AI
1.[AI]🧠 CNN(Convolutional Neural Network) 정리

합성곱 신경망(CNN)은 고차원 데이터를 효율적으로 처리하고, FCN(Fully Connected Network)의 연산량 및 오버피팅 문제를 해결하기 위해 등장한 구조입니다. 이미지 처리뿐 아니라 음성, 시계열 등 다양한 도메인에서 활용되고 있습니다.이미지처럼 고차원
2.[AI] CS229 머신러닝 정리 [1~10강]
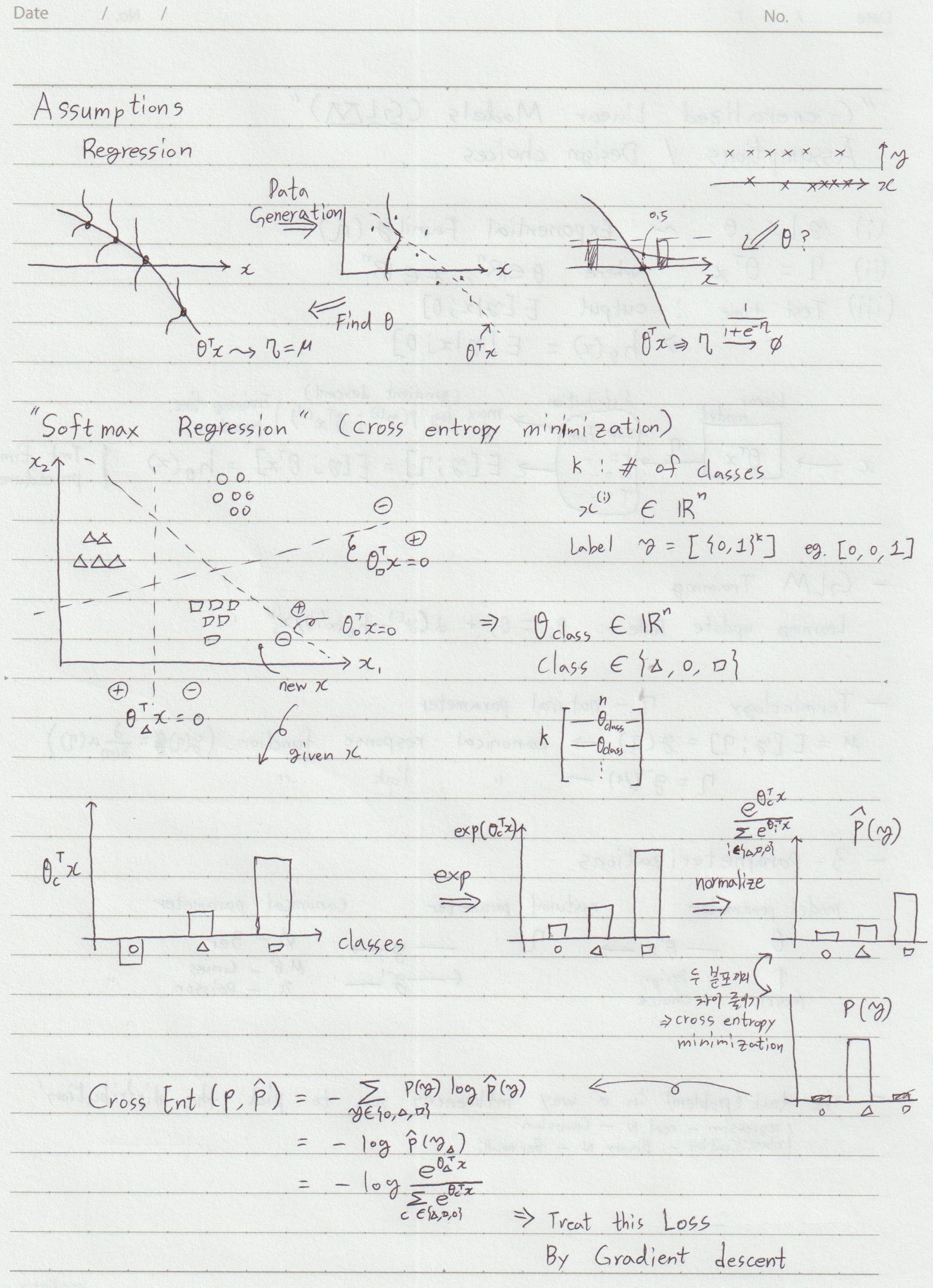
Stanford CS229 강의 정리 내용입니다
3.[AI] CS229 머신러닝 정리 [11~20강]
Stanford CS229 강의 정리 내용입니다
4.[AI] CS230 딥러닝 이론 & 꿀팁 정리

1. 딥러닝 프로젝트 꿀팁 2. 논문 읽기 꿀팁 3. 커리어 꿀팁 
고차원 데이터의 심층 탐험: 수학, 직관, 그리고 시각화로 이해하는 차원 축소 고차원 데이터는 마치 복잡하게 얽힌 실타래와 같습니다. 수많은 변수들은 데이터의 본질을 가리고, 분석과 시각화를 극도로 어렵게 만들죠. \\차원 축소(Dimensionality Reduct
6.[AI] L1 & L2 Norm 정리
L1과 L2는 두 점 사이의 거리를 측정하는 서로 다른 방식이며, 이 기하학적 차이가 데이터 과학 전반에서 다양한 활용을 낳는 핵심 원리입니다.정의: 두 점을 잇는 가장 짧은 직선 거리입니다. 🦅원리: 피타고라스의 정리에 기반하며, 우리에게 가장 직관적인 거리 개념입
7.[AI] 배치 정규화(Batch Normalization) vs 레이어 정규화(Layer Normalization) 비교
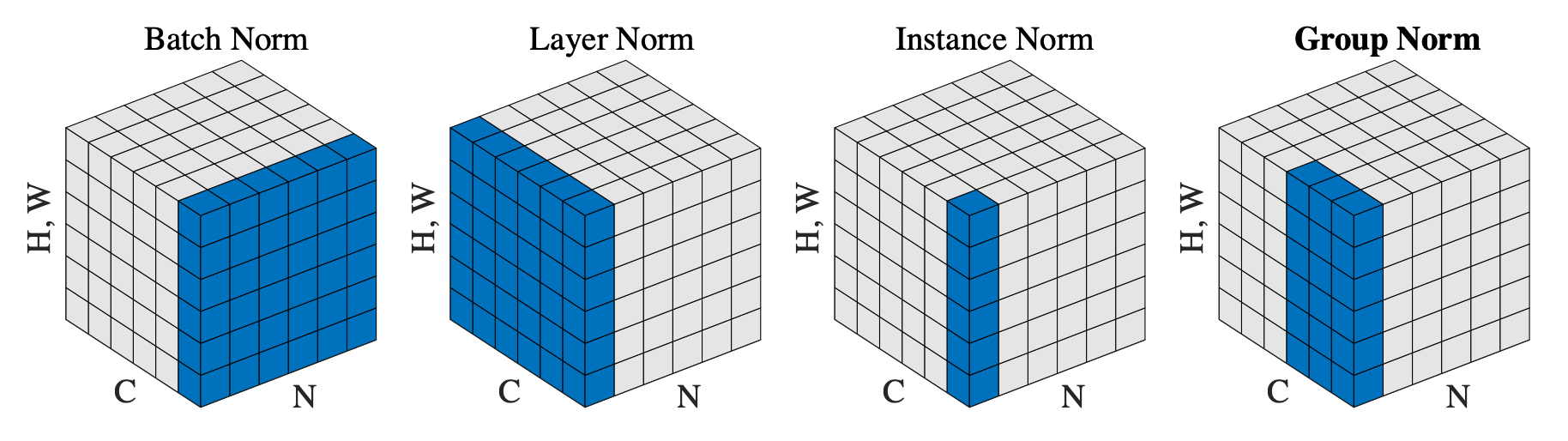
배치 정규화(Batch Norm)와 레이어 정규화(Layer Norm)는 딥러닝 모델의 학습을 안정화하고 속도를 높이기 위해 사용되는 대표적인 정규화 기법입니다. 두 기법 모두 활성화 함수(activation function)에 들어가는 입력값의 분포를 평균 0, 분산
8.[AI] KL Divergence와 JSD
LLM 관련 논문을 읽다 보면KL Divergence와 Jensen–Shannon Divergence(JSD)가 자주 등장한다.둘 다 “분포 비교”라고 설명되지만, 실제로는 쓰이는 목적과 의미가 꽤 다르다.이 글에서는KL과 JSD의 차이를 수식 나열이 아니라LLM /
9.[AI] EM 알고리즘 & 최대우도추정 & 베이즈 추정 개념 정리
머신러닝/딥러닝 논문을 읽다 보면EM 알고리즘, 최대우도추정(MLE), 베이즈 추정이 자주 같이 나온다.겉보기엔 서로 다른 개념처럼 보이지만, 실제로는MLE는 “학습 목표”EM은 “그 목표를 풀기 위한 방법”베이즈는 “학습을 바라보는 더 큰 관점(불확실성 포함)”으로