이번에 Convolutional Neural Network(CNN)의 발전 계기가 된 LeNet-5 아키텍쳐에 대한 논문인 Gradient-Based Learning Applied to Document Recognition에 대해서 읽어보았습니다. 이 논문에서 발표한 LeNet-5는 현재 CNN 구조의 직접적인 조상으로 여겨집니다.
논문의 분량 상 이번 포스팅에서는 1. Introduction부터 3. Results and Comparison with Other Methods까지 작성해보았습니다.
1. Introduction
이 논문의 패턴 인식 시스템에서 기존의 수작업 기반 휴리스틱 방식에서 벗어나, 자동 학습에 더 의존하는 방식으로 전환해야 한다고 주장합니다. 특히 경사 하강법 기반 학습(gradient-based learning)과 머신러닝 기술, 대용량 데이터셋의 가용성이 어떻게 더 뛰어난 패턴 인식 시스템을 구축할 수 있는지를 보여주고자 합니다.
기존의 패턴인식체계는 아래 사진과 같습니다.
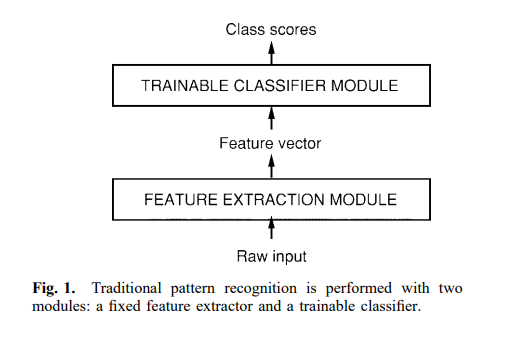
첫번째 모듈인 'Feature Extraction Module'에서는 입력 데이터를 저차원 벡터나 짧은 문자열로 변환합니다. 이것은 데이터를 쉽게 매칭 또는 비교할 수 있고, 입력 패턴의 본질을 바꾸지 않는 변형 및 왜곡에 관하여 상대적으로 불변합니다. 이는 수작업이 이용되어 많은 시간이 소요됩니다.
두번째 모듈인 'Trainable Classifier Module'은 'feature extractor'에 비해 보편적이고 학습 가능합니다.
여기서 문제점은 인식의 성능이 feature extractor를 설계하는 사람에 의해 좌우되고, 매번 다른 문제에 새로운 feature extractor를 설계해야 한다는 것입니다.
A. Learning from Data
먼저 그 당시 자주 이용되는 기법인 gradient-based learning(경사 기반 학습)에 대해 설명합니다.
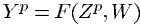
위 식에서 Zp는 p번째 입력 패턴이고 W는 adjustable(조정 가능)한 파라미터입니다. 함수의 출력 Yp는 패턴 Zp에 대해 예측한 class의 label이거나 각각의 class에 관련된 확률 또는 점수입니다.
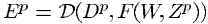
Ep는 loss function(손실함수)이고 Dp는 실제 label을 의미합니다. loss function은 Dp와 F(W,Zp)의 불일치(discrepancy)를 측정합니다.
그리고 Etrain를 {(Z1, D1),..., (Zp, Dp)}까지의 평균 오차인 avarage loss function를 의미합니다.
학습의 목표는 loss function을 가장 작게 만드는 W 파라미터를 찾는 것입니다.
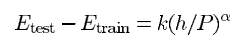
실제로 측정해야 하는 것은 error rate입니다. 그것은 위의 식과 같이 구할 수 있습니다. P는 학습 데이터의 크기이고 h는 machine의 complexity(복잡도) 혹은 effective capacity입니다. 그리고 k는 상수이고 는 0.5와 1.0 사이의 수 입니다. Etest는 test data에 대한 loss function 입니다.
이와 같이 두 측정값의 차이를 줄이면서 Etrain를 줄이는 것을 목표로 하고 그것을 structural risk minimization 이라고 합니다.
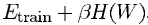
그래서 실제로는 위 식의 값을 줄이는 방식으로 진행됩니다. 는 상수이고 함수 H(W)는 regularization function입니다. H(W)는 매개변수 공간에서 고용량의 부분집합을 취하도록 선택됩니다. H(W)를 최소화 하는 것은 파라미터 공간에서 접근 가능한 subset을 줄어드는 단점이 있으므로 Etrain를 줄이는 것입니다.
B. Gradient-Based Learning
경사 기반 학습은 매끄럽고 연속적인 함수를 최소화하는 데 효과적인 방법입니다. 손실 함수의 기울기(gradient)를 계산하여 파라미터를 반복적으로 조정하는 원리입니다. loss function은 파라미터 값의 작은 변화의 영향을 측정하여 최소화 시킬 수 있고 이것에 gradient-based learning이 효과적으로 사용됩니다.
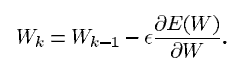
파라미터 값은 위 식을 토대로 수정됩니다. 은 스칼라 상수이고 E(W)는 연속적이고 미분 가능한 loss function입니다. W는 실수의 매개변수 집합입니다.
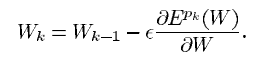
online update 라고도 불리는 stochastic gradient algorithm(확률적 경사법)은 위와 같습니다. stochastic gradient 알고리즘은 매개변수를 noisy하거나 approximated 된 average gradient를 사용하여 갱신합니다.
C. Gradient Back Propagation
경사 기반 학습 절차는 1950년대 후반 이후로 사용되었지만 대부분 선형 시스템에 한정되었습니다. 하지만 3가지 사건으로 인해 복잡한 머신러닝 과정에서도 유용하다고 밝혀지게 됩니다.
- loss function의 local minima 문제가 실제로는 큰 문제가 아니라는 것
- Rumelhart에 의해 back-propagation 알고리즘이 non-linear system에서 대중화된 것
- back-propagation 과정이 sigmoidal unit을 사용한 multi-layer neural network에 적용되면 복잡한 머신러닝 과업을 해결할 수 있다는 것
역전파의 기본 아이디어는 출력에서 입력 방향으로 기울기를 전파하여 계산하는 것입니다.
D. Learning in Real Handwriting Recognition System
필기체 인식의 어려운 문제 중 하나는 개별 문자를 인식하는 것뿐만 아니라, 단어나 문장 내에서 문자를 분리하는 '분할(segmentation)' 과정입니다. 그 당시 표준이라 불리는 segmentation 방식은 HOS(Heuristic OverSegmentation) 입니다.
HOS는 이미지 처리 기술을 사용하여 가능한 많은 문자 경계 후보를 생성한 뒤, 인식기가 각 후보 문자에 부여하는 점수를 기반으로 최적의 조합을 선택하는 방식입니다. 하지만 이는 labeling된 database를 생성하는 것이 어렵기 때문에 한계가 있습니다.
E. Globally Trainable System
부분 패턴 인식 시스템은 multiple modules로 구성되어 있습니다. 예를 들면 field locator, field segmenter, recognizer, contextual postprocessor와 같이. 모듈간 데이터 전송을 나타내는 것은 그래프로 나타내는 것이 잘 나타냅니다. 전체를 보고 파라미터를 조정하는 것은 많은 시간 소비 등의 단점이 있고 이 대안으로 global error를 측정하고 최소화 하는 방법으로 조정하는 것이 효과적입니다. 그리고 그 loss function E는 gradient-based learning을 사용하여 찾을 수 있습니다. 하지만 시스템이 복잡해 진다면 gradient-based learning을 적용시키기 어려워 보입니다.
먼저 loss function (,W)가 미분가능하기 위해선 전체 시스템이 미분 가능한 모듈의 feedforward network 이여야 합니다. 즉, 각각의 모듈의 함수들은 연속적이고 미분가능해야 합니다. 그리고 이 때 back propagation의 일반화가 시스템의 모든 파라미터들의 loss function의 기울기를 계산하는 곳에 쓰이는 것으로 잘 알려져 있습니다.
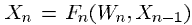
위와 같은 함수로 구성된 각 모듈들로 구성된 시스템을 고려해 봅시다.
은 벡터로 표현된 output이고 은 그 모듈에서 벡터로 표현된 tunable parameters(W의 부분집합), Xn-1은 모듈에 input 벡터 (즉, 이전 모듈의 output 벡터), 는 input pattern 과 같고 첫번째 input 입니다.
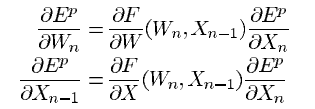
loss function 에 대한 과 Xn-1의 편미분은 각각 위의 식들과 같습니다. 첫 번째 수식은 의 일부 항의 gradient를 계산합니다. 두 번째 수식은 back-propagation 과정입니다. 위 식에서 Jacobian 곱을 partial derivatives에 이용하는데 그것 없이 직접적인 곱으로 계산하는게 대체로 쉽습니다.
2. Convolutional Neural Networks for Isolated Character Recognition
전통적인 패턴 인식 모델에는 hand-designed feature extractor가 정보를 모으고 관계없는 변수는 삭제하고 trainable classifier가 결과로 나온 특징 백터들을 클래스들로 카테고리화 합니다. 이와 같은 과정은 완전 연결 순전파 네트워크에는 잘 수행되는 반면 아래와 같은 문제들이 있었습니다.
-
보통 이미지의 크기는 커서 시스템의 capacity를 증가시키고 더 많은 training set을 필요로 합니다. 또한 메모리도 크게 잡아먹습니다. 그러나 이미지 또는 음성 응용을 위한 비정형 네트워크의 주요 결함은 번역이나 입력의 국부적 왜곡에 대한 내장된 불변성이 없다는 점입니다.
-
input의 topology가 무시될 수 있습니다.
이러한 문제들을 CNN(Convolutional Neural Networks)가 해결 가능합니다.
A. Convolutional Networks
Convolutional networks(합성곱 신경)은 세가지 아키텍쳐 아이디어를 조합합니다. 이 세가지 아이디어는 shift, scale, distortion invariance를 견디기 위해 조합합니다.
그 아이디어들은 아래와 같습니다.
1) local receptive field
2) shared weights (or weight replication)
3) spatial or temporal subsampling
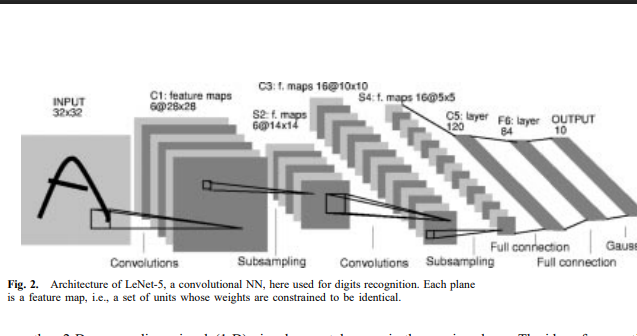
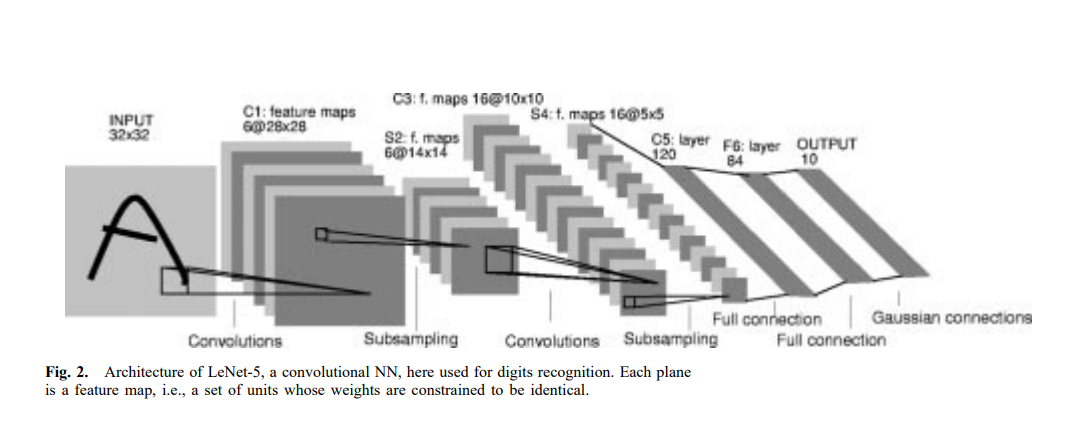
위 사진은 문자 인식을 위한 convolutional networks인 LeNet-5이다.
input으로 문자의 이미지를 받고 이 각각의 레이어의 유닛들은 이전 레이어의 근처에 위치한 유닛들의 집합에서 input을 받습니다.
local receptive fields neurons은 엣지, endpoints, 코너와 같은 기초적인 시각적 특징들을 추출 가능합니다. 이 특징들은 subsequent layers로 조합이 되고 그것은 고차원의 특징에 접촉하기 위해 사용됩니다. 상태가 초기일수록 input의 distrotions 또는 shift는 salient features의 position을 다르게 하는데 원인이 될 수 있습니다. 게다가 하나의 이미지 부분에 유용한 초기 특징 detectors은 전체 이미지에 유용할 가능성이 있습니다.
레이어의 유닛들은 각각의 모든 유닛이 공유하는 같은 weights 집합을 공유하는 planes으로 구성되어 있습니다. 이러한 plane의 유닛들의 outputs 집합은 feature map이라고 부릅니다.
feature map의 모든 units은 이미지의 다른 부분의 같은 operation으로 구성되었습니다. complete convolutional layer은 몇몇의 feature map으로 구성되었고 그래서 multiple 특징은 각각의 location에서 뽑아낼 수 있습니다.
이것의 예시가 LeNet-5의 첫번째 layer입니다. 사진을 보시면 첫번째 hidden layer는 6개의 plane으로 구성되었고 이것이 각각 feature map 입니다. feature map은 5x5의 25개 input들이 연결되었고 이것을 receptive field of the unit이라 부릅니다. feature map에서 연속 단위의 수신 필드는 이전 레이어의 해당 연속 단위에 중심을 둡니다. 즉, 인접 유닛의 수신 필드 중첩됩니다. 다른 feature map의 layer은 다른 weights와 biases를 사용하고 다른 타입의 local features를 뽑아낼 수 있습니다. LeNet-5의 예시에서 6개 feature map은 각각 다른 6개의 타입을 가집니다.
feature map의 연속적인 구성요소들은 입력 이미지를 하나의 유닛으로 스캔이 가능하고 feature map에서 서로 대응하는 위치의 이 유닛의 상태들을 수집합니다. 이 작업에서 additive bias와 squashing function만 추가하면 convolution과 동등해서 이것을 convolutional network라 이름이 붙었습니다.
convolutional layer의 흥미로운 특징은 만약 입력 이미지가 shift되면 결과 output featuremap 또한 같은 양만큼 shift 될것이고 그 외에는 변하지 않습니다.
특징이 감지되면 정확한 위치는 덜 중요해지고 그것의 관계있는 다른 특징의 대략적인 위치가 관련있습니다. 각 특징의 정확한 위치는 패턴을 식별하는 데 중요하지 않을 뿐만 아니라, 문자의 경우에 따라 위치가 다를 가능성이 있기 때문에 잠재적으로 해로울 수 있습니다.
이렇게 정확도를 줄이는 방법으로 feature map의 부분적인 해상도를 줄이는 방법이 있습니다. 이를 담당하는 layer를 subsampling layer라고 하고 LeNet-5의 2번째 hidden layer입니다.
이 layer는 이전 layer의 각 피처 맵마다 하나씩 총 6개의 feature map으로 구성됩니다. 그리고 수용 필드는 이전 layer의 대응하는 feature map의 2x2영역을 각각의 유닛으로 가집니다. 이런 unit은 2x2의 평균을 계산하고 해당 unit의 trainable coefficient와 곱한 다음 trainable bias와 더합니다. 그리고 sigmoid function을 적용시킵니다. 이전 convolutional layer와는 다르게 인접한 unit들 간의 overlapping은 하지 않습니다. 따라서 행의 수와 열의 수가 이전 layer에 비해 반으로 줄어들게 됩니다.
모든 weight들은 back-propagation을 통해 학습되기 때문에 convolutional network는 앞서 언급한 pattern recognition system의 feature extractor가 아예 합쳐진 것 처럼 보입니다. 그리고 weight sharing technique이 machine의 capacity를 줄여 앞에서 언급한 test error와 train error 사이의 격차를 줄일 수 있을 것이라고 생각됩니다.
B. LeNet-5
LeNet-5은 input을 제외하고 7개의 Layer로 이루어져 있습니다. input은 32x32 픽셀의 이미지이고 이것은 데이터베이스의 가장 큰 문자의 크기보다 큽니다. 그 이유는 stroke end-point나 corner와 같은 뚜렷한 feature들은 첫 번째 convolutional layer의 중간 receptive field에서 나타나기 때문입니다. 배경(흰색)은 -0.1로 글자(검은색)는 1.175로 nomalize 시킴으로써 평균 입력을 대략 0으로 만들고 분산을 대략 1로 만들어 학습을 가속화합니다.
먼저 다음과 같이 정의하였습니다. Cx는 convolutional layer, Sx는 subsampling layer, Fx는 fully connected layer를 나타냅니다. 여기서 x는 layer index입니다.
LeNet-5의 C1은 6개의 feature map들을 가지고 있습니다. 각 feature map의 unit은 input의 5x5의 근처요소와 연결됩니다. C1은 156개의 trainable한 파라미터와 122304개의 연결이 있습니다.
S2 layer는 subsampling layer이고 6개의 14x14크기의 feature map들을 가지고 있습니다. 각각의 feature map은 C1의 feature map에 대응 되는 2x2들과 연결됩니다. S2는 12개의 trainable한 파라미터들과 5880개의 연결이 있습니다.

C3 layer는 16개의 feature map들이 있고 각각의 feature map의 unit들은 S2 feature map의 부분적인 주위 5x5와 각각 연결됩니다. 위 사진은 table은 S2와 C3의 연결을 보여줍니다. S2의 모든 feature map이 C3의 모든 feature map과 연결되지 않은 이유는 두 가지가 있습니다.
첫 번째로 불완전한 연결 체계는 연결의 수를 합리적인 범위 내에서 유지합니다.
두 번째는 network의 대칭을 파괴합니다. 다른 feature map은 다른 feature를 추출합니다.
C3 layer는 1516개의 trainabel한 파라미터들과 156000개의 연결이 있습니다.
S4는 16개의 5x5크기의 feature maps들이 있고 2x2들과 연결됩니다. 파라미터는 32개가 있고 2000개의 연결이 있습니다.
C5는 1x1 크기의 120개의 feature map들이 있고 각각의 unit은 5x5와 연결되어 있습니다. C5는 48120개의 trainable한 연결이 있습니다.
마지막 F6은 84개의 유닛들과 C5와 fully connect 되어 있습니다. 10164개의 trainable한 파라미터들이 있습니다.
클래식한 NN에서는 F6의 레이어들을 dot prouct를 그들의 input 벡터와 weight 벡터로 하고 bias를 더하게 됩니다. unit 에 대하여 가중된 합을 라 하고 이것을 시그모이드 함수에 넣어서 만들어진 값을 라 하면 아래로 표현할 수 있습니다.
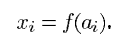
그리고 활성화 함수(squashing function)은 아래와 같이 hyperbolic tangent로 표현됩니다.
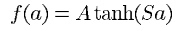
여기서 는 함수의 amplitude이고 는 원점에서의 기울기를 의미합니다.
마지막의 output layer는 Euclidean Radial Basis Function(RBF)으로 구성되어 있습니다. 아래 식을 이용해 각각의 RBF의 출력()을 구할 수 있게 됩니다.
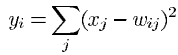
RBF의 unit들은 input 벡터와 parameter 벡터의 유클리드 거리를 계산하고 output으로 나오게 됩니다.
RBF는 입력 패턴과 정답 패턴 간의 차이를 측정하는 벌점 항(penalty term)으로 해석될 수 있습니다. 확률론적으로는 가우시안 분포의 unnormalized negative log-likelihood로 해석될 수 있습니다. RBF는 F6 layer에서 target vector 역할을 합니다. F6 layer의 weight들은 +1 아니면 -1인데 이는 sigmoid의 최대 곡률과 일치합니다. 그렇기 때문에 loss function의 느린 수렴을 야기하는 시그모이드 포화를 방지합니다.
C. Loss Function
LeNet-5에 사용하기 좋은 loss function은 MSE(Minimum Mean Squared Error)에 해당하는 Maximum Likelihood Estimation(MLE)입니다. 식은 아래와 같습니다.
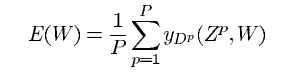
위 식에서 yDp는 RBF의 번째 요소입니다. 즉, 올바른 클래스의 입력 패턴 Z^p에 해당하는 것입니다. 이 식이 대부분이 옳지만 아래와 같은 세가지의 결점이 있습니다.
1) RBF의 매개변수들을 학습시키면 E(W)가 매우 작아지나, RBF의 모든 매개변수 벡터는 동일하기 때문에 결국 network의 입력은 무시한 채 모든 RBF의 출력이 0이 되게 됩니다.
2) 클래스들 사이에 경쟁이 없다는 것입니다. 이러한 경쟁은 HMM(은닉 마르코프 모델)을 훈련시키는 데 때때로 사용되는 최대 상호 정보량 기준과 유사한, 최대 사후 확률(maximum a posteriori, MAP) 기준이라고 불리는 더 판별적인 훈련 기준을 사용하여 얻을 수 있습니다. 이는 입력 이미지가 여러 클래스 중 하나 또는 배경 "쓰레기(rubbish)" 클래스 레이블로부터 올 수 있다는 조건 하에서, 정답 클래스 의 사후 확률을 최대화(또는 정답 클래스 확률의 로그 값을 최소화)하는 것에 해당합니다. 페널티의 관점에서 볼 때, 이 기준은 평균 제곱 오차(MSE) 기준처럼 정답 클래스의 페널티를 밀어 내리는 것 외에도, 오답 클래스들의 페널티를 끌어올린다는 것을 의미합니다.

위의 식이 MAP기준을 구체화한 손실함수 입니다.
두 번째 항의 음수 값은 "경쟁적인" 역할을 합니다. 이 값은 필연적으로 첫 번째 항보다 작거나 같으므로, 이 손실 함수는 양수입니다. 상수 j는 양수이며, 이미 페널티가 매우 큰 클래스들의 페널티가 더 이상 올라가는 것을 방지합니다.
3. Results and Comparison with Other Methods
각각의 문자를 인식하는 것은 실용적 인식 시스템을 구축하는 것을 포함한 많은 문제들 중 하나이지만 shape recognition methods를 비교하는데 좋은 benchmark 입니다.
A. Database : The Modified NIST Set
훈련과 테스트에 쓴 데이터베이스틑 NIST의 Special Database 3와 Special Database 1 입니다. 이것들은 손글씨의 binary image를 포함하고 있습니다. 원래 NIST는 SD-3를 train set으로 SD-1을 test set으로 사용하였습니다. 하지만 SD-3이 SD-1에 비해서 인식하기에 cleaner, easier 합니다. 학습 실험에서 합리적인 결론을 도출하려면 전체 샘플 세트 중에서 훈련 세트와 테스트 선택에 관계없이 결과가 독립적이어야 합니다. 따라서 NIST's datasets을 mixing한 새로운 database가 필요합니다.
먼저 본래의 dataset의 SD-1을 작성자 별로 재정렬 한 후 250명 작성자로 두개로 나누어 처음 하나는 train set으로, 남은 하나는 test set으로, 즉 약 30000개의 데이터로 나누었습니다. SD-3 또한 각각 데이터를 나누어서 train set과 test set을 60000개로 보충하여 사용하였습니다. 이 중 train set으로는 60000개를 전부 사용하였지만 test set은 각각 5000개씩, 총 10000개의 데이터를 사용하였습니다.
결과로 나온 이 데이터셋을 modified NIST, 즉 MNIST dataset이라 부릅니다.

원본 흑백 이미지는 가로세로 비율을 유지하면서 20x20 픽셀 상자에 맞도록 크기가 정규화되었습니다. 데이터베이스는 세 가지 버전이 사용되었습니다.
1) 이미지들은 픽셀의 무게 중심을 계산하고 이 점이 28x28 영역의 중앙에 위치하도록 이미지를 평행 이동시켜 28x28 이미지의 중앙에 배치되었습니다. 어떤 경우에는 이 28x28 영역이 배경 픽셀을 추가하여 32x32로 확장되었습니다. 이 버전의 데이터베이스는 일반(regular) 데이터베이스라고 부를 것입니다.
2) 문자 이미지가 기울기 보정된 후 20x20 픽셀 이미지로 잘렸습니다. 기울기 보정은 픽셀의 2차 관성 모멘트를 계산하고(전경 픽셀은 1, 배경 픽셀은 0으로 계산), 주축이 수직이 되도록 각 라인을 수평으로 이동시켜 이미지를 층밀림 변환합니다. 이 버전의 데이터베이스는 기울기 보정(deslanted) 데이터베이스라고 부를 것입니다.
3) 세 번째 버전의 데이터베이스는 일부 초기 실험에 사용되었으며, 이미지가 16x16 픽셀로 축소되었습니다. 그림 4는 테스트 세트에서 무작위로 뽑은 예시들을 보여줍니다.
B. Results
LeNet-5의 여러 버전이 MNIST 데이터베이스로 훈련되었습니다. 각 세션마다 전체 훈련 데이터에 대해 20회의 반복이 수행되었습니다. 전역 학습률(global learning rate) η의 값은 다음 스케줄에 따라 감소되었습니다.
-
처음 두 번의 패스(pass) 동안은 0.0005
-
다음 세 번 동안은 0.0002
-
그 다음 세 번 동안은 0.0001
-
그 다음 네 번 동안은 0.00005
-
그리고 그 이후에는 0.00001
각 반복 전에, diagonal Hessian 근사는 500개의 샘플에 대해 재평가되었고, 전체 반복 동안 고정되었습니다. 파라미터 μ는 0.02로 설정되었습니다. 첫 번째 패스 동안 결과적인 유효 학습률(effective learning rate)은 파라미터 집합에 걸쳐 대략 7×10⁻⁵에서 0.016 사이에서 변동했습니다.
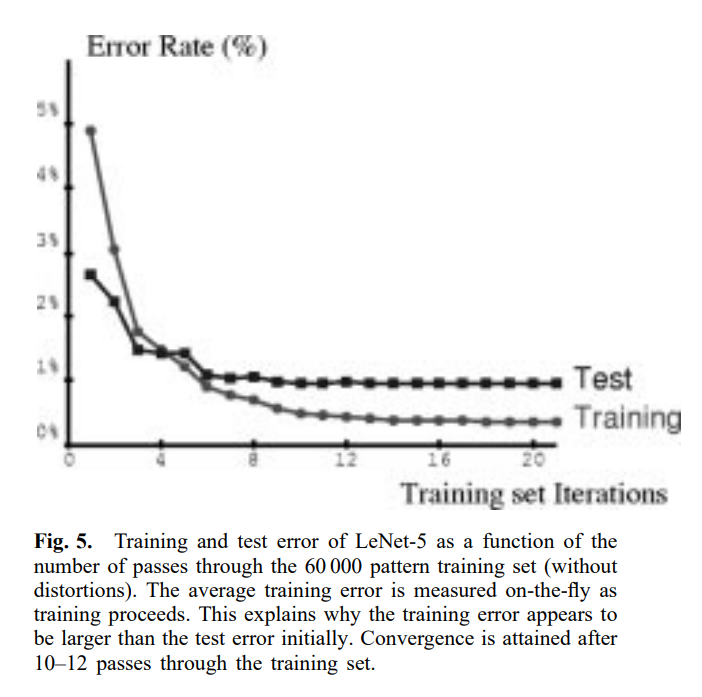
test error rate는 test set에 대한 약 10번의 패스 이후 0.95%에서 안정화됩니다. train set에 대한 error rate은 19번의 패스 이후 0.35%에 도달합니다. 많은 저자들은 다양한 과제에 대해 NN이나 다른 적응형 알고리즘을 훈련할 때 overfitting(과적합)이라는 현상을 관찰했다고 보고했습니다. 과적합이 발생하면, 훈련 오차는 시간이 지남에 따라 계속 감소하지만 테스트 오차는 최솟값을 찍고 일정 횟수의 반복 이후 다시 증가하기 시작합니다.
위 그림의 학습 곡선에서 볼 수 있듯이 LeNet-5의 경우에는 관찰되지 않았습니다. 가능한 이유는 학습률이 상대적으로 크게 유지되었기 때문입니다. 이것의 효과는 가중치가 local minimum에 안주하지 않고 무작위로 계속 진동한다는 것입니다. 그러한 변동 때문에, cost는 더 넓은 최솟값에서 더 낮아질 것입니다. 따라서, 확률적 경사 하강법(stochastic gradient)은 더 넓은 최솟값을 선호하는 regularization 항과 유사한 효과를 가질 것입니다. 더 넓은 최솟값은 파라미터 분포의 엔트로피가 큰 해에 해당하며, 이는 일반화 오차에 이롭습니다.
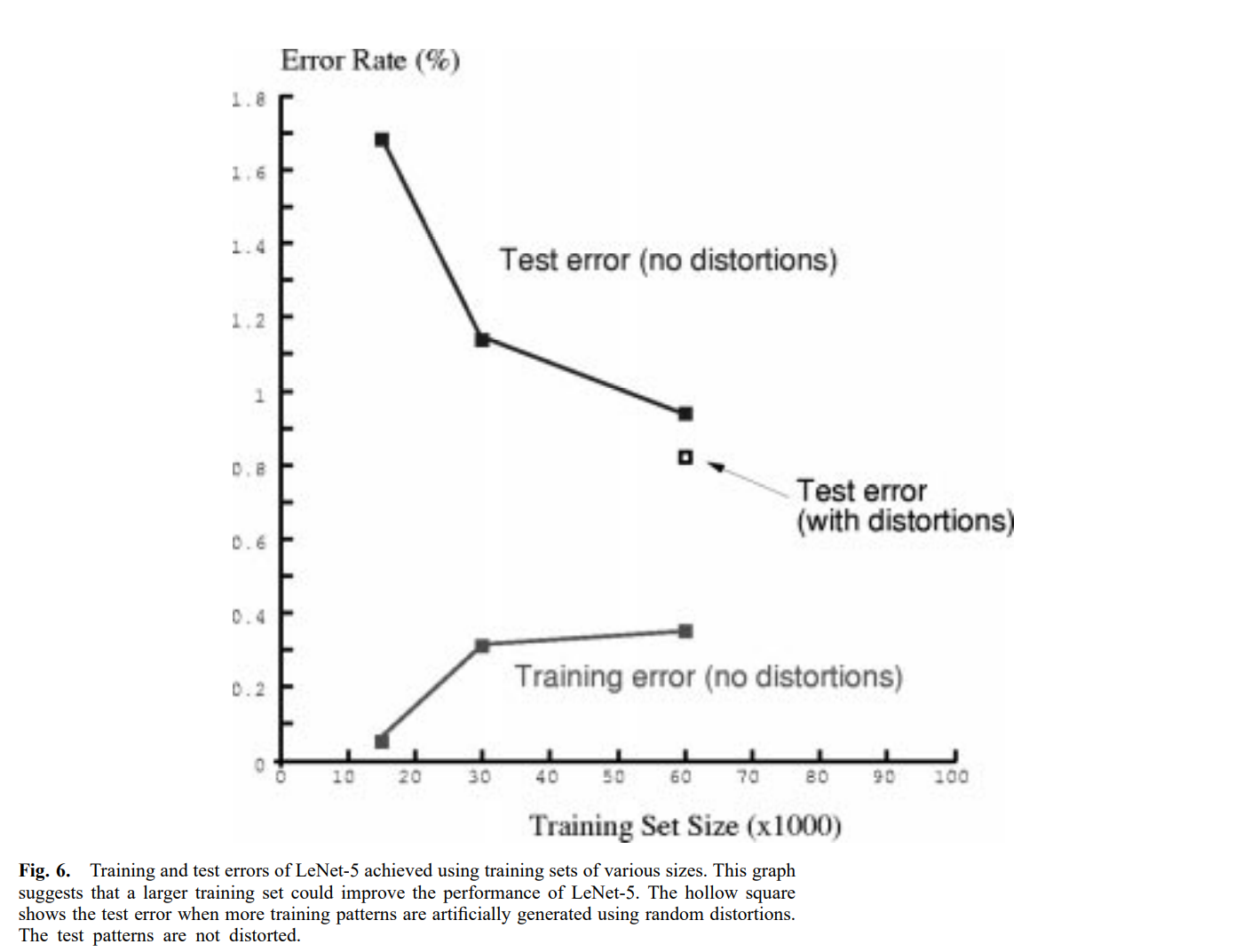
training set size의 영향은 15000, 30000, 60000개의 예제로 network를 train할때 측정되었습니다. training error와 test error는 위 그래프에서 볼 수 있습니다. LeNet-5 같은 전문화된 아키텍처에서는 더 많은 training data가 정확도를 향상시켜준다는 것이 명확합니다.

이 가설을 입증하기 위해서는 더 많은 training examples들을 원본 tringing images를 랜덤하게 분류하여 인공적으로 생성하여야 합니다. training set을 원래 60000개에서 540000개의 패턴을 더 추가하였습니다.
distortion은 다음과 같은 planar affine transformations들의 조합이었습니다:
- 수평 및 수직 이동
- scaling
- 찌그러뜨리기(수평 압축과 수직 신장의 동시 발생, 또는 그 반대)
- horizontal shearing
위 그림은 훈련에 사용된 distort 된 패턴의 예시를 보여줍니다.
distort 된 데이터를 훈련에 사용했을 때, test error rate는 0.8%로 떨어졌습니다 (변형이 없었을 때는 0.95%). deformation을 사용하지 않았을 때와 동일한 훈련 파라미터가 사용되었습니다. 전체 훈련 세션의 길이는 변경되지 않았습니다 (각각 60,000개 패턴으로 구성된 20번의 패스). 이 20번의 패스 과정 동안 네트워크가 각 개별 샘플을 실질적으로 단 두 번만 본다는 점은 흥미롭습니다.

위 그림은 잘못 분류된 테스트 예시 82개 전부를 보여줍니다. 이 예시들 중 일부는 정말로 모호하지만, 몇몇은 잘 나타나지 않는 스타일로 쓰였음에도 불구하고 사람에게는 완벽하게 식별 가능합니다. 이는 더 많은 훈련 데이터가 있다면 추가적인 개선이 기대된다는 것을 보여줍니다.
C. Comparison with Other Classifiers
비교를 위해 같은 database를 이용하였습니다.
다양한 방법의 test set의 error rate는 아래 그래프에 보여집니다.
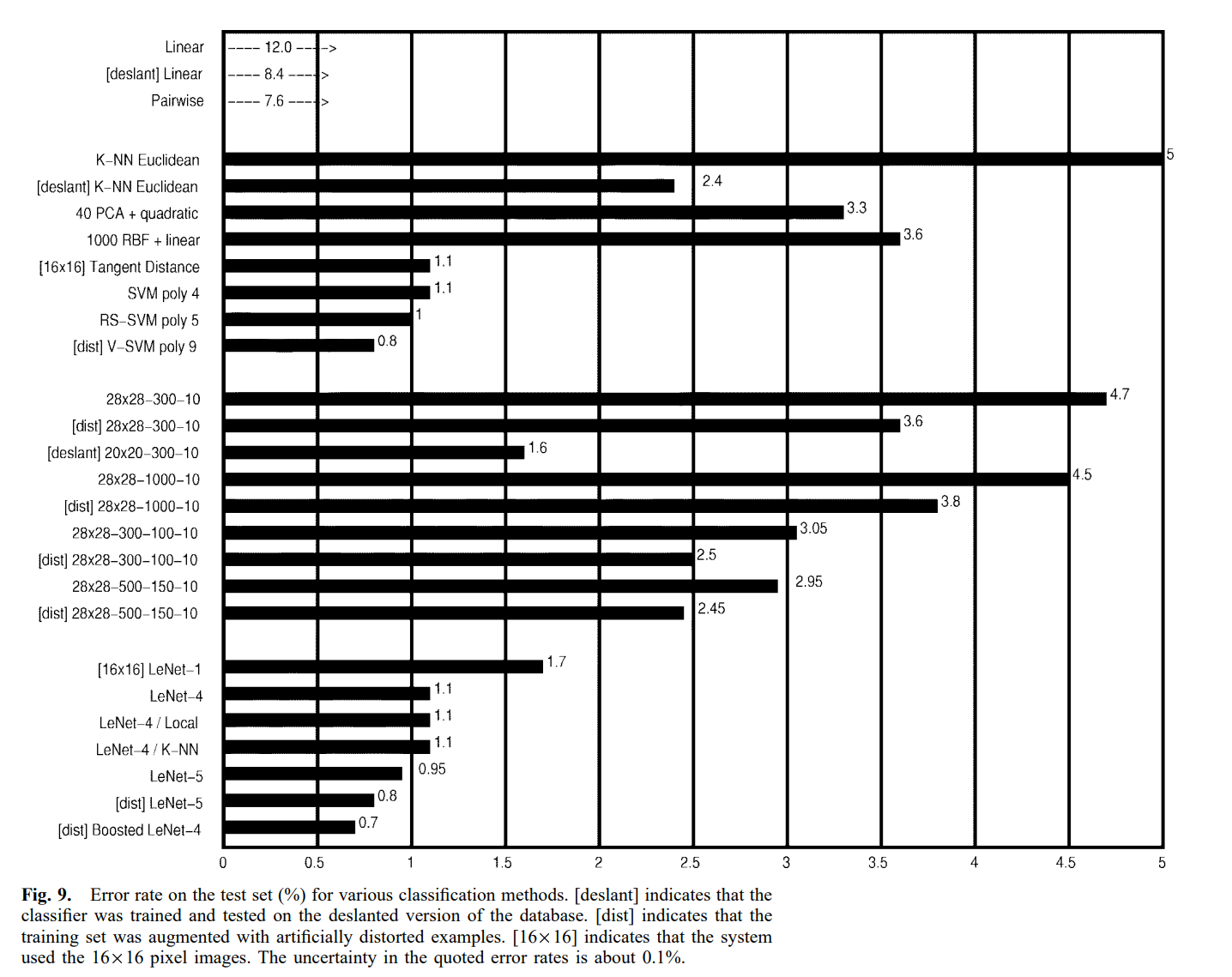
1. Linear Classifier and Pairwise Linear Classifier
각 입력 픽셀 값은 각 출력 유닛에 대한 weighted sum에 기여합니다. 가장 높은 합계(편향 상수의 기여 포함)를 가진 출력 유닛이 입력 문자의 클래스를 나타냅니다. regular data에서 error rate는 12%이며, 이때 네트워크는 7850개의 free parameters를 가집니다. deslanted 이미지에서 test error rate는 8.4%이고, 네트워크는 4010개의 자유 파라미터를 가집니다.
2. Baseline Nearest Neighbor Classifier
이 방법의 classifier는 input images 사이의 유클리드 거리를 측정함으로써 사용하는 K-NN classifier입니다. 이 classifier는 training time이 필요 없고 디자이너의 생각이 필요하지 않다는 장점이 있습니다. 하지만 많은 메모리가 필요하고 인식 시간이 큽니다(완전한 60000개의 20x20 픽셀 트레이닝 이미지가 run time에 이용가능해야 합니다).
k=3일 때, regular data에서는 error rate가 5.0%이고 deslanted data에서는 error rate가 2.4% 입니다. realistic Euclidean distance nearest-neighbor system은 직접적으로 픽셀보다는 feature 벡터로 나타나지만 이 연구의 다른 모든 시스템은 픽셀로 나타나기 때문에 이 결과는 baseline comparison에 유용합니다.
3. PCA and Polynomial Classifier
훈련 벡터 집합의 40개 주성분에 대한 입력 패턴의 projection을 계산하는 전처리 단계를 구성했습니다. 주성분을 계산하기 위해, 먼저 각 입력 성분의 평균을 계산하여 훈련 벡터에서 뺐습니다. 그 결과 나온 벡터들의 공분산 행렬을 계산한 다음 특이값 분해를 사용하여 대각화했습니다. 이 40차원의 특징 벡터는 2차 다항식 분류기의 입력으로 사용되었습니다. 이 분류기는 입력 변수 쌍들의 모든 곱을 계산하는 모듈 뒤에 821개의 입력을 가진 선형 분류기가 오는 것으로 볼 수 있습니다. regular test set error rate는 3.3%였습니다.
4. RBF Network
첫 번째 계층은 28x28 입력을 받는 1000개의 가우시안 RBF 유닛으로 구성되었고, 두 번째 계층은 1000개의 입력을 받아 10개의 출력을 내는 간단한 linear classifier 였습니다. RBF 유닛들은 100개씩 10개의 그룹으로 나뉘었습니다. 각 유닛 그룹은 적응형 K-평균 알고리즘(adaptive K-means algorithm)을 사용하여 10개 클래스 중 하나의 모든 훈련 예시에 대해 훈련되었습니다. 두 번째 계층의 가중치는 정규화된 유사역행렬 방법을 사용하여 계산되었습니다. 일반 테스트 세트에서의 오차율은 3.6%였습니다.
5. One-Hidden-Layer Fully Connected Multilayer NN
regular test set에서의 오차율은 은닉 유닛 300개를 가진 네트워크에서 4.7%, 은닉 유닛 1000개를 가진 네트워크에서 4.5%였습니다. 인공적인 왜곡을 사용하여 더 많은 훈련 데이터를 생성하는 것은 약간의 개선만을 가져왔습니다. 은닉 유닛 300개에서 3.6%, 은닉 유닛 1000개에서 3.8%였습니다. deslanted images를 사용했을 때, 은닉 유닛 300개를 가진 네트워크의 테스트 오차율은 1.6%로 내려갔습니다.
저자는 다층 신경망에서 경사 하강법 학습의 동역학이 "자기-정규화(self-regularization)" 효과를 가진다고 추측합니다. 가중치 공간의 원점은 거의 모든 방향에서 매력적인 안장점(saddle point)이기 때문에, 처음 몇 에포크 동안 가중치는 언제나 줄어듭니다. 작은 가중치는 시그모이드 함수가 거의 선형적인 영역에서 작동하게 만들어, 네트워크를 본질적으로 용량이 작은 단일 계층 네트워크와 동일하게 만듭니다. 학습이 진행됨에 따라 가중치는 커지고, 이는 점진적으로 네트워크의 effective capacity를 증가시킵니다.
6. Two-Hidden-Layer Fully Connected Multilayer NN
28x28-300-100-10 네트워크의 테스트 오차율은 3.05%로, 단일 은닉층 네트워크보다 훨씬 좋은 결과였습니다. 가중치와 연결을 약간만 더 사용했음에도 불구하고 말입니다. 네트워크 크기를 28x28-1000-150-10으로 늘리자 오차율이 2.95%로 약간 개선되었습니다. distorted patterns로 성능을 향상시키자 28x28-300-100-10 네트워크는 2.50%, 28x28-1000-150-10 네트워크는 2.45%의 오차율을 보였습니다.
7. A Small Convolutional Network--LeNet-1
CNN은 학습할 수 없는 작은 네트워크와 과적합된 것으로 보이는 큰 네트워크 사이의 딜레마를 해결하려는 시도입니다. LeNet-1은 CNN 아키텍처의 초기 구현으로, 여기서는 비교 목적으로 포함되었습니다. 이미지는 28x28 입력 계층에서 16x16 픽셀로 다운샘플링되고 중앙에 배치되었습니다. LeNet-1을 평가하는 데 약 100,000개의 곱셈/덧셈 단계가 필요하지만, 컨볼루션 특성 덕분에 자유 파라미터의 수는 약 2,600개로 유지됩니다. LeNet-1은 USPS(미국 우편 서비스) 데이터베이스의 자체 버전을 사용하여 개발되었으며, 그 크기는 가용한 데이터에 맞춰 조정되었습니다. 이렇게 적은 수의 파라미터를 가진 네트워크가 이처럼 좋은 오차율을 달성할 수 있다는 사실은 이 아키텍처가 해당 작업에 적합하다는 것을 나타냅니다. 테스트 오차율은 1.7%였습니다.
8. LeNet-4
LeNet-4는 아키텍처의 세부 사항에서 LeNet-5와 매우 유사합니다. 이는 2개의 첫 번째 특징 맵, 이어서 각 첫 번째 계층 특징 맵에 연결된 쌍으로 구성된 8개의 서브샘플링 맵, 그 다음 16개의 특징 맵, 이어서 120개의 유닛으로 구성된 완전 연결 계층, 마지막으로 출력 계층(10개 유닛)으로 구성됩니다. LeNet-4는 약 260,000개의 연결과 약 17,000개의 자유 파라미터를 포함합니다. 테스트 오차율은 1.1%였습니다.
9. Boosted LeNet-4
여러 신경망을 결합하는 부스팅(boosting) 방법을 개발했습니다. 3개의 LeNet-4가 결합되는데, 첫 번째 신경망은 일반적인 방식으로 훈련됩니다. 두 번째 신경망은 첫 번째 신경망이 통과시킨 패턴들과 첫 번째 신경망이 틀렸거나 맞혔던 패턴들의 50%로 구성된 혼합 데이터로 훈련됩니다. 세 번째 신경망은 첫 번째와 두 번째 신경망이 동의하지 않는 새로운 패턴들로 훈련됩니다. 테스트 시에는 세 신경망의 출력이 단순히 더해집니다.
LeNet-4의 오차율은 매우 낮기 때문에, 두 번째와 세 번째 신경망을 훈련시킬 충분한 샘플을 얻기 위해 인공적으로 왜곡된 이미지를 사용해야 했습니다. 테스트 오차율은 0.7%로, 다른 어떤 분류기보다도 좋은 결과였습니다. 언뜻 보기에는 단일 신경망보다 3배 더 비용이 많이 들 것 같지만, 실제로는 그렇지 않습니다. 첫 번째 신경망이 높은 신뢰도의 답을 내놓지 않을 경우에만 다른 신경망들이 호출됩니다. 평균적인 계산 비용은 단일 신경망의 약 1.75배입니다.
10. Tangent Distance Classifier
탄젠트 거리(Tangent Distance)는 거리 함수가 입력 이미지의 작은 왜곡과 이동에 둔감하게 만들어진 최근접 이웃 방법입니다. 이미지를 고차원 픽셀 공간의 한 점으로 생각할 때, 문자 특성의 왜곡은 픽셀 공간에서 곡선으로 나타납니다. 이 모든 왜곡들을 함께 고려하면 원본 이미지의 픽셀 공간 내에 저차원 매니폴드(manifold)를 정의합니다. 이 manifold는 접평면(tangent plane)으로 근사될 수 있습니다. 문자 이미지에 대한 "근접성"의 훌륭한 척도는 그들의 접평면 간의 거리이며, 여기서 평면을 생성하는 데 사용되는 왜곡 집합에는 평행 이동, 크기 변환, 찌그러뜨리기, 회전 및 선 굵기 변형이 포함됩니다. 16x16 픽셀 버전을 사용했을 때 테스트 오차율은 1.1%였습니다. 단순한 유클리드 거리를 사용한 전처리 기술은 접선 거리 계산에 필요한 반복 횟수를 줄였습니다.
11. SVM
SVM(Support Vector Machine)은 복잡한 결정 표면을 생성하기 위해 잘 연구된 다항식 분류기입니다. 안타깝게도 다항식 항의 수 때문에 고차원 문제에는 실용적이지 않습니다. 서포트 벡터 기술은 고차원 공간, 심지어 여러 유형의 곡면을 포함하는 공간에서 복잡한 표면을 나타내는 매우 경제적인 방법입니다.
특히 흥미로운 결정 표면의 부분 집합은 두 클래스의 볼록 폐포(convex hulls)로부터 최대 거리에 있는 초평면(hyperplanes)에 해당하는 것입니다. Boser 외는 최대 마진(maximum margin) 집합이 훈련 샘플의 부분 집합(support vector)과 입력 이미지의 dot product을 계산하고, 그 결과를 거듭제곱한 후, 얻어진 숫자들을 선형적으로 결합함으로써 임의의 차수 k의 다항식을 구현할 수 있다는 것을 깨달았습니다. 서포트 벡터와 계수를 찾는 것은 선형 부등식 제약 조건이 있는 고차원 이차 최소화 문제를 푸는 것과 같습니다.
일반 SVM을 사용했을 때 regular test set에서의 오차율은 1.4%였습니다. Cortes와 Vapnik은 약간 다른 기술을 사용하여 동일한 데이터에서 1.1%의 오차율을 보고했습니다. 이 기술의 계산 비용은 인식 건당 약 1,400만 번의 곱셈-덧셈 연산으로 매우 높습니다. Schölkopf의 V-SVM 기술을 사용하면 1.0%의 오차율을 달성했습니다. 더 최근에 Schölkopf는 V-SVM의 수정된 버전을 사용하여 0.8%에 도달했습니다. 안타깝게도 V-SVM은 일반 SVM보다 약 두 배나 비용이 많이 듭니다. 이 문제를 완화하기 위해 Burges는 RS-SVM 기술을 제안했으며, 일반 테스트 세트에서 1.1%의 오차율을 달성했습니다. 이는 인식 건당 65만 번의 곱셈-덧셈 연산의 계산 비용으로, LeNet-5보다 단지 60% 더 비싼 수준입니다.
D. Discussion
분류기들의 성능 요약은 그림 9~12에 나와 있습니다. 그림 9는 10,000개의 예시 테스트 세트에 대한 분류기들의 원본 오차율을 보여줍니다. Boosted LeNet-4가 0.7%의 점수를 달성하며 최고의 성능을 보였고, LeNet-5가 0.8%로 그 뒤를 바짝 쫓았습니다.
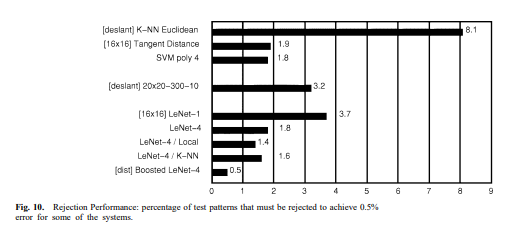
위 그림 10은 일부 방법에서 0.5%의 오차율을 달성하기 위해 기각해야 하는 테스트 세트 패턴의 수를 보여줍니다. 해당 값이 미리 정해진 임계값보다 작을 때 패턴이 기각됩니다. 많은 응용 분야에서 기각 성능은 원본 오차율보다 더 중요합니다. 패턴 기각 여부를 결정하는 데 사용된 점수는 상위 두 클래스의 점수 차이였습니다. 다시 한번, Boosted LeNet-4가 최고의 성능을 보였습니다. LeNet-4의 향상된 버전들은 원본 LeNet-4보다 성능이 좋았지만, 원본 정확도는 동일했습니다.
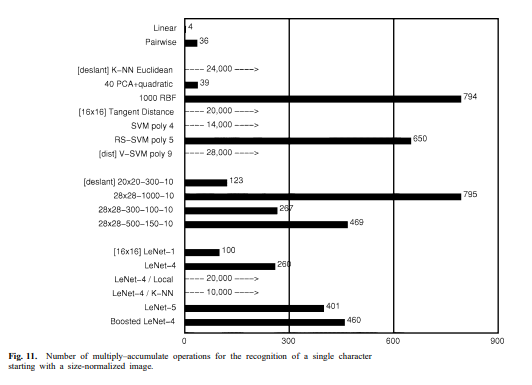
위 그림 11은 각 방법에 대해 단일 정규화된 이미지를 인식하는 데 필요한 곱셈-누적 연산의 횟수를 보여줍니다. 예상대로, 신경망은 메모리 기반 방법보다 훨씬 덜 까다롭습니다. CNN은 규칙적인 구조와 가중치에 대한 낮은 메모리 요구량 때문에 특히 하드웨어 구현에 적합합니다. LeNet-5의 선행 모델들의 칩 혼합 아날로그-디지털 구현은 초당 1000자 이상의 속도로 작동하는 것으로 나타났습니다. 그러나 주류 컴퓨터 기술의 급속한 발전은 이러한 이국적인 기술들을 빠르게 구식으로 만듭니다. 메모리 기반 기술의 효과적인 구현은 막대한 메모리 및 계산 요구 사항으로 인해 더 파악하기 어렵습니다.
훈련 시간도 측정되었습니다. K-NN과 탄젠트 거리 분류기는 본질적으로 훈련 시간이 없습니다. 단일 계층망, 쌍별 망, PCA+quadratic net은 1시간 이내에 훈련될 수 있었지만, 다층 신경망은 훈련 세트를 10-20회 통과해야 했습니다. 이는 단일 200MHz R10000 프로세서를 사용하는 Silicon Graphics Origin 2000 서버에서 LeNet-5를 훈련시키는 데 2~3일에 해당합니다. 훈련 시간은 설계자에게는 다소 중요하지만, 최종 사용자에게는 거의 중요하지 않다는 점에 유의하는 것이 중요합니다. 상당한 훈련 시간을 희생하여 약간의 개선을 가져오는 기존 기술과 새로운 기술 사이에서, 최종 사용자는 후자를 선택할 것입니다.
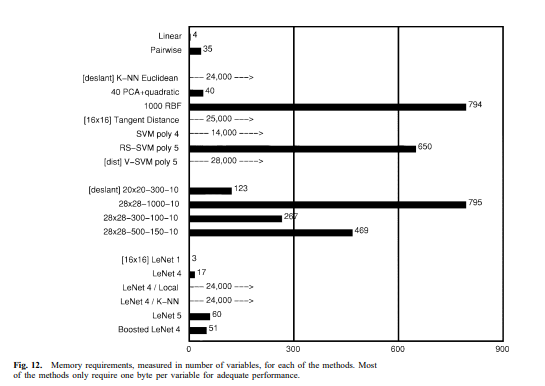
위 그림 12는 다양한 분류기들의 메모리 요구 사항, 즉 자유 파라미터의 수를 저장해야 할 변수의 수로 측정한 값을 보여줍니다. 대부분의 방법은 적절한 성능을 위해 변수당 약 1바이트만 필요합니다. 그러나 최근접 이웃 방법은 템플릿 이미지를 저장하기 위해 픽셀당 4비트가 필요할 수 있습니다. 놀랍지 않게도, 신경망은 메모리 기반 방법보다 훨씬 적은 메모리를 필요로 합니다.
전반적인 성능은 정확도, 실행 시간 및 메모리 요구 사항을 포함한 많은 요인에 따라 달라집니다. 컴퓨터 기술이 향상됨에 따라 더 큰 용량의 인식기가 실현 가능해집니다. 더 큰 인식기는 훈련 시간이 더 오래 걸립니다. LeNet-1은 1989년에 사용 가능한 기술에서는 적절했지만 LeNet-5는 그렇지 않았습니다. 1989년에는 LeNet-5만큼 복잡한 인식기는 몇 주간의 훈련과 더 많은 데이터가 필요했을 것이므로 고려되지 않았습니다. 오랫동안 LeNet-1은 최첨단 기술로 간주되었습니다. 지역 학습 분류기, 최적 마진 분류기 및 탄젠트 거리 분류기는 LeNet-1을 기반으로 개발되었으며 성공했습니다. 그러나 결국 개선된 신경망 아키텍처에 대한 동기가 생겼습니다.
저자는 Boosting이 메모리와 계산 비용을 약간만 증가시키면서 정확도를 약간 향상시킨다는 것을 발견했습니다. Distortion Models는 실제로 추가 데이터를 수집하지 않고도 데이터 세트의 유효 크기를 늘리는 데 사용될 수 있습니다.
SVM은 다른 고성능 분류기들보다 사전 지식이 현저히 적기 때문에 우수한 성능을 보여줍니다. 사실, 이 분류기는 이미지 픽셀이 뒤섞여 그림 구조를 잃더라도 거의 비슷한 성능을 보일 것입니다. 그러나 CNN에 필적하는 성능 수준에 도달하는 것은 메모리와 계산 요구 사항에서 상당한 비용을 치러야만 가능합니다. RSVM 요구 사항은 두 컨볼루션 신경망의 범위 내에 있으며 오차율은 매우 가깝습니다.
데이터가 많을 때, 많은 방법이 비슷한 행동을 보일 수 있습니다. NN 기반 방법은 훨씬 적은 공간을 차지하고 메모리 기반 방법보다 훨씬 적은 계산을 필요로 합니다. 훈련 데이터베이스의 크기가 계속 증가함에 따라 신경망의 이점은 더욱 두드러질 것입니다.
E. Invariance and Noise Resistance
CNN은 실제 단어 인식 시스템에서 휴리스틱 분할기에 의해 생성되는 것과 같이 위치, 크기 및 방향이 크게 다른 객체를 인식하거나 거부하는 데 특히 적합합니다.

위에서 설명한 실험에서는 크기 왜곡과 이동 불변성의 중요성이 명확하지 않습니다. 실제 응용 분야에서의 상황은 다릅니다. 문자는 일반적으로 인식 전에 컨텍스트에서 분리되어야 합니다. 분할 알고리즘은 거의 완벽하지 않으며 종종 문자 이미지에 외부 표시를 남기거나 때로는 너무 많이 잘라 불완전한 문자를 생성합니다. 이러한 이미지는 안정적으로 크기를 정규화하거나 중앙에 배치할 수 없습니다. 불완전한 문자를 정규화하는 것은 매우 위험할 수 있습니다. 따라서 많은 시스템이 단어나 필드의 수준에서 정규화를 시도했습니다. 한 경우, 전체 필드(예: 금액)의 상단 및 하단 경계가 감지되고 고정된 높이로 정규화하는 데 사용됩니다. 이는 stray mark가 문자 크기로 부풀려지지 않도록 보장하지만, 분할 후 문자의 크기와 수직 위치에 변화를 만듭니다. 따라서 이러한 변화에 강건한 recognizer를 사용하는 것이 좋습니다. 위 그림은 LeNet-5에 의해 정확하게 인식되는 왜곡된 문자의 몇 가지 예를 보여줍니다.
정확한 인식은 약 2배의 크기 변화, 문자 높이의 약 절반에 해당하는 상하 이동, 그리고 최대 ±30도의 회전까지 발생하는 것으로 추정됩니다. 복잡한 모양의 완전한 불변 인식은 여전히 어려운 목표이지만, CNN은 기하학적 왜곡에 대한 불변성 또는 강건성 문제에 대한 부분적인 해답을 제공하는 것으로 보입니다.
위 그림에는 극도로 잡음이 많은 조건 하에서 LeNet-5의 강건성 예시가 포함되어 있습니다. 이러한 이미지를 처리하는 것은 많은 방법에서 분할 및 특징 추출의 극복할 수 없는 문제를 제기하지만, LeNet-5는 이러한 어수선한 이미지에서 두드러진 특징을 강건하게 추출할 수 있는 것으로 보입니다. 여기에 표시된 네트워크에 사용된 훈련 세트는 소금-후추 잡음이 추가된 MNIST 훈련 세트였습니다. 각 픽셀은 0.1의 확률로 무작위로 반전되었습니다.
포스팅 마무리
논문의 분량상 나누어서 포스팅을 올릴 수 밖에 없었습니다. 논문이 총 10개의 섹션으로 나누어져 있는데 이번에는 3번째 섹션까지만 작성해 보았습니다. 나머지도 다 읽긴 했는데 포스팅을 올리는데 시간이 꽤 걸릴것 같지만 최대한 빨리 올려야 겠습니다.
아마 총 3개의 포스팅으로 나누어져서 올릴것 같고 다음은 4~6이나 4~7정도의 섹션을 올릴 것 같습니다.
