IPC(Inter-Process Communication)
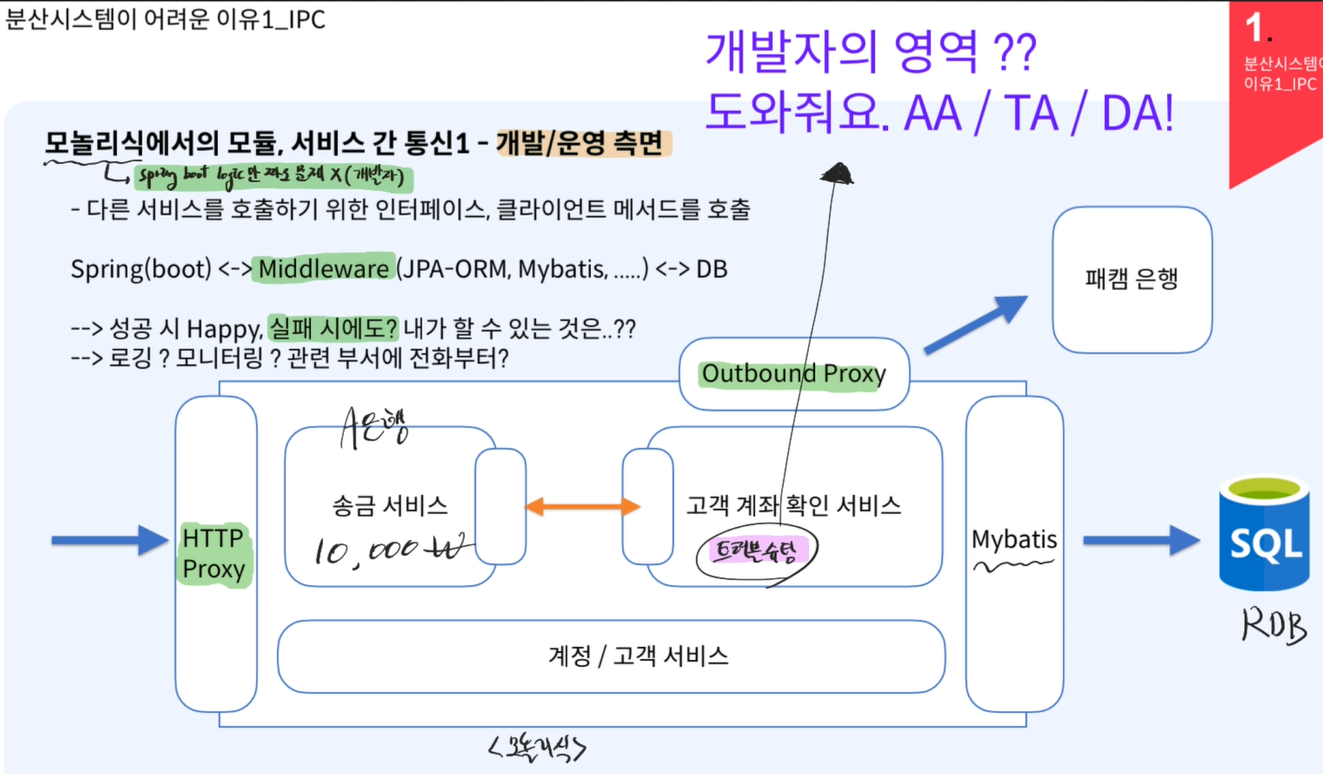
- 모놀리식에서의 모듈, 서비스 간 통신(개발, 운영 측면)
모놀리식에서는 개발자는 SpringBoot로 로직만 짜면 끝- 트러블 슈팅 발생 시, AA/TA/DA 호출
- 실패 시, 할 수 있는 것이 없음
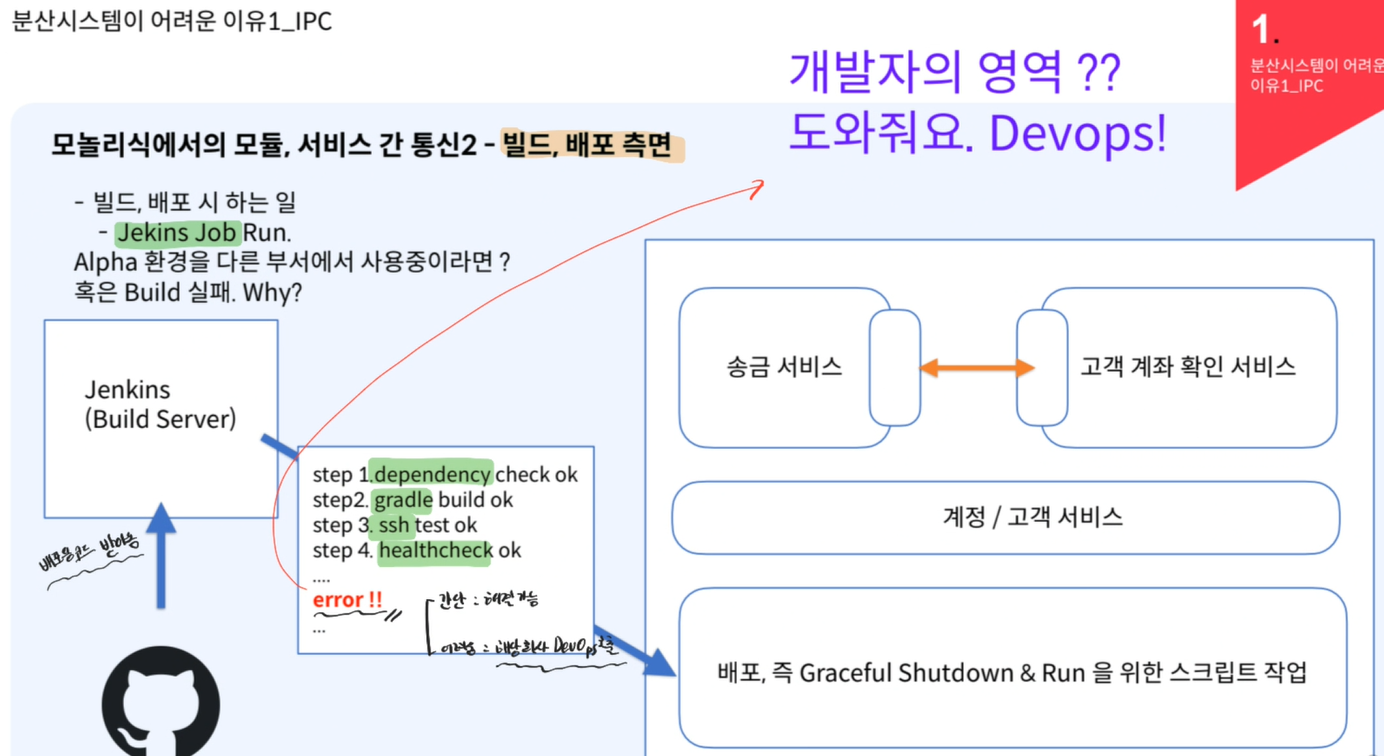
- 모놀리식에서의 모듈, 서비스 간 통신(빌드, 배포 측면)
- Jenkins Job으로 배포 : 깃허브로 부터 배포용 코드 받아오고 빌드
- 하지만 만약 빌드 도중에 ERROR 뜨면?
- 간단 : 갓 구글링으로 해결가능
- 복잡 : 해당 회사 DevOps 엔지니어 호출 ㅠㅠ
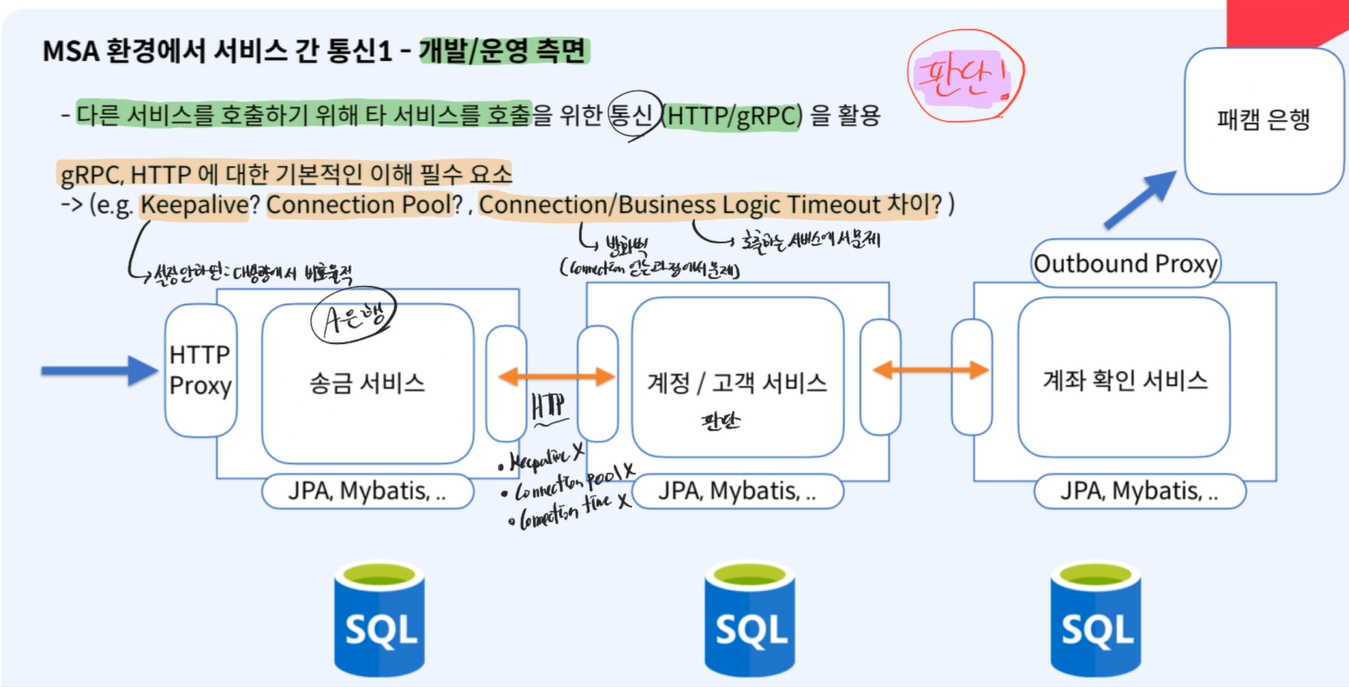
- MSA에서의 모듈, 서비스 간 통신(개발, 운영 측면)
다른 서비스를 호출:무조건 통신 필요(HTTP, gRPC)HTTP, gRPC 이해 필요Keepalive:설정을 하지 않으면 대용량 처리시 비효율적Connection PoolConnetcion Logic Timeout:방화벽문제, Connection을 얻어오는 과정에서 문제(외부)Business Logic Timeout:호출하는 서비스 내부에서 문제(내부)
- 따라서 이런 판단을 할 줄 알아야 하기 때문에 단점
- 알아야하는 양이 모놀리식에서는 개발만 하면 됬는데
- 지금은 어디서 문제가 발생했는지 알아야 DevOps 엔지니어와 소통이 가능
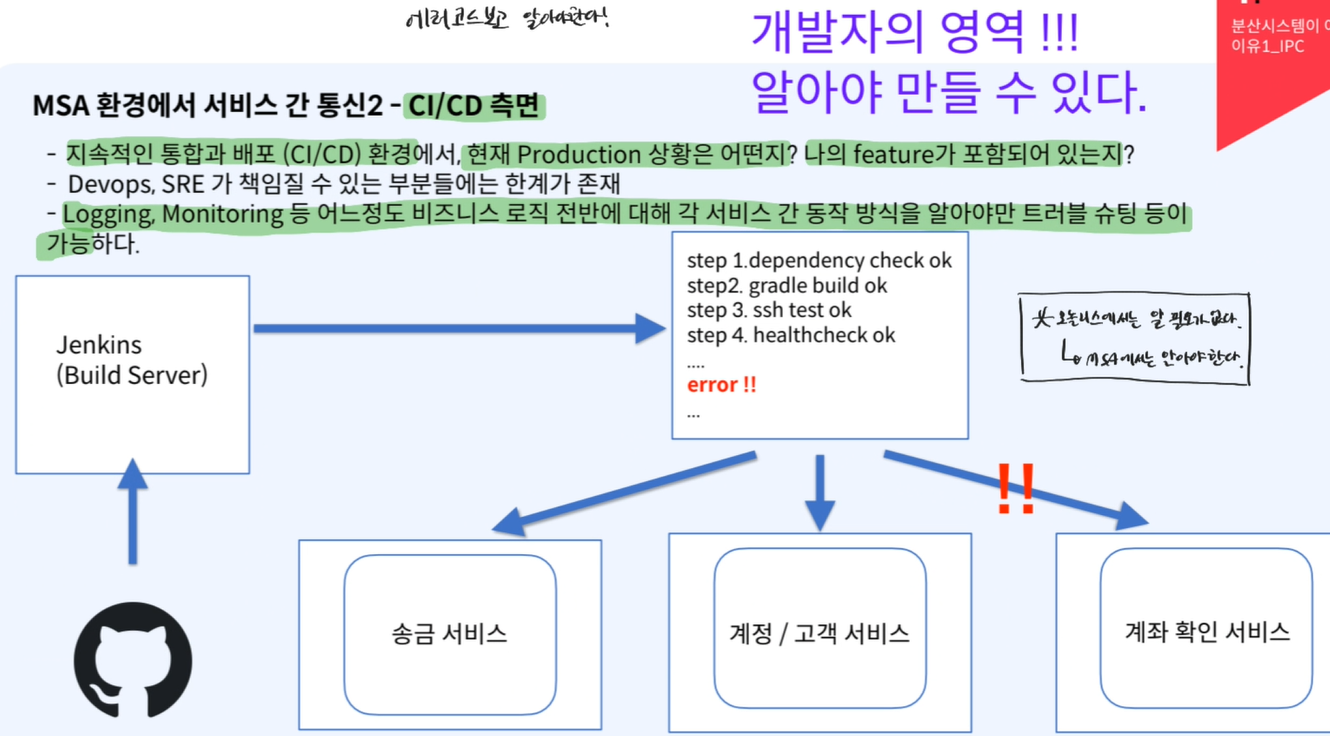
- MSA에서의 모듈, 서비스 간 통신(빌드, 배포 측면)
Transactions
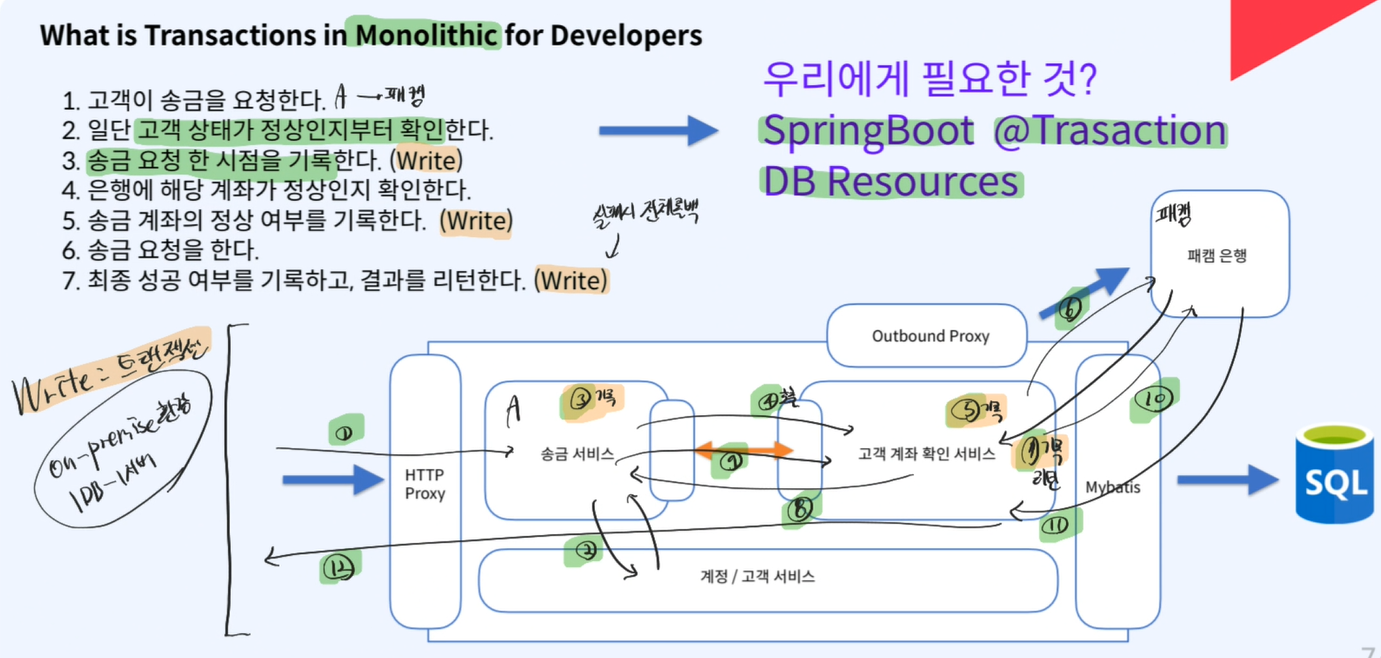
모놀리식 트랜젝션- 필요한 것
SpringBoot@TransactionDB Resource
on-premise방식이기 때문에1개의 DB 1개의 서버여서 트랜젝션은 1개의 서버에서 작동을 한다따라서 WRITE 3개중 1개라도 ERROR가 되면 전체가 ROLL BACK 된다.
- 필요한 것
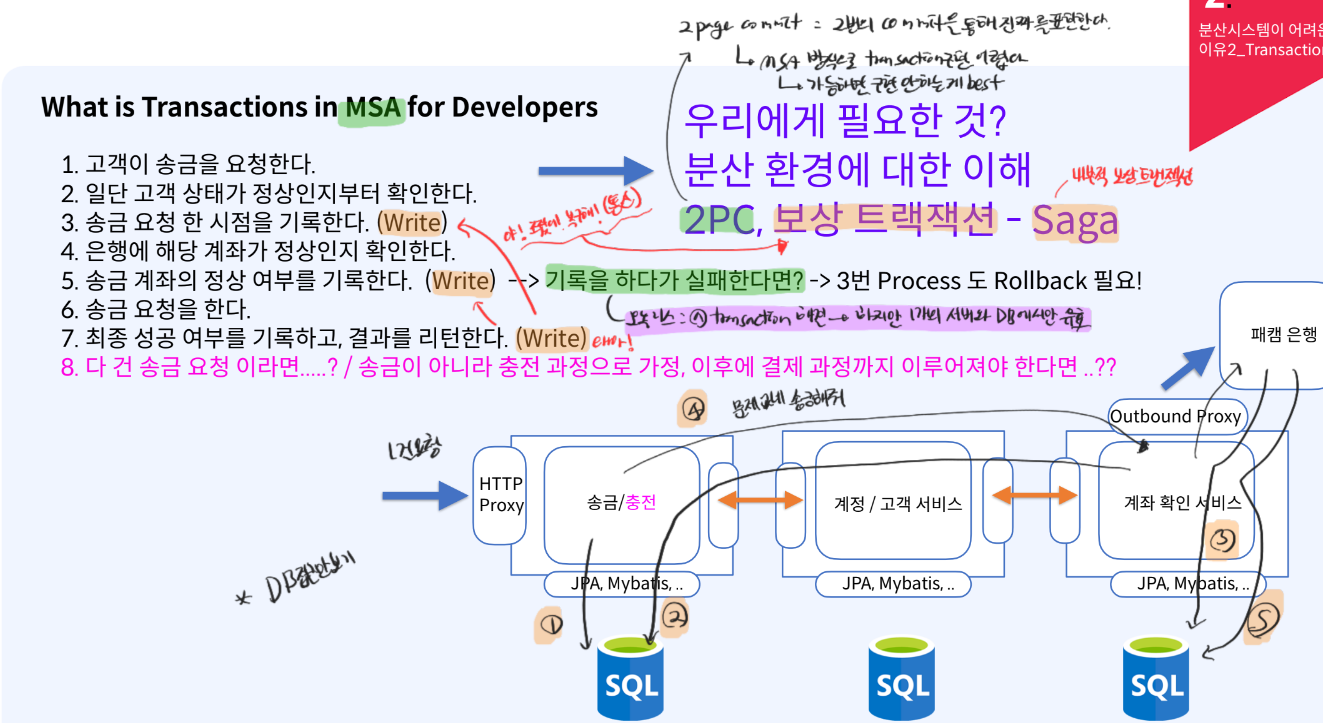
MSA 트랜젝션- 기본적으로
각 서비스를 호출할 때는통신을 통해서 호출한다. - 모놀리식의 경우 1개의 프로세스에서 실패시 전체 WRITE 되는 서비스가 ROLL BACK이지만
MSA의 경우는 통신이기 때문에 1개의 서비스가 실패시, 통신을 통해 이전 통과된 서비스에게도 실패했다고 알려주고 전부 ROLL BACK을 한다.- 이것을
보상 트랜젝션이라고 한다.
- 이것을
- 필요한 것
2PC:2 page commit2번의 commit을 통해 진짜를 표현- 따라서 2번이나 commit을 표현하는 것 자체가 어렵고 복잡
보상 트랜젝션Saga:내부적으로 보상 트랜젝션으로 구성
- MSA 트랜젝션은 복잡하고 어렵다.
- 기본적으로
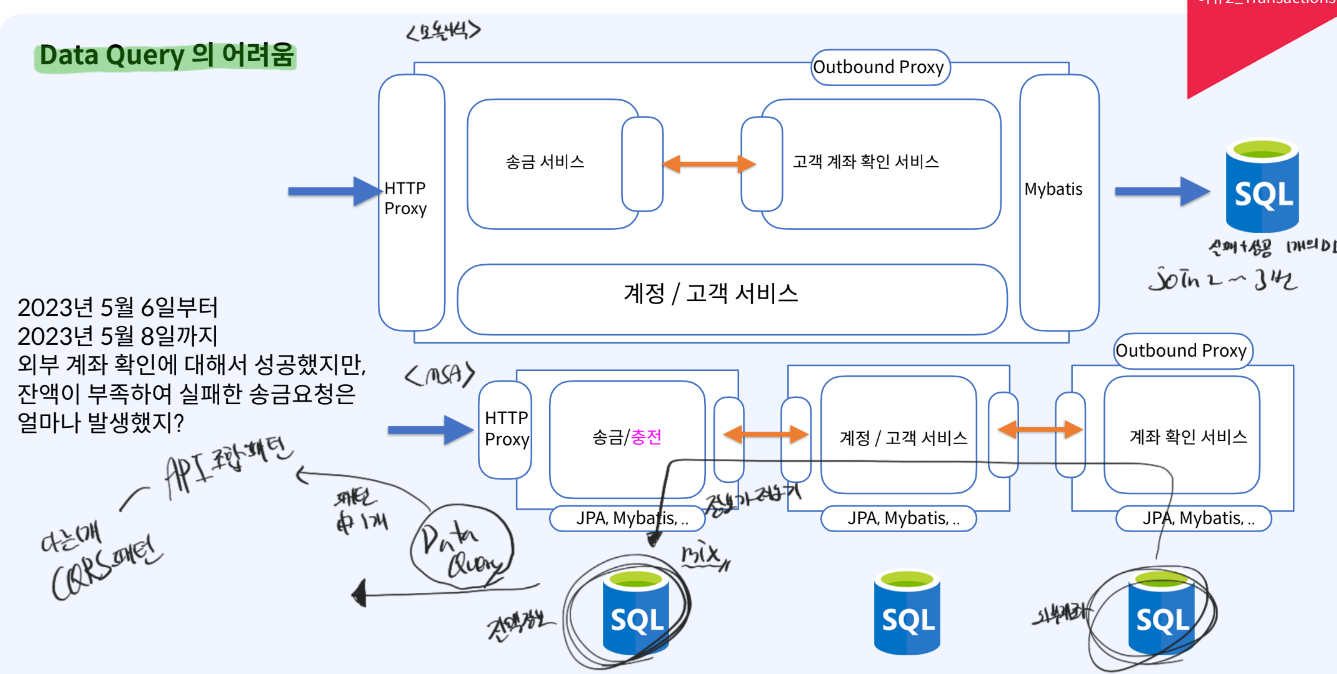
어렵고 복잡한 Data Query모놀리식의 경우: 1개의 DB만을 사용하기 떄문에 실패와 성공의 데이터를 가지고 오려면 JOIN을 2~3번 사용하면 해결 가능MSA의 경우:원하는 데이터가 서로 다른 곳에 존재하기 떄문에 통신을 통해서 먼저 다른 DB에서 원하는 데이터를 가져오고 그것을 바탕으로 정보를 추출- 듣기만 해도 복잡
- 이런 것을
Data QueryAPI 조합 패턴:말 그대로 API의 결과를 바탕으로 조합해서 Query 만듬CQRS 패턴
Monitoring
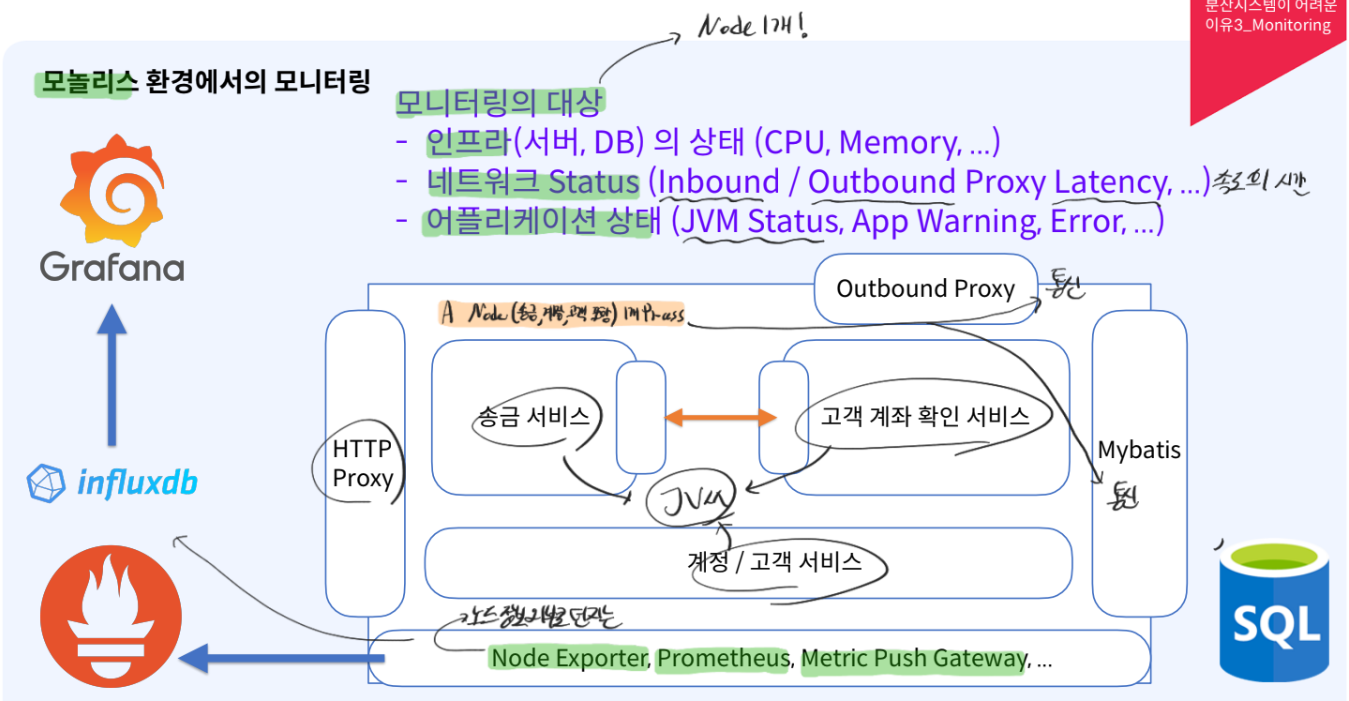
모놀리스 모니터링- 모니터링 대상
인프라- 서버, DB
상태:CPU, Memory
네트워크 Status:속도와 시간- Inbound Proxy Latency
- Outbound Proxy Latency
어플리케이션 상태- JVM Status
- App Warning
- Error
Node가 1개:송금서비스, 고객 계좌 확인 서비스, 계정/고객 서비스를 포함하는 1개의 Process1개의 Node가 외부와의 통신 + SQL과의 통신
- Node Exporter, Prometheus, Metric Push Gateway
- 모니터링 대상
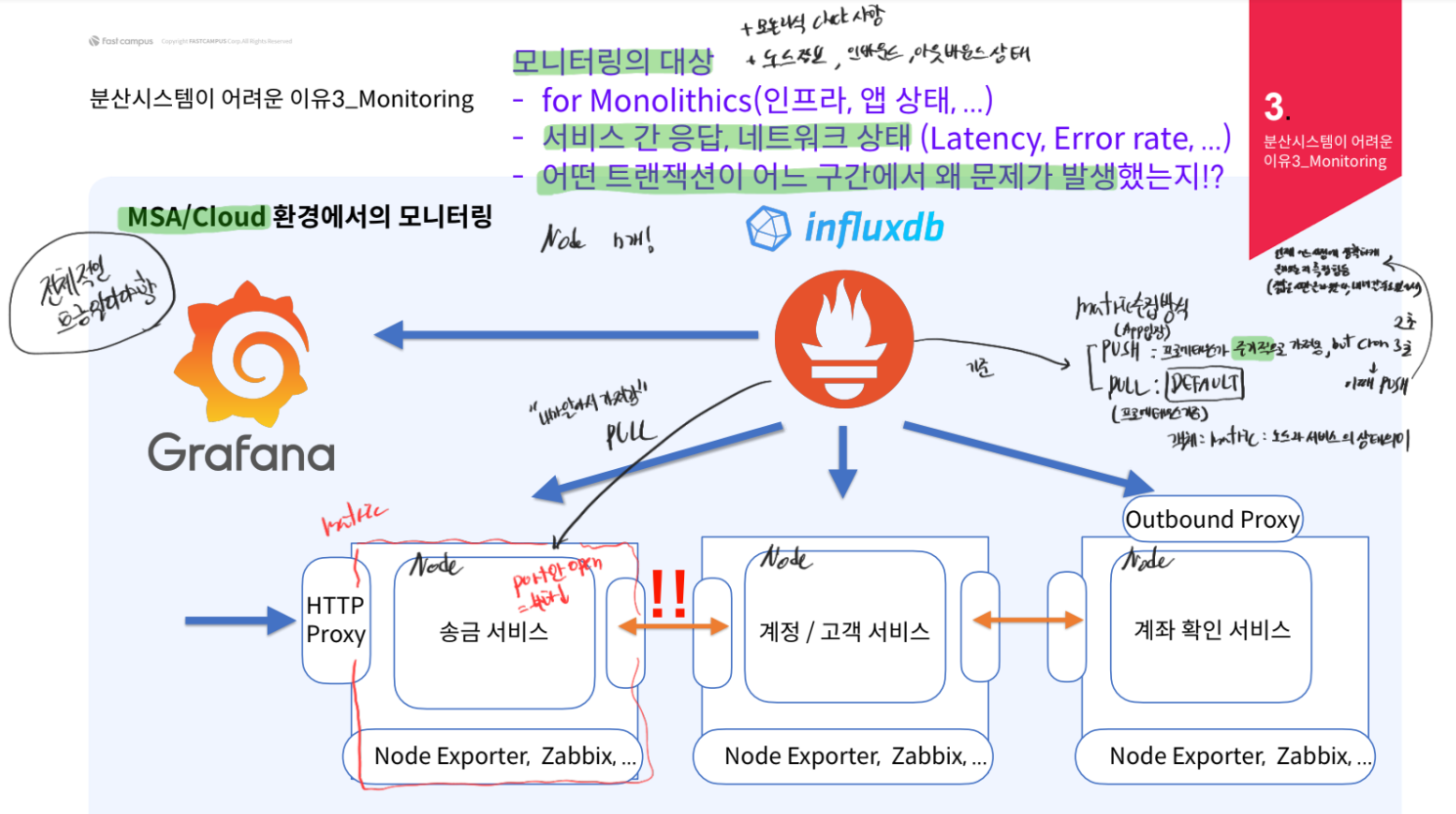
MSA/Cloud 모니터링- 모니터링 대상
모놀리스 모니터링 대상 포함서비스 간 응답, 네트워크 상태: Latency, Error rate어떤 트랜젝션이 어느 구간에서 왜 문제가 발생
전체적인 흐름을 다 알아야 모니터링이 가능어디서 문제가 생겼는지 알 수 있기 때문에
Node가 n개:각 서비스에 대해서 Node가 존재Matric:노드와 서비스의 상태를 의미Matric 수집방식PUSH(에플리케이션 기준): 프로메테우스가주기적으로 가지고 옴, but corn 2, 3초 이떄 PUSH언제 어느 시점에 정확하게 올라오는지 측정 힘듬- 짧은 시간올라왔다, 내려갈 수도 있어서
PULL(프로메테우스 기준):DEFAULT에플리케이션이 Port만 열어두면프로메테우스가 알아서 PULL을 해서 가져감- 따라서
에플리케이션 부하방지
- 따라서
- 모니터링 대상
- 결론
- MSA 난이도 높다
- 통신, 트랜젝션, 모니터링 -> 어려운 문제들
- 그러나 AWS, Cloud 기반 기술(Docker, K8S) 으로 많이 해결
- MSA환경에서 모니터링을 위한 다양한 기술 스택이나 이론 많이 나옴
전체적인 동작 방식과 구조 이해해야 -> Business Capabilites 챙길 수 있다.- 결론은
Business Capabilites 존나 중요, 돈이잖아 ㅎㅅㅎ.....

현재 블로그 : https://jasonsong97.tistory.com/