PintOS Proj_4 File System
PintOS 마지막 프로젝트이자 user program을 실행시키기 위한 프로젝트들 중 세번째로 File System(이하 FS)을 구현한다.
프로젝트3까지의 핀토스는 disk의 free 영역을 관리하기 위해 bitmap을 사용해왔으며 파일들은 disk의 연속된 sector를 할당받아 사용하고 있었다. 이러한 경우 외부 단편화가 심하게 발생할 수 있다. 여러개의 큰 덩어리로 인해 할당 가능한 영역이 나뉘어있으면 할당 가능한 용량은 충분히 되는데도 연속으로 할당할 수 없어 할당에 실패하게 되는 것이다. 이번 프로젝트에서는 이러한 문제를 해결하기 위해 FS를 도입하고 FS가 FS답게 동작할 수 있도록 subdirectory, link 등을 구현한다.
Indexed and Extensible Files
File system 에는 FFS, EXT, FAT 등 다양한 종류가 있다.
FFS는 Fast File System인데, 이는 말 그대로 빠르게 동작하는 FS를 구현하기 위해 만들어졌다. SSD를 사용하는 최근의 secondary memory의 경우에도 해당되는지는 잘 모르겠으나 이전에 사용되던 HDD의 경우 물리적인 디스크를 사용하였으며 원하는 sector를 읽기 위해서는 disk head를 움직여야했다. 이 작업을 seek라고 하는데 읽으려는 sector가 여기저기 분산되어있으면 seek 동작이 자주 일어나고 disk를 읽는 속도가 느려지게 된다. FFS는 이를 개선하기 위한 방법으로 짧은 시간 내 다시 읽힐 가능성이 큰 data를 가까운 곳에 배치하는 방법이다. Disk를 여러개의 cylinder로 나누고 어떠한 디렉토리와 이와 연결된 파일의 inode와 data 등을 하나의 cylinder에 배치하는 방식으로 구현된다.
EXT는 리눅스계열의 FS로 FFS와 multi level indexing(아래에서 설명) 등의 적용에 따라 ext2, ext3, ext4 등으로 발전되어온 방식이다. 자세한 설명은 필자의 지식이 부족한 관계로 생략한다.
위와 같은 다양한 FS는 대부분 disk의 할당가능한 영역을 bitmap으로 관리한다. 그리고 파일들은 연속된 sector들도 이루어지는것이 아니라 여기저기 흩어져있는 sector들로 이루어진다. 그렇다면 흩어져있는 sector들을 어떻게 하나의 file로 읽어오는 것일까. (일단 가상메모리가 연속된 가상주소로 접근되지만 실제 물리메모리에는 프레임들이 여러군데로 흩어져있었던 그림이 상상된다.)
파일의 메타데이터(파일과 관련된 정보들:파일크기, 생성일자, 수정일자 등)는 inode라는 자료구조로 관리된다(여기서 inode는 index node의 줄임말이다). 이 inode에는 다양한 정보를 저장하는데, 파일의 실제 data가 어느 sector에 위치하는지에 대한 정보도 포함된다. 이를 포인터라고 하는데 하나의 포인터는 하나의 섹터 또는 클러스터의 첫번째 주소를 가리킬 수 있다. 사이즈가 큰 파일의 경우 많은 수의 섹터 또는 클러스터로 이루어지기에 수 많은 포인터를 필요로 하게 된다. 하나의 inode에 모든 포인터를 담을 수 없기에 정해둔 수 만큼의 포인터를 inode에 담고 더 필요한 경우 포인터들을 담아둔 다른 섹터를 다시 가리키게 하는 방식으로 data를 관리하는데, 이를 multi level indexing이라고 한다. 보통 바로 데이터를 가리키는 12개(11개?)의 직접포인터와 포인터들을 담아둔 섹터를 가리키는 1개의 간접포인터로 구성된다고 한다. 의아할 수 있는 점이 직접포인터의 개수가 간접포인터의 개수보다 훨씬 많다는 점인데, 이는 통계적으로 컴퓨터에서 작은 사이즈의 파일이 훨씬 많기 때문에 작은 사이즈의 파일을 빠르게 읽을 수 있도록 하기 위함이라고 한다.
Multi level indexing은 구현하기에 굉장히 복잡한데, 이에 비해 FAT 파일 시스템은 cluster들의 연결관계를 단순한 방법으로 관리한다. FAT은 File Allocation Table로 data area의 할당여부와 cluster들의 연결관계를 관리하는 table을 의미한다. 이 table의 entry개수는 data영역의 총 cluster수와 같으며 각 entry의 index는 cluster들의 index(number)와 같다. 할당되지 않은 cluster의 entry는 0으로 세팅되어있어 file 생성시 FAT의 entry들 중 0 값을 갖는 entry를 찾음으로서 cluster를 할당할 수 있다. 할당된 cluster의 entry는 그 다음으로 연결된 cluster의 index값을 저장하며 마지막 cluster일 경우에는 지정된 EOC(End Of Chain)값을 저장한다. 이로써 파일을 읽을 때 연결된 cluster를 찾아 data가 저장된 sector를 찾을 수 있다.
이 챕터에서는 이전까지의 free map allocator 방식을 FAT 방식으로 바꾸어 FS를 구현한다. 이는 FS에 FAT이 적용되어야 할 뿐만 아니라, 기존의 방식으로 구현되어있는 모든 부분(inode, directory 등)에 FAT이 적용되어 FS가 정상적으로 작동할 수 있도록 대폭 수정이 필요하다.
기존의 FS에서는 파일의 크기가 초기에 확정되며 이후에는 파일의 크기를 변경할 수 없었다. FAT을 적용한 후의 PintOS는 파일이 확장될 수 있어야 한다. 파일의 확장은 파일에 write할 때 필요에 따라 발생될 수 있으며 필요한 크기에 따라 추가로 cluster를 할당받고 사용할 수 있도록 초기화를 해주어야 한다.
아래는 필자가 현 챕터 구현을 위해 노션에 정리한 내용이다. 공부하고 설계하면서 초반에 작성한 내용이라 중간에 바뀐 내용들이 덜 반영되기도 하였고 정리가 덜 되어있기도하니 참고만 하면 좋을 듯 하다.




Subdirectories and Soft Links
현재 PintOS의 FS는 모든 파일이 root directory안에만 존재할 수 있다. 이 챕터에서는 directory안에 directory가 존재 할 수 있도록 subdirectory를 구현해야 한다.
Unix에서는 directory를 하나의 file로 관리한다. 즉 directory는 file과 동일하게 inode를 가지며 실제 data가 저장된 cluster들로 구성된다. 일반 file과 다른점은 일반 file의 경우 file에 무슨 내용이 있는지 OS가 알 수 없지만 directory는 특정한 규칙?대로 내용이 구성되어있어 OS가 내용을 예측하고 읽어올 수 있다는 점이다.
Directory는 directory entry들로 채워진 sector를 가진 파일이다. 각 entry는 file이나 directory를 저장할 수 있는데, 이때 저장한다는 것은 file의 inode가 있는 sector와 file name등을 저장하는 것을 의미한다. 파일을 open하는 동작을 간단하게 살펴보면, 먼저 directory에서 파일이 위치하는 directory의 파일을 찾아 열면서 타고들어간 뒤 파일이 있는 directory에서 파일을 찾고 해당 파일을 열게 된다.
Directory에는 절대경로와 상대경로가 있는데 절대경로는 root directory로부터 시작하는 경로로 /a/b/c와 같은 방식으로 표현되며 상대경로는 현재 directory로부터 시작되는 경로로 ./a/b/c와 같은 방식으로 표현된다. 특히 ..은 부모 directory를 가리키며 .은 현재 directory를 가리킨다. 모든 directory는 ..과 .을 저장하고 있어야 하며 root directory의 경우 부모 directory가 없으므로 ..과 . 은 root directory 자신을 가리켜야 한다.
Subdirectory가 구현되고나면 FS와 관련된 여러 system call에서 경로를 포함한 file name이 입력되더라도 해당 directory에서 file을 찾을 수 있어야한다. 따라서 입력으로 들어온 string을 parsing하는 과정이 구현되어야한다.
Link는 쉽게말해 바로가기를 의미한다. Link에는 hard link와 soft link가 있다. Hard link는 directory entry가 직접 file을 가리키는 방법이며 이 경우 원본 file은 자신을 가리키는 link의 수 (참조횟수)를 기록하여 해당 참조횟수가 0이 되어야 실제로 file이 remove된다. Soft link는 이와 달리 file에 원본파일의 경로를 저장하는 방식으로 원본파일이 삭제되면 파일에 접근할 수 없게 된다. 이 챕터에서는 이 soft link를 구현하여 soft link로 접근하여도 원본 파일로 접근할 수 있도록 해야한다.



Buffer Cache (Extra)
현재의 FS은 file을 읽거나 쓸때 요청 시점에 바로 disk에 요청을 보내 읽어오거나 쓰고 있다. 하지만 disk I/O의 작업은 상당히 느려서 요청이 있을 때마다 처리하면 OS의 성능이 좋지 않아진다. 그래서 대부분의 실제 OS는 disk에 대한 읽기 쓰기 요청을 지연시켰다가 일괄적으로 처리하는데 이를 buffer cache라고 한다. 이 extra 챕터에서는 PintOS에서도 이 buffer cache가 작동할 수 있도록 buffer cache page를 만들고 적절한 때에 swap in/out action을 통해 data를 읽거나 쓸 수 있도록 한다.
Synchronization (Extra)
Disk와 disk내 file들은 공유자원이다. 그러므로 한번에 한 프로세스만 작업할 수 있도록 동기화가 필요하다. Disk의 경우 이미 lock이 구현되어있다. 하지만 file의 경우에는 추가적인 구현이 필요하다. 파일을 read하는 경우 여러 프로세스에서 동시에 read가 가능해야하지만 write의 경우 한번에 한 프로세스만 write할 수 있도록 구현해야한다(read/write문제).
Journaling & Mount (Extra)
FS에서 write를 하다가 crash가 나는 경우에 OS는 원자성(atomicity)을 보장해야한다. 즉, write가 성공하거나 아니면 아예 바뀌지 않거나 해야하는 것이다. 이를 위해 OS는 원본 File에 write를 하기 전에 따로 동일한 내용을 다른 영역에 기록하고, 이 기록이 성공하면 원본 file에 write를 한다. Write하다가 컴퓨터가 꺼지는 등의 문제가 발생하면, 부팅시 해당 영역을 확인하고 필요하면 해당 write작업을 진행하여 원본file이 정상적으로 변경될 수 있도록 한다. 이렇게 다른 영역에 기록해놓는 것을 Journaling이라고 하며 기록된 것을 log라고 한다.
USB와 같이 외부 FS가 연결되는 경우 OS에서는 root FS에 외부 FS를 연결하여 사용할 수 있도록 해야한다. 이를 Mount라고 한다.
회고
마지막 PintOS프로젝트였던 File system은 정글의 마지막 프로젝트인 '나만의 무기를 만들자'를 앞두고 바로 직전의 프로젝트였고 기간도 일주일로 짧았다. 분위기도 술렁이고 쉽지 않았지만 그래도 가능한 한 끝까지 해보고싶어서 열심히 해보았는데 결국 모든 과제를 수행하지는 못해 아쉬웠다. 하지만 subdirectory와 soft link를 구현하고 디버깅에 성공하자 extra 과제와 관련된 test case 2개를 제외하고는 모두 pass가 되어 그래도 의미있게 PintOS를 마무리할 수 있었다.
File system은 이전 project들에 비해서 안내되는 내용이 부족하여 어디까지 수정해야하는건지 찾는데 꽤 어려움을 겪었다. 안내자료에는 거의 FAT을 구현하는 부분만 소개가 되었는데 내 생각으로는 file system이 바뀌는만큼 많은 부분에서 수정이 되어야할 것이라고 생각했다. 역시나 기존 code의 많은 부분에서 기존의 system에 특화되어 적용되어있어 수정이 많이 필요해보였는데, code에는 수정이 필요하다거나 구현하라는 내용이 전혀 없었다(기존에는 일부 code에 to do 또는 your code goes here와 같이 어느정도 힌트가 포함되어있었다). 그럼에도 내 생각에는 반드시 수정이 필요하다고 판단되어서 팀원들과 얘기를 나누고 역할을 나누어 세세한 부분까지 수정을 진행했다. 진행하면서도 이렇게까지 해야하는게 맞을까 의문이 많이 들었지만 그렇지 않으면 작동하지 않을거라 생각했기에 끝까지 진행했고 그 끝에 test case들이 통과하는것을 보면서 이렇게 하는것이 맞았다는 것을 확인할 수 있었다. 너무도 코드 수정의 자유도가 높았어서 극악의 난이도였지만 그만큼 통과하는것을 봤을때 더 뿌듯함을 느낄 수 있었다. 안내자료에 세세한 부분들이 소개되어있지 않은 부분들이 조금은 불만이었지만 현업에서는 어떤 안내 없이 내가 구현해야하는 또는 구현하고싶은 것을 직접 설계하고 구현해야하는 만큼 큰 도움이 되었다고 생각이 들고 이런 것을 의도한 것이 아닐까 싶기도 했다.
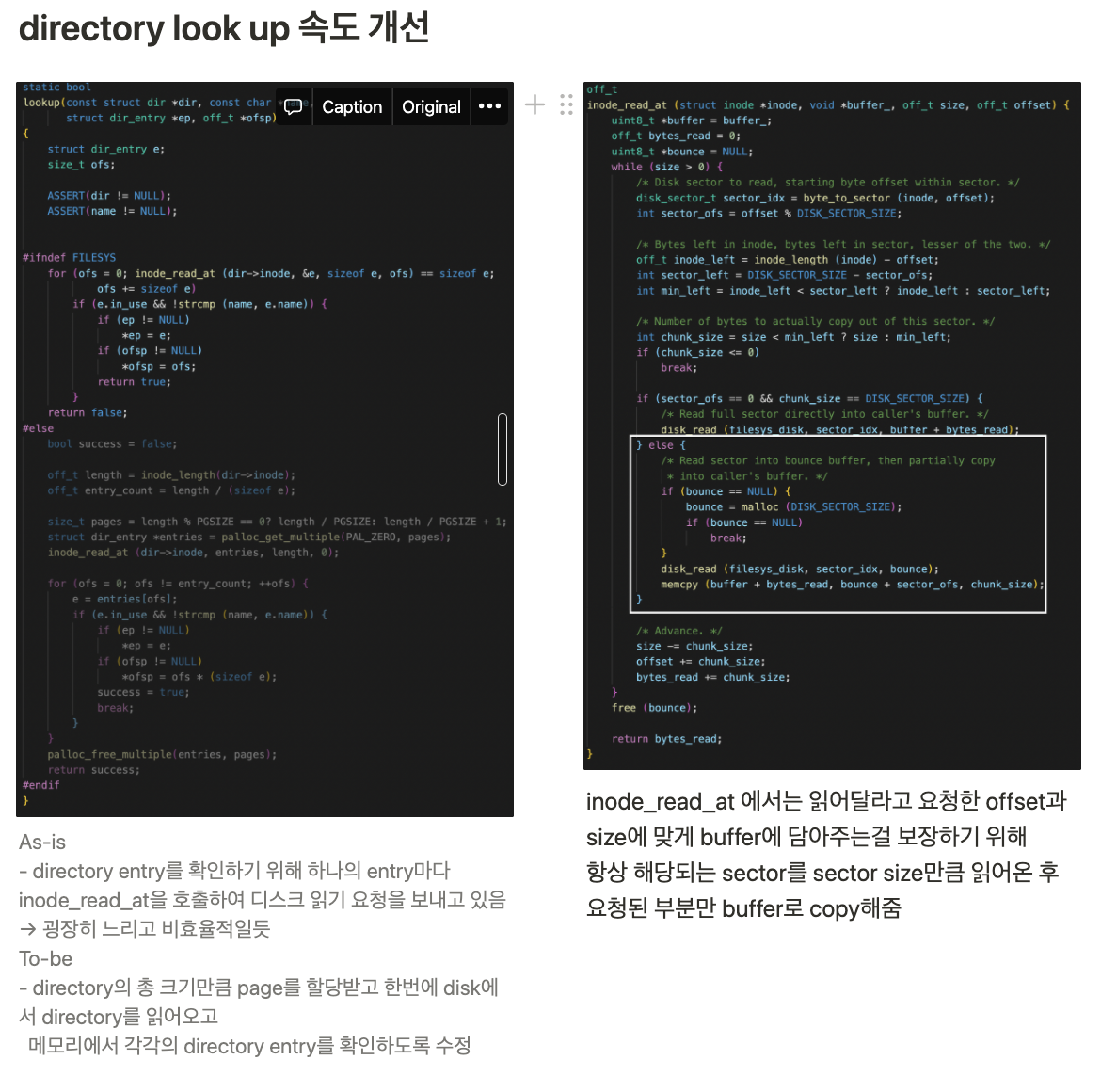
특히 기억에 남는 부분은 속도가 많이 느린 부분을 개선한 부분이다. 디렉토리에서 엔트리를 검색하는 과정이었는데, 기존의 코드에서는 디렉토리 엔트리를 확인하기 위해 엔트리의 크기만큼을 반복해서 디스크에서 읽어오고 있었다. 그리고 디스크에서 읽어오는 동작에서는 디스크에서는 섹터 단위로 읽을 수 있기 때문에 512바이트만큼을 읽어오는데, 그 중에서 엔트리는 32바이트(그렇게 설계했다)이기 때문에 읽어온 512바이트 중에 32바이트에 해당하는 부분만 복사하여 돌려주고 있었다. 엔트리 16개가 들어있는 512바이트를 이미 다 읽어왔으면서도 그 중 32바이트만 쓰고 나머지는 버리고 있었고, 그래놓고 다시 32바이트를 똑같은 섹터에서 반복해서 읽어오고 있던 것이다. 그래서 필자는 디렉토리로부터 실제 디렉토리에 있는 엔트리의 수만큼을 한번에 메모리로 읽어오고 메모리에서 엔트리들을 검색할 수 있도록 수정했고, 이 개선으로 인해서 타임아웃이 발생했던 여러 케이스를 통과시킬 수 있었다.
이제는 정글의 마지막 프로젝트인 나만무 만 앞두고 있다. 하루 빨리 개발자로 성장하여 취업하고 싶었는데 어느새 수료까지 두달도 남지 않았다. 그래서 기대도 되지만 조금은 두려운 마음이 든다. 두려움보다는 자신감과 기대감으로 취업할 수 있게 남은 기간 알고리즘도 프로젝트도 놓치지 않도록 노력해야겠다.
