이번 강의에서는 지연 로딩과 조회 성능 최적화에 대해 다루는 법을 볼 것이다.
이때 주의하여야 할 점은, @xxToOne 과 같이 하나의 객체가 나오는 매핑과 @xxToMany와 같이 컬렉션으로 나오는 경우에 대해 처리 방법이 다르다는 것이다.
준비하기
애플리케이션 구현과 동시에 사전 데이터를 넣는 과정을 알아보자.
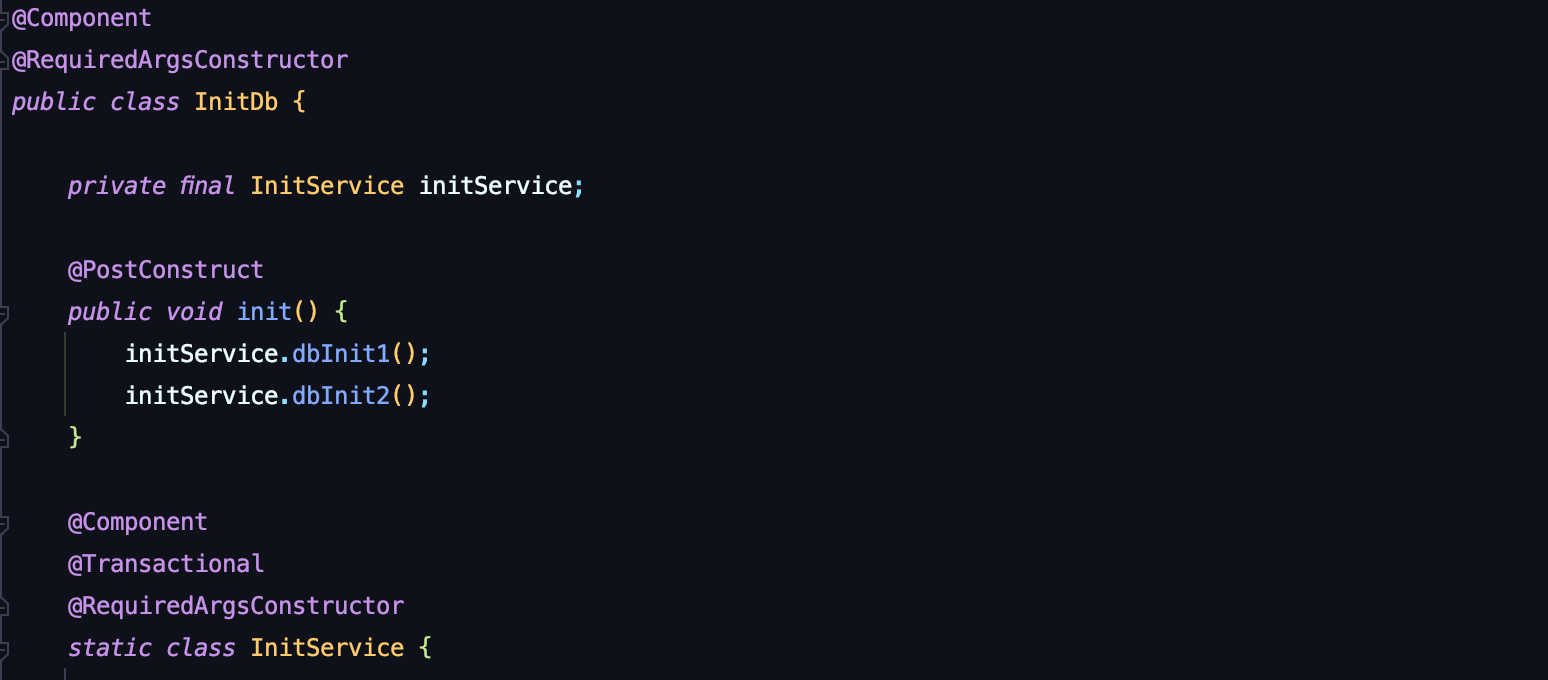
초기 설정을 할 데이터를 static 클래스로 미리 선언해두고,
@PostConstruct 어노테이션을 통해, 애플리케이션을 실행하며 자동으로 초기화 하게 한다.
xxToOne
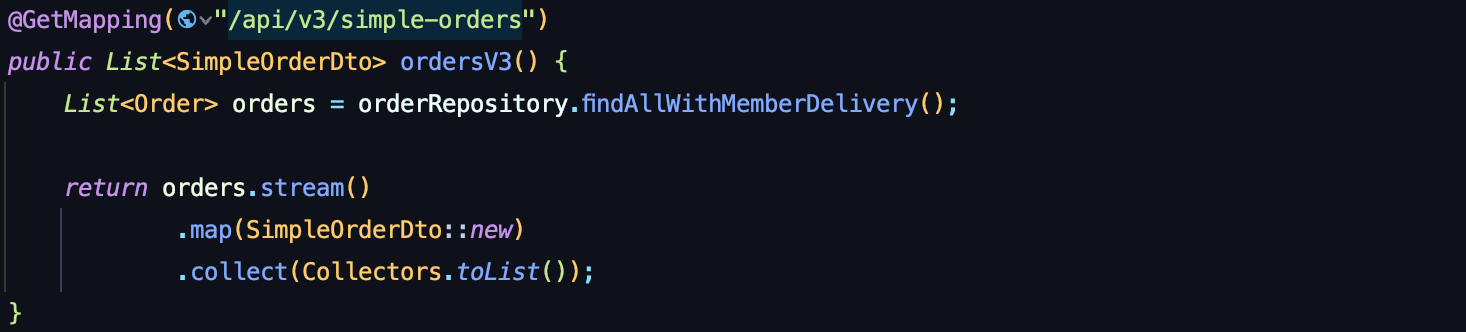

Order와 연관된 Member와 Delivery 클래스들을 fetch 조인으로 가져온다.
fetch 조인 속성은 fetchType.LAZY 보다 우선이기 때문에, 실제 값들을 가져오게되고, 쿼리가 1개만 나가는 것을 볼 수 있다.
가장 심플한 방법이다.
DTO 직접 조회

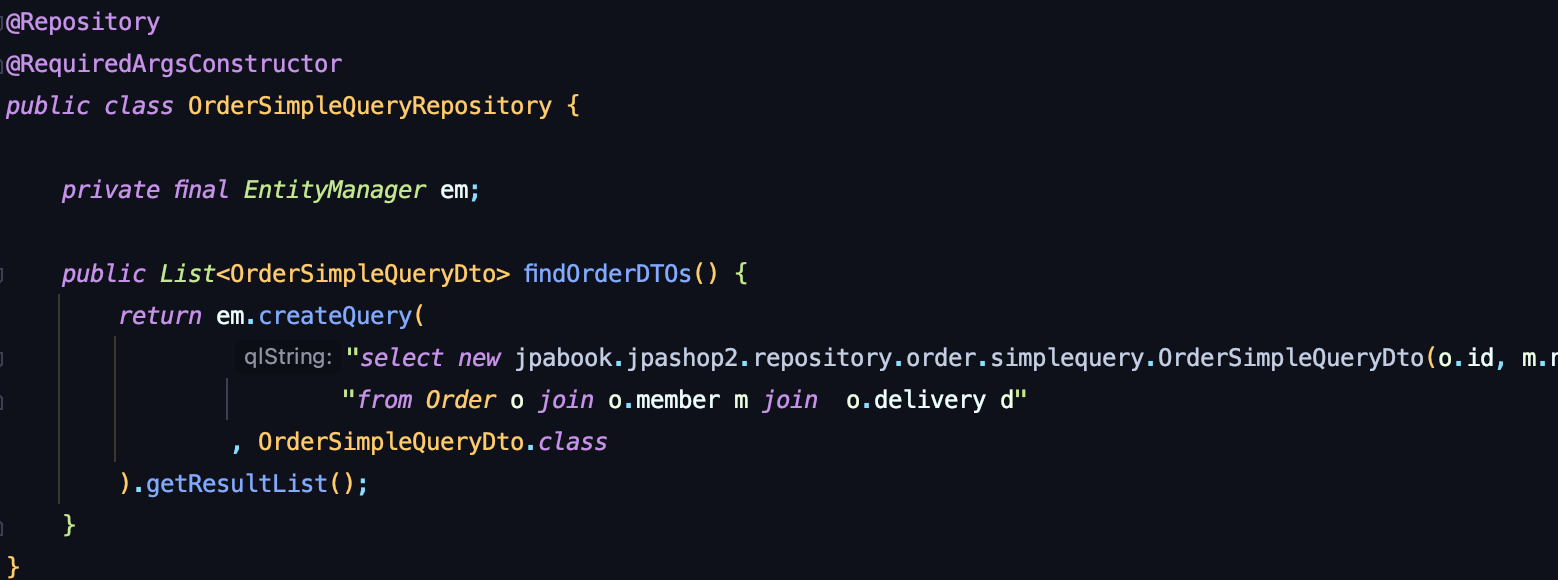
이 방법은 조회 쿼리를 위한 DTO를 새로 작성하고, 쿼리 내에서 이 DTO를 바로 생성하여 리턴해주는 방식이다.
하지만 쿼리를 다 작성해서 뽑아오는거라 재사용이 힘들다.
위의 V3는 원하는것만 페치 조인으로 뽑아와서 튜닝한거라 재사용이 가능하다.
3,4는 우열을 가리기 힘들다.
각각의 트레이드 오프가 있기때문에 상황에 맞게 잘 사용해야 한다.
정리
엔티티를 DTO로 변환하거나, DTO로 바로 조회하는 두가지 방법은 각각 장단점이 있다. 둘중 상황에 따라서 더 나은 방법을 선택하면 된다. 엔티티로 조회하면 리포지토리 재사용성도 좋고, 개발도 단순해진다. 따라서 권장하는 방법은 다음과 같다.
쿼리 방식 선택 권장 순서
1. 우선 엔티티를 DTO로 변환하는 방법을 선택한다.
2. 필요하면 페치 조인으로 성능을 최적화 한다. 대부분의 성능 이슈가 해결된다.
3. 그래도 안되면 DTO로 직접 조회하는 방법을 사용한다.
4. 최후의 방법은 JPA가 제공하는 네이티브 SQL이나 스프링 JDBC Template을 사용해서 SQL을 직접 사용한다.
xxToMany
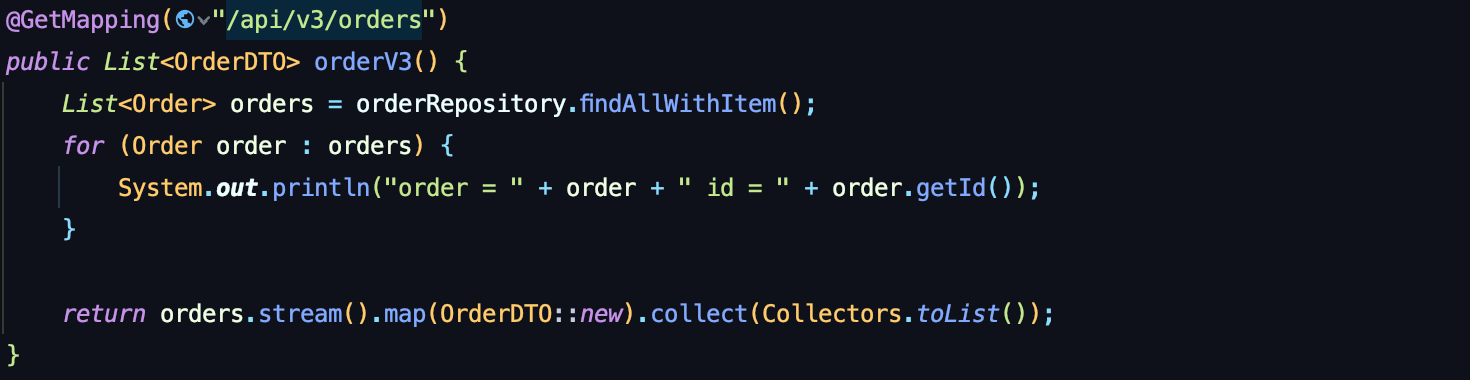
아주 간단한 V1
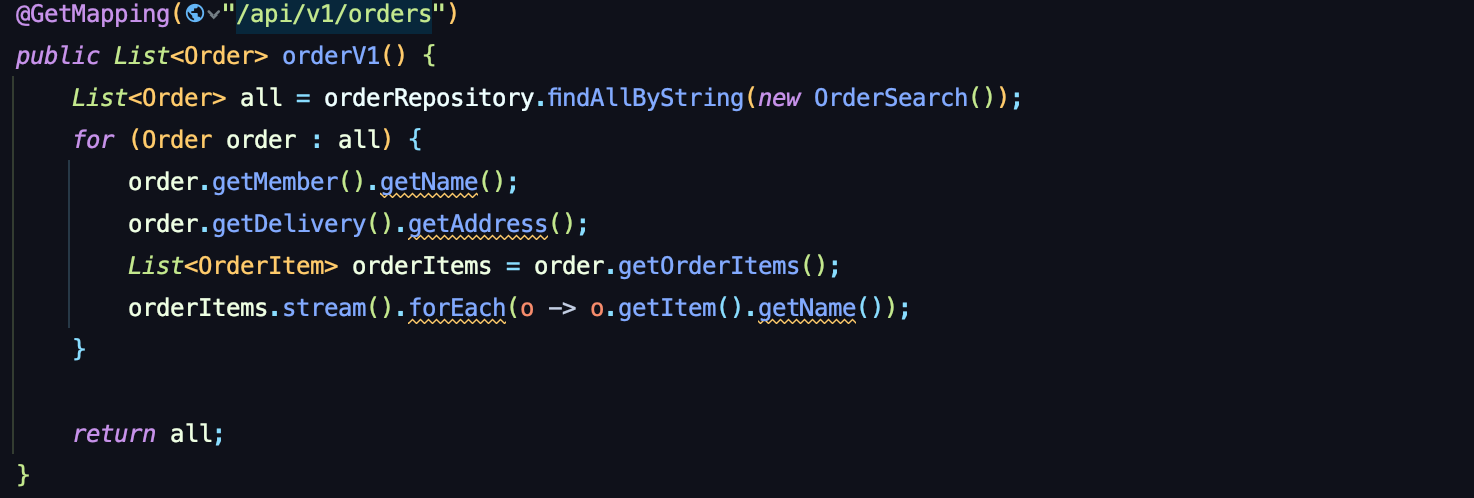
똑같은 Order를 뿌려줄 것인데, 이부분은 왜 ToMany 이냐면,
뿌려줄 스펙에 OrderItem이 들어있기 때문이다.
이 코드의 문제점은 이제 슬슬 말 안해도 알아야하지만,, 공부니까
Entity를 화면에 바로 뿌리지 말것...
Order내의 양방향 매핑으로 인한 무한 루프에 걸린다...

아주 기초적인 Entity를 반환한다거나, 쿼리의 N+1의 문제를 해결하기 위해
DTO와 fetch 조인을 사용한 코드이다. 쿼리도 1개만 나가는 것을 볼 수 있다.
위의 simple-order의 V3와 같은 코드이나, 가장 큰 차이는 컬렉션을 조회하는 fetch 조인은 페이징이 불가능하다.
이러한 상황에서 페이징을 하게되면, 페이징 sql은 무시되고, 애플리케이션 메모리내에서 페이징을 시도하여 어마무시한 자원을 소모한다.
컬렉션 fetch 조인은 1개만 사용할 수 있다. 컬렉션 둘 이상에 페치 조인을 사용하면 안된다. 데이터가 부정합하게 조회될 수 있다.
검색 메서드의 distinct를 사용한 이유는 1대다 조인이 있으므로 데이터베이스 row가 증가한다.
그 결과 같은 order 엔티티의 조회 수도 증가하게 된다.
JPA의 distinct는 SQL에 distinct를 추가하고, 더해서 같은 엔티티가 조회되면, 애플리케이션에서 중복을 걸러준다.
이 예에서 order가 컬렉션 페치 조인 때문에 중복 조회 되는 것을 막아준다.
페이징과 한계 돌파
컬렉션을 페치 조인하면 페이징이 불가능하다.
컬렉션을 페치 조인하면 일대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
일다대에서 일(1)을 기준으로 페이징을 하는 것이 목적이다. 그런데 데이터는 다(N)를 기준으로 row 가 생성된다.
Order를 기준으로 페이징 하고 싶은데, 다(N)인 OrderItem을 조인하면 OrderItem이 기준이 되어버린다.
페이징 + 컬렉션 엔티티를 함께 조회하려면 어떻게 해야할까?
- 먼저 ToOne(OneToOne, ManyToOne) 관계를 모두 페치조인 한다. ToOne 관계는 row수를 증가시키지 않으므로 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션은 지연 로딩으로 조회한다.
- 지연 로딩 성능 최적화를 위해
hibernate.default_batch_fetch_size,@BatchSize를 적용한다.
이 옵션을 사용하면 컬렉션이나, 프록시 객체를 한꺼번에 설정한 size 만큼 IN 쿼리로 조회한다.

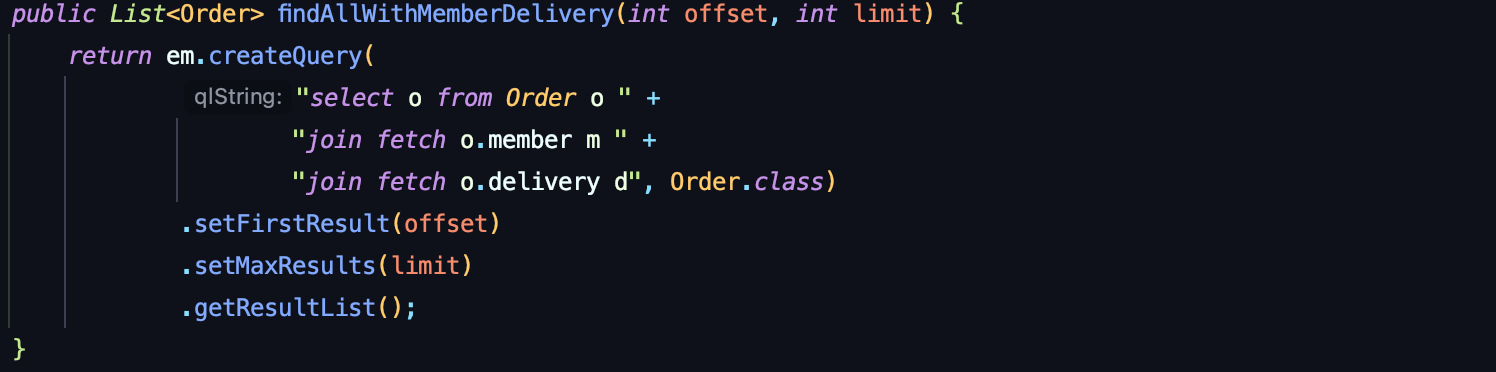
ToOne 관계인 엔티티만 페치 조인을 해주고, 페이징 쿼리를 적용시켰다.
In 쿼리 로그
select orderitems0_.order_id as order_id5_5_1_, orderitems0_.order_item_id as order_it1_5_1_, orderitems0_.order_item_id as order_it1_5_0_, orderitems0_.count as count2_5_0_, orderitems0_.item_id as item_id4_5_0_, orderitems0_.order_id as order_id5_5_0_, orderitems0_.order_price as order_pr3_5_0_ from order_item orderitems0_ where orderitems0_.order_id in (4, 11);이러한 방식을 사용하면,
- 쿼리호출수가1+N -> 1+1로최적화된다.
- 조인보다 DB 데이터 전송량이 최적화 된다. (Order와 OrderItem을 조인하면 Order가 OrderItem 만큼 중복해서 조회된다. 이 방법은 각각 조회하므로 전송해야할 중복 데이터가 없다.)
- 페치 조인 방식과 비교해서 쿼리 호출 수가 약간 증가하지만, DB 데이터 전송량이 감소한다. 컬렉션 페치 조인은 페이징이 불가능 하지만 이 방법은 페이징이 가능하다.
결과적으로,
ToOne 관계는 페치 조인해도 페이징에 영향을 주지 않는다. 따라서 ToOne 관계는 페치조인으로 쿼리 수를 줄이고 해결하고, 나머지는 hibernate.default_batch_fetch_size 로 최적화 하자.
DTO 직접 조회
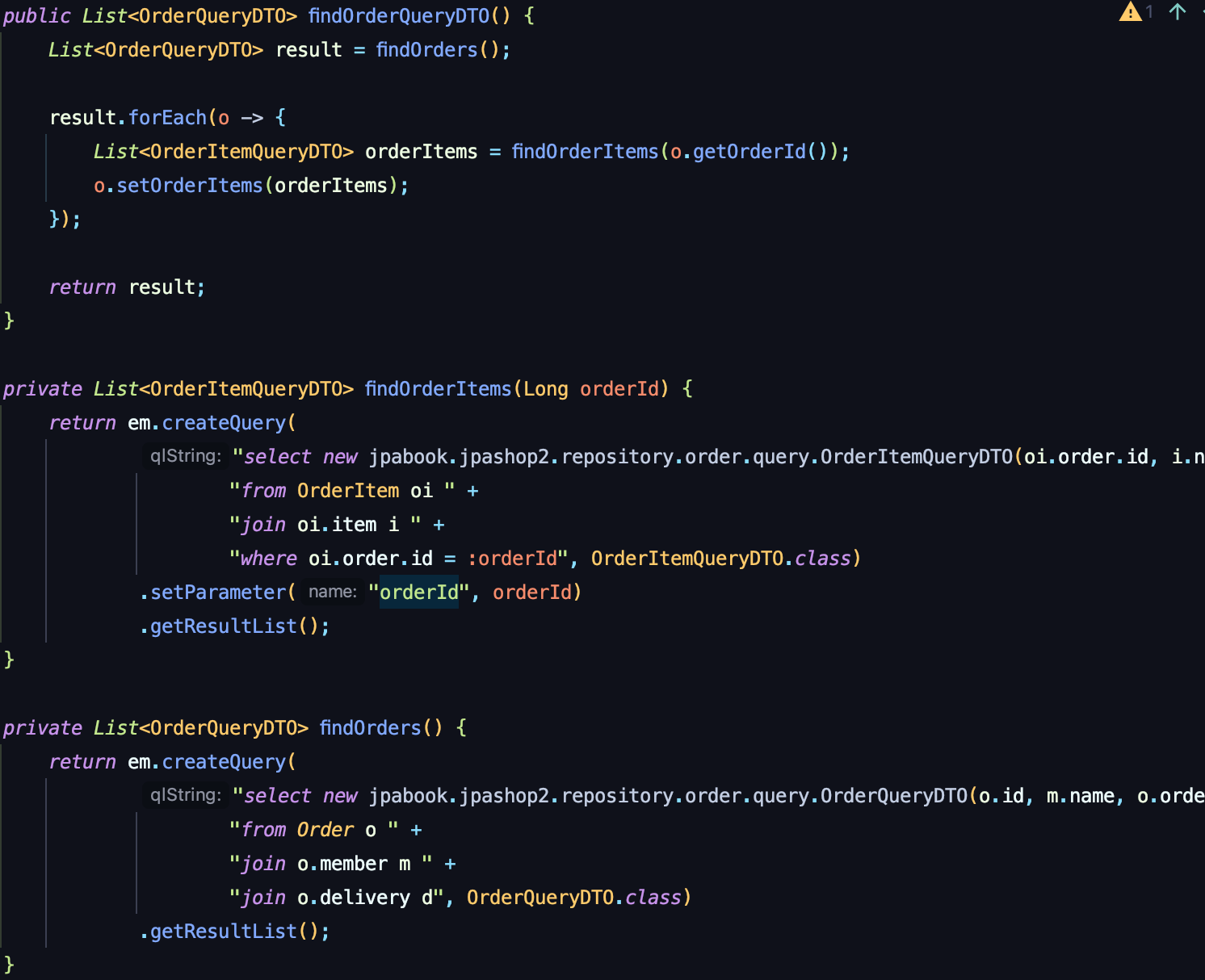
로직만 보자면, Order를 조회하기 위한 DTO와 조회 메서드를 작성하고
컬렉션을 조회하기 위한 컬렉션 DTO와 메서드를 정의하여 DTO를 직접 조회한다.
이런 방식을 사용하면, 루트 1번, 컬렉션 N번의 쿼리가 실행된다.
ToOne(N:1, 1:1) 관계들을 먼저 조회하고, ToMany(1:N) 관계는 각각 별도로 처리하는 것이다.
이런 방식을 선택한 이유는
- ToOne 관계는 조인해도 데이터 row 수가 증가하지 않는다.
- ToMany(1:N) 관계는 조인하면 row 수가 증가한다.
row 수가 증가하지 않는 ToOne 관계는 조인으로 최적화 하기 쉬우므로 한번에 조회하고, ToMany 관계는 최적화 하기 어려우므로 findOrderItems() 같은 별도의 메서드로 조회하는 것이다.
이 방식은 단건 조회에서 많이 사용하는 방식 이다.
데이터를 대량조회 시에는 Map을 사용하여 성능을 최적화할 수 있다.
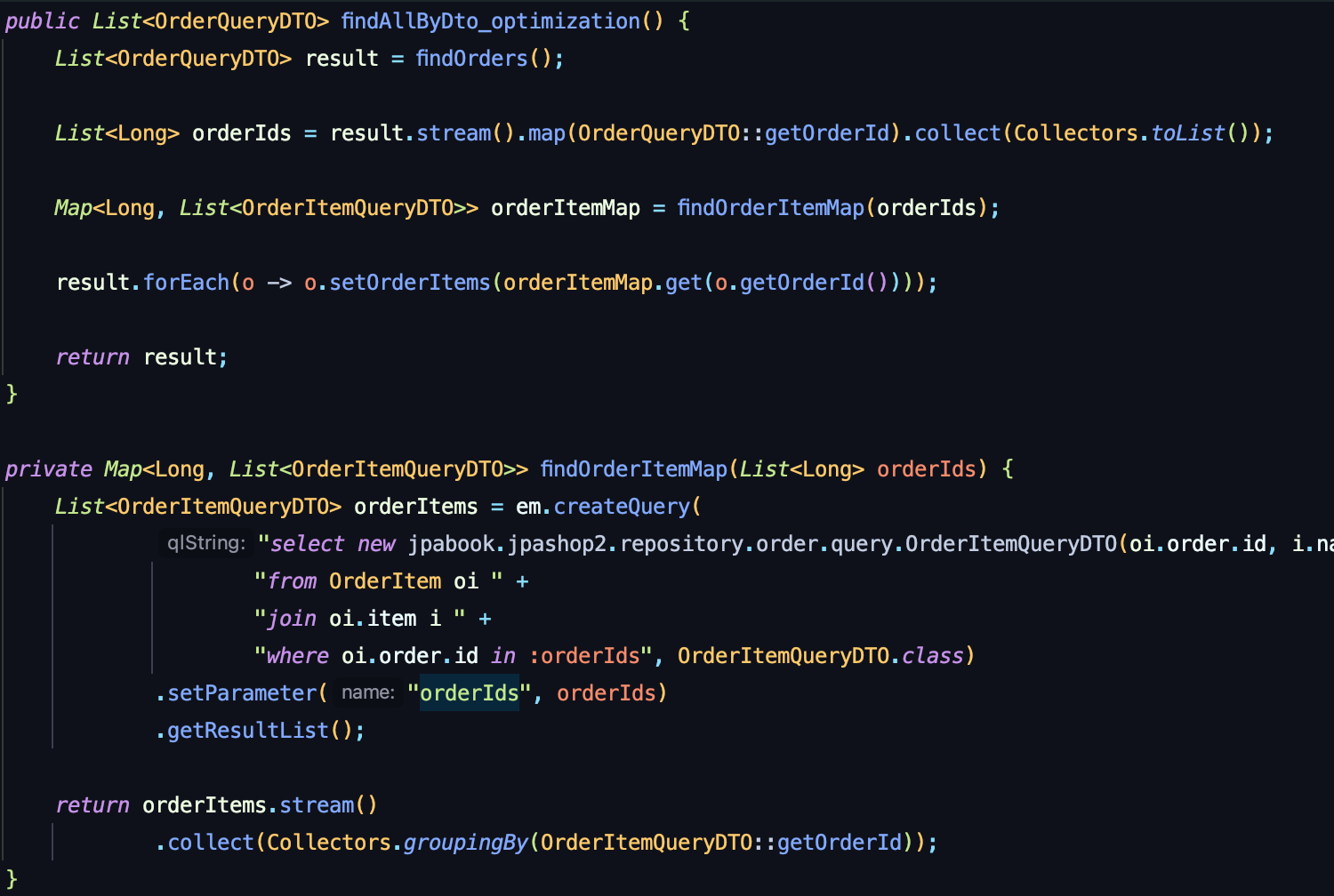
루트 1번, 컬렉션 1번의 쿼리가 나가며, orderItem 컬렉션을 MAP 한방에 조회하는 것이다.
result의 람다식에서 루프를 돌면서 컬렉션 추가(추가 쿼리 실행X) 한다.
ToOne 관계들을 먼저 조회하고, 여기서 얻은 식별자 orderId로 ToMany 관계인 OrderItem 을 한꺼번에 조회하고, MAP을 사용해서 매칭 성능 향상(O(1)) 하는 것이다.
simple-order와 같이 전용 DTO를 새로 짜서도 조회할 수 있다.
쿼리는 한번이지만 조인으로 인해 DB에서 애플리케이션에 전달하는 데이터에 중복 데이터가 추가되므로 상황에 따라 V5 보다 더 느릴 수 도 있다.
그리고 애플리케이션에서 추가 작업이 크다.
또한 페이징도 불가능 하다.
정리
- 페치 조인으로 쿼리 수 최적화: V3
- 컬렉션 페이징과 한계 돌파: V3.1
- JPA에서 DTO를 직접 조회: V4
- 컬렉션 조회 최적화 - 일대다 관계인 컬렉션은 IN 절을 활용해서 메모리에 미리 조회해서 최적화: V5
- 플랫 데이터 최적화 - JOIN 결과를 그대로 조회 후 애플리케이션에서 원하는 모양으로 직접 변환: V6
권장 접근 순서
- 엔티티조회방식으로우선접근
- 페치조인으로 쿼리 수를 최적화
- 컬렉션 최적화
- 페이징 필요
hibernate.default_batch_fetch_size,@BatchSize로 최적화 - 페이징 필요X 페치 조인 사용
- 페이징 필요
- 엔티티조회방식으로해결이안되면DTO조회방식사용
- DTO 조회 방식으로 해결이 안되면 NativeSQL or 스프링 JdbcTemplate
엔티티 조회 방식은 페치 조인이나, hibernate.default_batch_fetch_size , @BatchSize 같이 코드를 거의 수정하지 않고, 옵션만 약간 변경해서, 다양한 성능 최적화를 시도할 수 있다. 반면에 DTO를 직접 조회하는 방식은 성능을 최적화 하거나 성능 최적화 방식을 변경할 때 많은 코드를 변경해야 한다.
DTO 조회 방식은 SQL을 직접 다루는 것과 유사하기 때문에 잘 생각해서 써야하고, DTO로 조회하는 방법도 각각 장단이 있다. V4, V5, V6에서 단순하게 쿼리가 1번 실행된다고 V6이 항상 좋은 방법인 것은 아니다.
V4는 코드가 단순하다. 특정 주문 한건만 조회하면 이 방식을 사용해도 성능이 잘 나온다. 예를 들어서 조회한 Order 데이터가 1건이면 OrderItem을 찾기 위한 쿼리도 1번만 실행하면 된다.
V5는 코드가 복잡하다. 여러 주문을 한꺼번에 조회하는 경우에는 V4 대신에 이것을 최적화한 V5 방식을 사용해야 한다. 예를 들어서 조회한 Order 데이터가 1000건인데, V4 방식을 그대로 사용하면, 쿼리가 총 1 + 1000번 실행된다. 여기서 1은 Order 를 조회한 쿼리고, 1000은 조회된 Order의 row 수다. V5 방식으로 최적화 하면 쿼리가 총 1 + 1번만 실행된다. 상황에 따라 다르겠지만 운영 환경에서 100배 이상의 성능 차이가 날 수 있다.
V6는 완전히 다른 접근방식이다. 쿼리 한번으로 최적화 되어서 상당히 좋아보이지만, Order를 기준으로 페이징이 불가능하다. 실무에서는 이정도 데이터면 수백이나, 수천건 단위로 페이징 처리가 꼭 필요하므로, 이 경우 선택하기 어려운 방법이다. 그리고 데이터가 많으면 중복 전송이 증가해서 V5와 비교해서 성능 차이도 미비하다.
OSIV
Open Session In View : 하이버네이트
Open EntityManager In View: JPA
이제까지 공부하며 아래와 같은 경고 문구가 항상 나왔다.
spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
OSIV가 기본값으로 켜져있다. 라는 문구인데,
OSIV가 어떤 것일까
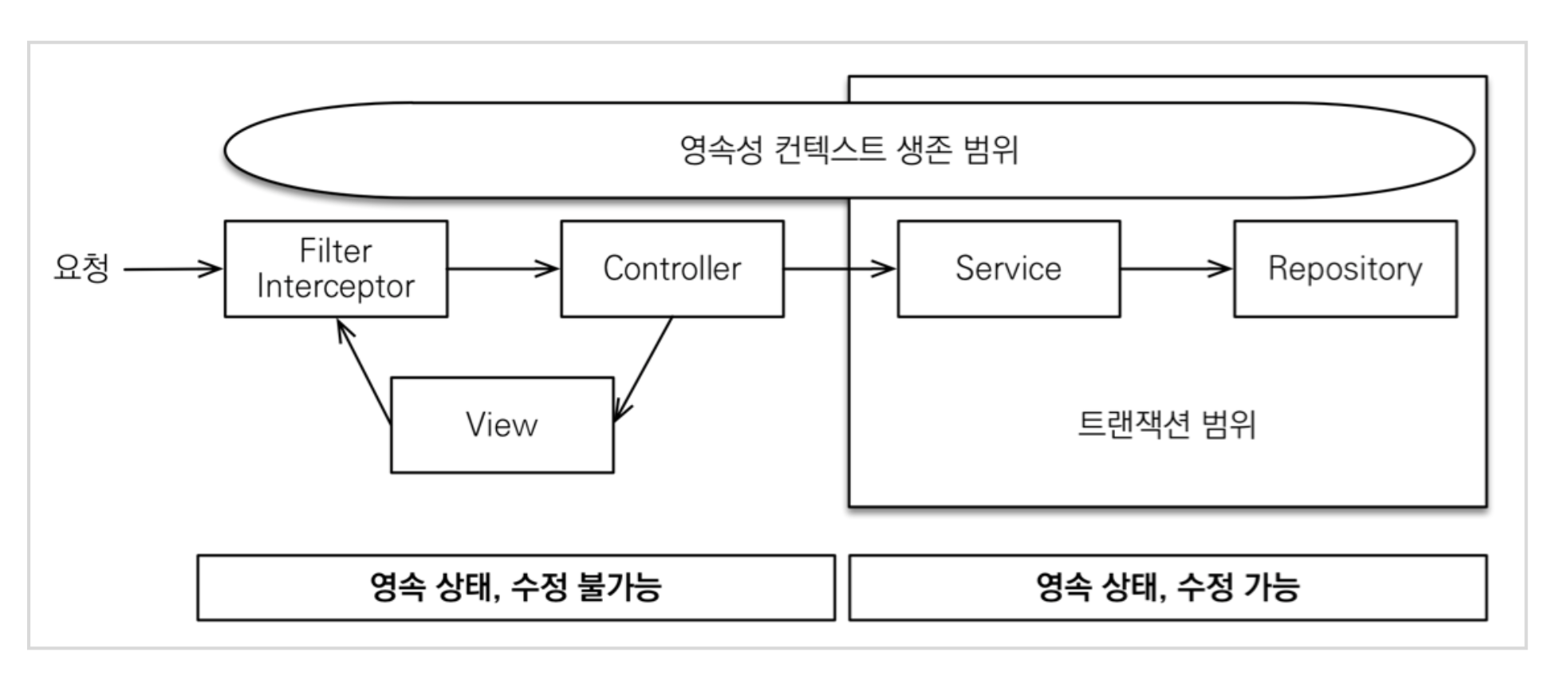
OSIV가 켜져있으면,
트랜잭션 시작처럼 최초 데이터베이스 커넥션 시작 시점부터 API 응답이 끝날 때 까지 영속성 컨텍스트와 데이터베이스 커넥션을 유지한다.
그래서 지금까지 View Template이나 API 컨트롤러에서 지연 로딩이 가능했던 것이다.
지연 로딩은 영속성 컨텍스트가 살아있어야 가능하고, 영속성 컨텍스트는 기본적으로 데이터베이스 커넥션을 유지한다. 이것 자체가 큰 장점이다.
그런데 이 전략은 너무 오랜시간동안 데이터베이스 커넥션 리소스를 사용하기 때문에, 실시간 트래픽이 중요한 애플리케이션에서는 커넥션이 모자랄 수 있다.
컨트롤러에서 외부 API를 호출하면 외부 API 대기 시간 만큼 커넥션 리소스를 반환하지 못하고, 유지해야 한다.
강사님의 경우 무려 배민의 팀장님이시다보니 OSIV를 사용할 경우 서비스가 아예 불가능 하시다고... 갓배민
OSIV의 경우 application.yml 에 jpa.open-in-view: false 속성을 통해 On/Off 할 수 있다.
경고 로그에서 볼 수 있듯, 속성을 true로 설정해준다면 저 경고 메세지는 나타나지 않는다.
하지만 OSIV를 끄게되면,
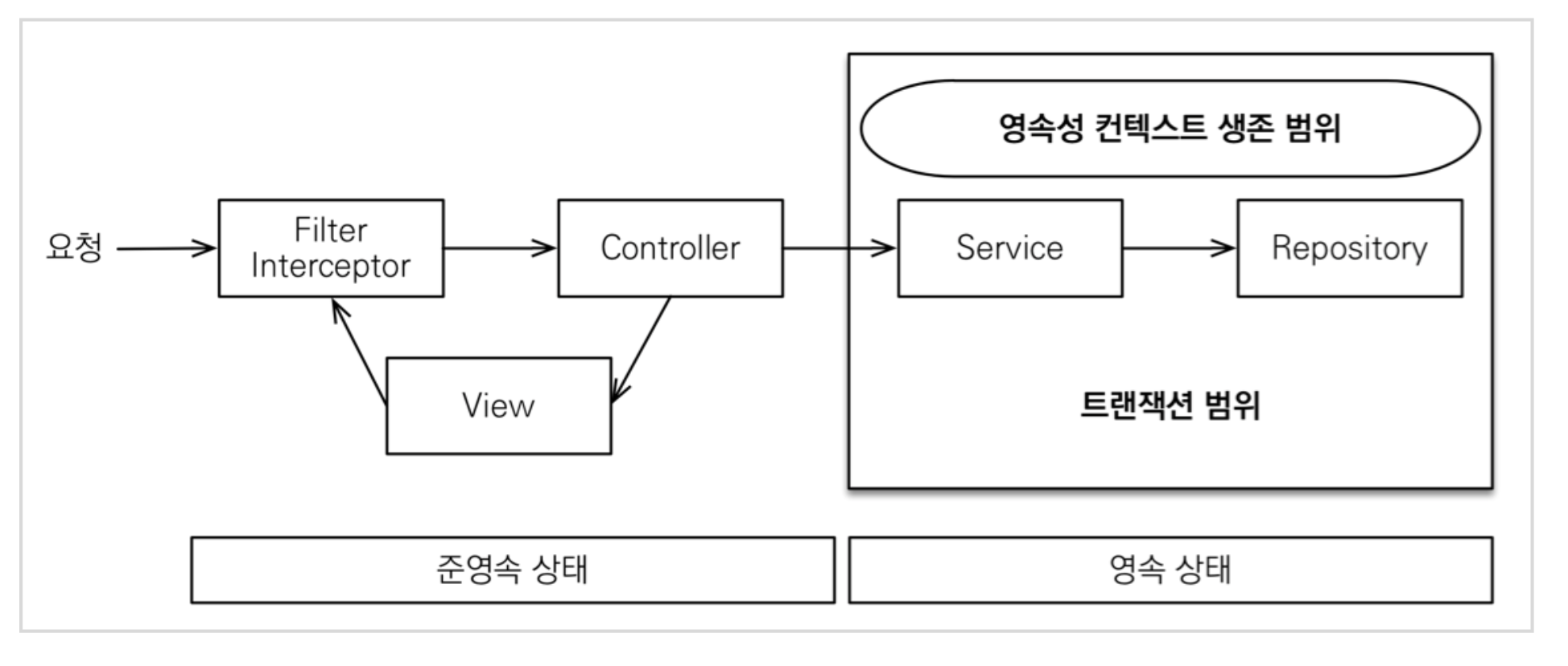
트랜잭션을 종료할 때 영속성 컨텍스트를 닫고, 데이터베이스 커넥션도 반환한다. 따라서 커넥션 리소스를 낭비하지 않는다.
OSIV를 끄면 모든 지연로딩을 트랜잭션 안에서 처리해야 한다. 따라서 지금까지 작성한 많은 지연 로딩 코드를 트랜잭션 안으로 넣어야 하는 단점이 있다.
결론적으로 트랜잭션이 끝나기 전에 지연 로딩을 강제로 호출해 두어야 한다.
이를 해결하기 위해서 커맨드와 쿼리를 분리한다.(Command_Query_Sepseparation)
보통 비즈니스 로직은 특정 엔티티 몇게를 등록하거나 수정하는 것이므로 성능이 크게 문제가 되지 않는다. 그런데 복잡한 화면을 출력하기 위한 쿼리는 화면에 맞추어 성능을 최적화 하는 것이 중요하다. 하지만 그 복잡성에 비해 핵심 비즈니스에 큰 영향을 주는 것은 아니다.
그래서 크고 복잡한 애플리케이션을 개발한다면, 이 둘의 관심사를 명확하게 분리하는 선택은 유지보수 관점에서 충분히 의미 있다.
