카프카
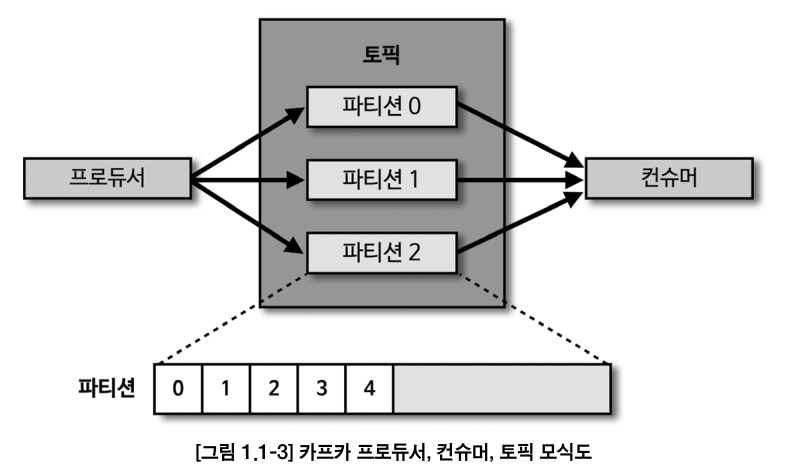
- 카프카 내부에 데이터가 저장되는 파티션의 동작은 FIFIO방식의 큐 자료와 유사함
- 큐에 데이터를 보내는 것이 프로듀서
- 큐에서 데이터를 가져가는 것이 컨슈머
- 데이터 포멧은 제한 없음 => 직렬화, 역직렬화를 통해 ByteArray로 통신하기 때문
- 카프카는 상용환경에서는 최소 3대 이상의 서버에서 부산 운영하여 프로듀서를 통해 전송받은 데이터를 파일 시스템에 안전하게 기록함.
- 서버 3대 이상으로 이루어진 카프카 클러스터 중 일부 서버에 장애가 발생하더라도 데이터를 지속적으로 복제하기 때문에 안전하게 운영이 가능
- 데이터를 묶음 단위로 처리하는 배치 전송을 통해 낮은 지연과 높은 데이터 처리량도 가지게 됨.
빅데이터 파이프라인에서 카프카의 역할
- 데이터 레이크 : 데이터가 모이는 저장 공간
- 높은 처리량
- 카프카는 프로듀서가 브로커로 데이터를 보낼 때와 컨슈머가 브로커로부터 데이터를 받을 때 모두 묶어서 전송
- 많은 양의 데이터를 묶음 단위로 처리하는 배치도 빠르게 처리할 수 있기 때문에 대용량의 실시간 로그데이터를 처리하는 데에 적합하다.
- 확장성
- 가변적인 환경에서 안정적으로 확장 가능하도록 설계되었음
- 스케일 아웃, 이케일 인
- 무중단 운영
- 영속성
- 데이터를 생성한 프로그램이 종료되더라도 사라지지 않은 데이터 특성을 뜻함
- 전송받은 데이터를 메모리가 아닌 파일 시스템에 저장
- I/O 성능 향상을 위해 페이지 캐시 영역을 메모리에 따로 생성하여 사용
- 페이지 캐시 메모리 영역을 사용하여 한번 읽은 파일 내용은 메모리에 저장시켰다가 다시 사용하는 방식이기에 철히량이 높다
- 고가용성
- 3개 이상의 서버들로 운영되는 카프카 클러스터는 일부 서버가 장애가 발생하더라도 무중단으로 안전하고 지속적으로 데이터를 처리할 수 있음
- 프로듀서로 부터 전송받은 데이터를 다른 서버에서 데이터를 복제함
왜 3대 이상의 브로커들로 구성해야하는가?
- 1대
- 테스트 목적으로 사용
- 2대
- 브로커 간에 데이터가 복제되는 시간차이로 인해 일부 데이터가 유실될 가능성이 있음.
- 3대
- 3개 중 1개의 브로커가 장애가 나더라도 지속적으로 데이터를 처리 가능
데이터 레이크 아키텍처와 카프카의 미래
데이터레이크 아키텍처는 람다아키텍처와 카파 아키텍처가 있다
- 람다 아키텍처
- 레거시 데이터 수집 플랫폼을 개선하기 위해 구성한 아키텍처
- 3가지 레이어로 나뉨
- 배치 레이어 : 배치 데이터를 모아서 특정 시간, 타이밍마다 일괄 처리
- 서빙 레이어 : 가공된 데이터를 데이터 사용자, 서비스 애플리케이션에서 사용할 수 있도록 데이터가 저장된 공간
- 스피드 레이어 : 서비스에서 생성되는 원천 데이터를 실시간으로 분석하는 용도로 사용
- 카파 아키텍처
- 람다 아키텍처의 단점을 해소하기 위함
- 람다 아키텍처와 유사하지만 배치 레이어를 제거하고 모든 데이터를 스피드 레이어에 넣어서 처리함.
- 로그는 배치 데이터를 스트림으로 표현하기 적합
- 배치 데이터를 로그로 표현헐 때는 각 시점의 배치 데이터의 변환기록을 시간 순서대로 기록함으로써 각 시점의 모든 스냅샷 데이터를 저장하지 않고도 배치 데이터를 표현할 수 있게 됨
배치데이터와 스트림 데이터
-
배치데이터
- 초, 분, 시간, 일 등으로 한정된 기간 단위 데이터
- 데이터를 일괄 처리하는 것이 특징
-
스트림 데이터
- 한정되지 않은 데이터로 시작 데이터와 끝 데이터가 명확히 정해지지 않은 데이터
- 사용자의 클릭 로그, 주식 정보, 사물인터넷의 센서 데이터를 스트림 데이터라 볼 수 있음
-
데이터 레이크
- 카파 아키텍처에서 서빙 레이어를 제거한 아키텍처

Hi