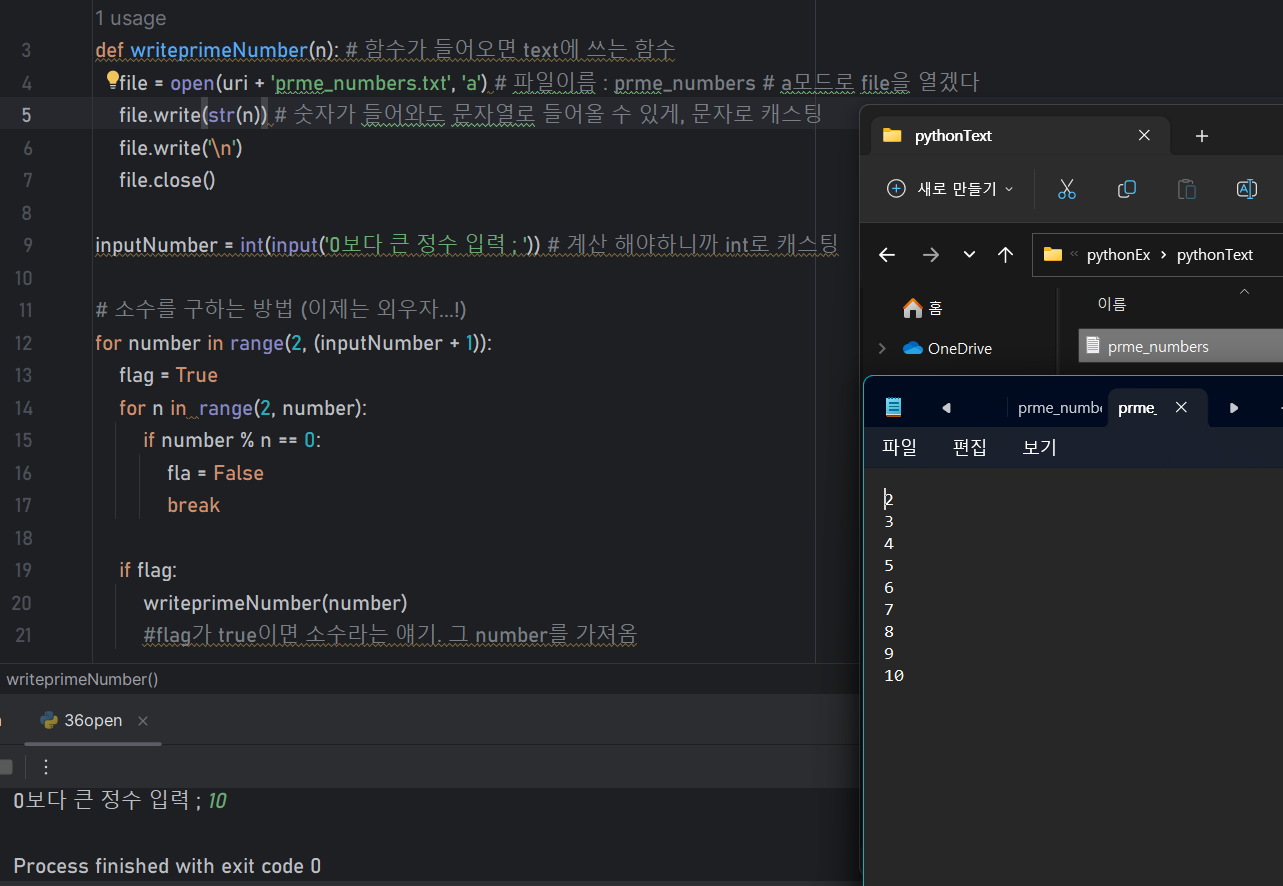
소수 구하는 방법! 이제는 외우자!!
세련되게? 간략하게 text 쓰는 방법을 알아보자!
file Mode (쓰기 전용)
📍 'w'
- 1. 파일이 없으면 새로 만듬
- 2. 파일이 있으면 기존 내용을 다 삭제하고 덮어 씌움
📍 'a'
- 기존 파일 내용이 있으면, 내용 다음에 새로운 글을 씀)
📍 'x'
- 파일이 있으면 error
- 없어야 하고, 새로 만들어서 써야 함
📍 'r'
- 파일이 있을 때만 읽을 수 있음📒text 쓰기
- write() 'w'
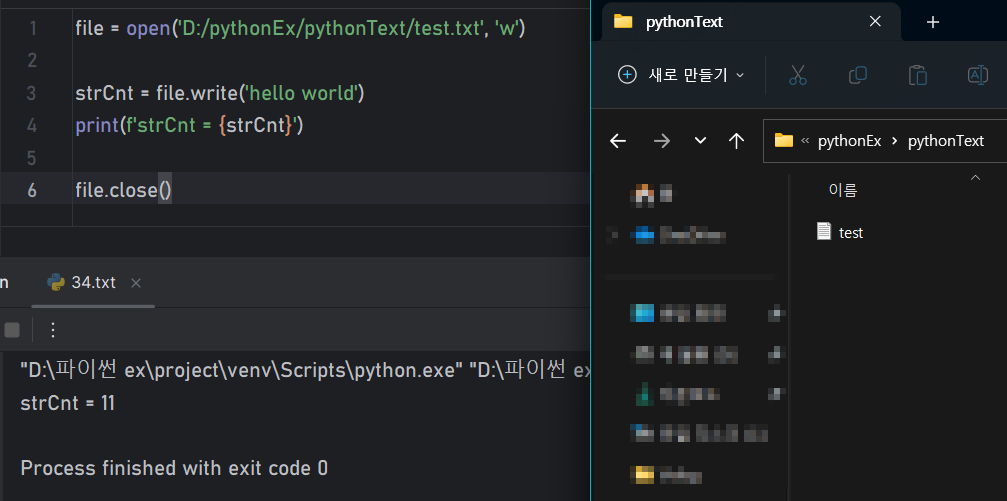
📝예제
📒text file 읽기
-
read() 'r'
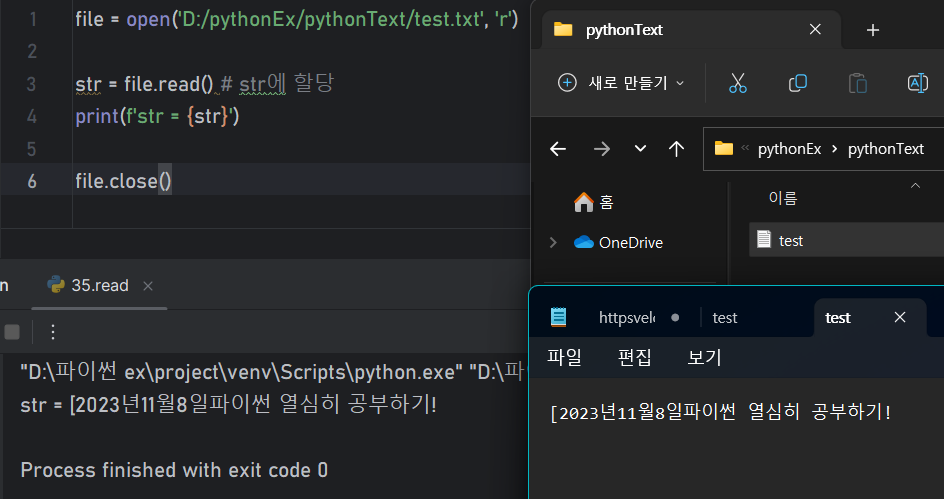
-
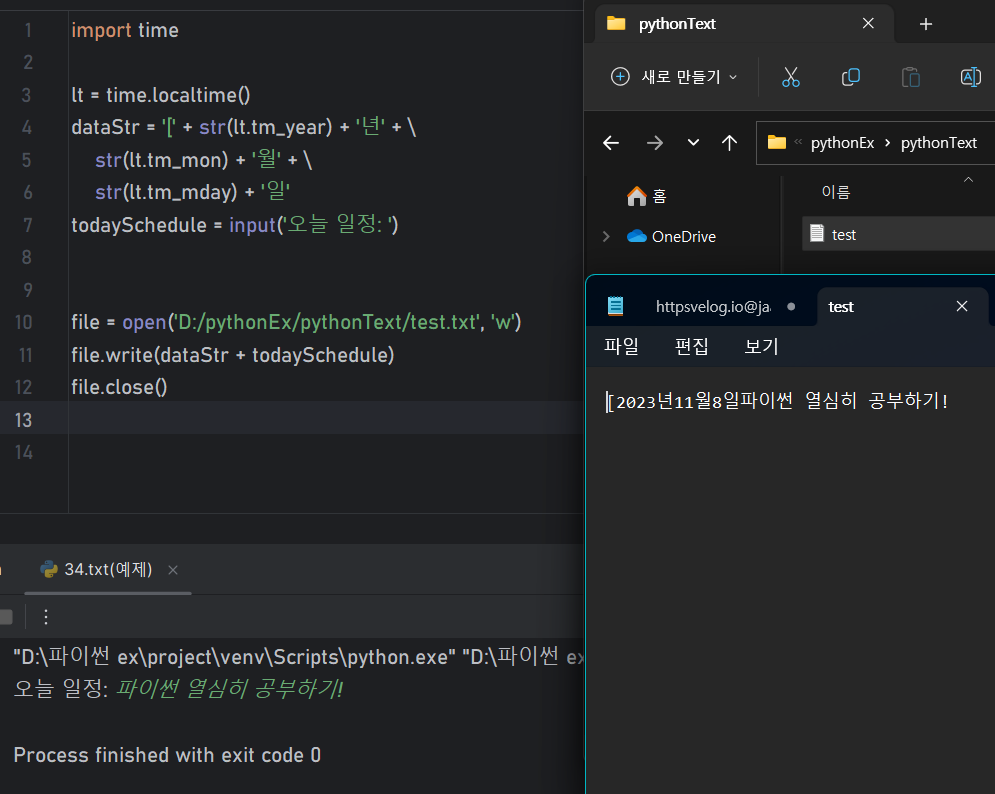
날짜 (Y:연, m:월, d:일, H:시간, M:분, S:초, d:오전/오후
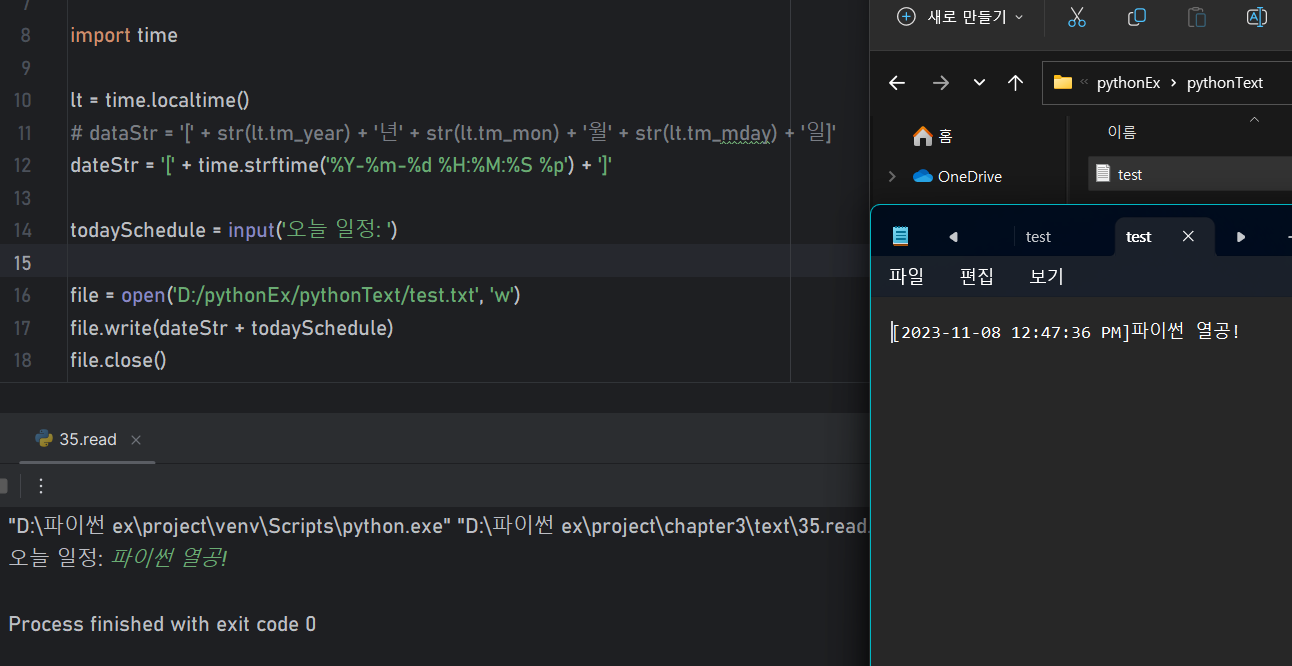
📒text file 예제
📒with ~ as문
file.close()를 하지 않아도 됨
- 일반적
uri = 'D:/pythonEx/pythonText/'
(1)
file = open(uri + 'with_as', 'a')
file.write('python study')
file.close()
(2)
file = open(uri + 'with_as', 'r')
file.read('python study')
file.close()- with ~ as문 (file.close() 생략 가능)
✅ 이 파일을 f라고 부르겠다.
✅ close를 하지 않아도 실행 됨
(1)
with open(uri + 'with_as', 'a') as f:
f.write('python study')
(2)
with open(uri + 'with_as', 'r') as f:
f.write('python study')
예제에 들어가기 앞서,
📌enumerate() 함수
리스트의 원소와 원소의 위치를 뜻하는 index를 동시에 처리해야 하는 경우, enumerate() 함수를 사용하면 원소와 index를 함께 출력할 수 있는 함수이다.
- 기본 구조는 enumerate( )이며, [반복문❗]과 함께 사용 된다.
- 즉 enumerate( )는 idx와 쓰이고, 변수 2개를 선언하는 것이 기본이다.📝예제 : 로또 번호 생성기
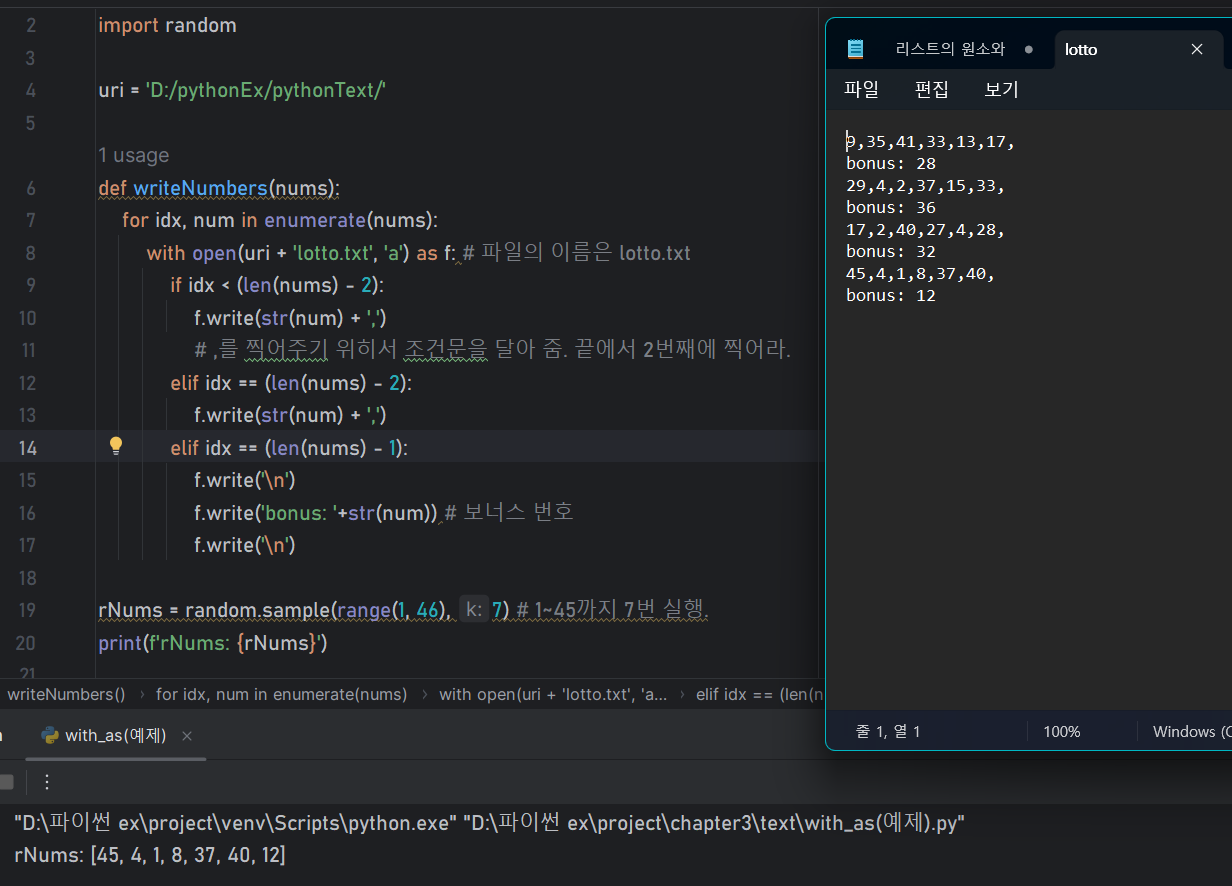
# 로또 번호 생성기
import random
uri = 'D:/pythonEx/pythonText/'
def writeNumbers(nums):
for idx, num in enumerate(nums):
with open(uri + 'lotto.txt', 'a') as f: # 파일의 이름은 lotto.txt
if idx < (len(nums) - 2):
f.write(str(num) + ',')
# ,를 찍어주기 위히서 조건문을 달아 줌. 끝에서 2번째에 찍어라.
elif idx == (len(nums) - 2):
f.write(str(num) + ',')
elif idx == (len(nums) - 1):
f.write('\n')
f.write('bonus: '+str(num)) # 보너스 번호
f.write('\n')
rNums = random.sample(range(1, 46), 7) # 1~45까지 7번 실행.
print(f'rNums: {rNums}')
writeNumbers(rNums)📒writelines()
반복문을 이용해, with open에서 'a'모드로 계속 누적해서 기록하면 모든 문자열이 차곡차곡 정리가 된다
이런 방법으로 반복 가능한 개체는 이런 방법으로 쓴다
파이썬은 'writelines()' 라는 함수를 제공해
더이상 for을 쓰지 않고, writelines()을 써서 반복 가능한 개체를 넣어주면 내부에서 알아서 반복 실행해서 파일에 써 줌
- 기존
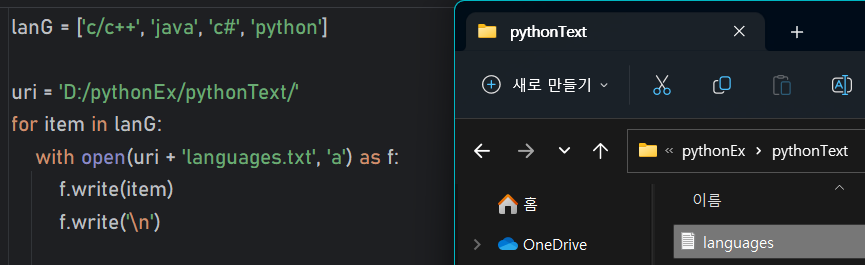
lanG = ['c/c++', 'java', 'c#', 'python']
uri = 'D:/pythonEx/pythonText/'
for item in lanG:
with open(uri + 'languages.txt', 'a') as f:
f.write(item)
f.write('\n')- writelines() 사용
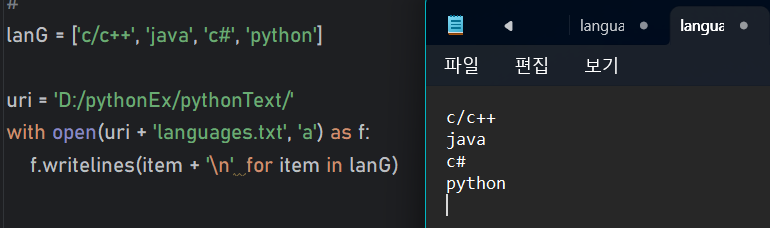
lanG = ['c/c++', 'java', 'c#', 'python']
uri = 'D:/pythonEx/pythonText/'
with open(uri + 'languages.txt', 'a') as f:
f.writelines(item + '\n' for item in lanG)
✅ f.writelines 사용할 때, [for]는 삭제
✅ 아이템을 개행해라 : item + '\n' for item in lanG📝예제
Q. 딕셔너리에 저장된 과목별 점수를 파일에 저장하는 코드 작성
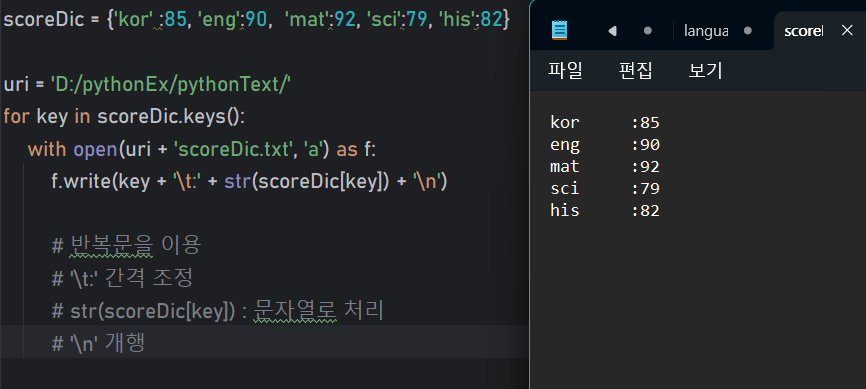
scoreDic = {'kor' :85, 'eng':90, 'mat':92, 'sci':79, 'his':82}
uri = 'D:/pythonEx/pythonText/'
for key in scoreDic.keys():
with open(uri + 'scoreDic.txt', 'a') as f:
f.write(key + '\t:' + str(scoreDic[key]) + '\n')
# 반복문을 이용
# '\t:' 간격 조정
# str(scoreDic[key]) : 문자열로 처리
# '\n' 개행📝응용1
Q. 딕셔너리에 저장된 과목별 점수를 파일에 저장하는 코드 작성
▶▶▶ 그대로 저장하고 싶다
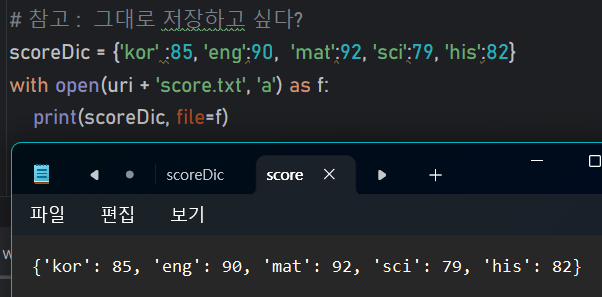
scoreDic = {'kor' :85, 'eng':90, 'mat':92, 'sci':79, 'his':82}
with open(uri + 'score.txt', 'a') as f:
print(scoreDic, file=f)📝응용2
Q. 딕셔너리에 저장된 과목별 점수를 파일에 저장하는 코드 작성
▶▶▶ 리스트를 써보고 싶다.
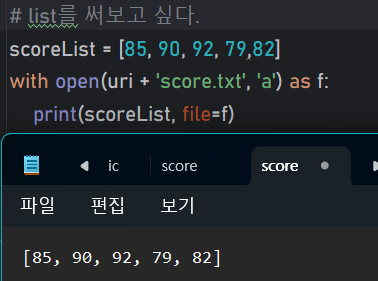
scoreList = [85, 90, 92, 79,82]
with open(uri + 'score.txt', 'a') as f:
print(scoreList, file=f)📒readlines()
파일의 모든 데이터를 읽어서 리스트 형태로 반환한다
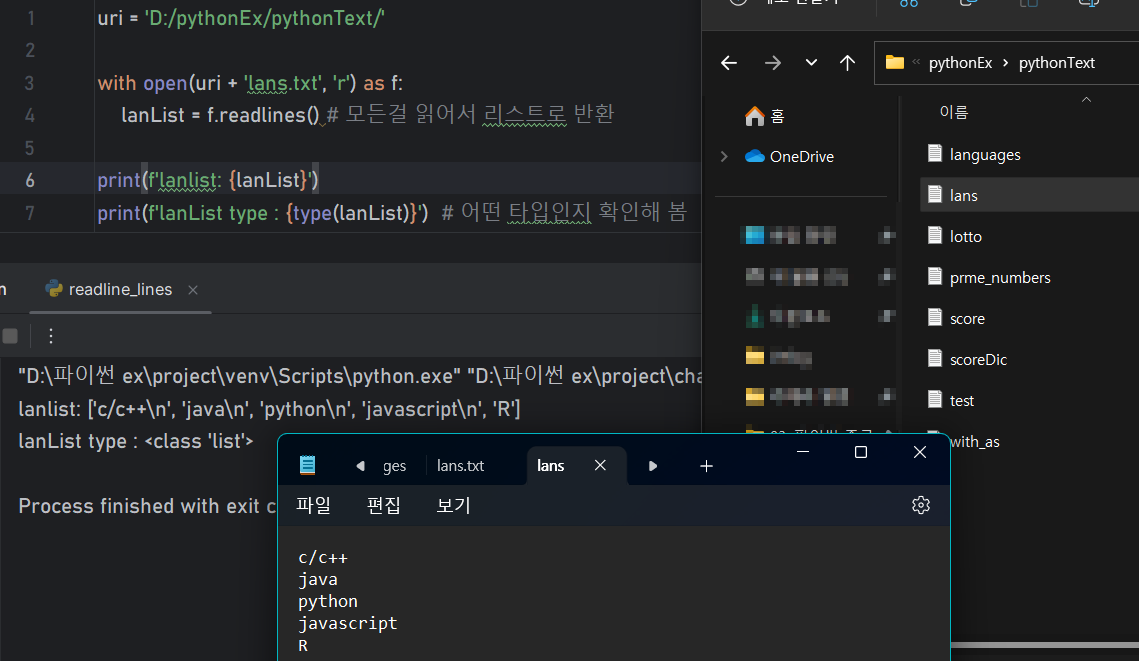
uri = 'D:/pythonEx/pythonText/'
with open(uri + 'lans.txt', 'r') as f:
lanList = f.readlines() # 모든걸 읽어서 리스트로 반환
print(f'lanlist: {lanList}')
print(f'lanList type : {type(lanList)}') # 어떤 타입인지 확인해 봄
예제에 들어가기 앞서,
📌split() 함수
000.split(':') -> :를 기점으로 앞뒤의 문자를 나눔
📌strip() 함수
strip 함수는 기본적으로 문자열에서 양 끝의 공백 문자를 삭제
📝예제
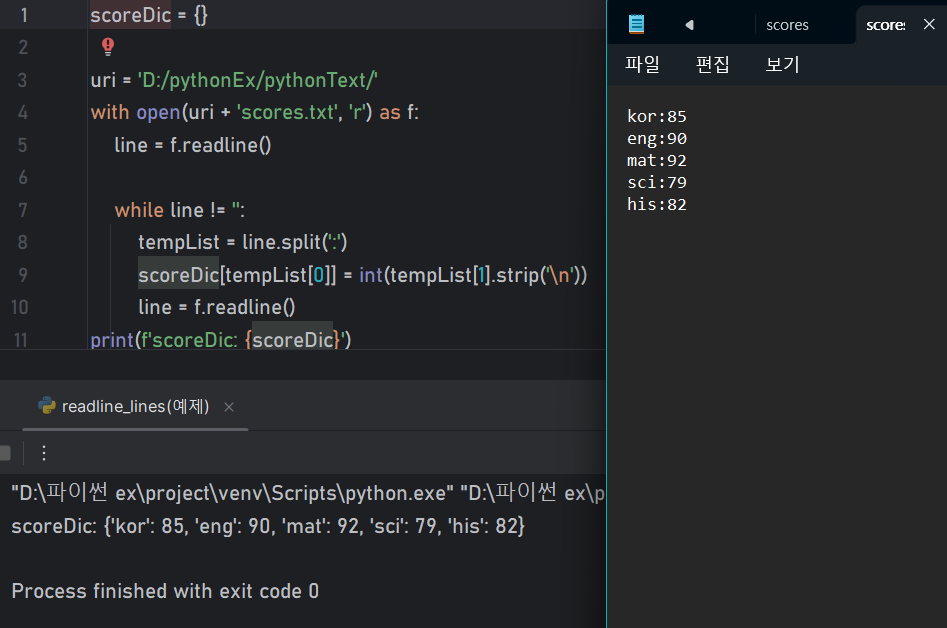
scoreDic = {}
uri = 'D:/pythonEx/pythonText/'
with open(uri + 'scores.txt', 'r') as f:
line = f.readline()
while line != '':
tempList = line.split(':')
scoreDic[tempList[0]] = int(tempList[1].strip('\n'))
line = f.readline()
print(f'scoreDic: {scoreDic}')# 제로베이스 데이터 취업 스쿨
# Daily study note

비전공자의 데이터 공부법