"밑바닥부터 시작하는 딥러닝 2"을 기반으로 정리한 내용입니다.
Word2Vec은 앞서 살펴보았던 통계 기반 기법의 단점을 보완하고자 나온 추론 기반 기법이다. 통계 기반 기법에서는 주변 단어의 빈도를 기초로 단어를 표현했었다. 구체적으로는 동시발생 행렬을 만들고 PPMI 행렬로 변환하고 SVD로 차원을 감소시킴으로써, 거대한 sparse vector를 작은 dense vector로 변환할 수 있었다.
통계 기반 기법은 말뭉치 전체의 통계(동시발생 행렬과 PPMI 등)를 이용해 단 1회의 처리(SVD 등) 만에 단어의 분산 표현을 얻는다. 한편, 추론 기반 기법에서는, 예컨대 신경망을 이용하는 경우는 미니 배치로 학습하는 것이 일반적이다.
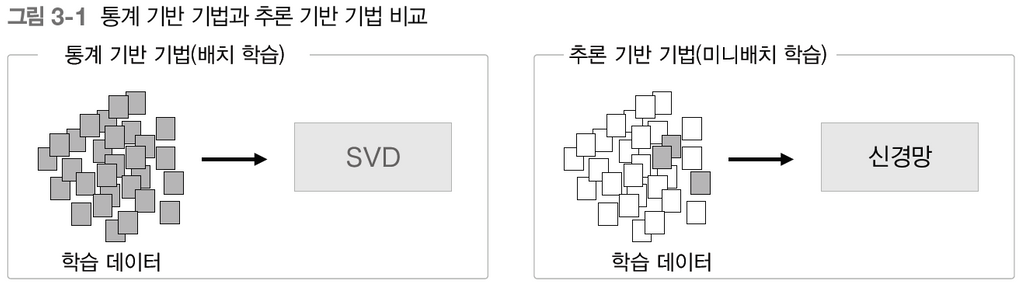
그림 1을 보면 통계 기반 기법은 전체 학습 데이터를 모두 사용해야 하기 때문에 한 번에 처리해야 할 연산량이 많고, 그에 반해 추론 기반 기법은 전체 학습 데이터 중 미니 배치 형태로 학습하기 때문에 계산량에서 큰 이득을 취할 수 있다.
추론 기반 기법의 간단한 예를 들자면
I ____ coke and you like water
라는 문장이 있을 때, "I" 와 "coke"를 사용해서 가운데 단어를 예측 or 추론하는 것을 말한다. 맞추고자 하는 단어의 주변 단어(맥락)를 모델에 입력으로 주고, 모델은 알고 있는 전체 단어들 중 해당 자리에 들어갈 단어의 확률분포를 결과로 준다. 이것이 추론 기반 기법의 기본 개념이다. 그렇다면 추론 기반 기법에서 사용되는 신경망에서는 단어를 어떻게 처리할까?
신경망에서의 단어 처리
신경망을 사용해서 단어를 처리하는 방법론 중 현재까지도 사용되는 Word2Vec에 대해 알아보자. Word2Vec은 2013년 구글에서 나온 논문이고 2가지 모델 아키텍처를 소개했다.
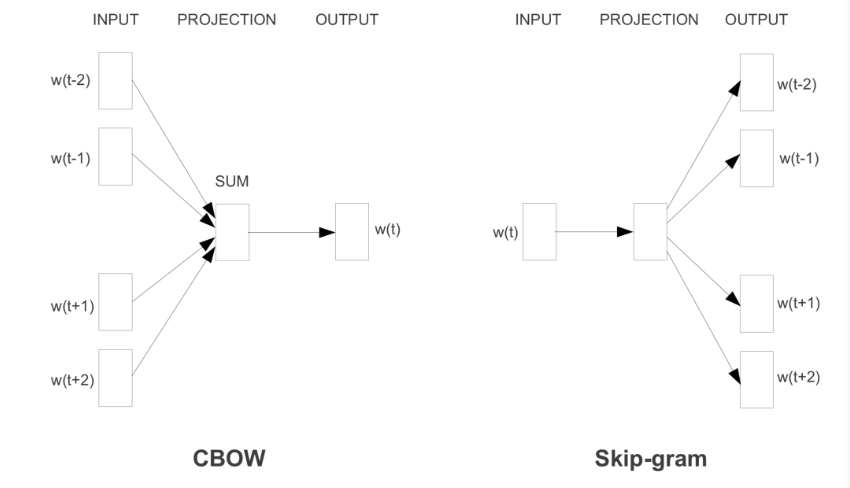
CBOW
CBOW(Continuous Bag of Words) 모델은 맥락(context)으로부터 가운데 있는 target을 예측하는 신경망이다. 예컨대 "I like coke and you like water" 문장이 있을 때, "I"와 "coke"를 CBOW모델 입력으로 주면 결괏값으로 "like"가 나오는 것이다.
Skip-gram
Skip-gram 모델은 CBOW와 반대로 생각하면 된다. 가운데 target 단어를 입력으로 주면 주변 단어(context)를 예측하는 모델이다. "like"를 입력으로 줬을 때, "I'와 "coke"가 결괏값으로 나오는 것이다.
CBOW 모델은 multi-classification 문제이기 때문에 학습하기 위해서는 softmax와 cross-entropy만 사용하면 된다. softmax를 활용해서 출력층에서의 확률값을 구하고 그 확률과 정답 레이블로부터 교차 엔트로피 오차를 구해서 backpropagation으로 학습시키면 된다.
위 그림을 보면 input layer, hidden layer, output layer, 총 3개의 layer로 구성되어 있고 input->hidden 사이에 weight_in이 있고 hidden->output 사이에 weigth_out이 존재하게 된다. 학습단에는 두 가중치를 모두 학습시키지만 최종적으로 사용하는 가중치는 입력 측의 가중치만 이용하는 것이 word2vec에서는 가장 효과적이라고 한다.
CBOW vs Skip-gram
두 기법중 어느 것이 더 좋은 성능을 보여줄까? Skip-gram이 더 좋은 성능을 나타낸다고 한다. 예컨대 사람이 직접 단어를 예측한다고 생각해보면, 주변 단어를 보고 가운데 단어를 맞추는 것이 가운데 단어를 보고 주변 여러 단어를 맞추는 것보다 쉬울 것이다. 신경망도 같은 맥락이다. 가운데 단어를 보고 주변 여러 단어를 맞추는 것(skip-gram)이 더 어려운 상황에서 단련하는 만큼 단어의 분산 표현이 더 뛰어날 가능성이 커지는 것이다.
정리
- 추론 기반 기법은 추측하는 것이 목적이며, 단어의 분산 표현을 얻을 수 있다.
- word2vec은 추론 기반 기법이며, 단순한 2층 신경망이다.
- word2vec은 skip-gram과 CBOW 모델을 제공한다.
- CBOW는 맥락으로부터 타깃을 예측한다.
- skip-gram은 타킷으로부터 맥락을 예측한다.
- word2vec은 가중치를 다시 학습할 수 있으므로, 단어의 분산 표현 갱신이나 새로운 단어 추가를 효율적으로 수행할 수 있다.
