : O(n^2)가능
- N의 범위가 100,000인 경우 : O(nlogn)
- N의 범위가 10,000,000인 경우 : O(n)
알고리즘 문제 해결 과정
- 지문 읽기
- 요구사항 분석 (복잡도 분석)
- 아이디어 탐색
- 소스코드 설계 및 코딩
- 일반적으로 아이디어를 캐치하면 간결하게 작성할 수 있도록 출제된다!
✔자료형
- 정수형 양의 정수, 음의 정수, 0 int()
- 실수형 소수점을 붙인 수, 0.7 >> .7로 사용, 실수형 데이터와의 연산을 하면 정수형도 실수형으로 변환
- 지수표현 방식 e나 #의 다음에 오는 수는 10의 지수부를 의미, 실수형 데이터에 포함
ex) 1e9 = 1* 10^9를 의미한다.- 2진수 > 값과 가장 가깝게 메모리에 저장하지만 미세한 오차가 발생하게 된다. >>> round()로 반올림하여 사용
- 기본적으로 나누기(/)를 사용하면 실수형으로 반환
- 나머지(%)를 사용할 때가 많음 ex)홀,짝 체크
- 몫(//), 거듭제곱(**)의 연산자를 사용한다
list
- 리스트는 대괄호로 원소를 넣어 초기화, index는 0부터 시작
- 리스트에 곱셈(*) 연산을 진행하면 한 리스트 안에 정의됨.
- indexing, slicing을 이용해서 특정 위치의 원소를 호출할 수 있다. 콜론(:)은 시작, 끝 인덱스를 사용, 마지막 인덱스는 1크게 설정한다.
list comprehension
- 대괄호 안에 조건문과 반복문을 적용해서 초기화 가능
- nm 크기의 2차원 list 초기화에 유용
ex) array = [[0]m for i in range(n)]
위 같이 정의하면 아래와 같은 결과가 생김 (리스트 내의 원소를 모두 같은 것으로 인식)
- 반복 수행 시 반복에 의한 변수 값이 필요 없으면 언더바(_)를 사용한다.![]
- list 함수와 시간복잡도
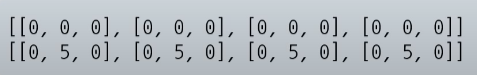

문자열
- '', ""로 문자열 초기화, 구체적인 것은 서치해서 사용😊
- 문자열 간에는 덧셈(Concatenate)가 가능, 곱셈도 가능
- 문자열도 indexing, slicing을 사용가능하나 이를 이용한 특정 인덱스의 값 변환은 불가능하다.
튜플
- 리스트와 유사하지만 한 번 선언된 값을 변경할 수 없다
()을 이용해서 정의- 기능이 제한적이기 때문에 리스트보다 공간 효율적(더 적은 메모리를 사용)
딕셔너리
- key:value를 쌍으로 가진다.
- keys()는 tuple형태로서 변경 불가능함
- 파이썬 자료형은 Hash Table을 이용하므로 데이터 조희, 수정에 있어서 O(1)의 시간복잡도를 가진다.
ex) dict['key_name'] = 'value'로 할당 or 변경 가능하다
관련 method
- dict.keys() : key data만 담은 list
- dict.values(): value data만 담은 list
조건문
- 프로그램의 흐름을 제어
- 조건에 따른 서로 다른 로직을 설정할 때 효과적으로 사용
반복문
- 반복적으로 실행하고자 할 때 사용하는 문법
while, for를 사용할 수 있는데 일반적으로 for문이 더 길이가 짧다.
함수
- 특정한 작업을 하나의 단위(함수)로 묶어 놓는 것을 의미
- 불필요한 소스코드의 반복을 줄일 수 있다.
- 내장 함수와 사용자 정의 함수로 나뉜다. 아래와 같이 정의 가능
def func_name(paramaeters): """define_action""" return # 반환 값을 정의하며 반드시 정의하지 않아도 됨
- parameter 지정은 순서를 맞춰서 지정하거나 '변수이름 = 변수값'으로 직접적으로 지정할 수 있다.
- global a : 함수 밖에서 정의된 parameter를 이용할 때 global keword로 함수 내에서 정의되어야 한다.
a = 0 def func(): global a a+=1 print(a) # func() >>> 1로 출력
여러 개의 반환 값
- 여러 개의 반환 값을 가질 수 있다(packing/unpacking)을 시행
ex func의 return a,b,c,d일 경우
x,y,z,w = func()로 정의 할 수 있다.(unpacking)
lambda 표현식
- lambda (변수):(변수에 대한 식)(변수에 대입하는 값)
실전에서 유용한 표준 라이브러리
- 내장함수 print(),sorted(),sum()
- itertools : 순열과 조합 library
- heapq : heap자료구조를 제공, 우선순위 큐(priority queue)기능을 구현할 때 사용, 대표적으로 최단경로 알고리즘에서 많이 사용됨
- bisect : 이진 탐색 기능 (Binary Search)
- collections: deque, Counter 등의 자료구조를 포함
Counter : 등장 횟수를 세는 기능을 제공, list같은 반복 가능한 객체가 주어졌을 때 내부의 원소 등장 횟수를 반환, counter>>dict형태로 반환해서 사용해야함 - math : 팩토리얼, 제곱근, 최대공약수, 삼각함수, pi 값 제공
gcd()를 사용하면 최대공약수를 구할 수 있다.
이를 이용해서 lcm(최소공배수)를 구할 수 있다.
def lcm(a,b):
return a*b//math.gcd(a,b)
Department of Artificial Intelligence, EWHA