install
# 가장 최신 버전으로 유지
!conda update conda
!pip install --upgrade pip
# 한글 자연어 처리 패키지
!pip install konlpy
!pip install tweepy==3.10.0
!conda install -y -c conda-forge jpype1==1.0.2
!conda install -y -c conda-forge wordcloud
!conda install -y nltk
!conda install -y scikit-learnimport nltk
nltk.download()from konlpy.tag import Okt
t = Okt()Kkma
from konlpy.tag import Kkma
kkma = Kkma()# 문장(sentences)
kkma.sentences('한국어 분석을 시작합니다 재미있어요 ~')['한국어 분석을 시작합니다', '재미있어요 ~']
# 명사(nouns)
kkma.nouns('한국어 분석을 시작합니다 재미있어요 ~')['한국어', '분석']
# 형태소분석(pos)
kkma.pos('한국어 분석을 시작합니다 재미있어요 ~')[('한국어', 'NNG'),
('분석', 'NNG'),
('을', 'JKO'),
('시작하', 'VV'),
('ㅂ니다', 'EFN'),
('재미있', 'VA'),
('어요', 'EFN'),
('~', 'SO')]
Hannanum
from konlpy.tag import Hannanum
hannanum = Hannanum()hannanum.nouns('한국어 분석을 시작합니다 재미있어요 ~')['한국어', '분석', '시작']
hannanum.morphs('한국어 분석을 시작합니다 재미있어요 ~')['한국어', '분석', '을', '시작', '하', 'ㅂ니다', '재미있', '어', '요', '~']
hannanum.pos('한국어 분석을 시작합니다 재미있어요 ~')[('한국어', 'N'),
('분석', 'N'),
('을', 'J'),
('시작', 'N'),
('하', 'X'),
('ㅂ니다', 'E'),
('재미있', 'P'),
('어', 'E'),
('요', 'J'),
('~', 'S')]
Okt
# UserWarning: "Twitter" has changed to "Okt" since KoNLPy v0.4.5. warn('"Twitter" has changed to "Okt" since KoNLPy v0.4.5.')
from konlpy.tag import Okt
t = Okt()t.nouns('한국어 분석을 시작합니다 재미있어요 ~')['한국어', '분석', '시작']
t.morphs('한국어 분석을 시작합니다 재미있어요 ~')['한국어', '분석', '을', '시작', '합니다', '재미있어요', '~']
t.pos('한국어 분석을 시작합니다 재미있어요 ~')[('한국어', 'Noun'),
('분석', 'Noun'),
('을', 'Josa'),
('시작', 'Noun'),
('합니다', 'Verb'),
('재미있어요', 'Adjective'),
('~', 'Punctuation')]
1.워드클라우드 wordcloud
- 중요하지 않은 영어 단어들을 제거하는 역할
from wordcloud import WordCloud, STOPWORDS
import numpy as np
from PIL import Image# 소설 읽어오기
text = open("./15. alice.txt").read()
# 이미지 읽어오기
alice_mask = np.array(Image.open("./15. alice_mask.png"))
# said 단어 제거
stopwords = set(STOPWORDS)
stopwords.add('said')import platform
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
path = "c:/Windows/Fonts/malgun.ttf"
if platform.system() == "Darwin":
print("Hangle OK in your MAC!!!")
rc("font", family="AppleGothic")
elif platform.system() == "Windows":
font_name = font_manager.FontProperties(fname=path).get_name()
print("Hangle OK in your Windows!!!")
rc("font", family=font_name)
else:
print("Sorry, Unkwnown System")
plt.rcParams["axes.unicode_minus"] = FalseHangle OK in your Windows!!!
plt.figure(figsize=(8,8))
plt.imshow(alice_mask, cmap=plt.cm.gray, interpolation='bilinear')
# plt.axis('off')
plt.show()
# WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다
wc = WordCloud(
background_color='white', max_words=2000, mask=alice_mask, stopwords=stopwords
)
wc = wc.generate(text)
wc.words_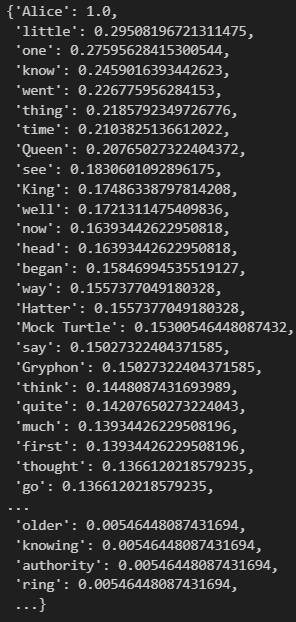
plt.figure(figsize=(8,8))
plt.imshow(wc,interpolation='bilinear')
# plt.axis('off')
plt.show()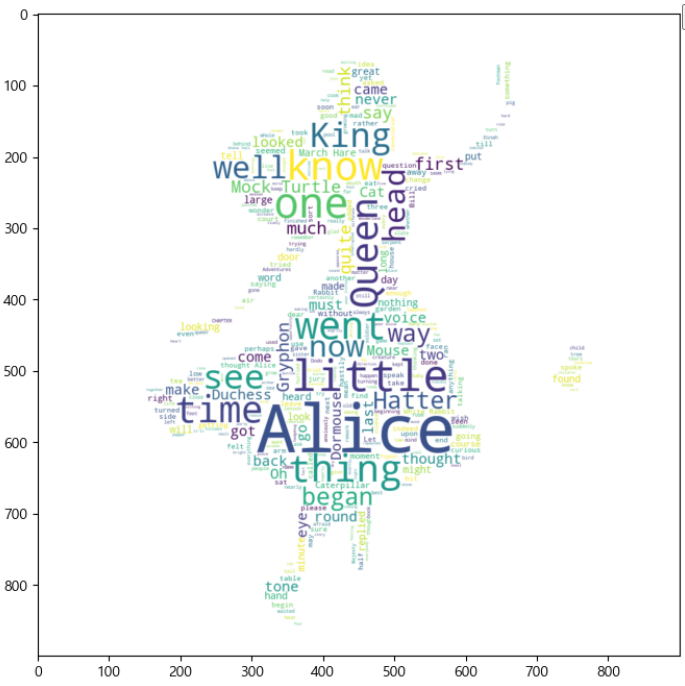
import nltk
from konlpy.corpus import kobill
files_ko = kobill.fileids()
doc_ko = kobill.open('1809890.txt').read()
doc_ko명사분석
from konlpy.tag import Okt
t = Okt()
token_ko = t.nouns(doc_ko)
token_ko # 명사 단어들의 집합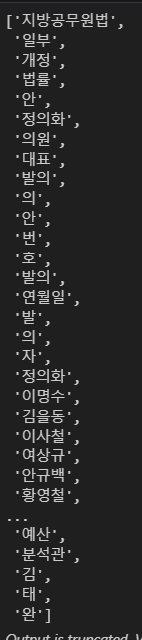
빈도수분석
ko = nltk.Text(token_ko, name='육아휴직법')
#token_ko : 명사 단어들의 집합# 이 문자열 단위 : token
print(len(ko.tokens)) # 사용된 단어들
print(len(set(ko.tokens))) # 중복 제외 단어들
ko.vocab() # 어떤 단어들이 있나요? : vocab(단어의 집합)
plt.figure(figsize=(12,6))
ko.plot(50)
plt.show()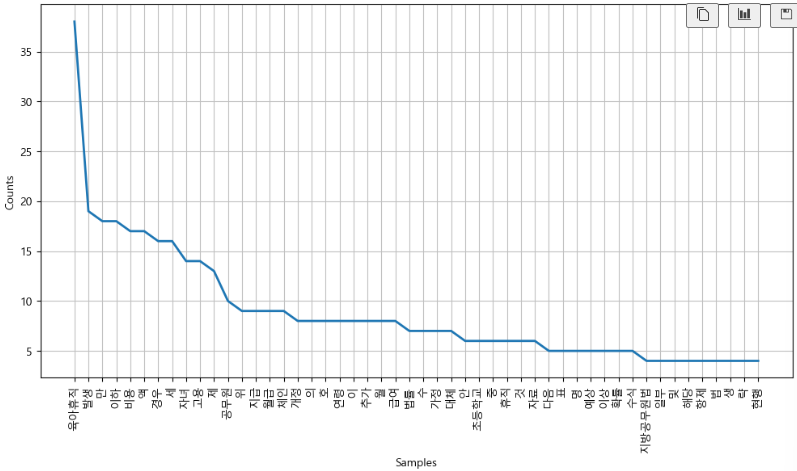
# 제거할 글자들
stop_words = [
'의', '.', '(', ')', ',', '%', '-', 'X', ').', 'x', '의',
'안', '번', '호', '발', '의', '자', '가', '를', '만', '을',
'다', '인', '김', '태', '완', '및', '정', '문', '종', '팀',
'장', '위', '의 ', '호']
ko = [each_word for each_word in ko if each_word not in stop_words]
ko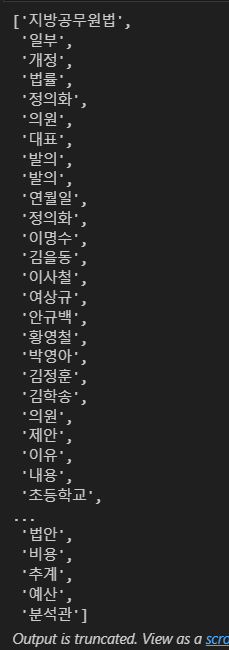
ko = nltk.Text(ko, name='대한민국 국회 의안 제 1809890호')
plt.figure(figsize=(12,6))
ko.plot(50)
plt.show()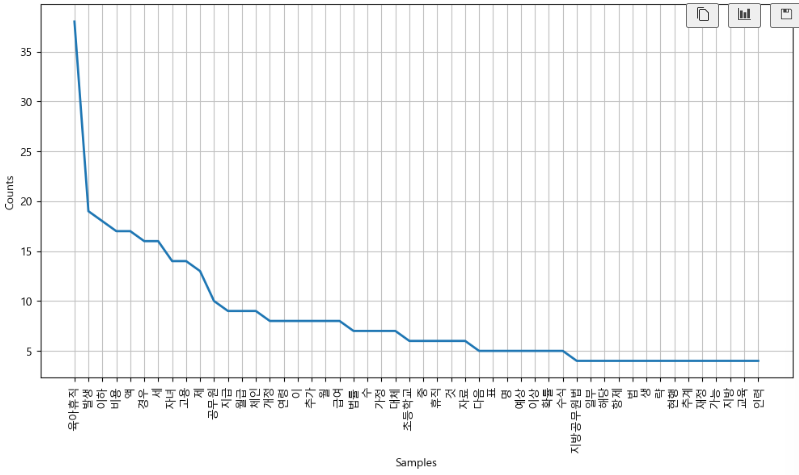
특정단어 빈도수 조사/조회
ko.count('고용')14
plt.figure(figsize=(12,6))
ko.dispersion_plot(['육아휴직','자녀','고용']) # dispersion_plot : 어디쯤에 위치한지 알려줌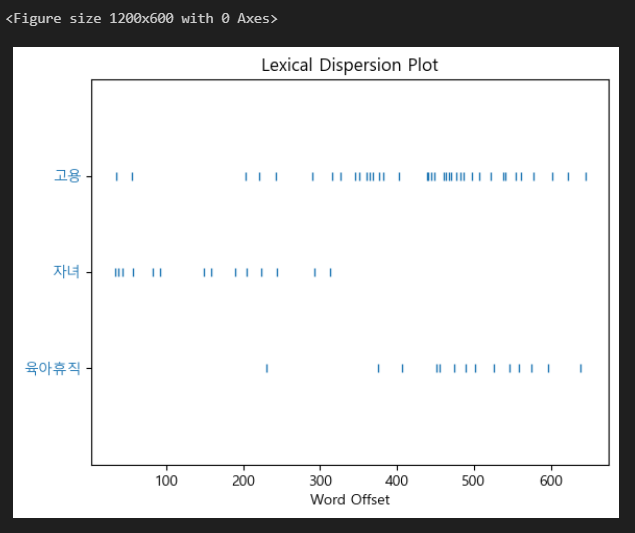
ko.concordance('고용') # 좌우 글자를 보여줘, 문맥을 파악하는데 도움을 줌
연관있어보이는 단어들 출력
ko.collocations()
워드클라우드 출력
data = ko.vocab().most_common(150)
# WordCloud 모듈은 자체적으로 단어를 추출해서 빈도수를 조사하고 정규화하는 기능을 가지고 있다
wordcloud = WordCloud(
font_path = "c:/Windows/Fonts/malgun.ttf",
relative_scaling=0.2, # 글자 간격
background_color='white'
).generate_from_frequencies(dict(data))
plt.figure(figsize=(12,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
2. 나이브베이즈 분류
나이브베이즈 분류를 이용한 감성분석
✍🏻 영어 ver.
from nltk.tokenize import word_tokenize
import nltktrain = [
('i like you', 'pos'),
('i hate you', 'neg'),
('you like me', 'neg'),
('i like her', 'pos')
]말뭉치 만들기
train[0]'i like you'
sentence = train[0]
word_tokenize(sentence[0]) #word_tokenize : 글자 분리['i', 'like', 'you']
# set 명령으로 인해 중복 없이 출력
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
all_words{'hate', 'her', 'i', 'like', 'me', 'you'}
말 뭉치에서 각 단어 유무 파악
- train 에서 x(=문장)를 하나씩 가져올 것임
- x[0](첫문장의 첫번쨰 것)을 띄어쓰기로 분리(word_tokenize)하고,
- all_words에 있는 모든 단어(word)를 가지고 2.에 있는지 확인
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
t[({'her': False,
'i': True,
'me': False,
'like': True,
'you': True,
'hate': False},
'pos'),
({'her': False,
'i': True,
'me': False,
'like': False,
'you': True,
'hate': True},
'neg'),
({'her': False,
'i': False,
'me': True,
'like': True,
'you': True,
'hate': False},
'neg'),
({'her': True,
'i': True,
'me': False,
'like': True,
'you': False,
'hate': False},
'pos')]
훈련 시작
- like가 있을 때 positive할 확률이 1.7 : 1
classifier = nltk.NaiveBayesClassifier.train(t) # 학습
classifier.show_most_informative_features() # 가장 많은 정보를 담고 있는 특성을 나열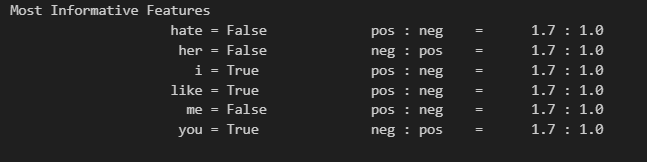
테스트 시작
test_sentence = "i like MeRui"
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features{'her': False,
'i': True,
'me': False,
'like': True,
'you': False,
'hate': False}
결과
classifier.classify(test_sent_features)'pos'
✍🏻 한글 ver.
from konlpy.tag import Okt
pos_tagger = Okt()
train = [
('메리가 좋아','pos'),
('고양이도 좋아','pos'),
('난 수업이 지루해','neg'),
('메리는 이쁜 고양이야', 'pos'),
('난 마치고 메리랑 놀거야','pos')
]
all_words = set(
word.lower() for sentence in train for word in word_tokenize(sentence[0])
)
t = [({word: (word in word_tokenize(x[0])) for word in all_words}, x[1]) for x in train]
classifier = nltk.NaiveBayesClassifier.train(t)
classifier.show_most_informative_features()
test_sentence = "난 수업이 마치면 메리랑 놀거야"
test_sent_features = {
word.lower(): (word in word_tokenize(test_sentence.lower())) for word in all_words
}
test_sent_features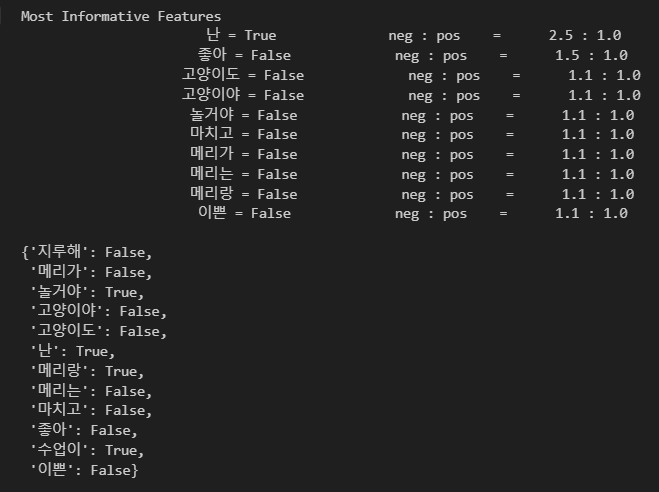
classifier.classify(test_sent_features)'neg'
Negative가 떴으니, 형태소 분석을 통해 정확히 맞혀보자
형태소분석
형태소 분석을 한 뒤 품사를 단어 뒤에 붙여봄
def tokenize(doc):
return["/".join(t) for t in pos_tagger.pos(doc, norm=True, stem=True)]train_docs = [(tokenize(row[0]), row[1]) for row in train]
train_docs[(['메리/Noun', '가/Josa', '좋다/Adjective'], 'pos'),
(['고양이/Noun', '도/Josa', '좋다/Adjective'], 'pos'),
(['난/Noun', '수업/Noun', '이/Josa', '지루하다/Adjective'], 'neg'),
(['메리/Noun', '는/Josa', '이쁘다/Adjective', '고양이/Noun', '야/Josa'], 'pos'),
(['난/Noun', '마치/Noun', '고/Josa', '메리/Noun', '랑/Josa', '놀다/Verb'], 'pos')]
말뭉치 만들기
tokens = [t for d in train_docs for t in d[0]]
tokens['메리/Noun',
'가/Josa',
'좋다/Adjective',
'고양이/Noun',
'도/Josa',
'좋다/Adjective',
'난/Noun',
'수업/Noun',
'이/Josa',
'지루하다/Adjective',
'메리/Noun',
'는/Josa',
'이쁘다/Adjective',
'고양이/Noun',
'야/Josa',
'난/Noun',
'마치/Noun',
'고/Josa',
'메리/Noun',
'랑/Josa',
'놀다/Verb']
def term_exists(doc):
return{word: (word in set(doc)) for word in tokens}
train_xy = [(term_exists(d),c) for d,c in train_docs]
train_xy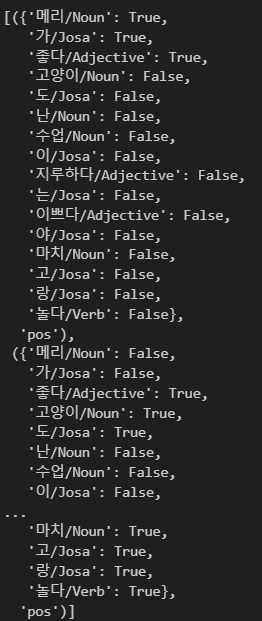
classifier = nltk.NaiveBayesClassifier.train(train_xy)
test_sentence = "난 수업이 마치면 메리랑 놀거야"
test_docs = pos_tagger.pos(test_sentence[0])
test_docs
classifier.show_most_informative_features()
test_sent_features = {word: (word in tokens) for word in test_docs}
test_sent_features
classifier.classify(test_sent_features)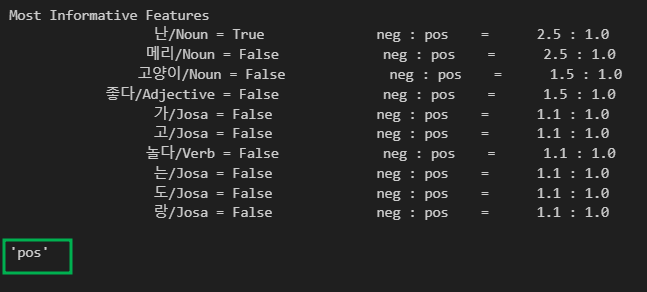
3. 문장의 유사도 측정
count vectorize
tfidf vectorize
네이버 API를 통해 유사 질문 찾기
