용어
LeNet: 합성곱 신경망(CNN)의 초기 형태라 할 수 있는 모델. 페이스북의 얀 르쿤이 개발한 딥러닝 모델이다.ANN: Artificial neural network, 인공 신경망CNN: Convolutional neural netwokr, 합성곱 신경망뉴런 / 유닛: 인공 신경망의 기본 계산 단위. 뉴런 또는 유닛 둘 다 같은 의미.필터 / 커널: 합성곱 신경망의 기본 계산 단위. 인공 신경망의뉴런 / 유닛과 같은 의미다.입력층: 처음 들어오는 데이터를 받는 곳. 신경망이 처리해야 할 원본 데이터를 전달하는 역할을 맡음.은닉층: 입력층과 출력층 사이에 있는 모든 층을 은닉층이라고 부름. 복잡한 계산을 통해 입력 데이터의 패턴을 찾고, 중요한
특징을 뽑아냄.출력층: 최종 결과를 내는 곳. 신경망의 최종 값을 만든다는 의미에서 출력층이라고 부름.합성곱층(convolutional layer): 이미지의 작은 부분을 스캔하여 중요한 특성을 추출하는 층. 특별히 합성곱 계산을 통해 압축적으로 얻은 출력을 특성 맵feature map이라고 부름.풀링층(pooling layer): 합성곱층에서 추출한 특성 맵을 압축(축소)하는 층. 특성 맵을 축소해 처리 속도를 높이고, 모델이 더 중요한 패턴에 집중하도록 만드는 층.밀집층(dense layer): 이전 층에서 추출된 특성을 바탕으로 최종 결과를 도출하는 층. 밀집층의 출력층에서는 추출된 이미지의 패턴을 바탕으로 분류 작업을 수행함.
밀집층은 각각의 입력 값이 모든 뉴런에 연결되기 때문에 완전 연결층(fully connected layer)이라고도 불림.패딩(padding): 이미지의 가장자리에 빈 공간(0)을 추가해 이미지 가장자리 부분의 픽셀이 처리될 수 있도록 함.세임 패딩(same padding): 입력과 특성 맵의 크기를 동일하게 만들기 위해 입력 주위에 적절한 개수의 패딩을 추가하는 방식.밸리드 패딩(valid padding): 패딩 없이 순수한 입력 배열에 대해서만 합성곱을 수행해 특성 맵을 만드는 방식.스트라이드(stride): 필터가 이미지 위를 이동하는 속도를 의미. 기본값은 1로, 예를 들면 입력 받은 이미지를 필터 크기만큼 1픽셀씩 이동하면서 스캔함.평균 풀링(Average pooling): 풀링 윈도 내에서 평균값을 구해 출력해 냄.최대 풀링(max pooling): 풀링 윈도 내에서 최대값을 구해 출력해 냄.
합성곱층(Convolutional layer)
import keras
from keras import layers
import numpy as np
# 정규 분포의 평균 : 0.0(기본값)
# 표준편차 : 1.0
# 생성하려는 배열의 크기 : (10 * 28 * 28 * 10) (w, x, y, z)
# normal() 함수를 사용해 28*28*1 크기의 흑백 이미지 10개를 랜덤으로 생성합니다. (1은 입력 데이터의 채널 수)
x = np.random.normal(size=(10, 28, 28, 1))- 필요한 라이브러리를 로드합니다.
- 테스트에 사용할 (28, 28) 크기 흑백 이미지를 10개 랜덤하게 생성합니다.
conv1 = layers.Conv2D(filters=10, kernel_size=(3, 3))
# 첫 번째 합성곱층에 x를 입력으로 전달하고 특성 맵을 출력합니다.
# 필터 개수와 커널 크기를 지정하는 합성곱층을 추가합니다.
conv_out = conv1(x)
# shape 속성을 사용해 합성곱층을 통과한 입력 데이터의 크기를 확인합니다.
# 커널 크기가 (3, 3)이고 패딩을 추가하지 않았기 때문에 높이와 너비가 2식 줄어들었고
#(valid padding으로 인한 특성 맵 축소)
print(conv_out.shape) # output : (10, 26, 26, 10)- Conv2D 클래스로 2차원 합성곱 레이어를 만듭니다(=conv1).
filters는 사용할 필터의 개수,kernel_size는 커널의 크기입니다 - 합성곱 레이어에 입력 데이터를 넣어서 나온 특성 맵의 차원을 출력합니다.
- 결과가 (10, 26, 26, 10)으로 나왔습니다. 각각의 의미를 살펴보자면,
10: 10개의 이미지가 그대로 처리되었다. (앞서 설정한 더미 이미지 데이터 10개)26: 각 이미지의 높이가 26이다.26: 각 이미지의 너비가 26이다.10: 필터 10개를 사용했더니, 깊이가 10으로 늘어났다.
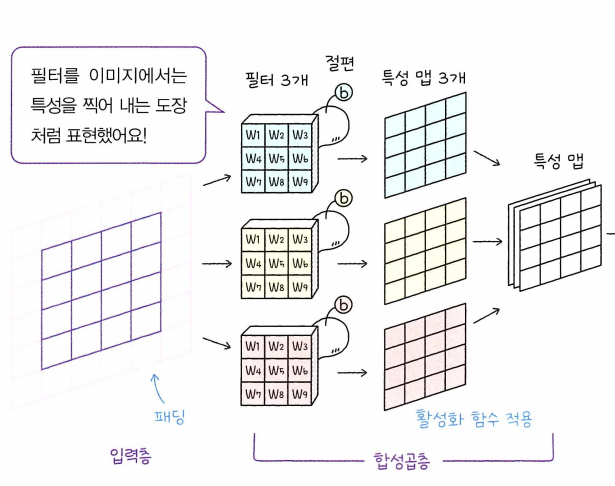
필터의 개수가 10개니까 나오는 특성 맵의 개수도 10개고, 이 특성 맵을 하나의 결과로 만들면, 깊이가 10인 특성 맵 하나가 만들어집니다.
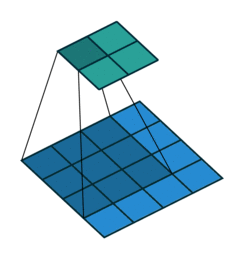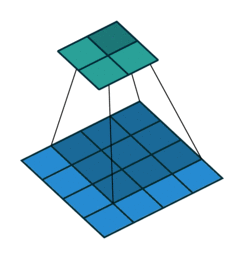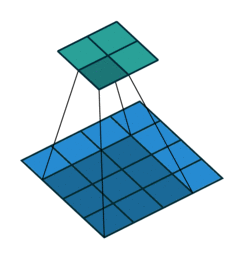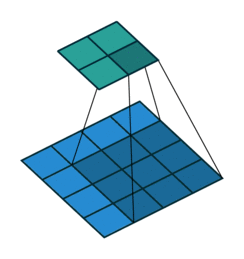
높이와 너비가 26으로 줄은 이유는 커널의 크기가 (3, 3)이고, 패딩을 추가하지 않았기 때문입니다.
conv2 = layers.Conv2D(filters=10, kernel_size=(3, 3), strides=(2, 2))
print(conv2(x).shape) # (10, 13, 13, 10)스트라이드 값을 2로 주니 한 칸 씩 건너 뛰면서 합성곱을 진행해서 출력 크기가 이전보다 절반이 줄어든 모습을 볼 수 있습니다.
# padding 방식을 same(세임)으로 변경합니다.
conv3 = layers.Conv2D(filters=10, kernel_size=3, strides=2, padding='same')
print(conv3(x).shape) # (10, 14, 14, 10)스트라이드가 2이고 세임 패딩을 사용했기 때문에 (28, 28)이었던 입력의 높이와 너비 크기가 정확히 절반으로 줄어들어
(14, 14)가 되었습니다. 만약 스트라이드를 기본값으로 사용한다면 (28, 28) 크기의 특성맵으로 입력과 동일해질겁니다.
풀링층(Pooling layer)
# 풀링 윈도를 각각 (2, 2), (3, 3) 크기로 만듭니다.
pool1 = layers.AveragePooling2D(pool_size=(2, 2))
pool2 = layers.AveragePooling2D(pool_size=(3, 3))
# 만들어진 풀링 윈도로 원본 데이터를 평균 풀링합니다.
# (28, 28)크기를 (2, 2)로 절삭해 압축하니 (14, 14) 크기로 변환됐습니다.
print(pool1(x).shape) # (10, 14, 14, 1)
# (28, 28)크기를 (3, 3)로 절삭해 압축하니 (9, 9) 크기로 변환됐습니다.
print(pool2(x).shape) # (10, 9, 9, 1)풀링을 통해 원본(28, 28)을 축소(압축)하니 풀링 윈도가 (2, 2)일 땐 절반 크기인 (14, 14)로, (3, 3)일 땐 (9, 9)로 압축됐습니다. 기본적으로 풀링 윈도에 딱 맞지 않는 짜투리 부분은 버려집니다.
밀집층(Dense layer)
# 뉴런이 3개짜리인 밀집층을 만듭니다.
dense1 = layers.Dense(3)
# 2개짜리 입력 특성을 만듭니다.
# 2차원으로 입력값을 넘기는 이유는 케라스 층에 전달되는 입력의 첫 번째 차원은
# 항상 배치 차원, 즉 데이터 묶음이여야 하기 때문에 입력값의 크기를 (2)이 아닌 (1,2)인 2차원 배열로 만듭니다.
x2 = np.array([[5, 7]])
print(dense1(x2).shape) # (1, 3)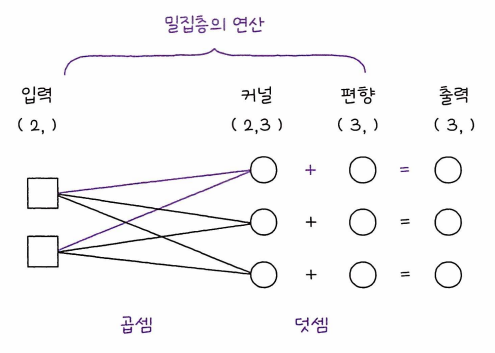
밀집층은 입력과 가중치의 점곱dot product을 수행합니다. 점곱 연산은 다음과 같은 수식으로 나타낼 수 있습니다.
결과값의 형태가 (3, 1)크기로 나오는 이유는 중간에 입력값에 곱하는 가중치, 커널의 크기가 (입력 크기, 유닛 개수)이기 때문입니다. 유닛은 각각의 입력값에 대해 가중치를 가져야 하며 이 가중치가 각 유닛 마다 갖고 있어야하기 때문에 가중치, 즉 커널의 크기(입력 크기, 유닛 개수)가 (2, 3)이 됩니다.
weight = dense1.get_weights()[0]
print(np.dot(x2, weight)) # [[33. 45. 57.]]
개발하고 만드는걸 좋아합니다