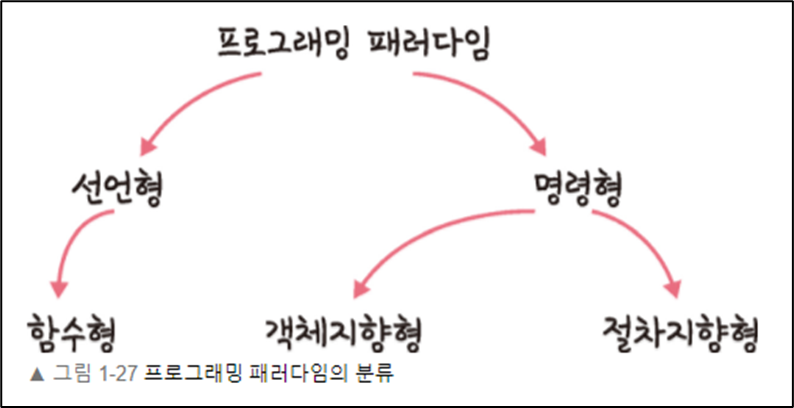
함수형 프로그래밍이란?
프로그래밍 패러다임 중 하나로 계산을 수학적 함수의 평가로 간주해, 상태의 변경과 가변 데이터보다 함수의 호출, 조합을 통해 프로그램을 작성하는 방식을 뜻한다.
이러한 접근방식을 통해 사이드 이펙트를 최소화 하려고 하며, 데이터의 불변성을 중시한다.
그렇다면 최근에 함수형 프로그래밍이 재조명 받았었던 이유는?
1958년도에 MIT에서 나온 LISP(LIST Programming)이 함수형 프로그래밍의 개념으로 처음 나왔으나 낮선 문법과 부족한 컴퓨터 성능, 저수준 언어 지원이 대부분인 산업환경, 학습의 장벽 등으로 널리 사용되지는 않았었다고 한다. 최근 재조명된 이유로는 컴퓨터의 성능이 발전하여 병렬, 분산 처리가 가능해 성능 최적화가 가능해지고, 간결하고 이해하기 쉬운 코드, 데이터 처리 흐름을 명확하게 볼 수 있다는 점을 꼽을 수 있다.
함수형 프로그래밍에 대한 장, 단점을 간단히 알아보자!
장단점을 짧게 요약하면 장점은 코드의 예측 가능성과 안정성을 높이고, 단점은 학습 곡선과 성능 문제가 있을 수 있다는 것인데 풀어서 설명하면 다음과 같다.
장점1) 순수 함수와 불변성: 함수형 프로그래밍은 순수 함수(부작용이 없는 함수)를 장려하며, 데이터의 불변성을 유지한다. 이런 특징은 코드의 예측 가능성을 높이고 병렬 처리와 같은 최적화를 쉽게 할 수 있게 한다.
장점2) 모듈화와 재사용성: 함수형 프로그래밍은 작은 함수들을 조합하여 복잡한 동작을 만들어내기 때문에 코드의 모듈화와 재사용성이 높다.
장점3) 코드의 간결성과 가독성: 함수형 프로그래밍에서는 상태 변이가 줄어들기 때문에 코드가 간결하고 읽기 쉬워진다.
단점1) 학습 곡선: 명령형 프로그래밍에서 벗어나 함수형 프로그래밍으로 넘어가는 데는 적응이 필요하다. 특히 순수 함수와 재귀적 접근 방식 등에 익숙하지 않은 개발자에게는 학습 곡선이 높을 수 있다.
단점2) 성능 문제: 함수형 프로그래밍에서는 불변성을 유지하기 위해 새로운 데이터 구조를 생성하는 경우가 많아 메모리 사용과 성능 문제가 발생할 수 있다. 이러한 단점을 최적화 기법을 사용하면 이러한 문제를 완화할 수 있다고 한다.
단점3) 모든 문제에 함수형 프로그래밍이 적합한 것이 아닐 수 있다.
함수형 프로그래밍의 주요 일곱가지 특징은?!(간단한 예시)
- 순수 함수 (Pure Functions): 순수 함수는 동일한 입력에 대해 항상 동일한 출력을 반환하며, 외부의 상태를 변경하지 않는다. 부작용이 없기 때문에 코드의 테스트와 디버깅이 용이하고, 병렬 처리를 쉽게 할 수 있다.
// 순수 함수 예시: 입력에 따라 항상 동일한 결과를 반환하는 함수 function add(a, b) { return a + b; } const result = add(3, 5); // 결과: 8 console.log(result);
- 불변성 (Immutability):데이터는 변경 불가능해야 하며, 한 번 생성된 데이터는 수정할 수 없다. 데이터의 불변성은 코드의 예측 가능성을 높이고, 여러 스레드나 프로세스에서 안전하게 공유될 수 있도록 한다.
// 불변성 예시: 기존 배열을 변경하지 않고 새로운 배열을 생성하는 함수 const numbers = [1, 2, 3, 4, 5]; function doubleArray(arr) { return arr.map(num => num * 2); } const doubledNumbers = doubleArray(numbers); // 기존 배열은 변경되지 않음 console.log(numbers); // 기존 배열: [1, 2, 3, 4, 5] console.log(doubledNumbers); // 새로운 배열: [2, 4, 6, 8, 10]
- 함수의 일급 객체 (First-Class Functions): 함수는 다른 데이터 타입과 마찬가지로 변수에 할당하거나 함수의 인자로 전달하거나 함수의 반환값으로 사용될 수 있다. 이를 통해 함수를 더욱 유연하게 조작하고 조합할 수 있게 한다.
// 함수의 일급 객체 예시: 함수를 변수에 할당하고, 다른 함수에 인자로 전달하기 const sayHello = function() { console.log('Hello, world!'); }; function greet(greetingFunction) { greetingFunction(); } greet(sayHello); // 출력: Hello, world!
- 함수 조합 (Function Composition): 작은 함수들을 조합하여 복잡한 동작을 만들어낸다. 조합을 통해 코드의 재사용성을 높이고, 더욱 추상화 된 레벨에서 프로그래밍을 할 수 있게 한다.
// 함수 조합 예시: 함수를 조합하여 순서대로 실행하는 파이프라인 구성 function addOne(num) { return num + 1; } function double(num) { return num * 2; } const transform = (num) => addOne(double(num)); const result = transform(3); // addOne(double(3)) -> addOne(6) -> 7 console.log(result); // 출력: 7
- 재귀 (Recursion): 반복문 대신 재귀를 많이 사용하며, 재귀는 함수형 프로그래밍에서 반복적인 처리를 구현하는 주요 방법으로 함수형 언어에서는 재귀 최적화 기법을 제공하여 성능을 최적화한다.
// 재귀 예시: 팩토리얼 계산을 재귀적으로 구현 function factorial(n) { if (n === 0 || n === 1) { return 1; } return n * factorial(n - 1); } const result = factorial(5); // 5 * 4 * 3 * 2 * 1 = 120 console.log(result); // 출력: 120
- 데이터 변환과 파이프라인 (Data Transformation and Pipelines): 데이터를 변환하는 과정에서 함수형 프로그래밍은 일련의 함수 호출을 사용하여 데이터의 흐름을 설명한다. 이는 데이터 처리 과정을 명확하게 만들어 준다.
// 데이터 변환과 파이프라인 예시: 배열에서 짝수를 필터링하고 각 값을 제곱한 후 합을 구하는 파이프라인 const numbers = [1, 2, 3, 4, 5]; const sumOfEvenSquares = numbers .filter(num => num % 2 === 0) // 짝수 필터링 .map(num => num ** 2) // 제곱 .reduce((acc, curr) => acc + curr, 0); // 합 구하기 console.log(sumOfEvenSquares); // 출력: 20 (2^2 + 4^2)
- 모듈화와 추상화 (Modularity and Abstraction): 함수형 프로그래밍은 코드를 작은 단위로 분리하고, 각 단위를 독립적이고 재사용 가능한 모듈로 만드는 데 중점을 둔다. 이를 통해 코드의 유지보수성을 높이고, 복잡성을 줄이는 데 도움을 준다.
// 모듈화와 추상화 예시: 간단한 수학 연산 함수들을 모듈화하여 사용 function add(a, b) { return a + b; } function multiply(a, b) { return a * b; } function applyOperation(a, b, operation) { return operation(a, b); } const result1 = applyOperation(3, 4, add); // 3 + 4 = 7 const result2 = applyOperation(3, 4, multiply); // 3 * 4 = 12 console.log(result1); // 출력: 7 console.log(result2); // 출력: 12
함수형 프로그래밍에 대해 대강 개념을 이해한 후 인프런 강의를 수강해보았다 - [inflearn 함수형 프로그래밍과 JavaScript ES6+ 응용편]
FxJS라는 라이브러리를 사용하여 함수형 프로그래밍을 어떻게 해야하는지, 어떤 장점이 있는지 배우게 되었다. 우선 FxJS는 함수형 프로그래밍을 지원하기 위한 라이브러리로 Mapple이라는 회사에서 만들었다.
다양한 고차 함수와 유틸리티들을 제공하여 개발자가 함수형 스타일로 코드를 작성하고 관리하기 편하다고 하기에 궁금했다. 강의에서는 간단한 함수를 명령어 프로그래밍에서 함수형 프로그래밍으로 바꾸며 가독성, 성능면에서 어떤점이 좋은지에 대해 설명한다.
우선 FxJS는 함수를 조합하고 합성할 수 있는 다양한 유틸리티 함수를 제공한다. 이를 통해 작고 재사용 가능한 코드를 만들어 데이터 불변성을 보다 쉽게 유지할 수 있다. 기존 ES6 배열 메서드랑 사용법의 큰 차이가 없어 이해가 간편하다. (아래는 간단한 함수들)
/** map: 배열의 각 요소에 함수를 적용하여 새로운 배열을 반환 filter: 배열의 요소 중 조건을 만족하는 요소들로 새로운 배열을 생성 reduce: 배열의 각 요소를 사용하여 단일 값(누적 값)을 계산 flatMap (또는 flat_map): 배열의 각 요소에 함수를 적용하고, 결과를 평탄화하여 새로운 배열을 생성 take: 배열에서 처음 몇 개의 요소를 추출하여 새로운 배열을 반환 drop: 배열에서 처음 몇 개의 요소를 제외한 나머지 요소로 새로운 배열을 생성 slice: 배열에서 지정된 범위의 요소를 추출하여 새로운 배열을 반환 every: 배열의 모든 요소가 조건을 만족하는지 여부를 확인 some: 배열의 어떤 요소라도 조건을 만족하는지 여부를 확인 find: 배열에서 조건을 만족하는 첫 번째 요소를 찾기 pipe: 함수들을 순차적으로 조합하여 새로운 함수를 생성 go: 함수들을 순차적으로 평가하고, 마지막 결과를 반환 */
이제 FxJS의 기본 개념들에 대해 알아보자. (강의에서는 컴포넌트를 만들어서 조합하여 사용하는등 훨씬 고차원의 함수들을 다루고 있다.)
- 함수의 조합성과 모듈화
함수들을 조합하여 파이프라인을 구성할 수 있는 pipe, go와 같은 함수들을 제공하여, 이를 통해 코드를 모듈화하고 재사용성을 높이며, 복잡한 데이터 처리를 간결하게 표현할 수 있다.
const { go, map, filter, take } = require('fxjs'); // FxJS 라이브러리 사용
const data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; // 가정한 데이터
// 데이터를 제곱하고 짝수만 추출하는 함수 (FxJS를 사용하여 작성)
function processData(data) {
return go(
data,
map(x => x * x), // 각 요소를 제곱
filter(x => x % 2 === 0), // 짝수인 요소만 필터링
take(5) // 처음 5개의 결과만 반환
);
}
// 결과를 출력할 때 실제 연산이 수행됨
console.log(processData(data)); // [4, 16, 36, 64, 100]- 지연 평가
fxjs에서는 map, filter, reduce 등의 고차 함수를 사용하여 데이터를 처리하는 것을 장려한다. ES6와 다르게 지연 평가(Lazy Evaluation)를 사용하여 계산이 필요한 시점까지 계산을 미루어 함수가 실행될 때마다 중간 결과를 생성하지 않아 성능에 도움을 준다.
설명보단 그림이 이해가 빨라 다른사이트에서 내용을 캡처 해보았다.
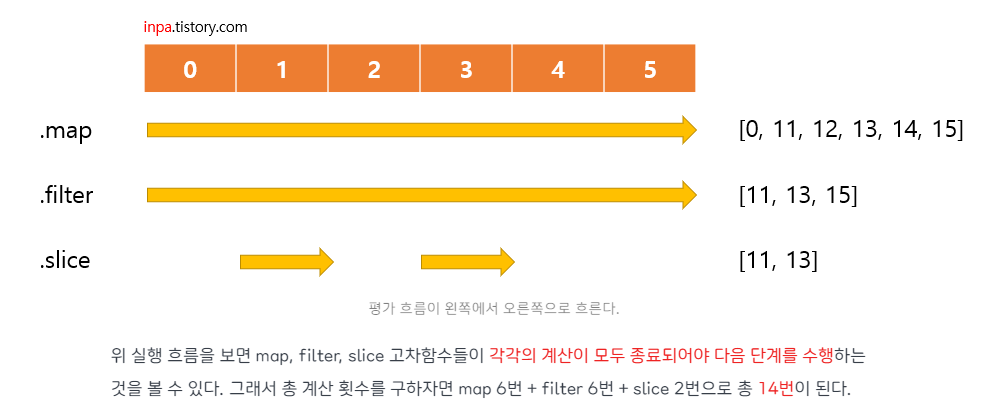
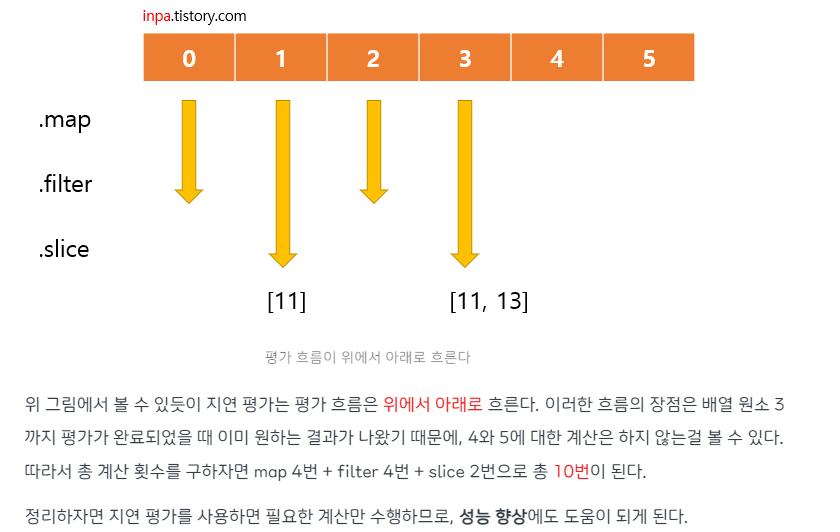
- 데이터 불변성
FxJS는 불변성을 강조하며, 순수 함수를 통해 부작용을 최소화한다. 이는 코드의 예측 가능성과 테스트 용이성을 높이는 데 기여한다.
- 비동기 코드 관리(pipe, go)
함수들을 pipe, go등의 함수로 조합하여 데이터 처리 파이프라인을 쉽게 구성하여 복잡한 로직을 단순하게 표현한다. 또한 비동기 작업을 처리하는 데 유용한 함수를 제공해 "콜백 헬"을 방지하고 Promise 체이닝을 간단하게 만들어준다.
const { pipe, map, filter, reduce } = require('fxjs');
// 예시 데이터
const data = [1, 2, 3, 4, 5];
// pipe를 사용하여 비동기적으로 연결된 함수 호출 구성, go라면 go(data, pipe와 동일하게 작업 map,filter 등...)
const result = pipe(
map(async x => {
// 비동기 작업 수행 (예: API 호출)
const response = await fetch(`https://api.example.com/data/${x}`);
const data = await response.json();
return data.result;
}),
filter(x => x > 0), // 결과를 필터링
reduce((acc, curr) => acc + curr, 0) // 결과를 합산
)(data);
console.log(result); // 비동기 작업이 완료된 후 최종 결과 출력- 커링과 부분 적용
커링(currying)과 부분 적용(partial application)을 사용하여 코드의 재사용성과 유연성을 높인다. 커링은 여러 개의 인자를 받는 함수를 한 개의 인자를 받는 여러 개의 함수들로 변환하는 기법이며, 부분 적용은 함수의 일부 인자를 고정하고, 나머지 인자를 나중에 전달하는 기법이다.
const { curry } = require('fxjs');
const { partial } = require('fxjs');
// 일반적인 덧셈 함수
function add(a, b) {
return a + b;
}
// 커링을 사용한 덧셈 함수
const curriedAdd = curry(add);
// 부분적인 인자 적용
const add2 = curriedAdd(2); // 이 시점에서 add2는 b를 받는 함수이다.
console.log(add2(3)); // 5 출력: 2 + 3
console.log(add2(5)); // 7 출력: 2 + 5
// 부분 적용을 사용한 덧셈 함수
const add3 = partial(add, 2); // 첫 번째 인자를 2로 고정
console.log(add3(3)); // 5 출력: 2 + 3
console.log(add3(5)); // 7 출력: 2 + 5
FxJS는 가독성, 성능, 사이드 이펙트 측면에서 모두 훌륭한가?
강의를 들으며 함수형 프로그래밍은 가독성이 너무 훌륭하고 성능면에서도 좋다고 하니 앞으로 무조건 써야하는 기법이구나... 라는 생각을 했지만 역시 이상과 현실은 달랐다. 일단 명령형 프로그래밍에 익숙해져있는 개발자 전원이 함수형 프로그래밍 기법에 익숙해지기 위한 시간이 필요하다는것과, 협업과 유지보수 측면에서도 추가적인 노력이 들 수 있다는 점이 가장 큰 걸림돌로 보였다ㅠ.
하지만 익숙해져서 무조건 좋은 것이라면 익숙해져야 한다고 생각하던 와중에 성능면에서도 이슈가 생길 수 있다고 한다. 데이터 셋의 크기가 너무 작거나 단순할 때 단순 반복문이 더 좋은 성능을 보일 수 있다고 하며, 너무 복잡한 연산이 들어갈 경우 중간 결과값을 재사용 하기 위해 성능 오버헤드를 초래할 수 있다고 한다. 앞서 함수형 프로그래밍의 단점에서 설명했던 부분이 그대로 나타난다.
결국 장, 단점이 존재하니 상황에 맞게 사용하는것이 좋아 보인다... 아마 시계열 그래프나 대시보드의 위젯같이 단순하지만 여러 경우의 필터링에 필요한 데이터를 요청하고 처리하는 케이스에 사용하면 좋지 않을까 하는 생각이 든다.
