
👍 이 글은 우아한형제들 클라우드플랫폼개발팀 김대호님의 세미나 클라우드 환경에서의 Kafka 운영기 를 보고 정리한 내용입니다.
좋은 강연해주신 연사분께 감사드립니다.우형 입사하면 커피 사겠습니다.
📣 소제목을 누르면 해당 발표 시간의 영상으로 이동합니다. 내용을 보다가 이해가지 않는 부분이 있다면 편하게 찾아보세요.
📝 세미나 소개글
Kafka는 이제 비동기 통신 환경을 구성하는 대표적인 시스템입니다. 우아한형제들의 많은 서비스들 역시 Kafka를 사용하고 있는데요, 우아한형제들의 클라우드플랫폼개발팀은 더욱 신뢰성 있는 Kafka 환경을 구성하고자 노력하고 있습니다. 이번 발표에서는 클라우드 환경에서 Kafka를 도입하고 운영하면서 겪었던 문제 상황과 이에 대해 고민했던 내용을 공유합니다.
다룰 내용
- 카프카와 클라우드 환경의 특징
- 우아한형제들의 카프카
- 운영 중 겪었던 이슈와 개선
카프카의 특징
카프카의 기본적인 구조
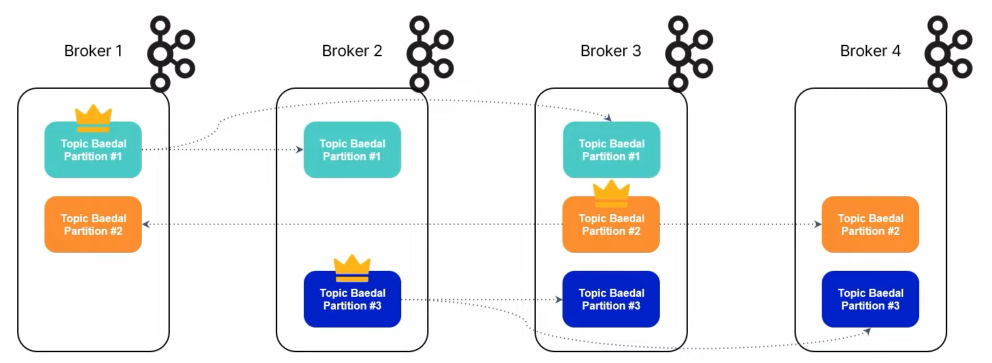
- 카프카는 토픽에 메시지를 발행(Publish) 및 구독(Subscribe)하는 구조
- 토픽은 병렬 처리를 위해 파티션 단위로 구성
- 파티션은 안정성을 위해 레플리카로 복제 구성
- 레플리카는 리더 레플리카와 팔로우 레플리카로 나뉘어 서로 다른 브로커에 퍼져 위치
- 그림은
배달이라는 토픽이 3개의 파티션과 복제 구성(?) 3으로 구성된 예시- 동일한 파티션 레플리카들이 서로 다른 브로커에 흩어져 구성
상태 기반(Stateful) 시스템
- 발행되는 메시지는
브로커의 파일 시스템에 저장- 토픽 파티션 별 로그 세그먼트(Log Segment)에 메시지가 저장
- 브로커가 토픽 파티션의 메시지를 저장하고 있다.
- = 브로커가 토픽 파티션의 레플리카를 가지고 있다.
- = 브로커가 토픽 파티션의 상태(State)를 가지고 있다.
하지만, 상태를 자동으로 옮기지 않는다
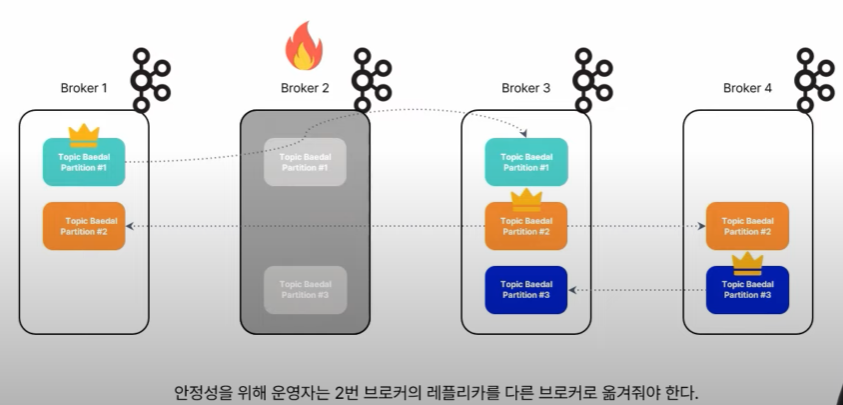
- 카프카는 브로커가 가지고 있는 레플리카를 다른 브로커로 임의로 옮기지 않는다.
- = 운영자가 상태를 관리해줘야 한다.
- 그림처럼 2번 브로커가 불능이 되었을 때, 해당 브로커에 위치한 1번 파티션의 레플리카와 3번 레플리카는 자동으로 옮겨지지 않음
정리🔑
카프카는 상태기반 시스템
클라우드 환경의 특징
클라우드 환경의 특징
필요한 리소스를 원하는 만큼 구성하기 쉽다.- 컴퓨팅 자원이 필요하면 바로 생성해서 사용 할 수 있음
- 하지만!
추적/예상하기 어려운 인프라 이슈- 인프라 작업에 의한 영향
- 클라우드 서비스는 내부적으로 다양한 작업들을 처리하는데, 이것이 영향을 주기도 함
- 이런 내부 작업으로 인한 영향은 미리 예상하기 어려움
- 물리적인 장비 이슈
- 인프라 작업에 의한 영향
실제 이슈 사례
- 현상: 특정 브로커의 갑작스러운 종료
- 클리스터의 일시적인 성능 저하
- 원인: EC2
underlying hardware 이슈- 네트워크 연결 끊김
- 시스템 전원 중단
- 물리적 호스트의 소프트웨어/하드웨어 문제
- 이런 이슈는 발생을 예상하기도, 그 영향 범위를 추적하기도 어렵다
클라우드 환경 + 카프카
운영자 입장
- 브로커가 죽으면 모든 작업
ALL STOP, 해당 이슈 관리에 초점이 맞춰지게 됨- 메시지 유실 등 클라이언트 쪽 영향이 없었는 지 확인
- 이슈 원인 파악
- 안정성을 위해 레플리카를 옮겨주기 등 후속 작업
- 인스턴스가 언제 어떻게 죽을지 모르는 클라우드 환경과, 이슈가 발생하면 상태를 하나하나 관리해줘야하는 카프카는 어찌보면 지뢰밭 같은 느낌
우아한형제들의 카프카
우아한형제들의 카프카 환경은 어떻길래 클라우드 환경을 지뢰밭처럼 느끼는 걸까
카프카 클러스터 규모 (2022년 8월 운영 환경 기준)
- 카프카 클러스터 27대
- 브로커 162대
- 파티션 약 24,000개
- 초당 평균 50만건, 최대 140만건 메시지 유입
카프카를 사용하는 서비스들

- 메시지 플랫폼
- 라이더 배차 시스템
- 데이터 플랫폼
- 로그 분석
카프카 클러스터는 지속적으로 생성 중!
- 20년 12월 기준 브로커 41대
- 22년 8월 기준 브로커 162대
- 2X년 X월 기준 브로커 ???대
점점 커지는 규모로 인한 고민
- 인스턴스 수가 늘어날수록 이슈의 발생 빈도는 증가할 것
- 클라우드 환경은 이러한 이슈 빈도를 더 높일 수 있다.
=> 클라우드 환경에서 점점 늘어나는 카프카 클러스터를 어떻게하면 안정적이고 효율적으로 운영할 수 있을지 항상 고민함
운영 중 겪었던 이슈와 개선
실제 운영 중에 겪었던 이슈와 개선 사항 3가지
이슈 1. 단일 주키퍼 클러스터
초기 카프카 클러스터 구성
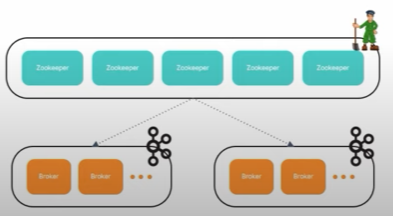
- 사내 서비스들은 MSA 기반으로 개별적으로 구성됨
- 카프카 클러스터도 각 서비스 별로 구성함
- 도입 초기엔 하나의 주키퍼 클러스터에 여러 카프카 클러스터를 구성
- "주기퍼 자체의 컴퓨팅 부하도 낮고, 아직 클러스터가 몇 개 안되니까!"
클러스터가 점점 늘어날수록 의존도가 증가
- 점점 주키퍼에 등록되는 카프카 클러스터가 증가
- 주키퍼 클러스터 이슈의 영향도가 증가하기 시작
- 만약, 주키퍼 인스턴스에 이슈가 생긴다면 전체 서비스 마비!!(SPOF)
개선 1. 격리된 클러스터 구성
주키퍼 클러스터도 분리
- 주피커:카프카 = 1:1구조로 변경하여 제공
서비스 별 격리된 환경으로 구성- 이슈가 발생하더라도 각 서비스 개별적으로 격리할 수 있었음 (이슈 영향도↓)
이슈 2. 업데이트가 어려워!
점점 어려워지는 카프카 업데이트
- 다양한 상황에서 카프카 업데이트가 필요
- Read-only 설정 업데이트
- 보안 패치를 위한 업데이트
- 가장 대표적인 카프카 업데이트 방법 =
롤링 업데이트(하나씩 껏다 킴) - 관리할 클러스터(브로커)가 점점 많아지면...?
- 10대는 조금만 시간 투자하면 가능, 50대는 하루 안에 못함, 200대는 대책 없음
롤링 업데이트의 한계
- 동작하고 있는 브로커를 내려야한다는 부담감
- 아무리 카프카가 레플리카를 통해 실패에 안정적인 환경이라지만, 그 과정에서 운영자의 여러 판단이 필요함
- 복제는 잘 되었나? (isr 설정)
- 클라이언트 쪽 이슈는 없나?
- 이제 다음 것 해도 되나?
- 아무리 카프카가 레플리카를 통해 실패에 안정적인 환경이라지만, 그 과정에서 운영자의 여러 판단이 필요함
+클라우드 환경
- 언제 인스턴스 실패가 발생할지 모르는 클라우드 환경
- 롤링 업데이트 중 다른 인스턴스에 이슈가 생긴다면..?
- 일시적인 다운타임 발생 가능!
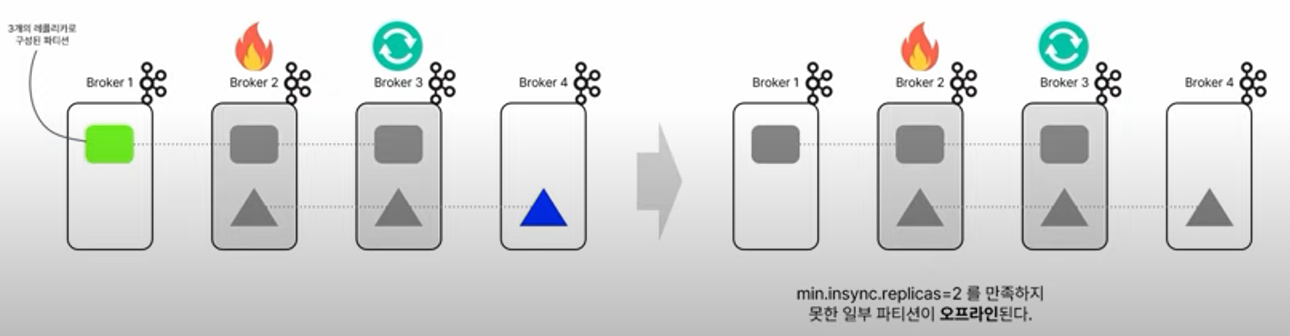
- 일시적인 다운타임 발생 가능!
개선 2. 쉬운 업데이트 환경 구성
카프카 클러스터 내에 논리적인 스택 구성
- 브로커 ID를 기준으로
논리적인 스택구성- 1~1000 : Blue
- 1001~2000: Green
- 업데이트 된 신규 브로커를 추가하고, 기존 브로커를 제거하는 방식
- 리소스 추가가 자유로운 클라우드 환경의 이점을 활용!
업데이트 방법🏷️
1. 신규 브로커를 기존 브로커 수에 맞게 클러스터에 추가한다.
2. 기존 브로커에서 신규 브로커로 파티션을 옮긴다.
3. 기존 브로커들을 제거한다.
- 트래픽이 있는 프로세스를 종료하지 않는
안정적인 업데이트 방법 - 브로커가 많아질수록 더 쉽고 간단해지는 방법
- 이벤트를 기반으로 하는 자동화를 구성할 수 있지 않을까?하는 기대
- 신규 브로커 프로비저닝 완료 > 파틴션 이동 > 기존 브로커 제거
이슈 3. 카프카 스트림즈의 상태 깨짐
카프카 스트림즈의 상태 관리
- 스트리밍 집계를 위해 사용하는 카프카 스트림즈
- 토픽 메시지를 집계하고 관리
- 카프카 스트림즈는 상태 정보를 로컬 db와 클러스터의 토픽에 저장
- 그렇다보니 다양한 원인으로 상태 깨짐을 발생시킬 수 있다.
- 브로커의 갑작스러운 종료
- 클라이언트 네트워크 이슈
- 스트림즈 이슈 사례가 이번 발표 주제와 어떠한 연관이 있는지 궁금해 할 수 있음
- 클라우드의 다소 불안정한 네트워크 환경이 이슈의 가장 대표적인 원인. 실제로도 이러한 이슈가 발생
실제 이슈 사례
- 라이더 현황 집계 값이 음수가 나오는 현상
- 권역 내의 라이더가 -2
- 네트워크 통신이 일시적으로 불안정하여 브로커의 주키퍼 세션이 만료
- 세션 만료로 인한 클러스터 제외 이슈 발생
- -> 스트림즈가 상태 반영을 제대로 하지 못함
- -> 라이더 수의 집계값이 클러스터에 반영되지 못함
개선(고민) 3. 상태 복구 툴 활용
상태를 어떻게 복구할 수 있을까?
- kafka-streams-application-reset.sh 스크립트를 이용한 복구
- 카프카 소스에서 같이 제공됨
- 특정 시점부터 스트림즈 애플리케이션을 Replay
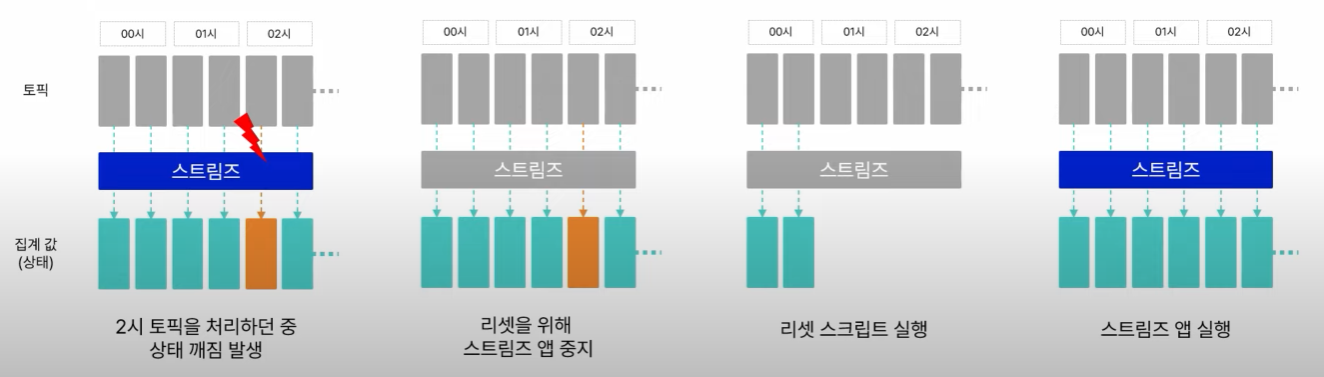
스트림즈 애플리케이션 Replay
- 상당한 공수가 필요한 작업
- 효율적인 방법에 대해 지속적인 고민 중
이외의 고민거리
- 토픽 메시지를 다른 클러스터로 쉽게 미러링하는 방법
- 클러스터 별 인증된 사용자만 접근할 수 있는 방법
- 파티션의 위치가 자동으로 관리되는 방법
- 컨슈머가 어느 팀에서 구성된건지 쉽게 알 수 있는 방법
- 토픽의 스키마를 중앙에서 관리할 수 있는 방법
- 사용자들이 좀 더 쉽게 리소스를 관리할 수 있는 방법
마무리
클라우드 환경에서 카프카 운영기
- 인프라 이슈를 추적/예상하기 힘든 클라우드 환경은 좀 더 높은 운영 난이도
- 게다가 관리할 리소스들이 많아지면서 이슈 빈도의 증가
- 하지만 신뢰성 있는 카프카를 제공하기 위해 지속적으로 고민하고 개선 중
