왜 쿠버네티스 인가?
쿠버네티스는 컨테이너를 쉽고 빠르게 배포/확장하고 관리를 자동화해주는 오픈소스 플랫폼입니다.
단순한 컨테이너 플랫폼이 아닌 마이크로서비스, 클라우드 플랫폼을 지향하고 컨테이너로 이루어진 것들을 손쉽게 담고 관리할 수 있는 그릇 역할을 합니다. 서버리스, CI/CD, 머신러닝 등 다양한 기능이 쿠버네티스 플랫폼 위에서 동작합니다.
쿠버네티스의 특징
-
Planet Scale
행성 규모로 확장할 수 있는 스케일
구글 보다 적게 사용하면 괜찮다는 의미 -
Never Outgrow
다양한 요구사항을 만족시킬 수 있는 유연함
로컬 테스트용으로 사용하던지 글로벌 기업에서 사용하던지 상관 없이 유연하게 규모를 늘릴 수 있음 -
Run Anywhere
온프레미스, 퍼블릭 클라우드 그리고 하이브리드 환경 어디서나 동작
대부분의 리눅스 시스템에서 동작하기 때문에 이동에 제약이 없음
쿠버네티스의 장점
-
오픈소스
CNCF 재단을 필두로 수많은 기업들이 사용중이며, 거대한 커뮤니티의 활성화 -
업계 표준급 (de facto)
엄청난 사용량에 힘입어 컨테이너 환경에서 사실상 오케스트레이션 툴의 표준으로 자리잡음
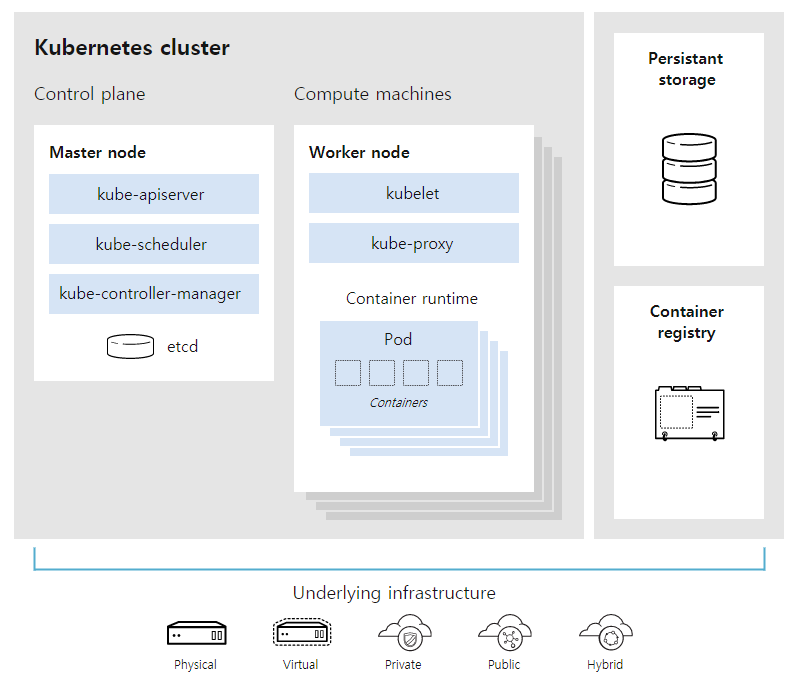
마스터 노드
마스터 노드 안에 있는 핵심 쿠버네티스 구성 요소는 컨테이너가 필요한 리소스와 함께 충분한 횟수로 실행되도록하는 중요한 작업을 처리한다.
kube-apiserver
쿠버네티스 클러스터와 상호 작용할 때, API를 통한다.
쿠버네티스 API는 쿠버네티스 컨트롤 플레인의 프론트엔드로, 내부 및 외부 요청을 처리한다.
API 서버는 요청이 유효한지 판별하고 유효한 요청을 처리하고, REST 호출이나 kubectl 커맨드라인 인터페이스 또는 kubeadm과 같은 기타 CLI(command-line interface)를 통해 API에 액세스할 수 있다.
kube-scheduler
스케줄러는 CPU 또는 메모리와 같은 포드의 리소스 요구 사항과 함께 클러스터의 상태를 고려하고, 그런 다음 포드를 적절한 작업자 노드에 예약한다.
kube-controller-manager
컨트롤러는 실제로 클러스터를 실행하고 쿠버네티스 controller-manager에는 여러 컨트롤러 기능이 하나로 통합되어 있다.
하나의 컨트롤러는 스케줄러를 참고하여 정확한 수의 파드가 실행되게 한다.
파드에 문제가 생기면 또 다른 컨트롤러가 이를 감지하고 대응한다.
컨트롤러는 서비스를 파드에 연결하므로 요청이 적절한 엔드포인트로 이동한다.
또한 계정 및 API 액세스 토큰 생성을 위한 컨트롤러가 있다.
etcd
설정 데이터와 클러스터의 상태에 관한 정보는 키-값 저장소 데이터베이스인 etcd에 저장된다.
내결함성을 갖춘 분산형 etcd는 클러스터에 관한 궁극적 SOT(Source Of Truth)가 되도록 설계되었다.
워커 노드
쿠버네티스 클러스터에는 최소 1개 이상의 작업자 노드가 필요하지만 일반적으로 여러 개의 워커 노드가 있다.
파드는 작업자 노드에서 실행되도록 예약 및 오케스트레이션된다.
클러스터의 용량을 확장해야 한다면, 더 많은 워커 노드를 추가한다.
파드
파드는 쿠버네티스 오브젝트 모델에서 가장 작고 단순한 유닛으로, 애플리케이션의 단일 인스턴스를 나타낸다.
각 파드는 컨테이너 실행 방식을 제어하는 옵션과 함께 컨테이너 하나 또는 긴밀히 결합된 일련의 컨테이너로 구성되어 있다.
파드를 퍼시스턴트 스토리지에 연결하여 스테이트풀(stateful) 애플리케이션을 실행할 수 있다.
컨테이너 런타임 엔진
컨테이너 실행을 위해 각 작업자에는 컨테이너 런타임 엔진이 있다.(대표적으로 Docker)
하지만 쿠버네티스는 rkt, CRI-O와 같은 다른 Open Container Initiative 호환 런타임도 지원한다.
kubelet
각 작업자 노드에는 마스터 노드와 통신하는 매우 작은 애플리케이션인 kubelet이 있다.
kublet은 컨테이너가 파드에서 실행되게 한다.
마스터 노드에서 워커 노드에 작업을 요청하는 경우 kubelet이 이 작업을 실행한다.
kube-proxy
각 작업자 노드에는 쿠버네티스 네트워킹 서비스를 용이하게 하기 위한 네트워크 프록시인 kube-proxy도 있다.
kube-proxy는 운영 체제의 패킷 필터링 계층에 의존하거나 트래픽 자체를 전달하여 클러스터 내부 또는 외부의 네트워크 통신을 처리한다.
외의 클러스터에 필요한 요소
퍼시스턴트 스토리지
쿠버네티스는 애플리케이션을 실행하는 컨테이너를 관리할 뿐만 아니라 클러스터에 연결된 애플리케이션 데이터도 관리할 수 있다.
쿠버네티스를 사용하면 사용자가 기본 스토리지 인프라에 관한 상세 정보를 알지 못해도 스토리지 리소스를 요청할 수 있다.
퍼시스턴트 볼륨은 파드가 아닌 클러스터에 따라 다르므로 파드보다 수명이 오래 지속될 수 있다.
컨테이너 레지스트리
쿠버네티스가 의존하는 컨테이너 이미지는 컨테이너 레지스트리에 저장된다.
이러한 레지스트리를 직접 구성하거나 제품을 사용할 수 있다.
파드가 생성되는 과정
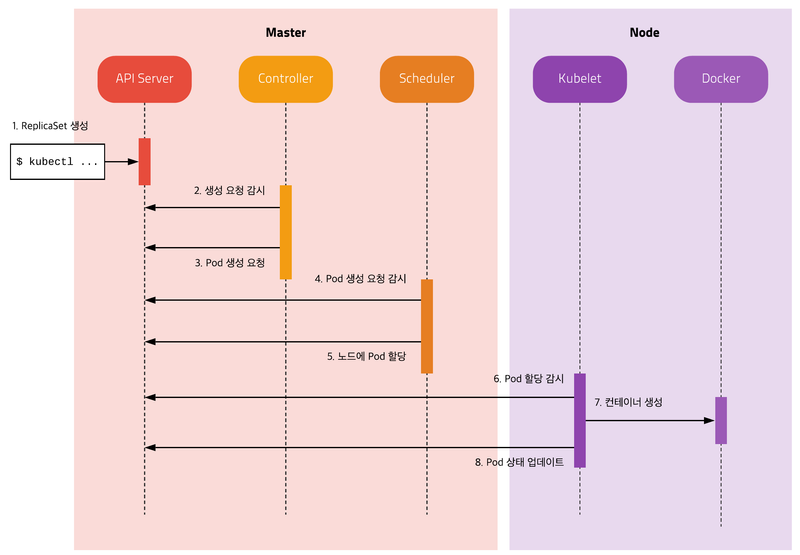
kubectl
- ReplicaSet 명세를 yml파일로 정의하고 kubectl 도구를 이용하여 API Server에 명령을 전달
- API Server는 새로운 ReplicaSet Object를 etcd에 저장
Kube Controller
- Kube Controller에 포함된 ReplicaSet Controller가 ReplicaSet을 감시하다가 ReplicaSet에 정의된 Label Selector 조건을 만족하는 Pod이 존재하는지 체크
- 해당하는 Label의 Pod이 없으면 ReplicaSet의 Pod 템플릿을 보고 새로운 Pod(no assign)을 생성. 생성은 역시 API Server에 전달하고 API * Server는 etcd에 저장
Scheduler
- Scheduler는 할당되지 않은(no assign) Pod이 있는지 체크
- 할당되지 않은 Pod이 있으면 조건에 맞는 Node를 찾아 해당 Pod을 할당
Kubelet
- Kubelet은 자신의 Node에 할당되었지만 아직 생성되지 않은 Pod이 있는지 체크
- 생성되지 않은 Pod이 있으면 명세를 보고 Pod을 생성
- Pod의 상태를 주기적으로 API Server에 전달
