입력 데이터의 개수에 따른 복잡도의 증가
만약 그 복잡도가 지수꼴이라면 n값의 증가에 따른 증가폭이 급격히 증가한다.
따라서 코드를 짤 때 있어서 최대한 일차 or log함수를 그 복잡도로 갖는 코드를 작성하는 것이 좋다.
효율적인 알고리즘
알고리즘이 결과 도출까지 걸리는 시간이 짧을수록, 사용하는 메모리가 적을수록 효율적이라고 할 수 있다.
항상 코드를 실행할 때 있어서 시간을 측정하고 비교하자.
import time
start_time = time.time()
main코드
print('소요시간 : ', time.time()-start_time)시간 복잡도와 시간 복잡도 함수
Time Complexity : 알고리즘을 수행하는 데에 연산들이 몇 번 이루어지는 지를 숫자로 표기
(연산 : 산술, 대입, 비교, 이동을 의미)
데이터 개수가 n일 때의 시간 복잡도 함수는 T(n)으로 표기한다.
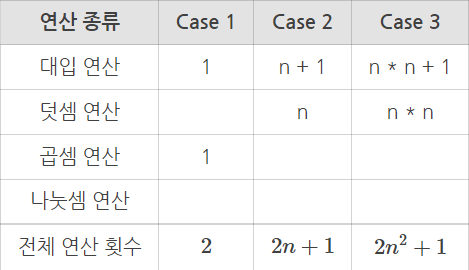
ex. 양의 정수 n을 n번 더하는 계산
case 1
sum = n * n
case 2
sum = 0
for i in range (n):
sum = sum + n
case 3
sum = 0
for i in range (n):
for j in range (n)
sum = sum + 1
빅오 표기법(big-oh notation)
시간복잡도 함수를 간단하게 할 목적으로 가장 큰 차수를 그 함수로 한다.
ex) T(n) = 2n+4 = O(n)
T(n) = 4n = O(n) 으로 같다.
수식의 n이 커지면 둘의 차이는 미미해지고, 실행 시간이 가장 중요한 n에 정비례하기 때문에.
O(1) (Constant)
입력 데이터의 크기에 상관없이 언제나 일정한 시간이 걸리는 알고리즘. 데이터가 얼마나 증가하든 성능에 영향 거의 x
ex) T(n) = 5 = O(1)
O(log₂ n) (Logarithmic)
입력 데이터의 크기가 커질수록 처리 시간이 로그(log: 지수 함수의 역함수) 만큼 짧아지는 알고리즘. 예를 들어 데이터가 10배가 되면, 처리 시간은 2배가 됩니다. 이진 탐색이 대표적이며, 재귀가 순기능으로 이루어지는 경우도 해당.
O(n) (Linear)
입력 데이터의 크기에 비례해 처리 시간이 증가하는 알고리즘. for문이 여기에 해당.
O(n log₂ n) (Linear-Logarithmic)
데이터가 많아질수록 처리시간이 로그(log) 배만큼 더 늘어나는 알고리즘. 예를 들어 데이터가 10배가 되면, 처리 시간은 약 20배가 된다. 정렬 알고리즘 중 병합 정렬, 퀵 정렬이 대표적.
O(n²) (quadratic)
데이터가 많아질수록 처리시간이 급수적으로 늘어나는 알고리즘. 예를 들어 데이터가 10배가 되면, 처리 시간은 최대 100배가 됩니다. 이중 루프(n² matrix)가 대표적.
O(2ⁿ) (Exponential)
데이터량이 많아질수록 처리시간이 기하급수적으로 늘어나는 알고리즘. 대표적으로 피보나치 수열이 있으며, 재귀가 역기능을 할 경우도 해당.
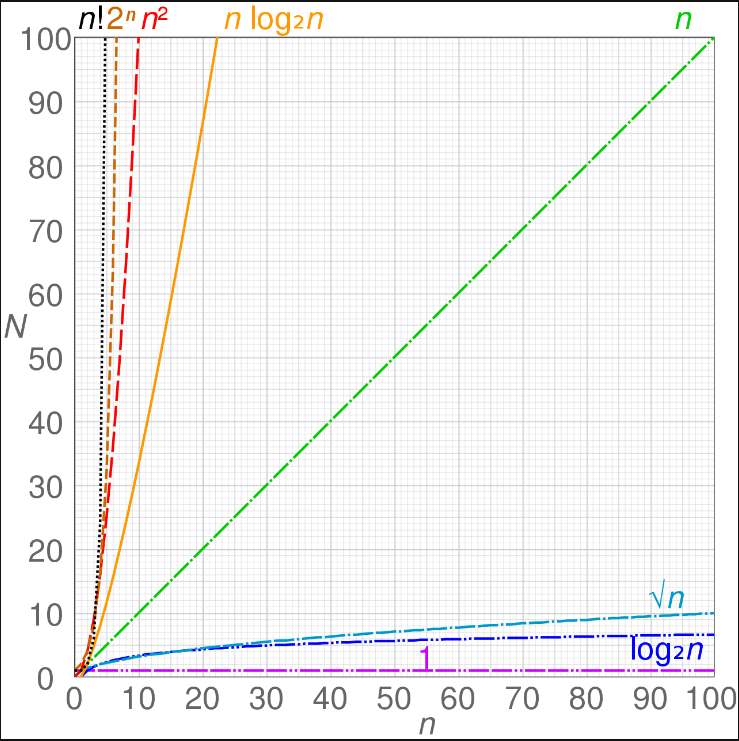
시간 복잡도에 따른 성능 비교는 아래와 같다.
faster O(1) < O(log n) < O(nlog n) < O(n²) < O(2ⁿ) slower
Consider Worst case
시간 복잡도 함수의 big-oh notation은 최악의 경우(알고리즘의 수행 시간이 가장 오래 걸리는 경우)를 고려한다.
공간 복잡도와 공간 복잡도 함수
공간 복잡도(Space Complexity)란 작성한 프로그램이 얼마나 많은 공간(메모리)을 차지하느냐를 분석하는 방법.
컴퓨터 성능의 발달로 그 중요도는 시간 복잡도보다는 떨어짐.
공간 복잡도를 줄이는 방법
공간 복잡도는 보통 배열의 크기, 동적할당, 재귀 함수 등의 영향을 받는다.
고정 공간과 가변 공간으로 보통 나누어지는데, 가변 공간을 사용하는 자료 구조에서 더 효율을 보임.
