간단한 사용법
1. QuerydslRepositorySupport
@Repository
public class UserRepositorySupport extends QuerydslRepositorySupport {
private final JPAQueryFactory jpaQueryFactory;
public UserRepositorySupport(JPAQueryFactory jpaQueryFactory) {
super(User.class);
this.jpaQueryFactory = jpaQueryFactory;
}
}2. Custom / Impl 사용 -> 항상 2개의 Repository를 의존성으로 받아야 함.
public interface UserRepositoryCustom {
}
@RequiredArgsConstructor
public class UserRepositoryImpl implements UserRepositoryCustom{
private final JPAQueryFactory jpaQueryFactory;
}3. QueryRepository 만들기
@RequiredArgsConstructor
@Repository
public class UserQueryRepository {
private final JPAQueryFactory jpaQueryFactory;
}4. 참고 사항
- QUser가 생성안됬을 경우
Gradle -> Tasks -> other -> complieJava를 실행하면 Q파일(build/generated)이 생성됨. - QUser.user -> user로 사용하고 싶을 때
import com.example.demo.business.user.entity.QUser;
// 위처럼 import 되는데 아래처럼 변경하면 QUser.user 를 user로 사용이 가능함
import static com.example.demo.business.user.entity.QUser.user;쿼리 사용해보기 (위의 3번째 방식)
- 쿼리
from: 쿼리 소스를 추가
where: 쿼리 필터를 추가(가변인자나 and/or 메서드를 이용해서 필터를 추가)
public List<User> findByName(String name) {
return jpaQueryFactory.selectFrom(user)
.where(user.name.eq(name))
.fetch();
}- 조인
innerJoin, join, leftJoin, rightJoin, on: 조인 부분을 추가
조인 메서드 (첫 번째 인자는 조인 소스, 두 번재 인자는 대상(별칭))
// left, right, inner 조인 동일함 .on()도 사용이 가능
public User joinBook() {
return jpaQueryFactory.selectFrom(user)
.join(user.book, book)
.fetchFirst();
}
public User joinBook2() {
return jpaQueryFactory.selectFrom(user)
.join(user.book, book)
.on(user.age.gt(30))
.fetchFirst();
}select user0_.id as id1_1_, user0_.age as age2_1_, user0_.book_id as book_id5_1_, user0_.email as email3_1_, user0_.name as name4_1_
from user user0_
inner join book book1_
on user0_.book_id=book1_.id
limit ?
select user0_.id as id1_1_, user0_.age as age2_1_, user0_.book_id as book_id5_1_, user0_.email as email3_1_, user0_.name as name4_1_
from user user0_
inner join book book1_
on user0_.book_id=book1_.id and (user0_.age>?)
limit ?- 정렬
orderBy: 정렬 표현식을 이용해서 정렬 순서를 지정
숫자나 문자열에 대해서는 asc()나 desc()를 사용
OrderSpecifier에 접근하기 위해 다른 비교 표현식을 사용
public List<User> orderByName(){
return jpaQueryFactory.selectFrom(user)
.orderBy(user.name.asc())
.fetch();
}- 그룹핑
groupBy: 가변인자 형식의 인자를 기준으로 그룹을 추가
having: Predicate 표현식을 이용해서 "group by" 그룹핑의 필터를 추가
public List<String> groupByName(){
return jpaQueryFactory.select(user.name).from(user)
.groupBy(user.name)
.fetch();
}- 서브쿼리
- Select SubQuery
public List<UserForm.Response.Count> selectSubQuery(){
return jpaQueryFactory
.select(
Projections.fields(
UserForm.Response.Count.class,
user.name,
ExpressionUtils.as(
JPAExpressions.select(book.count())
.from(book)
.where(book.author.eq(user.name)),
"num")
)
)
.from(user)
.fetch();
}select user0_.name as col_0_0_, (
select count(book1_.id)
from book book1_
where book1_.author=user0_.name
) as col_1_0_
from user user0_- Where SubQuery
public List<Book> whereSubQuery(String name){
return jpaQueryFactory
.selectFrom(book)
.where(book.author.eq(
JPAExpressions
.select(user.name)
.from(user)
.where(user.name.eq(name))
)
)
.fetch();
}select book0_.id as id1_0_, book0_.author as author2_0_, book0_.price as price3_0_, book0_.title as title4_0_
from book book0_
where book0_.author=(
select user1_.name from user user1_ where user1_.name=?
)- 동적쿼리 : BooleanExpression을 사용
BooleanExpressiond은 각 메소드에서 조건이 맞지 않으면 null을 리턴, 만족하면 메서드 리턴
public User dynamicQuery(String name, int age){
return jpaQueryFactory
.selectFrom(user)
.where(
eqName(name),
gtAge(age)
)
.fetchFirst();
}
private BooleanExpression eqName(String name) {
if (StringUtils.isEmpty(name)) {
return null;
}
return user.name.eq(name);
}
private BooleanExpression gtAge(int age) {
if (age == 0) {
return null;
}
return user.age.gt(age);
}- 그 외
limit, offset, restrict: 결과의 페이징을 설정
limit은 최대 결과 개수
offset은 결과의 시작 행
restrict는 limit과 offset을 함께 정의
Select 성능 개선
1. exist 사용 금지
왜? QueryDSL은 SQL의 exist가 아닌 count를 사용함!! public Boolean exist(Long id) {
Integer fetchOne = jpaQueryFactory
.selectOne()
.from(user)
.where(
user.id.eq(id)
)
.fetchFirst();
return fetchOne != null;
}조회 결과가 없으면 null을 반환하기 때문에, null 체크를 통해 엔티티 존재 여부를 반환2. cross Join 금지 -> innerJoin 사용
- Hibernate의 이슈이기 때문에 Spring Data JPA를 사용하는 이상 어쩔 수 없음
3.Entity보다는 Dto를 우선
- Entity 조회 = 실시간으로 Entity변경이 필요한 경우
- Dto 조회 = 고강도 성능 개선 or 대량의 데이터 조회가 필요한 경우
- 조회 컬럼 최소화하기 (as 컬럼은 select에서 제외)
- Select 컬럼에 Entity를 자제 (oneToOne은 LazyLoading이 안됨)
4. Group By 최적화
MySQL에서 쿼리가 인덱스를 타지 않았을 때, Group By를 실행하면 FileSort가 반드시 발생한다.
그런데 정렬이 필요없는 경우에도 대량의 데이터를 정렬한다면 성능 손실이 크다.
이를 해결하기 위해 MySQL에선 order by null을 사용하면 Filesort가 제거되는 기능을 지원
페이징일 경우엔 Order by null을 사용할 수 없음.
import com.querydsl.core.types.NullExpression;
import com.querydsl.core.types.Order;
import com.querydsl.core.types.OrderSpecifier;
public class OrderByNull extends OrderSpecifier {
public static final OrderByNull DEFAULT = new OrderByNull();
private OrderByNull() {
super(Order.ASC, NullExpression.DEFAULT, NullHandling.Default);
}
}
// 사용
...
.orderBy(OrderByNull.DEFAULT)
...5. 커버링 인덱스
쿼리를 충족시키는데 필요한 모든 컬럼을 갖고 있는 인덱스를 말함.
select / where / order by / group by 등에서 사용되는 모든 컬럼이 인덱스에 포함된 상태
NoOffset방식과 더불어 페이징 조회 성능을 향상시키고 가장 보편적인 방법
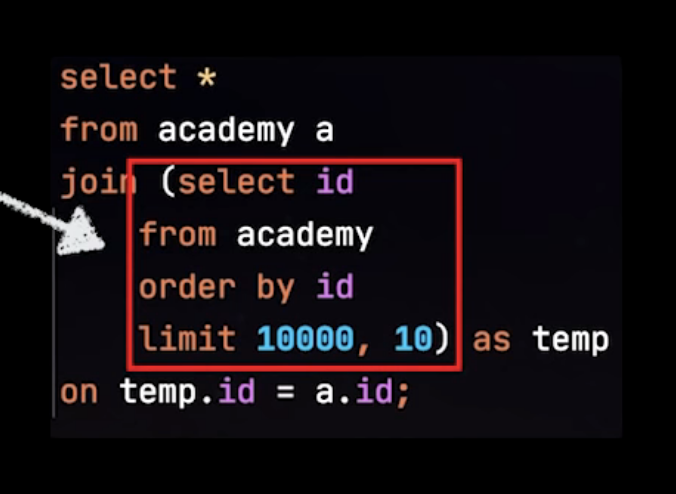
빨간 네모 박스 부분 커버링 인덱스를 사용한 쿼리
JPQL은 from절의 서브쿼리를 지원하지 않기 때문에, from 서브쿼리를 사용하는 경우 커버링 인덱스를 적용할 수 없음.
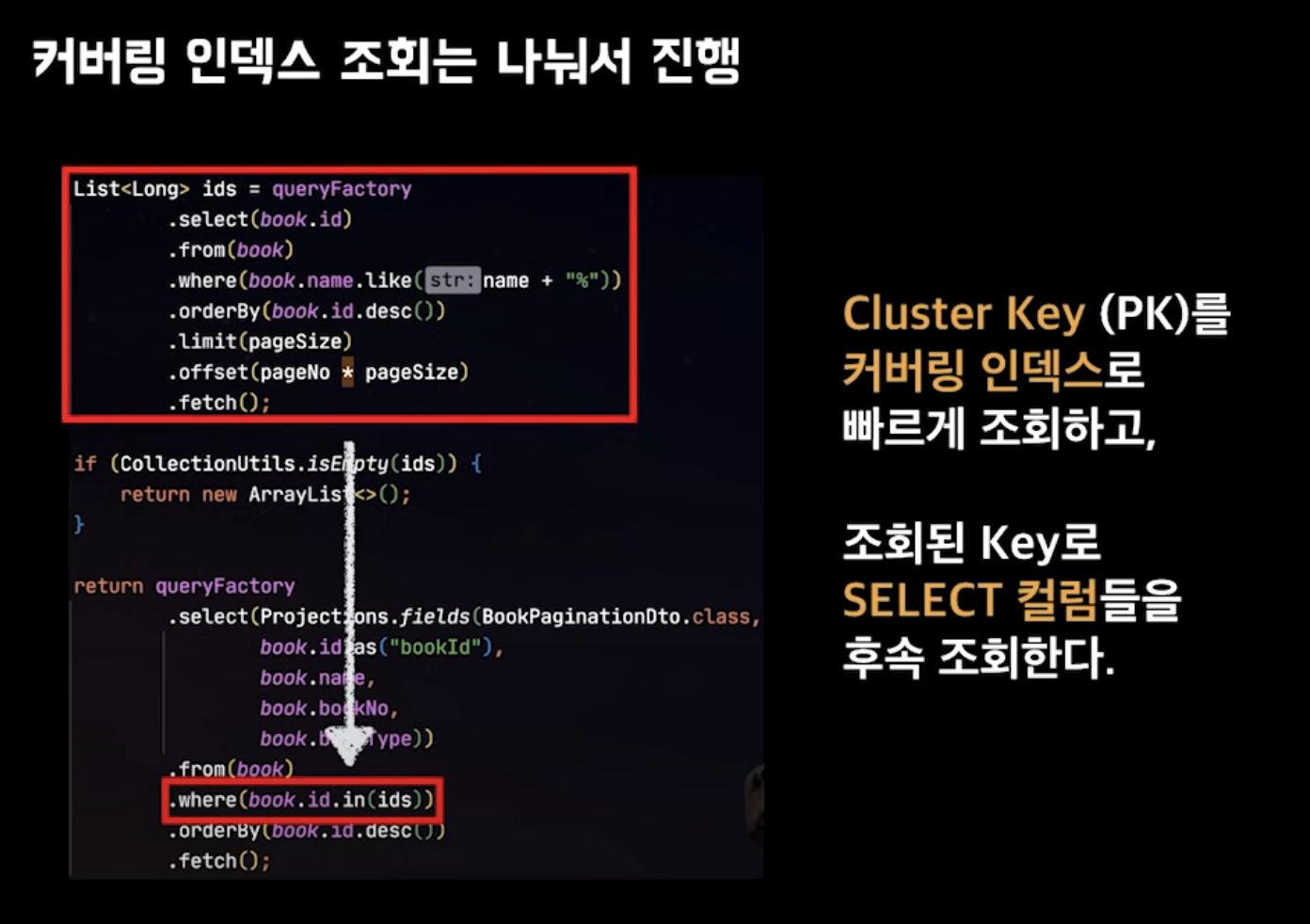
일괄 Update 최적화
- DirtyChecking은 실시간으로 비즈니스를 처리하거나, 소량의 데이터를 처리할 때 사용
- Querydsl update는 대량의 데이터를 일괄로 업데이트 처리할 때 사용
참고

Hi
으이ㅏ...감사합니다 .....!!😍