💡 머신러닝 종류
- 지도학습 (Supervised Learning)
- 분류 (Classification)
- 회귀 (Regression)
- 예측 (Forecasting)
- 비지도 학습 (Unsupervised Learning)
- 클러스터링
- 차원 축소
- 강화 학습 (Reinforcement Learning)
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
💡 사이킷런 Task
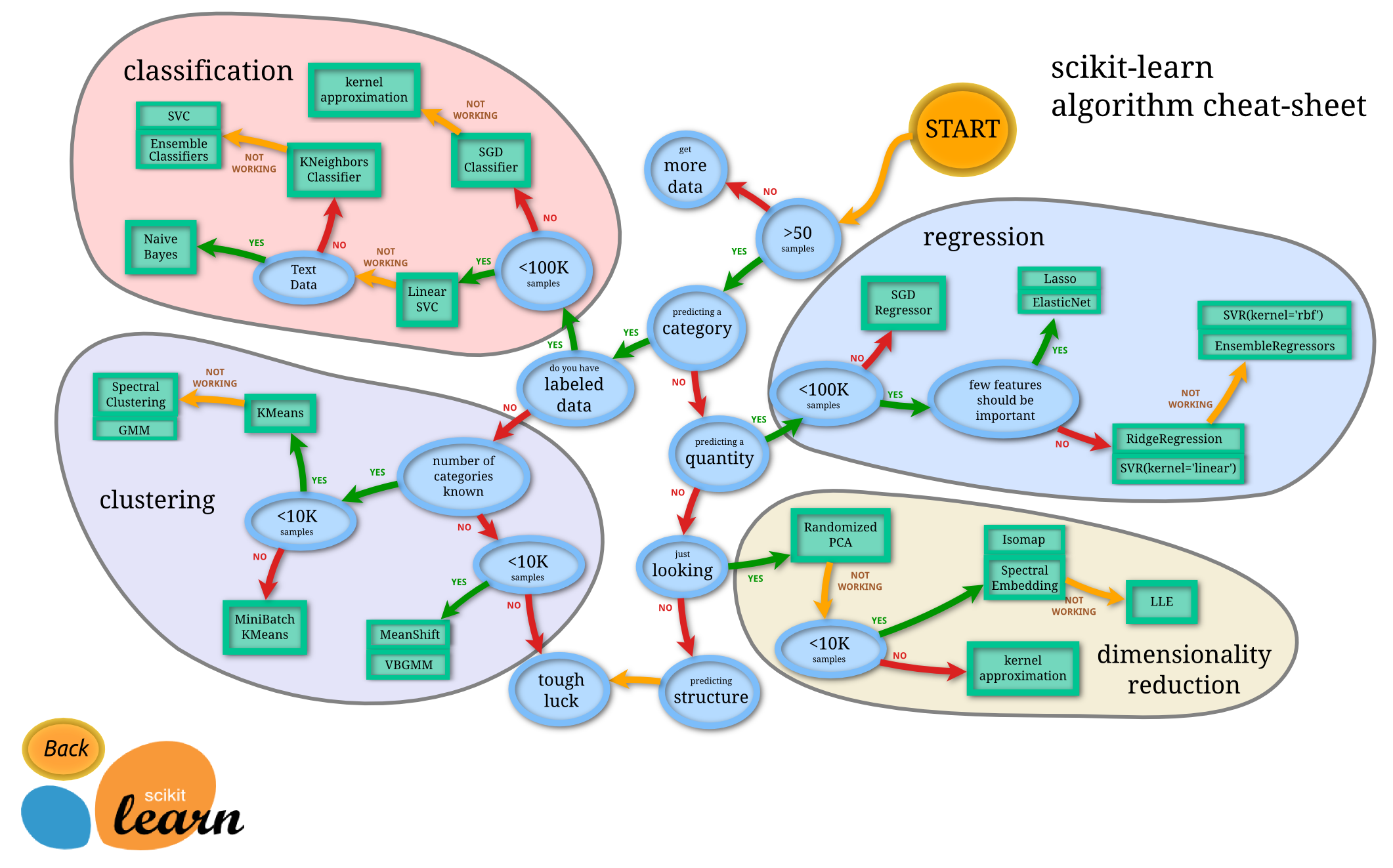
사진 출처 : http://https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
💡 사이킷런 주요 모듈
📌 데이터 표현법
-
사이킷런에서는 numpy의 ndarray, Pandas의 dataFrame, SciPy의 Sparse Matrix를 이용해 나타낼 수 있다.
-
대표적인 표현방식 2가지
- 특성 행렬 (Feature Matrix)
- 입력 데이터를 뜻한다.
- n_samples, n_features는 행,열 형태의 2차원 배열 구조를 가진다.
- 특성 행렬은 주로 변수명 'X'로 표기한다.
- 타겟 벡터 (Target Vector)
- 입력 데이터의 라벨(정답)을 의미한다.
- 타겟 벡터는 주로 변수명 'y' 로 표기한다.
- 특성 행렬의 X의 n_samples와 타겟벡터 y의 n_samples는 동일 해야한다.
- 특성 행렬 (Feature Matrix)
📌 회귀 모델 실습
import numpy as np import matplotlib.pyplot as plt r = np.random.RandomState(10) x = 10 * r.rand(100) y = 2 * x - 3 * r.rand(100) plt.scatter(x,y)
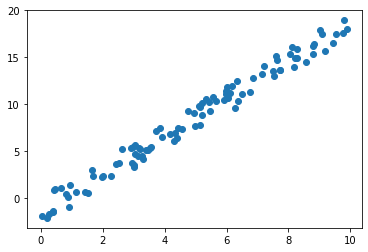
머신러닝 모델을 사용하기 위해 모델 객체를 생성해준다.
from sklearn.linear_model import LinearRegression model = LinearRegression()
여기서 그냥 fit() 메서드에 입력 데이터 x를 그대로 넣으면 에러가 발생한다.
x의 모양은 (100,)으로 1차원 벡터이기 때문이다. 행렬 형태의 입력데이터와 1차원 벡터 모양의 라벨을 넣어줘야 한다.
X = x.reshape(100,1) model.fit(X,y)
이제 새로운 데이터를 넣고 예측을 해보려 한다. np.linspace()를 이용해 생성한다.
x_new = np.linspace(-1, 11, 100) X_new = x_new.reshape(100,1) y_new = model.predict(X_new) plt.scatter(x, y, label='input data') plt.plot(X_new, y_new, color='red', label='regression line')
.png)
📌 datasets 모듈
Toy dataset 예시
- datasets.load_boston(): 회귀 문제, 미국 보스턴 집값 예측
- datasets.load_breast_cancer(): 분류 문제, 유방암 판별
- datasets.load_digits(): 분류 문제, 0 ~ 9 숫자 분류
- datasets.load_iris(): 분류 문제, iris 품종 분류
- datasets.load_wine(): 분류 문제, 와인 분류
datasets.load_wine() 훑어보기
input :
from sklearn.datasets import load_wine data = load_wine() type(data)
output :
sklearn.utils.Bunch
여기서 Brunch는 파이썬의 딕셔너리와 유사한 형태의 데이터 타입니다.
input :
print(data.keys())
ouput :
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
- data : 키값 data는 특성 행렬이다.
- target : 타켓 벡터.
- feature_names : 키에 특성들의 이름이 저장되어 있다.
- target_names : 분류하고자 하는 대상.
- DESCR : 데이터에 대한 설명.
💡 훈련 데이터와 테스트 데이터 분리하기
📌 데이터 직접 분리하기
보통 훈련 데이터와 테스트 데이터의 비율은 8:2 비율로 분할한다.
validation데이터가 있을경우 train, validation, test를 각각 6:2:2로 분할한다.
from sklearn.datasets import load_wine data = load_wine() print(data.data.shape) print(data.target.shape)
(178, 13) (178,)
전체 데이터 갯수는 178개이다 train과 test데이터를 8:2비율로 분할하면
train 142개 test 36개로 나뉜다.
X_train = data.data[:142] X_test = data.data[142:] y_train = data.target[:142] y_test = data.target[142:]
훈련 데이터와 테스트 데이터 분리가 끝났으므로, 다시 훈련과 예측을 진행 해보자.
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier() model.fit(X_train, y_train) y_pred = model.predict(X_test)
정확도를 평가해보면,
from sklearn.metrics import accuracy_score print("정답률=", accuracy_score(y_test, y_pred))
output :
정답률= 0.9444444444444444📌 train_test_split() 사용해서 분리하기
사이킷런 에서는 train 데이터와 test 데이터를 분리해주는 기능을 API로 제공한다.
from sklearn.model_selection import train_test_split result = train_test_split(X, y, test_size=0.2, random_state=42) print(result[0].shape) print(result[1].shape) print(result[2].shape) print(result[3].shape)
(142, 13) (36, 13) (142,) (36,)
0번째 원소부터 순서대로 train 데이터 특성행렬, test 데이터 특성행렬, train 데이터 타겟벡터, test 데이터 타겟벡터다. 보통 사용자들은 아래와 같이 언패킹해서 사용한다.
from sklearn.model_selection import train_test_split from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score
data = load_wine() X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=11) model = RandomForestClassifier() model.fit(X_train, y_train) y_pred = model.predict(X_test) print("정답률=", accuracy_score(y_test, y_pred))
