[SK shieldus Rookies 19기][Python] 2일차, 포맷, 입출력, 각 자료형, if문
포맷 문자열
https://docs.python.org/ko/3/tutorial/inputoutput.html#formatted-string-literals
기본 포맷팅
import math
'The value of pi is approximately %.3f' % math.pi
# 'The value of pi is approximately 3.142'f-string 포맷팅
f'The value of pi is approximately {math.pi:.3f}'
# 'The value of pi is approximately 3.142'
str.format() 포맷팅
'The value of pi is approximately {:.3f}'.format(math.pi)
# 'The value of pi is approximately 3.142'정수 포맷팅
"%d" % 1234
# '1234'
"%10d" % 1234
# ' 1234'
"%-10d" % 1234
# '1234 '부동소수점 포맷팅
"%f" % 1234.5678
# '1234.567800'
"%.3f" % 1234.5678
# '1234.568'
"%10.3f" % 1234.5678
# ' 1234.568'str.format()를 사용한 문자열 포맷팅
"I eat {0} apples".format(3)
# 'I eat 3 apples'
"I eat {} apples".format(3)
# 'I eat 3 apples'
"{0:<10}python".format("hi!")
# 'hi! python'
"{0:>10}python".format("hi!")
# ' hi!python'
"{0:!<10}python".format("hi")
# 'hi!!!!!!!!python'기본 포맷팅
import math
'The value of pi is approximately %.3f' % math.pi
# 'The value of pi is approximately 3.142'기본 포맷팅
import math
'The value of pi is approximately %.3f' % math.pi
# 'The value of pi is approximately 3.142'print() 함수
기본 사용법
print("The Latin 'Oryctolagus cuniculus' means 'domestic rabbit'.")
# 출력: The Latin 'Oryctolagus cuniculus' means 'domestic rabbit'.탭과 개행 문자를 포함하는 문자열
\n = 줄바꿈
\t = tab
print('one\ttwo\nthree\tfour')
# 출력: one two
# three four여러 줄 문자열의 출력
members = '''one
two
three'''
print(members)
# 출력: one
# two
# threeprint() 함수의 세부 사용법
print(1, 2, 3)
# 출력: 1 2 3
print(1, 'two', 'three', 4.0)
# 출력: 1 two three 4.0
radius = 5
print("The diameter of the circle is", radius * 2, "cm.")
# 출력: The diameter of the circle is 10 cm.sep과 end 파라미터
print('a', 'b', 'c')
# 출력: a b c
print('a', 'b', 'c', sep='|')
# 출력: a|b|c
print('a', 'b', 'c', sep='|', end='...')
# 출력: a|b|c...input() 함수
입력받기
species = input()
# 사용자 입력: Homo sapiens
# 'Homo sapiens'
species = input("Please enter a species: ")
# 사용자 입력: Python curtus
# 'Python curtus'입력된 값의 타입 확인 및 변환
population = input()
# 사용자 입력: 6973738433
# '6973738433'
type(population)
# <class 'str'>
population = int(population)
# 6973738433
type(population)
# <class 'int'>f-string을 사용한 출력
name = input("이름을 입력하세요. : ")
# 사용자 입력: 홍길동
print(f"안녕. {name}")
# 출력: 안녕. 홍길동
리스트 자료형
리스트 생성 및 기본 사용법
리스트 생성하기
# 빈 리스트 생성
a = [] # a = list()와 동일
# 출력: []
# 숫자 리스트 생성
b = [1, 2, 3]
# 출력: [1, 2, 3]
# 문자열 리스트 생성
c = ['Life', 'is', 'too', 'short']
# 출력: ['Life', 'is', 'too', 'short']
# 혼합 타입의 리스트 생성
d = [1, 2, 'Life', 'is']
# 출력: [1, 2, 'Life', 'is']
# 리스트를 포함한 리스트 생성
e = [1, 2, ['Life', 'is']]
# 출력: [1, 2, ['Life', 'is']]리스트 인덱싱과 슬라이싱
리스트 인덱싱
a = [1, 2, 3]
print(a[0]) # 첫 번째 요소 접근
# 출력: 1
print(a[0] + a[2]) # 첫 번째 요소와 세 번째 요소의 합
# 출력: 4
print(a[-1]) # 마지막 요소 접근
# 출력: 3
# 중첩된 리스트 인덱싱
a = [1, 2, 3, ['a', 'b', 'c']]
print(a[-1][0]) # 중첩된 리스트의 첫 번째 요소 접근
# 출력: 'a'리스트 슬라이싱
a = [1, 2, 3, 4, 5]
print(a[0:2]) # 첫 번째부터 세 번째 요소 직전까지
# 출력: [1, 2]
# 중첩된 리스트 슬라이싱
a = [1, 2, 3, ['a', 'b', 'c'], 4, 5]
print(a[2:5]) # 세 번째 요소부터 다섯 번째 요소까지
# 출력: [3, ['a', 'b', 'c'], 4]
print(a[3][:2]) # 중첩된 리스트의 첫 번째부터 두 번째 요소까지
# 출력: ['a', 'b']리스트 연산하기
리스트 더하기와 반복하기
# 리스트 더하기
a = [1, 2, 3]
b = [4, 5, 6]
print(a + b)
# 출력: [1, 2, 3, 4, 5, 6]
# 리스트 반복하기
print(a * 3)
# 출력: [1, 2, 3, 1, 2, 3, 1, 2, 3]리스트 길이 구하기
print(len(a))
# 출력: 3리스트 수정과 삭제
리스트 값 수정하기
a[2] = 4
print(a)
# 출력: [1, 2, 4]
리스트 요소 삭제하기
del a[1]
print(a)
# 출력: [1, 4]
# 슬라이싱을 사용한 요소의 범위 삭제
a = [1, 2, 3, 4, 5]
del a[2:]
print(a)
# 출력: [1, 2]튜플 자료형
튜플이란?
- 튜플은 리스트와 유사하지만 몇 가지 중요한 차이점이 있음
- 튜플은 ()로 요소를 감싸서 생성
- 튜플의 요소는 한 번 설정되면 변경, 삭제, 추가가 불가능
튜플 생성하기
t1 = () # 빈 튜플
t2 = (1,) # 요소가 하나인 튜플을 생성할 때는 요소 뒤에 쉼표를 붙여야 함
t3 = (1, 2, 3)
t4 = 1, 2, 3 # 괄호를 생략해도 튜플 생성 가능
t5 = ('a', 'b', ('ab', 'cd'))튜플 다루기
튜플은 리스트와 매우 비슷하게 다룰 수 있지만, 요소를 변경할 수 없다.
인덱싱
t1 = (1, 2, 'a', 'b')
print(t1[0]) # 첫 번째 요소 접근
# 출력: 1
print(t1[3]) # 네 번째 요소 접근
# 출력: 'b'슬라이싱
print(t1[1:]) # 두 번째 요소부터 끝까지
# 출력: (2, 'a', 'b')튜플 더하기
t2 = (3, 4)
t3 = t1 + t2 # 튜플 결합
print(t3)
# 출력: (1, 2, 'a', 'b', 3, 4)튜플 곱하기
t3 = t2 * 3 # 튜플 반복
print(t3)
# 출력: (3, 4, 3, 4, 3, 4)튜플 길이 출력
print(len(t1)) # 튜플의 길이
# 출력: 4튜플의 요소 변경 시도
튜플의 요소는 변경할 수 없음
변경을시도할 경우 파이썬은 오류를 반환함
# 튜플 요솟값을 삭제하려 할 때
# del t1[0] # TypeError
# 튜플 요솟값을 변경하려 할 때
# t1[0] = 'c' # TypeError딕셔너리 자료형
파이썬 딕셔너리(Dictionary)
딕셔너리는 Key와 Value의 쌍으로 이루어진 컬렉션이다. 파이썬의 매우 유용한 데이터 구조 중 하나로, 다른 언어에서는 해시(Hash)나 연관 배열(Associative Array)과 유사하다.
딕셔너리의 특징
- {}를 사용하여 데이터를 둘러싸서 생성한다.
- Key를 통해 Value를 빠르게 찾아낼 수 있다.
- Key는 고유한 값이어야 하며, 중복이 허용되지 않다.
- Value는 다양한 데이터 타입을 사용할 수 있다.
딕셔너리 생성
# 빈 딕셔너리
dic = {}
# 키와 값의 쌍을 포함한 딕셔너리
dic = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
# 정수 키와 문자열 값
a = {1: 'hi'}
# 값에 리스트 포함
a = {'a': [1, 2, 3]}딕셔너리 쌍 추가 및 삭제
쌍 추가하기
a = {1: 'a'}
a[2] = 'b' # {1: 'a', 2: 'b'}
a['name'] = 'pey' # {'name': 'pey'}
a[3] = [1, 2, 3] # {3: [1, 2, 3]}쌍 삭제하기
del a[1] # {2: 'b', 'name': 'pey', 3: [1, 2, 3]}딕셔너리 사용법
Key를 통해 Value 얻기
grade = {'pey': 10, 'julliet': 99}
print(grade['pey']) # 10
print(grade['julliet']) # 99딕셔너리 관련 함수들
Key 리스트 만들기(keys)
a = {'name': 'pey', 'phone': '010-9999-1234', 'birth': '1118'}
print(list(a.keys())) # ['name', 'phone', 'birth']Value 리스트 만들기(values)
print(list(a.values())) # ['pey', '010-9999-1234', '1118']Key, Value 쌍 얻기(items)
print(list(a.items())) # [('name', 'pey'), ('phone', '010-9999-1234'), ('birth', '1118')]Key: Value 쌍 모두 지우기(clear)
a.clear()
print(a) # {}Key로 Value 얻기(get)
print(a.get('name')) # 'pey'
print(a.get('nokey')) # None
# 디폴트 값이 주어진 경우
print(a.get('nokey', 'default')) # 'default'해당 Key가 딕셔너리 안에 있는지 조사하기(in)
print('name' in a) # True
print('email' in a) # False집합 자료형(set)
집합(set)은 중복을 허용하지 않고, 순서가 없는 자료형이다. 집합은 집합에 관련된 것을 쉽게 처리하기 위해 만들어졌다.
집합 자료형 생성하기
# 리스트를 이용한 집합 생성
s1 = set([1, 2, 3])
print(s1) # {1, 2, 3}
# 문자열을 이용한 집합 생성
s2 = set("Hello")
print(s2) # {'e', 'H', 'l', 'o'}집합 자료형의 특징
- 중복을 허용하지 않는다.: 자동으로 중복된 값은 제거된다.
- 순서가 없다.(Unordered): 따라서, 인덱싱으로 값을 얻을 수 없다.
집합 자료형 활용
집합 자료형은 교집합, 합집합, 차집합을 구하는 데 유용하다.
s1 = set([1, 2, 3, 4, 5, 6])
s2 = set([4, 5, 6, 7, 8, 9])
# 교집합
print(s1 & s2) # {4, 5, 6}
print(s1.intersection(s2)) # {4, 5, 6}
# 합집합
print(s1 | s2) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
print(s1.union(s2)) # {1, 2, 3, 4, 5, 6, 7, 8, 9}
# 차집합
print(s1 - s2) # {1, 2, 3}
print(s2 - s1) # {7, 8, 9}
print(s1.difference(s2)) # {1, 2, 3}
print(s2.difference(s1)) # {7, 8, 9}집합 자료형 관련 함수들
값 추가하기(add)
s1 = set([1, 2, 3])
s1.add(4)
print(s1) # {1, 2, 3, 4}값 여러 개 추가하기(update)
s1.update([4, 5, 6])
print(s1) # {1, 2, 3, 4, 5, 6}특정 값 제거하기(remove)
s1.remove(2)
print(s1) # {1, 3, 4, 5, 6}주의할 점
집합 자료형은 순서가 없기 때문에, 인덱싱으로 값을 얻기 위해서는 리스트나 튜플로 변환해야 한다.
불(bool) 자료형
불 자료형은 참(True)과 거짓(False)을 나타내는 자료형으로, 두 가지 값만을 가질 수 있다. True는 참을, False는 거짓을 의미한다. True와 False는 파이썬의 예약어로, 첫 문자를 대문자로 작성해야 한다.
a = True
b = False
print(type(a)) # <class 'bool'>
print(type(b)) # <class 'bool'>불 자료형은 조건문의 결과값으로도 사용되며, 특정 조건이 참인지 거짓인지를 나타낼 때 사용된다.
print(1 == 1) # True
print(2 > 1) # True
print(2 < 1) # False파이썬에서의 불린(Boolean) 타입
True와 False 두 가지 값을 가진다.
논리 연산(not, and, or)이 가능하다.
0, 0.0, 빈 문자열(''), None은 False로 취급. 그 외 모든 수, 문자열은 True로 취급한다.
연산자 우선순위
산술 연산자 > 비교 연산자 > 불 연산자
x = 3
print((1 < x) and (x <= 5)) # True
print(1 < x <= 5) # True
print(3 < 5 != True) # True
print(3 < 5 != False) # True단락 평가(Short-Circuit Evaluation)
and나 or를 포함하는 표현식은 왼쪽부터 오른쪽으로 평가된다.
평가를 멈출 만한 충분한 정보를 얻으면, 아직 평가하지 않은 피연산자가 있어도 평가를 멈춘다.
print((2 < 3) or (1 / 0)) # True (1 / 0은 평가되지 않음)문자열 비교
ASCII 코드를 기준으로 비교한다. (공백(32) < A(65) < z(122))
사전순 비교: 문자열 내 서로 대응하는 문자들을 왼쪽부터 오른쪽으로 비교한다.
in 연산자: 어떤 문자열이 다른 문자열 내에 들어 있는지 확인한다.
print(' ' < 'A') # True
print('A' < 'z') # True
print('abc' < 'abcd') # True
print('Jan' in '01 Jan 2020') # True
print('' in 'abc') # True (빈 문자열은 모든 문자열의 부분 문자열)
print('' in '') # True에러 유형
구문 오류(Syntax Error): 유효하지 않은 파이썬 코드를 입력했을 때 발생.
# 3 + # SyntaxError: invalid syntax의미 오류(Semantic Error): 파이썬이 수행할 수 없는 작업을 요청했을 때 발생. 예를 들어, 수를 0으로 나누거나, 존재하지 않는 변수를 사용하는 경우.
# 3 + moogah # NameError: name 'moogah' is not defined자료형의 참과 거짓
파이썬에서는 다음과 같은 기준으로 자료형의 참과 거짓을 구분한다.
빈 문자열(""), 빈 리스트([]), 빈 튜플(()), 빈 딕셔너리({}), 0, None은 False로 취급한다.
그 외의 값들은 True로 취급한다.
if "python":
print("참")
else:
print("거짓")
# 출력: 참
if []:
print("참")
else:
print("거짓")
# 출력: 거짓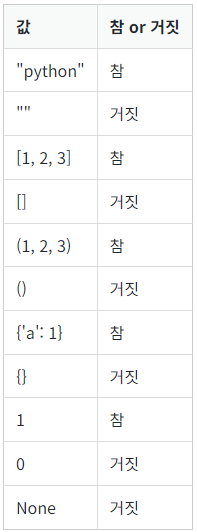
불 연산
print(bool('python')) # True
print(bool('')) # False
print(bool([1, 2, 3])) # True
print(bool([])) # False
print(bool(0)) # False
print(bool(3)) # Truewhile문과 불 자료형
while문에서 리스트가 비어 있지 않은 동안 (즉, 리스트가 참인 동안) 반복 실행되는 예제:
a = [1, 2, 3, 4]
while a:
print(a.pop())위 코드는 리스트 a의 요소가 더 이상 없을 때까지 (즉, a가 거짓이 될 때까지) 리스트의 마지막 요소를 하나씩 제거하며 출력한다.
if문과 불 자료형
if문에서는 조건이 참(True)인 경우 해당 블록을 실행하고, 거짓(False)인 경우 다른 블록을 실행한다.
if [1, 2, 3]:
print("참")
else:
print("거짓")
# 출력: 참자료형에 값 저장하기
변수 만들기
파이썬에서 변수는 단순히 데이터를 저장하는 이름이 아니라, 객체를 가리키는 참조로 사용된다.
a = 1
b = "python"
c = [1, 2, 3]리스트 복사
리스트를 복사할 때는 단순히 b = a와 같이 할당하면, a와 b는 동일한 리스트 객체를 참조한다. 따라서 한 변수에서 리스트를 변경하면 다른 변수에도 영향이 간다.
a = [1, 2, 3]
b = a
a[1] = 4
print(b) # [1, 4, 3]리스트를 복사해서 서로 다른 객체를 만들고 싶다면, 슬라이싱이나 copy 모듈의 copy 함수를 사용할 수 있다.
슬라이싱
a = [1, 2, 3]
b = a[:]
a[1] = 4
print(a) # [1, 4, 3]
print(b) # [1, 2, 3]copy
from copy import copy
a = [1, 2, 3]
b = copy(a)
print(b) # [1, 2, 3]
print(b is a) # False변수 생성 방법
파이썬에서는 튜플이나 리스트를 사용하여 여러 변수에 동시에 값을 할당할 수 있다.
튜플을 사용한 변수 생성
a, b = ('python', 'life')
# 또는
(a, b) = 'python', 'life'리스트를 사용한 변수 생성
[a, b] = ['python', 'life']여러 변수에 같은 값을 할당
a = b = 'python'변수의 값 교환
파이썬에서는 다음과 같이 간단하게 두 변수의 값을 교환할 수 있다.
a = 3
b = 5
a, b = b, a
print(a) # 5
print(b) # 3조건문(if)
조건문은 특정 조건을 만족하는지 여부에 따라 코드의 실행 흐름을 제어하는 기본적인 구조다. 파이썬에서 조건문은 if로 시작하며, 조건이 참(True)일 때만 해당 코드 블록을 실행한다.
# 조건문 예시
money = True
if money:
print("택시를 타고 가라")
# 출력: 택시를 타고 가라비교 연산자
비교 연산자는 두 값을 비교하여 참이나 거짓을 반환합니다. 파이썬에서는 다음과 같은 비교 연산자를 사용할 수 있다:
x = 3
y = 2
print(x > y) # True 작다
print(x < y) # False 크다
print(x == y) # False 같다
print(x != y) # True 같지 않다논리 연산자
논리 연산자는 여러 조건을 조합하여 복잡한 조건문을 만들 때 사용한다:
- and: 모두 참이면 참
- or: 하나라도 참이면 참
- not: 참이면 거짓, 거짓이면 참
money = 2000
card = True
if money >= 3000 or card:
print("택시를 타고 가라")
else:
print("걸어가라")
# 출력: 택시를 타고 가라in과 not in
in 연산자는 어떤 값이 특정 시퀀스(리스트, 튜플, 문자열 등) 안에 있는지 확인할 때 사용한다:
print(1 in [1, 2, 3]) # True
print('a' in ('a', 'b', 'c')) # True
print('j' not in 'python') # True
pocket = ['paper', 'cellphone', 'money']
if 'money' in pocket:
pass
else:
print("카드를 꺼내라")elif
elif는 여러 조건을 체인처럼 연결할 때 사용한다:
pocket = ['paper', 'cellphone']
card = True
if 'money' in pocket:
print("택시를 타고 가라")
elif card:
print("택시를 타고 가라")
else:
print("걸어가라")
# 출력: 택시를 타고 가라조건부 표현식
if 'money' in pocket: pass
else: print("카드를 꺼내라")
# 조건부 표현식
score = 60
message = "success" if score >= 60 else "failure"
print(message) # success