kNN 이란?
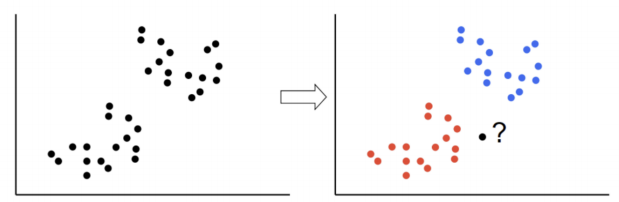
- 새로운 데이터가 있을 때, 기존 데이터의 그룹 중 어떤 그룹에 속하는지 분류하는 문제
- k는 몇 번째 가까운 데이터까지 볼 것인가를 정하는 수치
- 즉, 쉽게 말해 새로운 데이터(검은점)이 빨강-파랑 중 어디로 분류 되는지 정하는 것
- 더 간단히 말해, K값을 설정하고, 그 값에 가까이 있는 애로 분류할게~
더 자세히 볼까요???
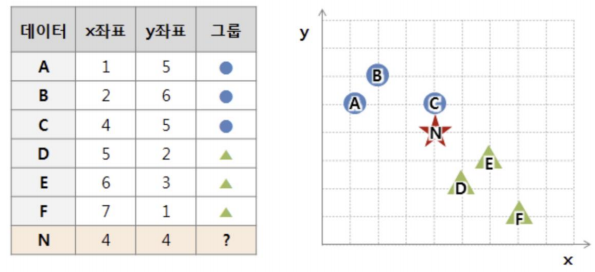
N은 파랑과 녹색 중 어디 일까?
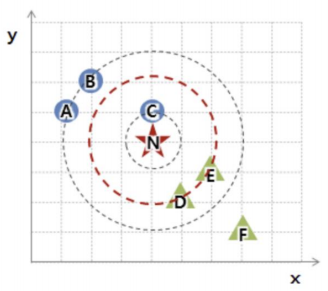
-
2번째 거리에 가깝게 설정 ; 세모 그룹
-
3번째 거리에 가깝게 설정 ; 동그라미 그룹
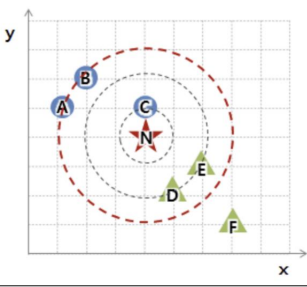
💡따라서 k값(거리)는 표준화!! 해주는 것이 상당히 중요하다
kNN 장단점
- 실시간 예측을 위한 학습이 필요치 않다
- 결국 속도가 빨라진다
- 고차원 데이터에는 적합하지 않다
실습 _ iris
from sklearn.datasets import load_iris
iris = load_iris()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=13, stratify=iris.target
)# 1) kNN 학습
from sklearn.neighbors import KNeighborsClassifier
# n_neighbors= : 몇개 까지 가까운걸 찾을래?
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)# 2) accuracy 확인
from sklearn.metrics import accuracy_score
pred = knn.predict(X_test)
print(accuracy_score(y_test, pred))0.9666666666666667
# 3) 간단한 성과 (?)
from sklearn.metrics import (classification_report, confusion_matrix)
print(confusion_matrix(y_test, pred))
print(classification_report(y_test, pred))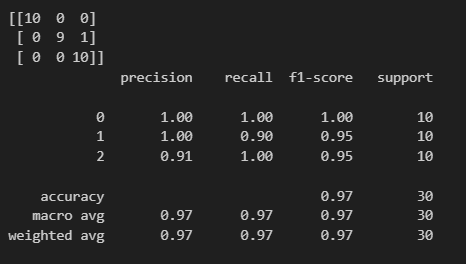
간단한 ㄷ이터를 다룰 때 kNN은 큰 두각을 나타내지 못합니다...
다음 언젠가 실습 시 두각을 나타내는 결과를 보길 기대하며..

비전공자의 데이터 공부법