앙상블 ?

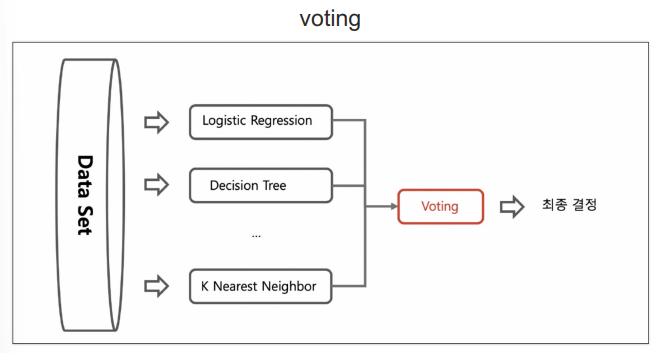
📌 앙상블 기법의 voting
- 전체 데이터 셋에서 각기 다른 알고리즘을 돌리는 것
- 아는 것 다 돌려보고 다수결에 의해서 최종결정 하겠다
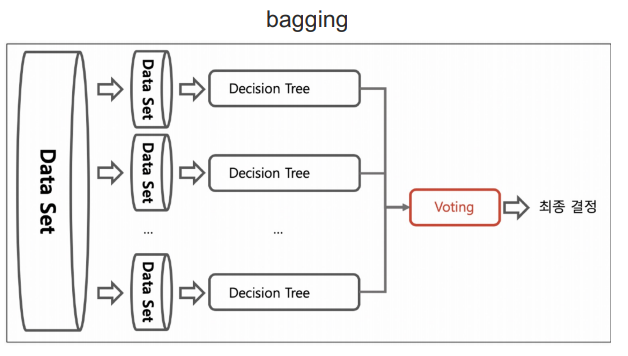
📌 bagging 기법
- bootstrapping : 중복을 허용해 샘플링 함
- 랜덤하게 샘플링된 데이터에 각각의 알고리즘을 붙여서 결과를 받아들임
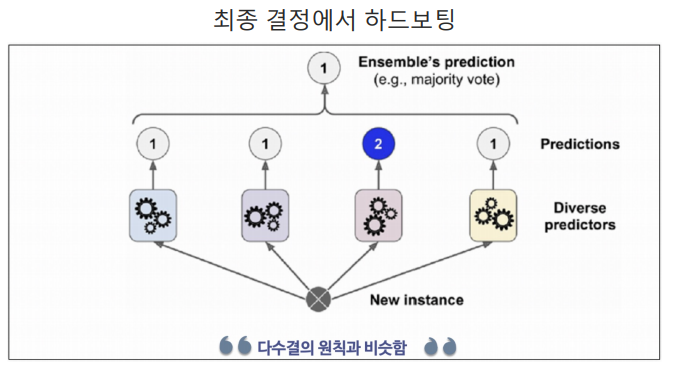
📌 결정 방법에서의 하드보팅
- 우리가 아는 다수결
- 모두가 1인데 하나가 2면, 2는 제거하고 1을 선택
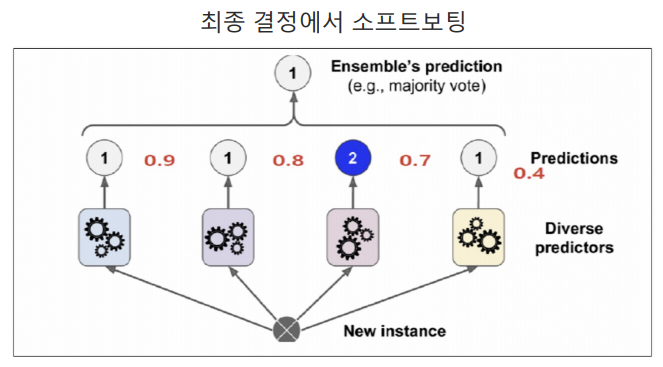
📌 소프트보팅
- 동일한 값의 확률 평균을 구해서, 다른 값과 비교
- 동점일 시 [다수결]을 따르고
- 더 높은 값이 있다면, 높은 점수를 선택
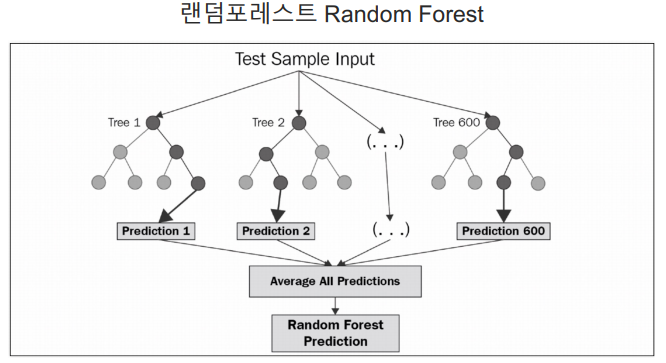
📌 랜덤포레스트
- DecisionTree(결정나무) 여러개를 사용해서 투표하는 방식
- bagging 기법의 대표적인 방법
HAR, Human Activity Recognition
-
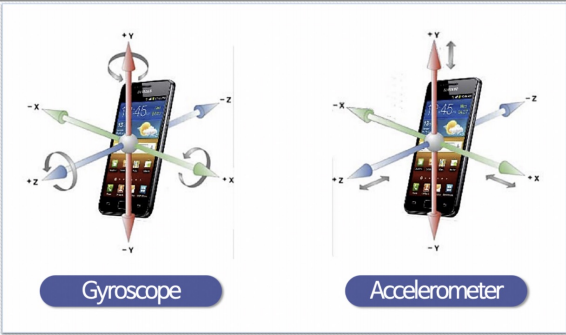
IMU 센서를 활용해서 사람의 행동을 인식하는 실험
-
폰에 있는 가속도/자이로 센서 사용
-
데이터 소개

- 데이터 특성

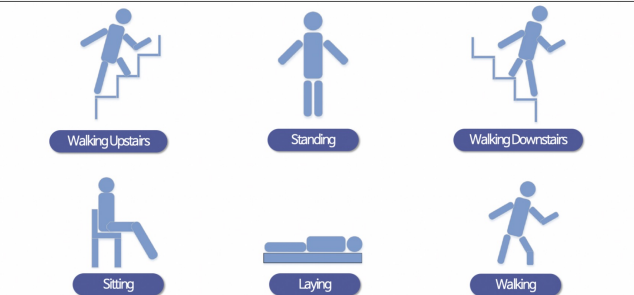
- 데이터 클래스
1) 데이터 읽기
import pandas as pd
import matplotlib.pyplot as plt
# txt 파일
url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/features.txt'
# '\s+' 공백, header 그대로, 컬럼 이름 names
feature_name_df = pd.read_csv(url, sep='\s+', header=None, names=['columns_index','columns_name'])
feature_name_df.head()2) 특성(feature) 갯수 확인
len(feature_name_df)3) 데이터 확인
# 밸류만 가지고 feature_name 추출 -> 즉, 앞으로 561개의 이름만 저장하게 됨
feature_name = feature_name_df.iloc[:, 1].values.tolist()
feature_name[:10]4) 일단 X데이터만
X_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/X_train.txt'
X_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/X_test.txt'
X_train = pd.read_csv(X_train_url, sep='\s+', header=None)
X_test = pd.read_csv(X_test_url, sep='\s+', header=None)5) 대용량 데이터 컬럼 확인
X_train.columns = feature_name
X_test.columns = feature_name
X_train.head()6) y 데이터 읽어오기
y_train_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/train/y_train.txt'
y_test_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/HAR_dataset/test/y_test.txt'
y_train = pd.read_csv(y_train_url, sep='\s+', header=None, names=['action'])
y_test = pd.read_csv(y_test_url, sep='\s+', header=None, names=['action'])7) shape - 개수 확인
X_train.shape, X_test.shape, y_train.shape, y_test.shape8) 각 action 별 데이터 수
y_train['action'].value_counts()- action
6 1407
5 1374
4 1286
1 1226
2 1073
3 986
Name: count, dtype: int64
9) DecisionTree 결정나무
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=13, max_depth=4)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy_score(y_test, pred)- 0.8096369189005769
10) Train - GridSearchCV (max_depth를 다양하게 하기 위해)
from sklearn.model_selection import GridSearchCV
params = {
'max_depth' : [6,8,10,12,16,20,24]
}
# scoring='accuracy': accuracy 계열은 기록해주세요
# cv=5 :KFold는 5개
grid_cv = GridSearchCV(dt_clf, param_grid=params, scoring='accuracy', cv=5, return_train_score=True)
grid_cv.fit(X_train, y_train)
11) Train 밸리데이션한 값의 best score & params 확인
grid_cv.best_score_, grid_cv.best_params_(0.8543335321892183, {'max_depth': 8})
12) Train max_depth별로 표로 성능을 정리
cv_result_df = pd.DataFrame(grid_cv.cv_results_)
cv_result_df[['param_max_depth', 'mean_test_score', 'mean_train_score']]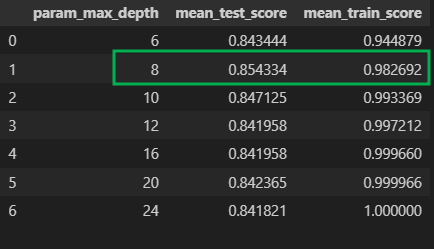
13) Test 데이터에서의 결과
max_depth = [6,8,10,12,16,20,24]
for depth in max_depth:
dt_clf = DecisionTreeClassifier(max_depth=depth, random_state=156)
dt_clf.fit(X_train, y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
print('Max_Depth =', depth, ', Accuracy =', accuracy)- Max_Depth = 6 , Accuracy = 0.8557855446216491
Max_Depth = 8 , Accuracy = 0.8707159823549372
Max_Depth = 10 , Accuracy = 0.8673227010519172
Max_Depth = 12 , Accuracy = 0.8646080760095012
Max_Depth = 16 , Accuracy = 0.8574821852731591
Max_Depth = 20 , Accuracy = 0.8547675602307431
Max_Depth = 24 , Accuracy = 0.8547675602307431
14) Test - 베스트 모델의 결과는
best_dt_clf = grid_cv.best_estimator_
pred1 = best_dt_clf.predict(X_test)
accuracy_score(y_test, pred1)0.8734306073973532
15) 랜덤포레스트 적용
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
params = {
'max_depth' : [6,8,10], # DecisionTree에 적용할 파라미터
'n_estimators' : [50,100,200], # DecisionTree에 tree 몇개
'min_samples_leaf' : [8,12], # DecisionTree에 맨끝 데이터(leaf) 최소 몇개
'min_samples_split' : [8,12] # 분할 기준에서 최소한으로 남는 데이터 수 (큰영향 X)
}
rf_clf = RandomForestClassifier(random_state=13, n_jobs=-1) # n_jobs=-1 : cpu core 다 써서
grid_cv = GridSearchCV(rf_clf, param_grid=params, cv=2, n_jobs=-1)
grid_cv.fit(X_train, y_train)
16) 결과 정리
cv_results_df = pd.DataFrame(grid_cv.cv_results_)
cv_result_df.columns- Index(['mean_fit_time', 'std_fit_time', 'mean_score_time', 'std_score_time',
'param_max_depth', 'params', 'split0_test_score', 'split1_test_score',
'split2_test_score', 'split3_test_score', 'split4_test_score',
'mean_test_score', 'std_test_score', 'rank_test_score',
'split0_train_score', 'split1_train_score', 'split2_train_score',
'split3_train_score', 'split4_train_score', 'mean_train_score',
'std_train_score'],
dtype='object')
17) target_cols 지정 & 순위 메기기
# mean_test_score : train 데이터의 validation score (아까는 85% 였는데, randomforest하니까 90% 이상)
# param_n_estimators : 몇개의 나무
target_cols = ['rank_test_score', 'mean_test_score', 'param_n_estimators', 'param_max_depth']
cv_results_df[target_cols].sort_values('rank_test_score').head()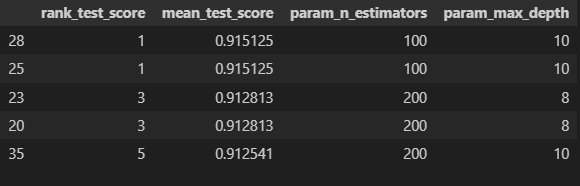
18) best 찾기
grid_cv.best_params_, grid_cv.best_score_- ({'max_depth': 10,
'min_samples_leaf': 8,
'min_samples_split': 8,
'n_estimators': 100},
0.9151251360174102)
19) Test 데이터에 적용
rf_clf_best = grid_cv.best_estimator_
rf_clf_best.fit(X_train, y_train)
pred1 = rf_clf_best.predict(X_test)
accuracy_score(y_test, pred1)0.9205972175093315
20) 중요특성 확인
# 베스트 모델에서 랜덤포레스트를 반환(feature_importances_) 받아서
best_cols_values = rf_clf_best.feature_importances_
# 영향력이 높은(best_cols_values) feature만 추려서
best_cols = pd.Series(best_cols_values, index=X_train.columns)
# 정렬(sort_values) 한 다음에 20개만 출력
top20_cols = best_cols.sort_values(ascending=False)[:20]
top20_cols- angle(X,gravityMean) 0.034638
tGravityAcc-max()-Y 0.032518
tGravityAcc-energy()-X 0.031309
tGravityAcc-mean()-X 0.029513
tGravityAcc-min()-X 0.027775
tGravityAcc-max()-X 0.027662
angle(Y,gravityMean) 0.026553
tGravityAcc-mean()-Y 0.026052
tGravityAcc-min()-Y 0.023037
tGravityAcc-energy()-Y 0.018678
tGravityAcc-mean()-Z 0.015688
angle(Z,gravityMean) 0.012837
fBodyAcc-mad()-X 0.012558
tBodyAcc-max()-X 0.011970
fBodyAccJerk-bandsEnergy()-1,24 0.011803
tBodyAccJerk-entropy()-X 0.011647
tGravityAccMag-std() 0.011451
tBodyAccJerk-energy()-X 0.011333
tGravityAcc-arCoeff()-Z,1 0.011257
fBodyAccJerk-max()-X 0.011040
dtype: float64
21) 주요 특성 확인
import seaborn as sns
plt.figure(figsize=(8, 8))
sns.barplot(x=top20_cols, y=top20_cols.index)
plt.show()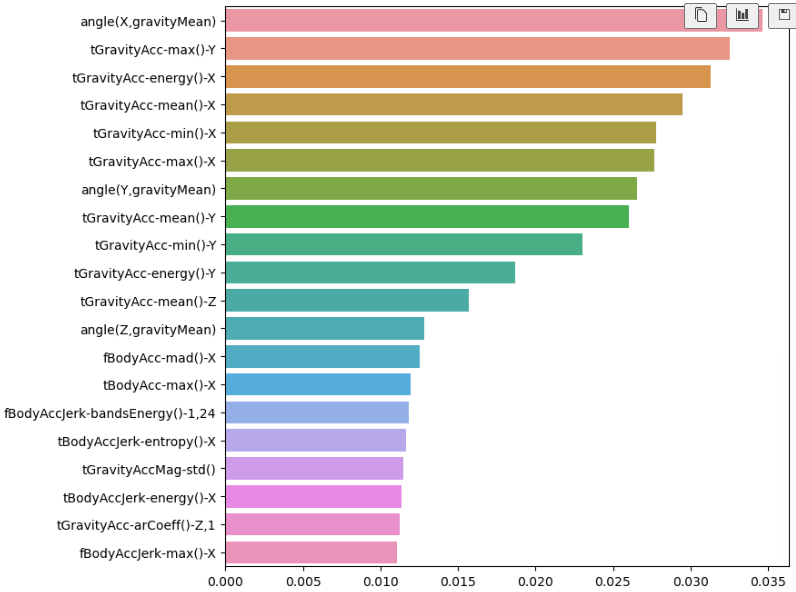
22) 주요 특성 20 가지
- 561개를 굳이 다써야 하나? 아래 그래프를 보아 하니 주요 특성 몇가지만 가지고 봐도 될 것 같음
- 따라서 20개로 보고자 함
top20_cols.index- Index(['angle(X,gravityMean)', 'tGravityAcc-max()-Y', 'tGravityAcc-energy()-X',
'tGravityAcc-mean()-X', 'tGravityAcc-min()-X', 'tGravityAcc-max()-X',
'angle(Y,gravityMean)', 'tGravityAcc-mean()-Y', 'tGravityAcc-min()-Y',
'tGravityAcc-energy()-Y', 'tGravityAcc-mean()-Z',
'angle(Z,gravityMean)', 'fBodyAcc-mad()-X', 'tBodyAcc-max()-X',
'fBodyAccJerk-bandsEnergy()-1,24', 'tBodyAccJerk-entropy()-X',
'tGravityAccMag-std()', 'tBodyAccJerk-energy()-X',
'tGravityAcc-arCoeff()-Z,1', 'fBodyAccJerk-max()-X'],
dtype='object')
23) 20개 특성으로 다시 확인
X_train_re = X_train[top20_cols.index]
X_test_re = X_test[top20_cols.index]
rf_clf_best_re = grid_cv.best_estimator_
rf_clf_best_re.fit(X_train_re, y_train.values.reshape(-1, ))
pred1_re = rf_clf_best_re.predict(X_test_re)
accuracy_score(y_test, pred1_re)0.8177807940278249

비전공자의 데이터 공부법