- 실수형 주의할 점
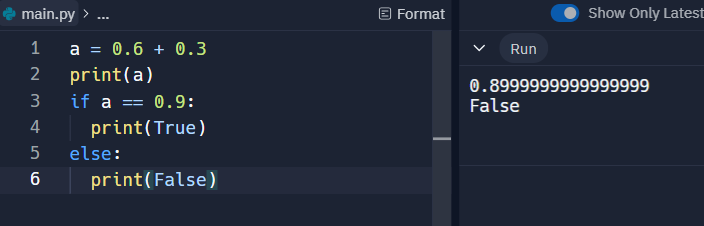
실수형 더하기 (0.3 +0.6)
IEEE754 표준에는 실수형을 저장하기 위한 4바이트, 혹은 8바이트의 고정된 크기의 메모리를 할당하므로, 실수형을 표현하는 데에 있어서 정확도가 떨어집니다.
그렇기에 0.6 + 0.3는 0.9이지만, 0.89999... 로 값이 나옵니다.
왜나하면 2진수에서 0.9를 정확히 표현할 수 있는 방법이 없기 때문입니다.
- 해결방법
결과 값에 round를 넣어 해결합니다.
- 리스트 컴프리헨션
파이썬의 자료구조(list, dictionary, set)에 데이터를 좀 더 쉽고 간결하게 담기 위한 문법
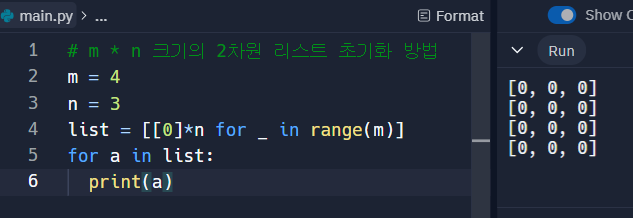
n * m 크기의 2차원 리스트 초기화
m = 4 n = 3 list = [[0]*n for _ in range(m)] for a in list: print(a)
- 언더바 사용 시기
반복을 수행할 때, 변수의 값을 무시하고자 할 때 언더바(_)를 사용합니다.
예시
m = 4 n = 3 list = [[0]*n for _ in range(m)] for a in list: print(a)
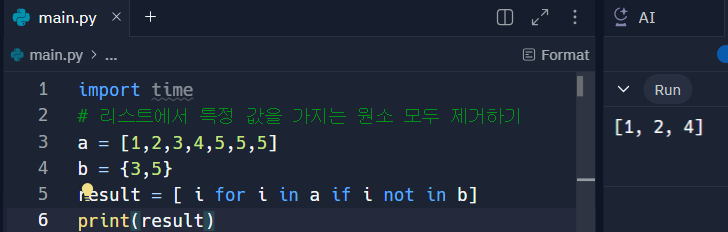
- 리스트에서 특정 값을 가지는 원소 제거하기
# 리스트에서 특정 값을 가지는 원소 모두 제거하기 a = [1,2,3,4,5,5,5] b = {3,5} result = [ i for i in a if i not in b] print(result)
- 튜플의 사용법과 사용하면 좋은 경우
파이썬에서 튜플(tuples)은 여러 값을 하나의 객체로 묶어주는 데이터 구조입니다. 튜플은 리스트와 비슷하지만, 몇 가지 중요한 차이점이 있습니다.
튜플의 성질
- 불변성 (Immutability)
튜플은 생성된 후 그 값을 변경할 수 없습니다. 즉, 튜플은 읽기 전용 데이터 구조입니다. 이는 데이터의 무결성을 보장하는데 유리합니다.my_tuple = (1, 2, 3) # my_tuple[0] = 10 # TypeError 발생- 순서가 있음 (Ordered)
튜플은 요소의 순서를 유지합니다. 리스트와 마찬가지로 인덱스를 통해 요소에 접근할 수 있습니다.my_tuple = (10, 20, 30) print(my_tuple[1]) # 출력: 20
- 혼합 데이터 타입 지원
튜플은 다양한 데이터 타입을 포함할 수 있습니다. 숫자, 문자열, 리스트, 심지어 다른 튜플도 가능합니다.mixed_tuple = (1, "hello", [1, 2, 3], (4, 5))
- 해시 가능 (Hashable)
튜플은 해시 가능하여 딕셔너리의 키로 사용할 수 있습니다. 반면 리스트는 해시 불가능합니다.my_dict = {(1, 2): "value"}튜플을 사용하면 좋은 경우
- 서로 다른 성질의 데이터를 묶어서 관리할 때
- 최단 경로 알고리즘에서 (비용, 노드 번호)의 형태로 튜플 자료형을 자주 사용함.
- 데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때
- 튜플은 변경 불가능하므로 리스트와 다르게 키 값으로 사용될 수 있습니다.
- 리스트보다 메모리를 효율적으로 사용해야 할 때
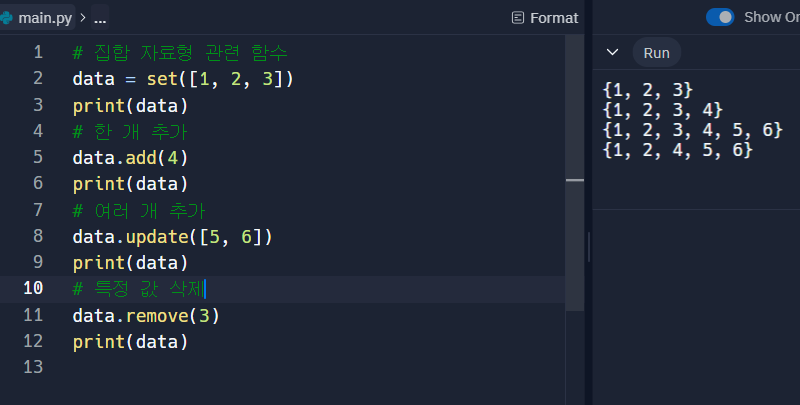
- 집합 자료형
파이썬에서 집합(set)은 중복되지 않는 요소의 모음으로, 수학적 집합을 구현한 데이터 구조입니다. 집합은 다양한 유용한 기능을 제공하여 데이터 처리에 유리합니다.
집합의 주요 특징
- 중복 제거
집합은 동일한 요소를 허용하지 않습니다. 중복된 값은 자동으로 제거됩니다.my_set = {1, 2, 3, 2, 1} print(my_set) # 출력: {1, 2, 3}- 순서 없음
집합은 요소의 순서를 유지하지 않습니다. 따라서 인덱스를 통한 접근은 불가능합니다.my_set = {1, 2, 3} # print(my_set[0]) # TypeError 발생
- 변경 가능
집합은 변경 가능한(mutable) 자료형입니다. 새로운 요소를 추가하거나 기존 요소를 제거할 수 있습니다.my_set = {1, 2, 3} my_set.add(4) print(my_set) # 출력: {1, 2, 3, 4} my_set.remove(2) print(my_set) # 출력: {1, 3, 4}집합 연산
- 합집합: 집합 A에 속하거나 B에 속하는 원소로 이루어진 집합
# 합집합 print(a | b)
- 교집합: 집합 A에도 속하고 B에도 속하는 원소로 이루어진 집합
# 교집합 print(a & b)
- 차집합: 집합 A의 원소 중에서 B에 속하지 않는 원소로 이루어진 집합
# 차집합 print(a - b)집합 관련 함수
- 입력
입력을 위한 전형적인 소스코드 (1)
# 입력을 위한 전형적인 소슼코드 (전달받은 값을 각 정수형으로 받기) data= list(map(int,input().split())) print(data) print(type(data)) print(type(data[2]))빠르게 입력받기
import sys #문자열 입력받기 data= sys.stdin.readline().rstrip() print(data)단, 입력 후 엔터가 줄 바꿈 기호로 입력되므로 rstrip() 메서드를 함께 사용합니다.

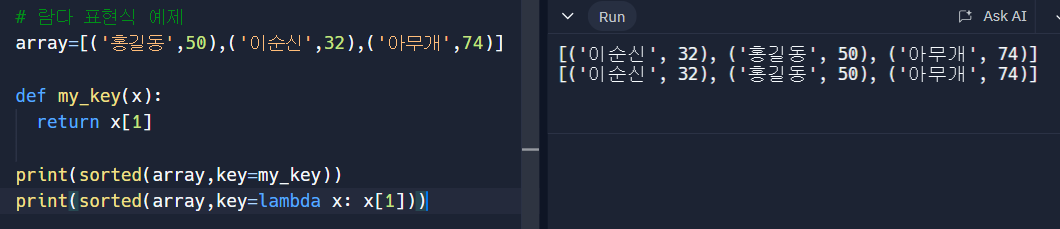
- 람다 표현식
사전형에서 적용하는 방법
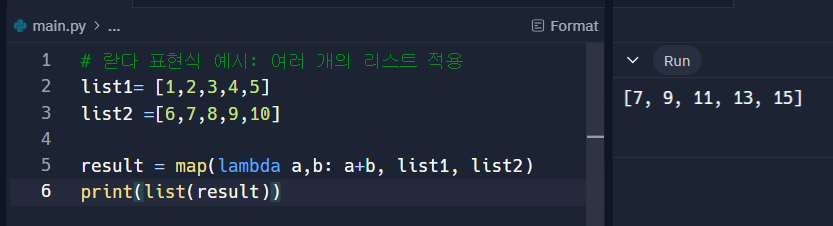
다음과 같이 한 번 쓰고 말 함수들은 람다식을 이용하여 쉽게 사용할 수 있음.여러 개의 리스트에 적용하는 방법
- 순열과 조합
순열:
서로 다른 n 개에서 서로 다른 r 개를 선택하여 일렬로 나열하는 것
# 선택하여 조합을 찾아내는 방법 from itertools import permutations data = ['A', 'B', 'C'] result = list(permutations(data, 3)) print(result)조합:
서로 다른 n 개에서 순서에 상관 없이 서로 다른 r개를 선택하는 것
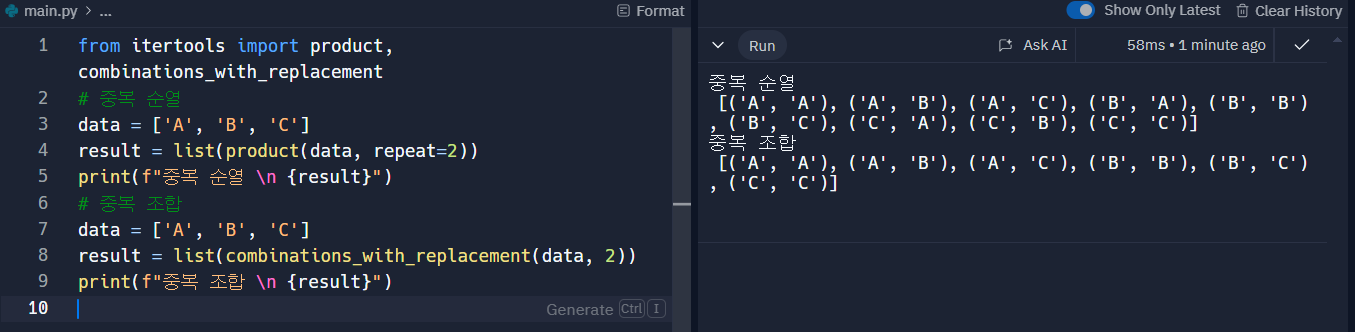
# 선택하여 조합을 찾아내는 방법 from itertools import combinations data = ['A', 'B', 'C'] result = list(combinations(data, 2)) print(result)중복 순열과 중복 조합
from itertools import product, combinations_with_replacement # 중복 순열 data = ['A', 'B', 'C'] result = list(product(data, repeat=2)) print(f"중복 순열 \n {result}") # 2개를 뽑는 모든 순열 구하기 (중복 허용) # 중복 조합 data = ['A', 'B', 'C'] result = list(combinations_with_replacement(data, 2)) print(f"중복 조합 \n {result}") # 2개를 뽑는 모든 조합 구하기 (중복 허용)


- Counter
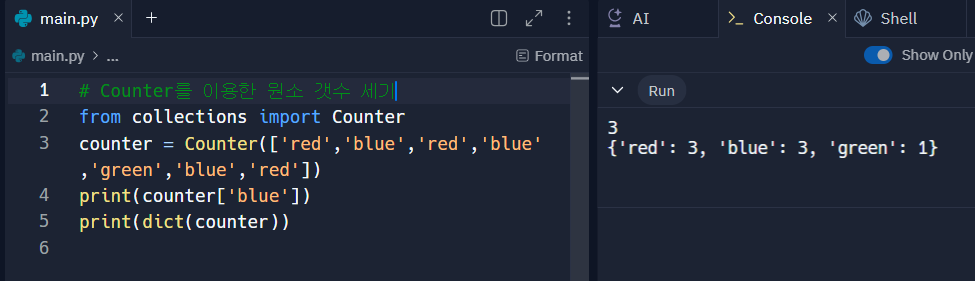
- collections 라이브러리의 Counter는 등장 횟수를 세는 기능을 제공함.
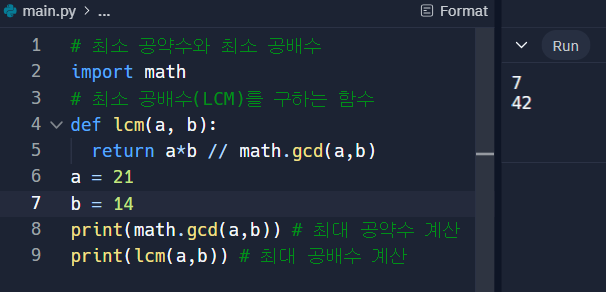
# Counter를 이용한 원소 갯수 세기 from collections import Counter counter = Counter(['red','blue','red','blue' ,'green','blue','red']) print(counter['blue']) print(dict(counter))최대 공약수와 최소 공배수
# 최소 공약수와 최소 공배수 import math # 최소 공배수(LCM)를 구하는 함수 def lcm(a, b): return a*b // math.gcd(a,b) a = 21 b = 14 print(math.gcd(a,b)) # 최대 공약수 계산 print(lcm(a,b)) # 최대 공배수 계산
- stack[::1]에 대한 설명
stack[::1]는 파이썬에서 리스트나 배열을 슬라이싱하는 방법 중 하나입니다. 여기서stack은 리스트, 배열, 또는 다른 시퀀스 타입을 의미합니다.
슬라이싱 구문은start:stop:step형식으로 구성되며,::1은 다음과 같은 의미를 가집니다:
- start: 생략되어 기본값인 0부터 시작합니다.
- stop: 생략되어 끝까지 포함합니다.
- step: 1이므로, 모든 요소를 1씩 건너뛰지 않고 가져옵니다.
결과적으로stack[::1]은stack의 모든 요소를 그대로 반환합니다. 즉, 원본 리스트나 배열과 동일한 결과를 가져옵니다.예시
stack = [1, 2, 3, 4, 5] result = stack[::1] print(result) # 출력: [1, 2, 3, 4, 5]
출처
