이제까지 예제 프로젝트를 진행하며
JPA를 순수 JPA 기반 Repository로 진행해왔다.
여기서 스프링 데이터 JPARepository에 대해 알아보자.
JpaRepository 살펴보기
JpaRepository를 살펴보기 전,
이제까지 사용했던 순수 Repository를 먼저 다시 보자.
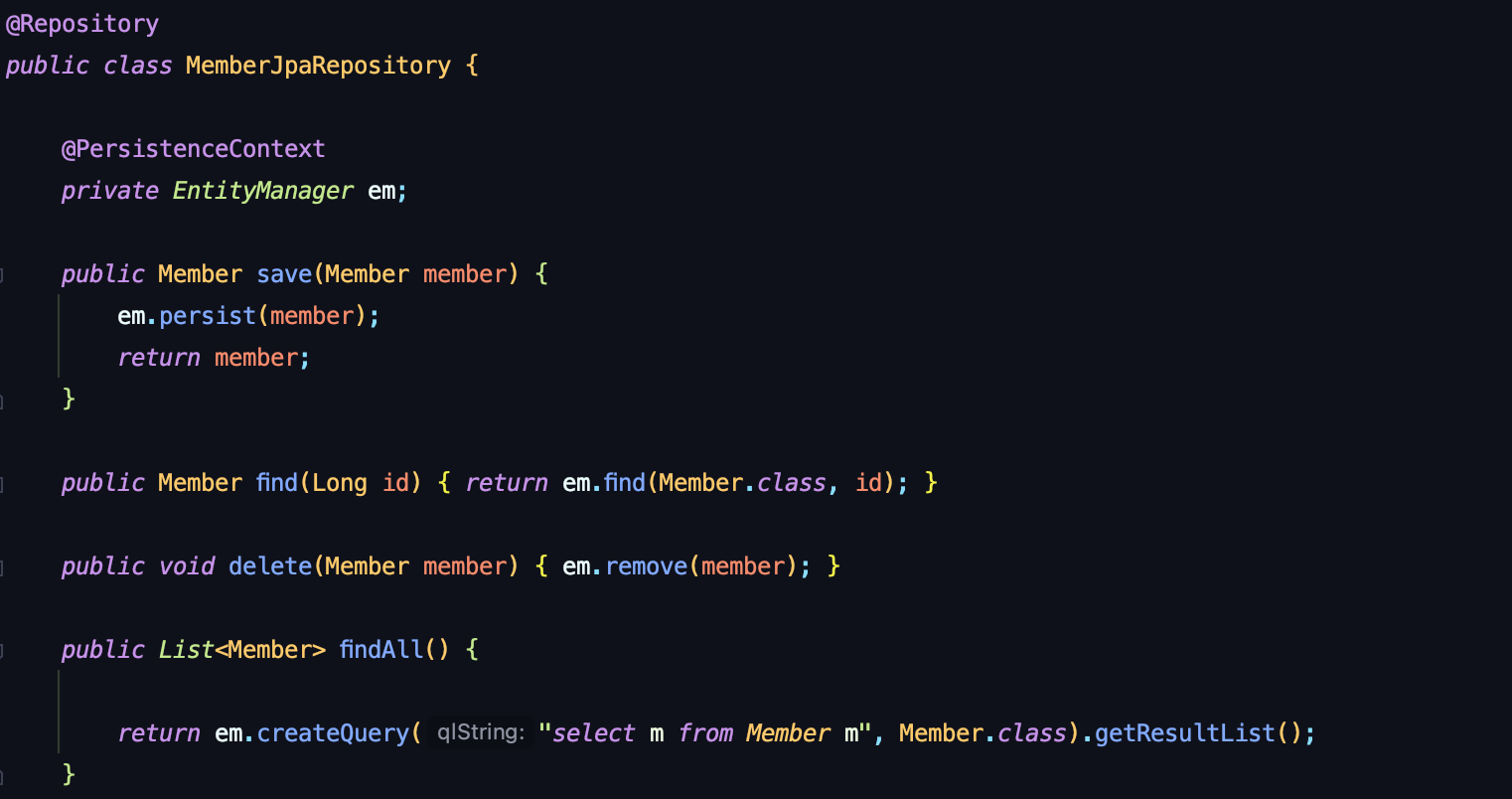
위와 같이 CRUD 메서드를 일일히 구현하여 추가할 기능을 추가하고 하는 쪽으로 사용했다.
JpaRepository는
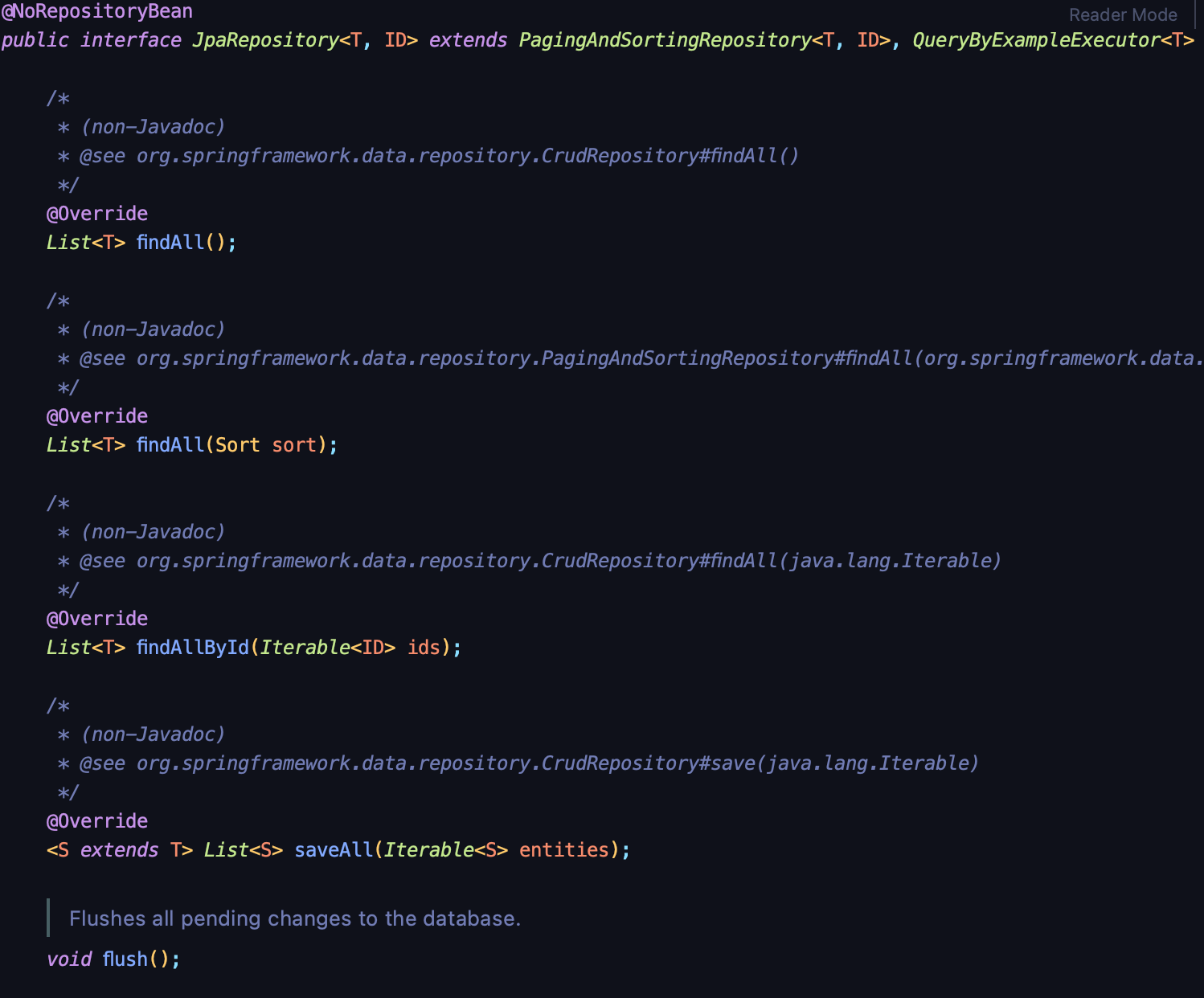
대략적인 메서드를 모두 구현해 놓아서, 레포지토리를 상속 받는 것만으로도 많은 메서드를 사용할 수 있다.
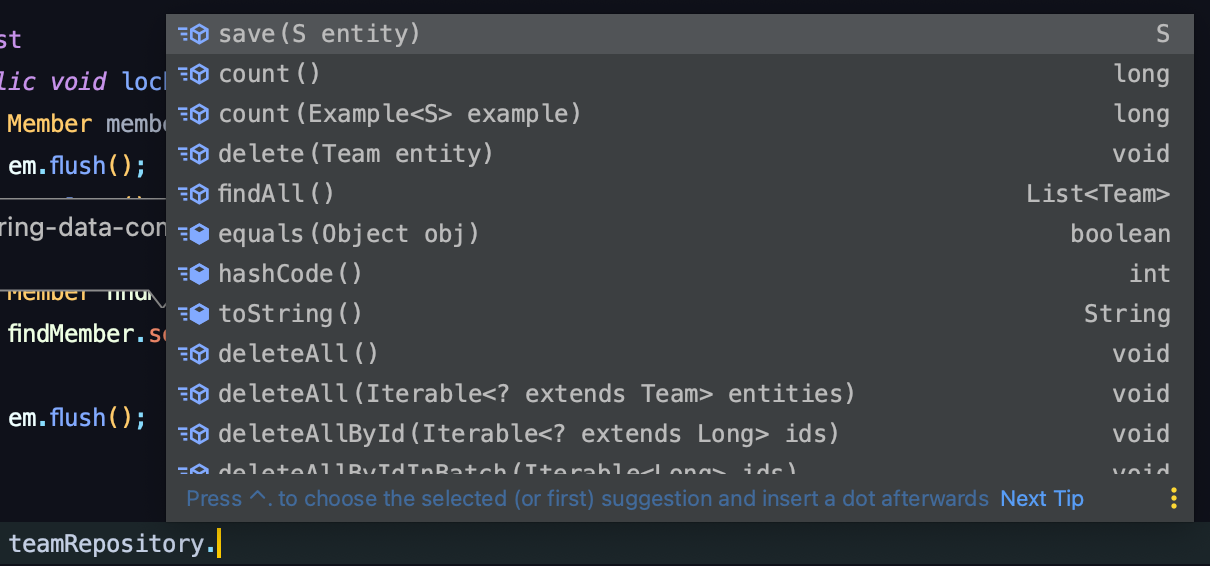
아무것도 구현하지 않고, 상속만 받은 상태의 teamRepository 위 말고도 무수히 많다.
이 Jpa를 활용하는 방법들을 알아보자.
JpaRepository 메서드
메서드 이름으로 쿼리 생성
JpaRepository에는 대부분의 경우에 공통적으로 사용될 듯한 메서드들이 구현되있는데, 만약 어떤 속성을 기준으로 검색하고자 한다면 그 속성은 프로젝트별로 제각각이기 일 것이기 때문에 구현되어 있지 않다.
만약 이름과 나이를 기준으로 회원을 조회하려고 한다면
public List<Member> findByUsernameAndAgeGreaterThan(String username, int age) {
return em.createQuery("select m from Member m where m.username = :username and m.age > :age")
.setParameter("username", username)
.setParameter("age", age)
.getResultList();
}와 같은 코드가 작성될 것이다.
그런데 마법같은 JpaRepository는
List<Member> findByUsernameAndAgeGreaterThan(String username, int age);이 한 줄의 메서드 선언으로 위와 동일한 메서드를 제공한다.
스프링 데이터 JPA는 메서드 이름을 분석해서 JPQL을 생성하고 실행한다.
메서드의 이름을 파싱해 마치 예약어 처럼 몇몇 필터를 넣어줄 수 있고, 필드네임을 기준으로 속성을 자동으로 지정해준다.
대충 눈대중으로 봐도 And, Greater, Than 같은 단어가 눈에 들어 올것이다.
이 외의 필터들은 쿼리 메서드 필터 와 동일 페이지의 4.4.2, 4.4.5 챕터 를 참고하자.
이 기능은 엔티티의 필드명이 변경되면 인터페이스에 정의한 메서드 이름도 꼭 함께 변경해야 한다. 그렇지 않으면 애플리케이션을 시작하는 시점에 오류가 발생한다.
NamedQuery
우리는 이전에 아래와 같이 NamedQuery를 공부했다.

이를 아래와 같이 사용했다.
public List<Member> findByUserName(String username) {
return em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("name", username)
.getResultList();
}이를 JpaRepository도 지원하는데
@Query(name = "Member.findByUsername")
List<Member> findByUsername(@Param ("name") String name);이렇게 간단해진다.
그리고 무려 어노테이션을 제거해도 문제 없이 사용할 수 있다.
왜냐하면 우선적으로 해당 Entity의 namedQuery를 먼저 찾아본 후 실행할 Named 쿼리가 없으면 메서드 이름으로 쿼리 생성 전략을 사용하기 때문이다.
리포지토리 메서드에 쿼리 정의
하지만 Named 쿼리는 실무에서 그렇게 자주 사용하진 않는다고 한다.
대신 @Query 어노테이션을 통해 리포지토리 메서드에 쿼리를 직접 정의하는 경우가 많다.
@Query("select m from Member m where m.username= :username and m.age = :age")
List<Member> findUser(@Param("username") String username, @Param("age") int age);실행할 메서드에 정적 쿼리를 직접 작성하므로 이름 없는 Named 쿼리라 할 수 있다.
이러한 방식의 장점은 실제 쿼리문은 String 타입이기 때문에 컴파일러가 문법 오류를 잡아주지 못하지만,
JPA Named 쿼리처럼 애플리케이션 실행 시점에 문법 오류를 발견할 수 있다.
위에서 본 메소드 이름으로 쿼리 생성 기능은 파라미터가 증가하면 메서드 이름이 매우 지저분해진다. 따라서 @Query 기능을 자주 사용하게 된다.
DTO, 값 타입 조회하기
이전에 본 DTO로 직접 조회하거나, 값 타입(@Embedded) 도 JpaRepository에서 조회 가능 하다.
@Query("select new study.datajpa.dto.MemberDto(m.id, m.username, t.name) from Member m join m.team t")
List<MemberDto> findMemberDto();DTO로 직접 조회 하려면 JPA의 new 명령어를 사용해야 한다. 그리고 다음과 같이 생성자가 맞는 DTO가 필요하다. (JPA와 사용방식이 동일하다.)
파라미터 바인딩
@Query("select m from Member m where m.username = :name")
Member findMembers(@Param("name") String username);여기까지 왔으면 아주 직관적으로 알 수 있을 것!
이 뿐아니라 컬렉션 파라미터 바인딩도 가능하다.
@Query("select m from Member m where m.username in :names")
List<Member> findByNames(@Param("names") List<String> names);names의 내용중 걸리는게 있다면 조회되는 방식이다.
반환 타입
스프링 데이터 JPA는 유연한 반환 타입 지원한다.
List<Member> findByUsername(String name); //컬렉션
Member findByUsername(String name); //단건
Optional<Member> findByUsername(String name); //단건 Optional단건으로 지정한 메서드를 호출하면 스프링 데이터 JPA는 내부에서 JPQL의 Query.getSingleResult() 메서드를 호출한다. 이 메서드를 호출했을 때 조회 결과가 없으면 javax.persistence.NoResultException 예외가 발생하는데 개발자 입장에서 다루기가 상당히 불편하다.
스프링 데이터 JPA는 단건을 조회할 때 이 예외가 발생하면 예외를 무시하고 대신에 null 을 반환한다.
순수 JPA 페이징과 정렬
만약 아래와 같이 페이징 하고자 한다면
- 검색 조건: 나이가 10살
- 정렬 조건: 이름으로 내림차순
- 페이징 조건: 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
순수 JPA 코드는 아래와 같다.
public List<Member> findByPage(int age, int offset, int limit) {
return em.createQuery("select m from Member m where m.age = :age order by m.name desc", Member.class)
.setParameter("age", age)
.setFirstResult(offset)
.setMaxResults(limit)
.getResultList();
}
public long totalCount(int age) {
return em.createQuery("select count(m) from Member m where m.age = :age", Long.class)
.setParameter("age", age)
.getSingleResult();
}totalCount(int age) 가 필요한 이유는 페이징 시 대부분 전체 조회수가 필요하기 때문에 만든 것이다.
아직은 그렇게 페이징에 대해 와닿진 않지만,
일전의 강의에서 컬렉션 페이징 등을 보니 페이징이 굉장히 중요하고, 까다롭다는 걸 느낌적인 느낌으로 느낄수 있다...ㅋㅋㅋㅋ
Jpa에서는 아주 어메이징한 페이징 기능을 제공한다.
페이징과 정렬 파라미터
org.springframework.data.domain.Sort : 정렬 기능 org.springframework.data.domain.Pageable : 페이징 기능 (내부에 Sort 포함)
특별한 반환 타입
org.springframework.data.domain.Page : 추가 count 쿼리 결과를 포함하는 페이징
org.springframework.data.domain.Slice : 추가 count 쿼리 없이 다음 페이지만 확인 가능 (내부적으로 limit + 1조회)
List (자바 컬렉션): 추가 count 쿼리 없이 결과만 반환
이를 사용하는 법을 알아보자
Jpa 메서드는 아래와 같이 간단하다.
Page<Member> findByAge(int age, Pageable pageable);이 메서드를 제대로 사용하는 법을 보기위해 테스트 코드를 보자.
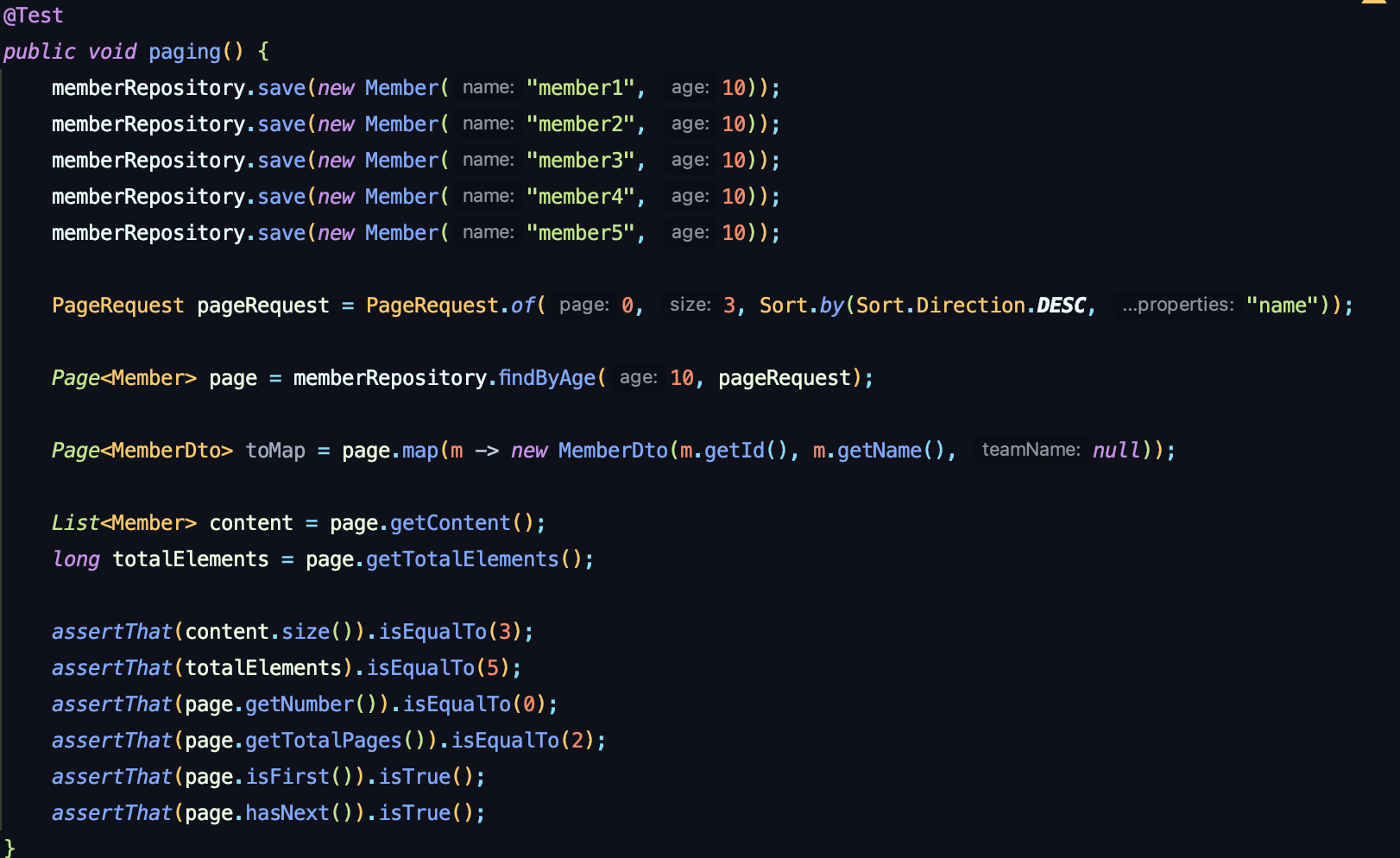
먼저 PageRequest 인스턴스를 생성한다.
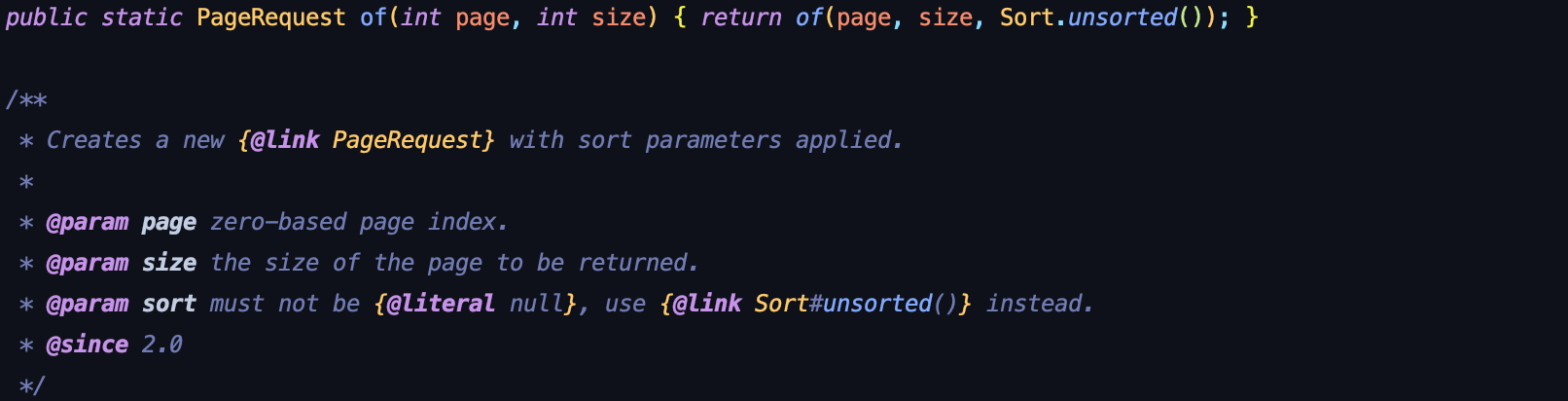
매개변수를 살펴보자면, page = offset, size = limit, sort = 정렬 전략 이라고 생각하면 된다.
Page의 장점은 테스트 아래를 볼 수 있듯 내용을 꺼낸다거나, 전체 수를 조회한다거나, 수많은 메서드를 제공한다.
Page는 Slice를 상속 받으며, Page에 페이지 수, 건 수등의 메서드가 추가되어 있다.
Count 쿼리 분리하기
전체 건수를 조회 한다는것은 엄청난 일이다.
전체 데이터베이스의 모든 데이터를 가져와야 하기 때문이다.
그래서 Count 쿼리가 성능에 큰 영향을 미친다.
@Query(value = “select m from Member m”, countQuery = “select count(m.username) from Member m”)
Page<Member> findMemberAllCountBy(Pageable pageable);이와 같이 Count 쿼리를 분리할 수 있다.
이 분리에 대한 차이는 복잡한 join 쿼리가 들어가게되면 Count 쿼리가 join 관계를 타며 엄청난 조회를 만들어 내기 때문에 join 쿼리를 분리하기 위함이다.
벌크성 수정 쿼리
public int bulkAgePlus(int age) {
int resultCount = em.createQuery(
"update Member m set m.age = m.age + 1" +
"where m.age >= :age")
.setParameter("age", age)
.executeUpdate();
return resultCount;
}순수 JPA에서는 .executeUpdate() 메서드를 통해 벌크성 수정 쿼리를 적용한다.
@Modifying
@Query("update Member m set m.age = m.age + 1 where m.age >= :age")
int bulkAgePlus(@Param("age") int age);JpaRepository의 벌크성 수정, 삭제 쿼리는 @Modifying 어노테이션을 사용한다.
이전의 벌크성 수정 쿼리를 보았을 때, 벌크 연산은 영속성 컨텍스트를 무시하고 실행하기 때문에, 영속성 컨텍스트에 있는 엔티티의 상태와 DB에 엔티티 상태가 달라질 수 있다는 점을 보았다.
이를 위해 @Modifying(clearAutomatically = true) 속성을 통해 벌크성 쿼리를 실행하고 나서 영속성 컨텍스트 초기화 시켜줄 수 있다.
fetch 조인
지연 로딩 관계에서 야기되는 N+1 문제등 여러 문제를 이미 확인한 바 있다.
//JPQL을 사용한 fetch 조인
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin();
//공통 메서드 오버라이드
@Override
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();
//JPQL + 엔티티 그래프
@EntityGraph(attributePaths = {"team"})
@Query("select m from Member m")
List<Member> findMemberEntityGraph();
//메서드 이름으로 쿼리에서 특히 편리하다.
@EntityGraph(attributePaths = {"team"})
List<Member> findByUsername(String username)
@EntityGraph 어노테이션을 통해 fetch 조인을 사용할 수 있다.
사실상 페치 조인(FETCH JOIN)의 간편 버전이며, LEFT OUTER JOIN 사용한다.
JPA Hint
JPA 쿼리 힌트(SQL 힌트가 아니라 JPA 구현체에게 제공하는 힌트)
@Test
public void queryHint() throws Exception {
memberRepository.save(new Member("member1", 10));
em.flush();
em.clear();
Member member = memberRepository.findReadOnlyByUsername("member1");
member.setUsername("member2");
em.flush();
}CRUD의 Update의 경우 따로 메서드를 구현하지 않고 더티 체킹을 통해 Update를 사용한다.
그런데 이 기능은 원본 데이터와 영속성 컨텍스트에 1차 캐싱된 객체 2개의 객체를 관리한다.
이 말은 메모리를 추가로 사용한다는 뜻.
그런데 만약에 이 데이터를 변경할 가능성이 없이 조회만 할 것이라면, 이러한 비용은 낭비다.
이럴때 성능 향상을 위해서 사용하는 것이 JPA Hint이다.
@QueryHints(value = @QueryHint(name = "org.hibernate.readOnly", value = "true"))
Member findReadOnlyByUsername(String username);이렇게 Query 힌트를 주게되면 readOnly로 설정되어, 1차 캐싱 객체를 만들지 않아서 내부 메서드에서 값을 변경하더라도 Update가 적용되지 않는다.
그런데 이 옵션을 통한 성능 향상의 부분은 크지 않고, 로직의 문제가 더 큰 경우가 많다고 한다.
정말 트래픽이 많은 경우에 사용하자.
