-
기본적인 cs 지식 (tcp/udp 차이, http/https 차이)
-
자신의 장단점
-
주위사람이 자기를 어떻게 평가하는지, 자소서 기술서 인성 질문 믹스
-
인터넷에 있는 웹관련 질문
-
스트레스 어떻게 해결?
-
갈들 상황에서의 대처
-
스타트업에 지원하게된 동기
-
서비스에 대한 소감
-
사람의 열정과 의자 많이 봄
-
객체지향 프로그랭이나 함수형 프로그래밍에 대해서 알고 있는 것 말해주셈
-
아키텍쳐와 기술 스택, 그리고 이런 기술을 사용해봤는지 갈등을 어떻게 해결했는지
-
아키텍쳐 관련 문제
-
애자일 조직과 워터풀 조직 본인에게 맞는 조직은?
-
본인의 프로젝트 중 가장 애착가는 플젝은?
-
자사의 서비스 개선 사항은?
-
Nestjs 라이프사이클
-
자기소개그리고 스트래스 관리법
애자일 조직과 워터풀 조직
워터폴 방법론은 개발 프로세스를 선형적으로 이루어지는 단계로 구성합니다. 요구 사항 정의, 설계, 구현, 테스트, 유지보수 등의 단계를 순차적으로 진행하는 방식으로, 각 단계가 완료되면 다음 단계로 넘어가는 구조입니다. 이 방식은 초기에 요구 사항을 명확하게 정의한 뒤에 개발을 시작하기 때문에 변경이 필요할 때에는 추가 비용과 시간이 소요될 수 있습니다.
애자일 방법론은 유연하고 반복적인 방식으로 개발을 진행합니다. 작은 단위의 일(주로 2주에서 한 달 정도)을 반복하면서 개발하고, 이후 피드백을 받아 보완하고 발전시키는 방식입니다. 이는 요구 사항이 변경될 수 있다는 전제하에 빠르게 대응하고 유연하게 작업을 진행하는 것을 강조합니다. 애자일은 고객의 요구사항을 유연하게 받아들이며, 작은 단위로 개발을 진행하여 변화에 빠르게 대응할 수 있습니다.
워터폴은 요구 사항을 미리 정의하고 개발을 진행하는 데 적합하며, 애자일은 빠르게 변화하는 환경에서 유연하게 대응할 수 있는 방법론입니다. 최근에는 이 두 방법론을 혼합하여 사용하는 경우도 많아지고 있습니다.
자바스크립트 작동원리
자바스크립트는 인터프리터 언어로, 코드를 실행하는 데에는 여러 단계가 포함됩니다.
파싱 (Parsing):
자바스크립트 엔진은 코드를 읽고 이해하기 위해 파싱 단계를 거칩니다. 소스 코드를 토큰으로 분해하고 구문 트리로 변환합니다.
컴파일 (Compilation) 또는 인터프리테이션 (Interpretation):
파싱된 코드는 컴파일러나 인터프리터에 의해 기계어로 변환됩니다. 이렇게 변환된 코드가 실행됩니다. 최근의 자바스크립트 엔진은 JIT(Just-In-Time) 컴파일러를 사용하여 실행 속도를 향상시킵니다.
실행 (Execution):
변환된 코드는 실행되며, 이때 변수, 함수, 객체 등의 메모리 공간이 할당되고 값이 계산됩니다. 코드는 위에서부터 아래로 순차적으로 실행되지만, 비동기적인 작업은 이를 조정하는 방식으로 처리됩니다.
이벤트 루프 (Event Loop):
자바스크립트는 단일 스레드에서 실행되기 때문에 이벤트 루프를 통해 비동기적 작업을 관리합니다. 비동기적 작업은 백그라운드에서 처리되고, 이벤트 루프를 통해 그 결과를 기다리거나 처리합니다.
자바스크립트는 단일 스레드로 동작하지만, 비동기적 작업을 통해 동시성을 활용할 수 있습니다. 또한, 브라우저에서는 DOM(Document Object Model)을 조작하고 웹 페이지를 업데이트하는 데에도 자바스크립트가 사용됩니다.
프로세스, 스레드, 멀티스레드
프로세스 (Process):
프로세스는 실행 중인 프로그램입니다. 각 프로세스는 독립된 메모리 공간을 가지고 있으며, 운영체제에 의해 관리됩니다. 각 프로세스는 실행 중인 프로그램의 인스턴스로, 프로그램 코드, 데이터, 메모리 등을 포함합니다. 각각의 프로세스는 다른 프로세스와 독립되어 있고, 서로 영향을 주지 않습니다.
스레드 (Thread):
스레드는 프로세스 내에서 실행되는 흐름의 단위입니다. 하나의 프로세스에는 여러 개의 스레드가 있을 수 있습니다. 스레드는 프로세스의 자원을 공유하며, 각각의 스레드는 독립적인 실행 흐름을 가지고 있습니다. 스레드는 프로세스의 코드, 데이터를 공유하면서 동시에 여러 작업을 수행할 수 있습니다.
멀티스레딩 (Multithreading):
멀티스레딩은 하나의 프로세스 내에서 여러 개의 스레드가 동시에 작업하는 것을 말합니다. 멀티스레딩을 통해 여러 작업을 병렬적으로 처리할 수 있으며, 이는 프로그램의 성능을 향상시킬 수 있습니다. 하나의 스레드가 작업을 완료하기 전에도 다른 스레드가 작업을 수행할 수 있어서 시스템 자원을 효율적으로 사용할 수 있습니다.
변수의 생성과정과 호이스팅에 대해 설명
- 변수의 생성과정
선언 (Declaration):
변수를 생성하기 위해 해당 변수의 이름을 선언합니다. 선언은 메모리에 변수를 위한 공간을 할당하고, 변수의 이름을 프로그램에 알립니다.
할당 (Initialization 또는 Assignment):
선언된 변수에 값을 할당하거나 초기화합니다. 이 단계에서는 변수에 원하는 값을 저장합니다.
- 호이스팅
자바스크립트와 같은 몇몇 프로그래밍 언어에서, 변수 및 함수 선언들이 컴파일 단계에서 해당 스코프의 최상단으로 옮겨지는 현상을 말합니다. 즉, 코드 실행 전에 변수 선언이나 함수 선언이 메모리에 먼저 올려지는 것입니다.
console.log(myVar); // undefined
var myVar = 10;
console.log(myVar); // 10
.
.
.
myFunction(); // "Hello!"
function myFunction() {
console.log("Hello!");
}함수 선언이 함수가 호출되기 이전에 작성되었지만, 호출은 잘 실행됩니다. 이는 함수 선언이 호이스팅되어 코드의 상단으로 올라가기 때문입니다.
호이스팅은 변수나 함수의 선언을 상단으로 옮기지만, 실제 할당 과정은 옮겨지지 않습니다. 이러한 특성은 코드의 가독성과 예측성을 해치기도 하므로, 변수와 함수의 사용 전 선언하는 것이 좋습니다.
동기와 비동기
동기 (Synchronous)
동기 작업은 순차적으로 진행되며, 하나의 작업이 끝날 때까지 다음 작업이 시작하지 않습니다. 즉, 작업이 차례로 진행되며, 이전 작업이 완료될 때까지 다음 작업을 기다리는 방식입니다. 동기적인 작업은 요청된 작업이 완료될 때까지 대기하고 결과를 반환합니다.
비동기 (Asynchronous)
비동기 작업은 작업을 순차적으로 기다리지 않고, 요청된 작업을 실행한 후에도 다음 작업을 바로 시작합니다. 즉, 한 작업이 시작되더라도 결과를 기다리지 않고 다른 작업을 수행할 수 있습니다. 비동기적인 작업은 작업의 완료를 기다리지 않고, 보통 콜백(callback) 함수나 프라미스(promise)를 사용하여 작업이 완료되면 그에 따른 처리를 합니다.
간단히 말하자면, 동기는 순차적이고 직렬적인 실행을 의미하며, 비동기는 병렬적으로 작업을 처리하고 다른 작업을 기다리지 않고 진행하는 방식을 의미합니다. 비동기 작업은 대기 시간을 최소화하고 성능을 향상시키는 데 도움이 될 수 있습니다.
Promise특징과 Async/Await 특징
Promise는 자바스크립트에서 비동기 처리를 위한 객체로, 비동기 작업의 결과를 처리할 수 있는 대기 중(pending), 이행됨(fulfilled), 거부됨(rejected)의 상태를 가집니다. Promise는 then(),catch() 메서드를 사용하여 이행됨 상태와 거부됨 상태에 대한 처리를 지정할 수 있습니다.
비동기 작업의 결과를 처리할 수 있습니다.
이행됨 상태와 거부됨 상태에 대한 처리를 지정할 수 있습니다.
Promise 체인을 사용하여 여러 개의 비동기 작업을 순차적으로 처리할 수 있습니다.
콜백 지옥(callback hell)를 방지할 수 있습니다.
Promise는 서버와의 통신, 파일 업로드/다운로드, 데이터베이스 조회 등의 비동기 작업에서 자주 사용됩니다.
const를 사용했을 때 값을 변경할 수 있는 상황은
const로 변수를 선언하면, 이후에 변수의 값이 변경되는 것을 방지할 수 있습니다. 그러나 const로 선언한 변수의 값이 변경되는 상황은 다음과 같습니다.
- const로 선언한 변수가 객체 또는 배열인 경우, 해당 변수가 가리키는 객체나 배열 내부의 값은 변경될 수 있습니다. 즉, 변수의 값은 변경할 수 없지만 객체나 배열 내부의 값은 변경이 가능합니다.
const arr = [1, 2, 3];
arr.push(4); // 가능
arr[0] = 0; // 가능
console.log(arr); // [0, 2, 3, 4]
const obj = { name: 'John', age: 30 };
obj.age = 31; // 가능
console.log(obj); // { name: 'John', age: 31 }2.const로 선언한 변수가 함수인 경우, 해당 함수는 변수를 변경할 수 있는 코드를 포함할 수 있습니다.
이때는 변수의 값이 아닌 변수에 할당된 함수의 내용이 변경되는 것입니다.
const func = () => {
console.log('Hello');
};
func = () => {
console.log('Goodbye'); // 불가능, TypeError: Assignment to constant variable.
};
func(); // Hello
const obj = {
name: 'John',
sayHello: function() {
console.log('Hello, ' + this.name);
}
};
obj.sayHello(); // Hello, John
obj.sayHello = function() {
console.log('Goodbye, ' + this.name); // 가능
};
obj.sayHello(); // Goodbye, John그러나 위의 예제와 같이 const로 변수를 선언할 때 값을 변경하는 것은 일반적으로 권장되지 않습니다.
코드의 가독성과 유지보수성을 위해서는 변경이 필요한 경우 let 또는 var 키워드를 사용해야 합니다.
타입스크립트의 장점
타입 안정성: 코드를 작성할 때 변수, 매개변수, 반환 값 등에 명시적인 타입을 지정하여 오류를 사전에 방지하고 안정성을 높입니다.
IDE 지원: 타입 정보를 활용하여 더 강력한 자동 완성, 오류 감지 및 리팩터링 기능을 IDE에서 제공받을 수 있습니다.
유지보수 용이성: 타입스크립트는 코드의 가독성과 이해를 높이며, 대규모 프로젝트에서 코드베이스를 관리하고 유지보수하는 데 도움이 됩니다.
자체 문서화: 코드 내부에 명시적인 타입 정보를 포함하므로, 코드의 기능과 사용법을 이해하기 쉽고 문서화하기 용이합니다.
ES6+ 기능 지원: 최신 자바스크립트 기능을 활용할 수 있으면서도 추가적인 정적 타입 지원을 제공하여 개발 생산성을 향상시킵니다.
Express
Express는 Node.js를 위한 웹 프레임워크로, HTTP 요청과 응답을 처리하는데 사용됩니다. 이것은 미들웨어를 활용하여 웹 애플리케이션의 라우팅, 요청 처리, 템플릿 엔진 연동 등을 단순화하며, 웹 애플리케이션을 개발하기 위한 핵심 기능을 제공합니다. Express는 가볍고 유연하여 웹 서버를 빠르게 구축하고 관리할 수 있도록 도와줍니다.
NestJS 구조
request - middleware - guard - intercepter - pipe - controller - service - repository - exception filter - intercepter - request
DI와 IOC
NestJS에서는 클래스의 의존성을 외부에서 주입하는 패턴을 사용합니다. 이는 클래스가 필요로 하는 객체를 클래스 내부에서 생성하는 것이 아니라, 외부에서 객체를 주입받아 사용함으로써 모듈성과 유연성을 높입니다.
IOC는 프로그램의 제어 흐름을 역전시키는 개념으로, NestJS에서는 주로 의존성 주입을 통해 구현됩니다. NestJS 프레임워크가 개발자가 작성한 코드 대신에 객체의 생성과 관리를 담당함으로써, 코드의 결합도를 줄이고 유지보수성을 향상시킵니다.
Express와 NestJS의 차이
express 라이브러리이고 nestjs 프레임워크입니다.
RestAPI 란
네트워크 기반의 소프트웨어 아키텍처를 따르는 웹 서비스를 말합니다. 클라이언트와 서버 간의 통신을 위한 규칙과 규약입니다.
RestAPI에서의 rest란
rest는 자원을 표현하는 상태를 전달하는 방식을 의미, 이를 위해 HTTP 프로토콜을 사용
GraphQL
웹 클라이언트가 데이터를 서버로부터 효육적으로 가져오는 것이 목적인 쿼리 언어이고, SQL은 DB 시스템에 저장된 데이터를 효율적으로 가져오는 것이 목적이 쿼리언어
GraphQL과 RestAPI 차이점
GraphQL은 클라이언트가 원하는 데이터를 정확하게 요청할 수 있는 쿼리 언어이자 런타임 환경입니다. REST API와 달리 GraphQL은 단일 엔드포인트로 모든 데이터 요청을 처리하며, 클라이언트가 필요한 데이터의 구조와 양을 명시적으로 요청할 수 있습니다. 이는 네트워크 효율성과 클라이언트 요구에 맞는 유연한 데이터 처리를 제공합니다.
데이터베이스 정규화 비정규화
- 정규화 (Normalization)
정규화는 중복을 최소화하고 데이터를 구조화하여 데이터베이스를 설계하는 과정입니다. 주로 다음과 같은 목적으로 수행됩니다.
데이터 중복 최소화: 중복된 데이터를 최소화하여 저장 공간을 절약하고 데이터 일관성을 유지합니다.
데이터 무결성 유지: 삽입, 갱신, 삭제 시 데이터 일관성을 보장합니다.
쿼리 최적화: 쿼리의 성능을 향상시키기 위해 테이블을 적절히 분리하여 데이터를 관리합니다.
주로 정규화는 제1정규형, 제2정규형, 제3정규형 등의 단계를 거쳐 데이터를 나누고 정리하는 과정을 말합니다.
- 비정규화 (Denormalization)
비정규화는 성능 향상을 위해 데이터베이스 설계에서 정규화된 구조를 조금씩 변경하여 중복을 포함시키는 과정을 의미합니다. 이는 주로 다음과 같은 목적으로 수행됩니다.
조인을 줄이는 것: 더 빠른 조회를 위해 테이블 간의 조인을 줄입니다.
읽기 성능 향상: 복잡한 조인 없이 데이터를 더 빨리 읽고 쓸 수 있도록 합니다.
종합된 데이터: 여러 테이블을 조합하여 하나의 테이블로 만들어 통합된 데이터를 가지게 합니다.
비정규화는 특히 읽기 중심의 작업이 많고, 대량의 데이터를 처리하는 시스템에서 성능을 향상시키기 위해 사용됩니다. 하지만 데이터의 중복성과 일관성 유지에 주의해야 합니다.
데이터베이스에서 사용하는 인덱스란
인덱스(Index)는 데이터베이스에서 검색 속도를 향상시키기 위해 사용되는 데이터 구조입니다. 이는 특정 열(또는 열의 조합)에 대한 빠른 검색을 가능하게 합니다.
간단히 말해, 인덱스는 책의 색인과 유사하게 데이터베이스의 특정 열에 대한 색인을 만들어 빠른 검색을 돕습니다. 이는 데이터베이스에서 데이터를 조회하거나 검색할 때 해당 열에 인덱스가 생성되어 있다면, 데이터베이스가 인덱스를 사용하여 특정 조건에 맞는 데이터를 빠르게 찾아내는 데 도움을 줍니다.
인덱스를 사용하면 데이터베이스가 전체 데이터를 순차적으로 검색하는 것보다 더 빠르게 원하는 데이터를 찾을 수 있으므로 검색 성능이 향상됩니다. 하지만 인덱스를 생성하면 추가적인 저장 공간을 차지하고, 데이터 변경 시 인덱스도 업데이트되어야 하므로 삽입, 수정, 삭제 작업에도 영향을 줄 수 있습니다. 선택적으로 인덱스를 생성하여 쿼리의 성능을 최적화할 수 있습니다.
SQL과 NoSQL의 장단점과 차이점
- SQL (관계형 데이터베이스)
장점:
일관성: ACID(원자성, 일관성, 고립성, 지속성) 트랜잭션을 지원하여 데이터의 일관성을 보장합니다.
정형화된 데이터: 테이블과 스키마를 사용하여 구조화된 데이터를 다루기에 적합합니다.
복잡한 쿼리 지원: 복잡한 쿼리를 작성하고 데이터 간의 관계를 쉽게 표현할 수 있습니다.
단점:
확장성 제약: 수평적 확장이 어렵고, 대규모 데이터 처리에 제한이 있을 수 있습니다.
고정된 스키마: 스키마 변경이 어려울 수 있고, 유연성이 부족할 수 있습니다.
- NoSQL (비관계형 데이터베이스)
장점:
확장성: 수평적 확장이 용이하며, 대용량 데이터 처리에 유용합니다.
유연성: 동적인 스키마를 허용하여 데이터 모델을 유연하게 변경할 수 있습니다.
빠른 속도: 데이터베이스가 단순하고 빠르게 읽고 쓸 수 있습니다.
단점:
일관성 부족: ACID 특성을 완전히 보장하지 않을 수 있습니다.
쿼리 복잡성: 관계형 데이터베이스보다 복잡한 쿼리 작성이 어려울 수 있습니다.
이러한 특성에 따라, SQL은 구조화된 데이터와 복잡한 쿼리가 필요한 경우에 유용하며, NoSQL은 대규모 데이터와 유연성이 필요한 경우에 적합합니다. 선택은 프로젝트의 요구 사항과 데이터 구조에 따라 달라질 수 있습니다.
RDBMS JOIN문의 종류
INNER JOIN:
두 개의 테이블 간에 일치하는 값들을 기반으로 연결합니다. 두 테이블 간에 매칭되는 값이 없는 경우 해당 레코드는 결과에 포함되지 않습니다.
LEFT JOIN (또는 LEFT OUTER JOIN):
왼쪽 테이블의 모든 레코드를 포함하고, 오른쪽 테이블과 일치하는 값이 있는 경우에는 연결합니다. 오른쪽 테이블에 매칭되는 값이 없는 경우에는 NULL로 표시됩니다.
RIGHT JOIN (또는 RIGHT OUTER JOIN):
LEFT JOIN의 반대로 오른쪽 테이블의 모든 레코드를 포함하고, 왼쪽 테이블과 일치하는 값이 있는 경우에는 연결합니다. 왼쪽 테이블에 매칭되는 값이 없는 경우에는 NULL로 표시됩니다.
FULL JOIN (또는 FULL OUTER JOIN):
왼쪽과 오른쪽 테이블 간의 모든 레코드를 포함하며, 양쪽 테이블에서 매칭되는 값이 있는 경우에는 연결합니다. 어느 한 쪽에만 매칭되는 값이 있는 경우에는 NULL로 표시됩니다.
CROSS JOIN:
두 테이블의 카테시안 곱(모든 조합)을 생성합니다. 즉, 왼쪽 테이블의 각 레코드와 오른쪽 테이블의 모든 레코드를 조합하여 결과를 생성합니다. 이는 대규모 데이터셋에서는 사용을 피해야 합니다.
RDBMS KEY 종류
기본 키 (Primary Key):
테이블에서 각 레코드를 고유하게 식별하는 데 사용되는 고유한 식별자입니다. 중복되지 않고, NULL 값을 가질 수 없습니다.
외래 키 (Foreign Key):
다른 테이블의 기본 키를 참조하는 키로, 두 테이블 간의 관계를 설정하는 데 사용됩니다. 부모 테이블의 기본 키를 자식 테이블의 외래 키로 설정하여 참조 관계를 유지합니다.
대체 키 (Alternate Key):
기본 키가 아니지만 레코드를 고유하게 식별할 수 있는 키입니다. 데이터베이스에서 기본 키로 사용할 수 있는 후보키(Candidate Key) 중에서 선택된 대안으로 사용될 수 있습니다.
고유키 (Unique Key):
중복 값을 허용하지 않는 키로, 해당 열에 대해 유일한 값을 갖도록 보장합니다. 기본 키가 아니지만 중복을 방지하는 데 사용됩니다.
슈퍼 키 (Super Key):
릴레이션 내의 모든 튜플을 유일하게 식별할 수 있는 키로, 하나 이상의 열로 구성됩니다. 슈퍼 키는 후보키나 기본 키를 포함할 수 있습니다.
Docker란
도커(Docker)는 컨테이너 기반 가상화 플랫폼으로, 애플리케이션을 손쉽게 개발, 배포, 실행할 수 있도록 도와주는 기술입니다. 도커를 사용하면 애플리케이션과 그에 필요한 모든 환경을 컨테이너에 패키징하여 동일한 환경에서 동작하도록 만들 수 있습니다. 이를 통해 개발과 운영 환경의 일관성을 유지하고, 확장성과 이식성을 향상시킬 수 있습니다.
Docker와 가상OS의 차이점
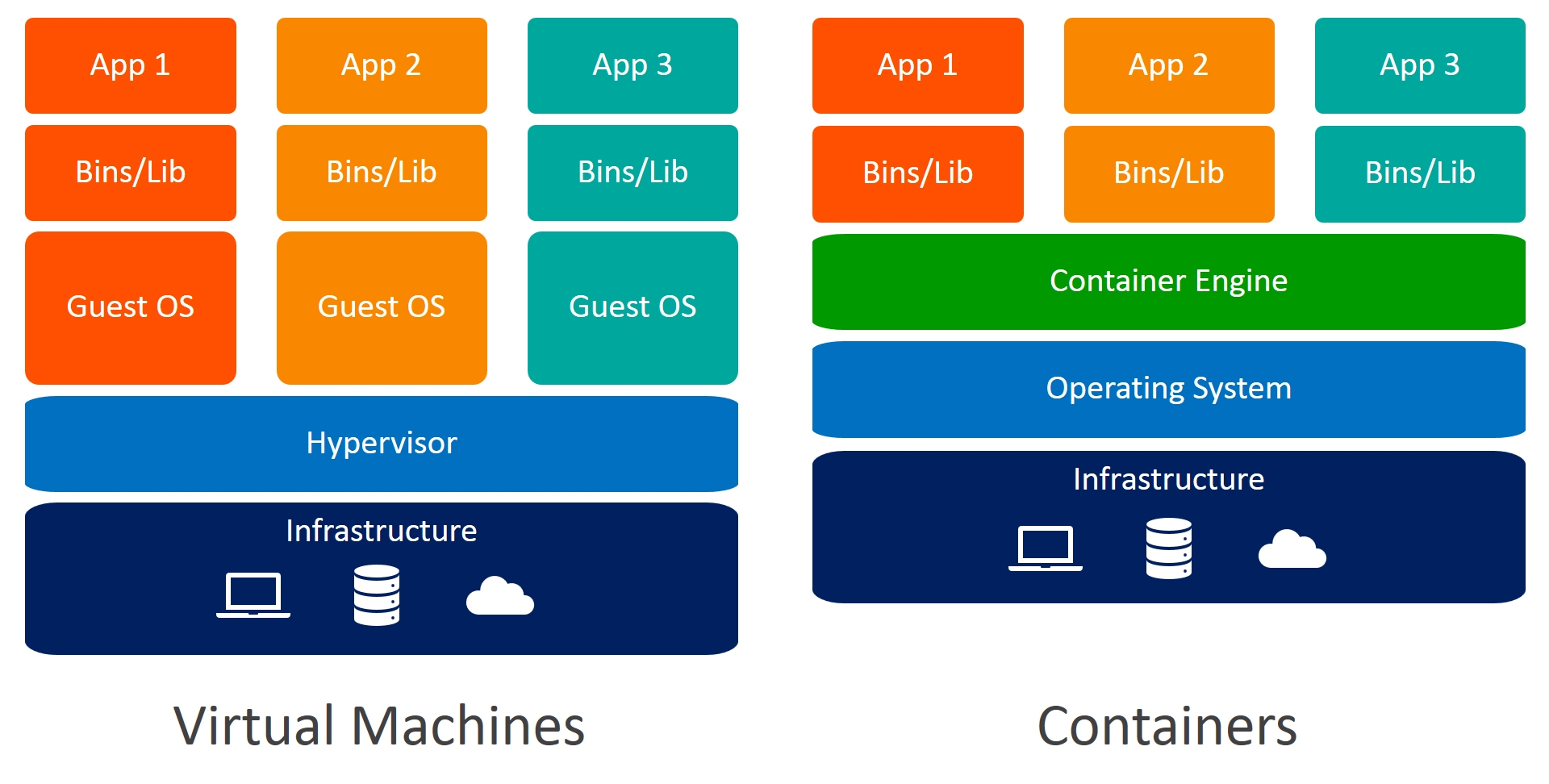
AWS 배포를 어떻게 진행하는지
계정 및 서비스 설정:
AWS 계정 생성 및 로그인 후, 필요한 서비스(예: EC2, S3, RDS 등)를 설정하고 필요한 권한을 부여합니다.
인프라 구성:
EC2 인스턴스나 컨테이너 서비스(ECS 또는 EKS), 혹은 서버리스(AWS Lambda) 등을 선택하여 애플리케이션을 호스팅할 인프라를 설정합니다.
애플리케이션 배포:
웹 애플리케이션의 경우, 배포 파일을 EC2 인스턴스에 업로드하거나 Docker 이미지를 Amazon ECR(Elastic Container Registry)에 푸시하고, 해당 이미지를 ECS 또는 EKS 클러스터에 배포합니다.
로드 밸런싱 및 Auto Scaling 설정:
Elastic Load Balancer(ELB)를 통해 트래픽을 분산하고, Auto Scaling을 설정하여 트래픽 증가 시 자동으로 인스턴스를 추가하거나 감소시켜 확장성을 유지합니다.
데이터베이스 및 저장소 연결:
필요한 경우 RDS(Relational Database Service)나 DynamoDB와 같은 데이터베이스 서비스를 설정하고, S3와 같은 저장소 서비스를 연결하여 데이터를 저장합니다.
보안 및 모니터링 설정:
IAM(Identity and Access Management)을 사용하여 보안을 강화하고, CloudWatch 등의 모니터링 도구를 설정하여 시스템 상태를 모니터링하고 로그를 관리합니다.
도메인 연결:
Route 53을 사용하여 도메인을 연결하고, SSL/TLS 인증서를 적용하여 HTTPS 프로토콜을 통한 보안 통신을 설정합니다.
배포 및 테스트:
배포 파이프라인을 구축하여 CI/CD 도구를 통해 자동화된 배포를 설정하고, 테스트 환경을 통해 신뢰성 있는 배포를 확인합니다.
객체지향 프로그래밍의 4가지 특징과 5가지 원칙
캡슐화 (Encapsulation):
데이터와 해당 데이터를 다루는 메서드를 하나로 묶어 외부에서의 접근을 제한하여 정보 은닉과 보안을 강화합니다.
상속 (Inheritance):
부모 클래스의 특성과 기능을 자식 클래스가 물려받아 재사용하고 확장하여 코드의 재사용성과 확장성을 높입니다.
다형성 (Polymorphism):
같은 이름의 메서드나 함수를 다양한 방식으로 동작하도록 하는 특성으로, 오버로딩(Overloading)과 오버라이딩(Overriding)을 통해 구현됩니다.
추상화 (Abstraction):
복잡한 시스템이나 개념을 단순화하여 모델링하고, 필요한 부분만을 추출하여 표현함으로써 핵심적인 부분에 집중할 수 있도록 도와줍니다.
- SOLID 원칙
단일 책임 원칙 (Single Responsibility Principle, SRP):
클래스는 단 하나의 책임만 가져야 하며, 변경의 이유는 하나여야 합니다.
개방-폐쇄 원칙 (Open/Closed Principle, OCP):
확장에는 열려 있고, 수정에는 닫혀 있어야 합니다. 기존의 코드를 변경하지 않고도 새로운 기능을 추가할 수 있도록 합니다.
리스코프 치환 원칙 (Liskov Substitution Principle, LSP):
서브 타입은 언제나 자신의 기반 타입으로 교체할 수 있어야 합니다. 즉, 하위 클래스는 상위 클래스의 기능을 변경하지 않고 확장할 수 있어야 합니다.
인터페이스 분리 원칙 (Interface Segregation Principle, ISP):
클라이언트는 자신이 사용하지 않는 인터페이스에 의존하도록 강요받지 말아야 합니다. 즉, 큰 덩어리의 인터페이스보다 작고 구체적인 여러 개의 인터페이스가 더 좋습니다.
의존성 역전 원칙 (Dependency Inversion Principle, DIP):
고수준 모듈은 저수준 모듈에 의존해서는 안 되며, 둘 모두 추상화된 것에 의존해야 합니다. 추상화된 것은 세부 사항에 의존하면 안 됩니다.
객체지향 프로그래밍의 장단점
장점:
재사용성: 클래스와 객체를 사용하여 코드를 모듈화하고, 이를 재사용할 수 있어 개발 속도와 효율성을 향상시킵니다.
유지보수성: 코드의 가독성이 높아져 수정과 확장이 쉬워집니다. 객체 지향은 코드를 캡슐화하고 모듈화하여 유연성을 높여줍니다.
추상화 및 상속: 추상화를 통해 현실 세계를 모델링하고, 상속을 통해 코드의 재사용성을 높이며, 계층 구조를 만들 수 있습니다.
코드의 구조화: 객체지향은 객체 간의 관계를 구조화하여 설계하므로, 복잡한 시스템을 더 명확하고 체계적으로 만들 수 있습니다.
단점:
학습 곡선: 객체지향의 개념을 이해하고 익히는 데 시간이 걸립니다. 초기에는 프로그래밍하는 데 더 많은 시간이 필요할 수 있습니다.
자원 소모: 클래스와 객체의 생성, 관리 등에 따른 오버헤드가 있을 수 있습니다. 일부 경우에는 성능 저하를 가져올 수 있습니다.
복잡성: 잘못된 설계나 너무 많은 객체화는 코드의 복잡성을 증가시킬 수 있습니다. 유연성이 과도하게 증가할 경우에는 코드 이해를 어렵게 만들 수 있습니다.
객체지향형 프로그래밍, 함수형 프로그래밍
객체지향 프로그래밍은 프로그램을 객체들의 모임으로 바라보는 개념입니다. 이 객체들은 데이터와 그 데이터를 조작하는 메소드(함수)로 구성됩니다. 이 패러다임은 클래스(class)를 사용하여 객체를 정의하고, 상속(inheritance), 다형성(polymorphism), 캡슐화(encapsulation)와 같은 개념을 활용하여 코드를 구조화합니다.
반면에 함수형 프로그래밍은 함수를 주요한 구성 요소로 삼는 패러다임입니다. 함수를 변수에 할당하거나 함수를 인자로 전달받고, 함수를 반환하는 등의 기능을 강조합니다. 또한, 함수형 프로그래밍은 상태 변경이나 가변 데이터보다는 불변성(immutable data)과 순수 함수(pure functions)를 중요시합니다. 이는 함수의 입력값만을 사용하여 결과를 반환하고, 부작용(side effects)이 없도록 하는 것을 의미합니다.
두 패러다임은 각각의 장단점을 가지고 있습니다. 객체지향 프로그래밍은 구조화된 코드를 유지보수하기 쉽게 만들어주고, 함수형 프로그래밍은 병렬 처리와 상태 관리에 유용합니다. 종종 이 두 패러다임을 혼합하여 사용하기도 하는데, 이를 함수형 객체지향 프로그래밍(Functional OOP)이라고 부르기도 합니다.
HTTP vs HTTPS
보안:
HTTP: 데이터가 평문으로 전송되기 때문에 보안성이 낮고, 중간에서 데이터를 쉽게 엿볼 수 있습니다. HTTPS: 데이터를 암호화하여 전송하기 때문에 보안성이 높습니다. 중간에서 데이터를 엿볼더라도 암호화되어 있어 민감한 정보를 보호합니다.
암호화:
HTTP: 데이터가 암호화되지 않아서 민감한 정보(비밀번호, 신용카드 정보 등)를 전송할 때 취약합니다. HTTPS: SSL/TLS 프로토콜을 사용하여 데이터를 암호화하므로, 중간에 누군가가 가로채도 복호화하지 못합니다.
프로토콜:
HTTP: 웹 브라우저와 웹 서버 간의 텍스트 데이터를 주고받는 표준 프로토콜입니다. HTTPS: HTTP 프로토콜 위에 SSL/TLS 암호화 프로토콜을 추가한 것으로, 보안 강화를 위해 사용됩니다.
HTTP는 주로 정보를 공개적으로 전송할 때 사용되고, HTTPS는 민감한 정보 전송이 필요할 때 사용됩니다. HTTPS를 사용하면 데이터의 안전성과 보안을 확보할 수 있습니다.
- SSL 인증서에서 SSL이란?
SSL(Secure Sockets Layer) 인증서는 웹사이트와 브라우저 간의 통신을 암호화하고 보안을 제공하는 디지털 인증서입니다. 이 인증서는 웹사이트가 신뢰할 수 있는 서버임을 증명하고, 브라우저와의 안전한 통신을 가능하게 합니다.
간단하게 말하면, SSL 인증서는 브라우저와 웹 서버 사이의 통신을 암호화하여 외부의 누군가가 정보를 엿보거나 조작하는 것을 방지하며, 사용자들에게 웹사이트가 안전하다는 것을 보장해줍니다. 사용자가 웹사이트에 접속할 때 녹색 잠금 아이콘이 표시되면 SSL 인증서가 적용된 것입니다.
프로젝트간 본인이 맡은 기능들에 대한 설명
알아서 잘 말하기
쿠키와 세션의 차이
- 쿠키와 세션을 사용하는 이유
- HTTP 프로토콜의 특징
- 쿠키란?
- 세션이란?
- 쿠키와 세션의 차이
JWT에 대한 설명과 JWT를 활용하여 본인이 프로젝트에서 어떻게 사용했는지?
알아서 잘 말하기
Package.json에서 Dependencies와 devDependencies의 차이
dependencies:
dependencies에 명시된 패키지는 프로덕션 환경에서 실행되는 데 필요한 패키지입니다. 즉, 애플리케이션을 실행하는 데 필수적인 라이브러리와 모듈이 여기에 포함됩니다.
devDependencies:
devDependencies에 명시된 패키지는 개발 환경에서만 필요한 패키지입니다. 주로 테스트, 개발 서버 또는 빌드 도구 등 개발 과정에 필요한 라이브러리와 모듈을 여기에 추가합니다. 이 패키지들은 애플리케이션을 배포하거나 실행하는 데 직접적으로 필요하지 않습니다.
간단히 말하면, dependencies는 애플리케이션의 실행에 필수적이고, devDependencies는 개발과정에서만 필요한 패키지들을 관리하는 데 사용됩니다. dependencies는 프로덕션 환경에서, devDependencies는 개발 환경에서 사용됩니다.
