
📕 1교시
📜 복습
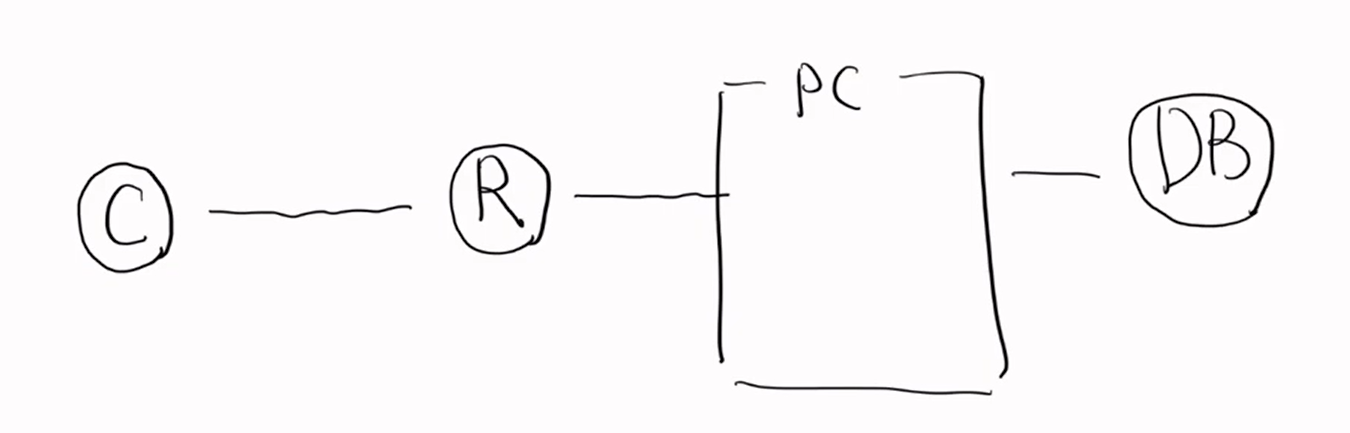
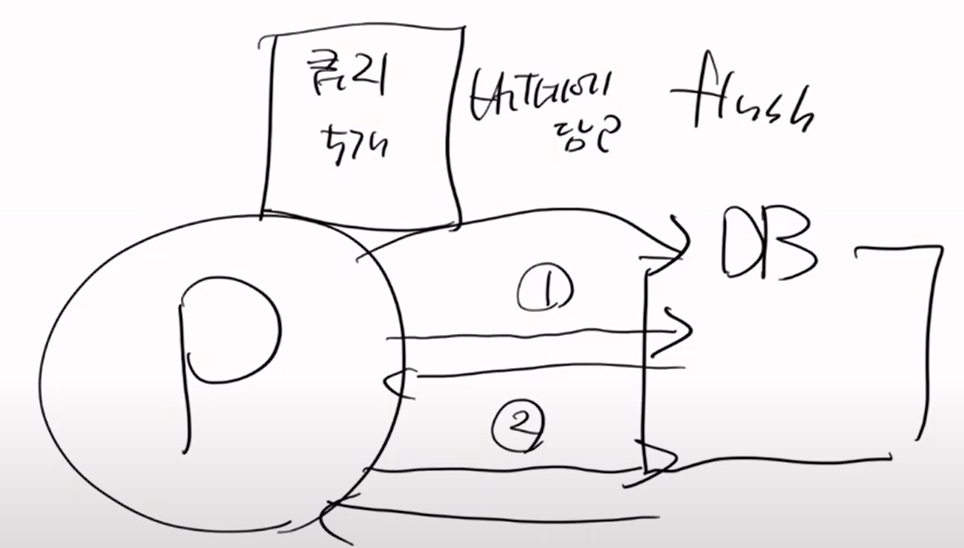
하이버네이트가 있다. 컨트롤러 - 레포지토리 - PC - DB 이렇게 있다.

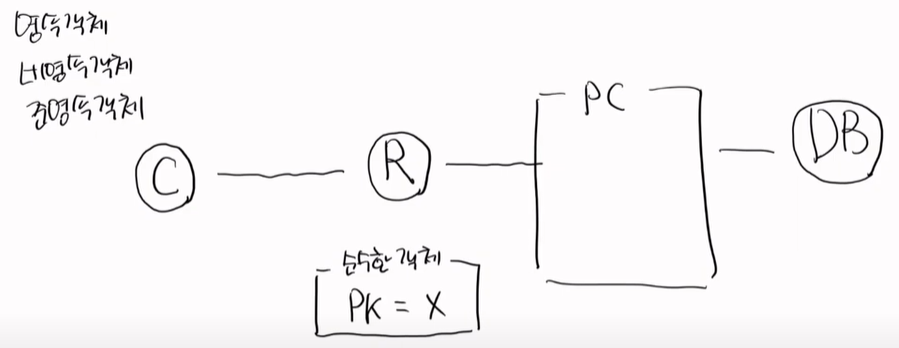
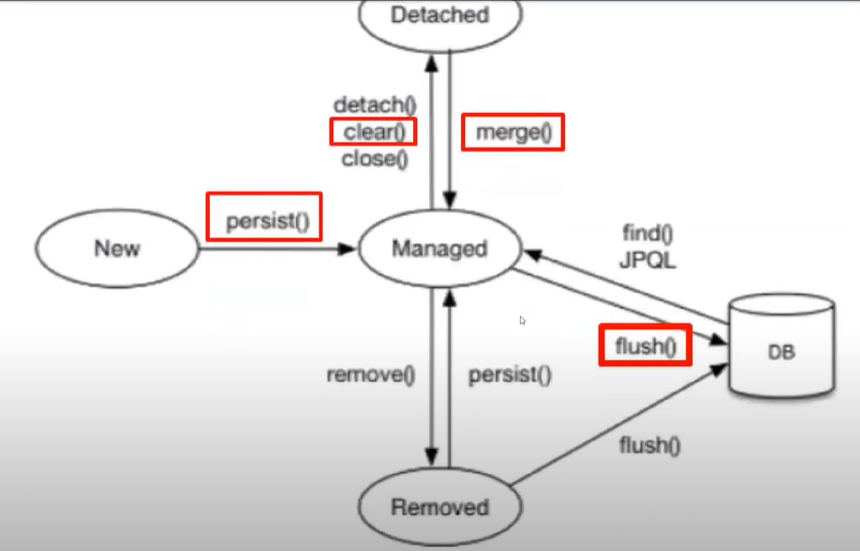
여기서 영속객체, 비영속객체, 준영속 객체가 있다. 이 객체들의 조건을 @Entity가 있어야 이 3가지 중에 하나가 된다.
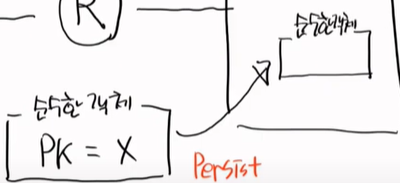
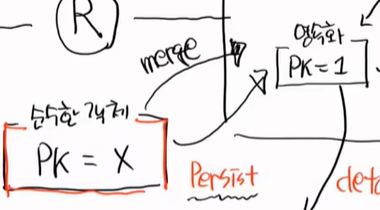
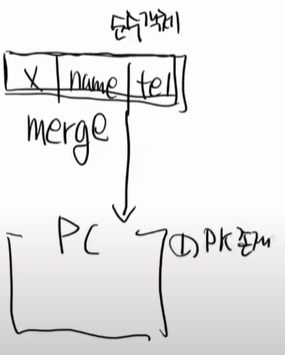
일단 순수한 객체가 하나가 있다. 순수한 객체는 PK가 없는 것이다.
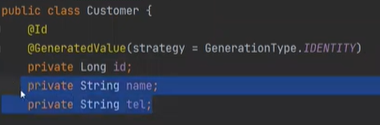
id가 없고 name, tel만 있는 상태이다.
순수한 객체를 PC에 넣는 것을 Persist라고 한다. 영속화이다.
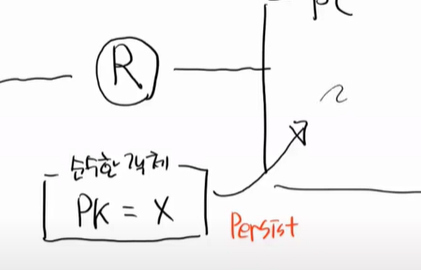
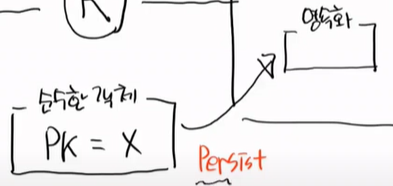
이 순수한 객체가 그대로 들어왔지만 아직도 순수한 객체이다.
이것을 영속화 되었다고 하고, 영속객체가 되지는 않았다. 영속객체가 되기 위해서는 PK가 있어야 한다.
이 상태에서 Persist를 하면 flush를 한다. insert문이 날라가고 응답을 받는다. 이것을 동기화 된다고 한다.
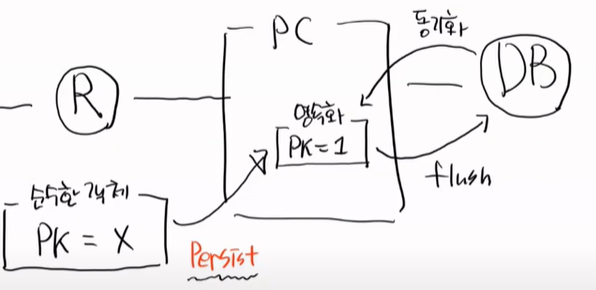
왜냐하면 PC 입장에서는 PK를 알지 못한다. 이떄 순수한 객체가 영속객체가 된다.
조건은 @entity + PC 내부에 존재 + PK 존재 + 디폴트생성자 가 있어야 한다.

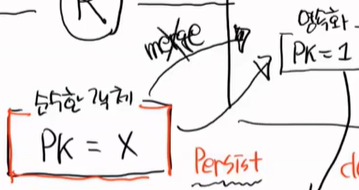
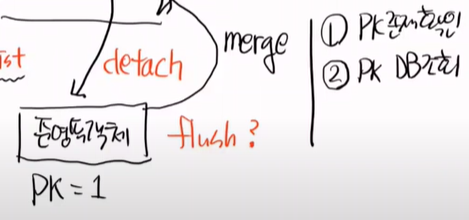
준영속 객체를 이야기 해보자. 준영속이 무엇일까? 영속화 되어있는 영속객체를 밖으로 꺼내는 것이다.
이 행위를 detach라고 하고 이렇게 되면 준영속객체가 된다.
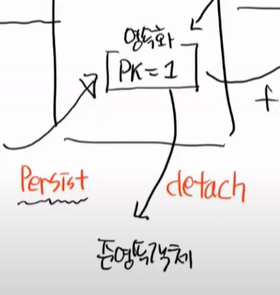
em.detach를 하면된다.

밖으로 뺐다는 것은 clear한 것과 같다. 그러면 준영속 객체는 flush가 먹을까?
안된다.
왜냐하면 더이상 영속객체가 아니기 때문에 PC가 관리를 하지 않기 떄문이다.
우리는 준영속객체를 다룰일이 없다. 개념만 이해하자
자 생각해보자
순수한 객체를 PC에다가 merge를 할 수 있다. 병합이다.
그러면 순수한 객체는 어떻게 될까?
아무일도 일어나지 않는다. 왜냐하면 PK가 없기 때문이다. merge라는 것은 PK를 들고 있어야 일어난다.
하지만 PK가 없기 떄문에 불가능하다.
그러면 준영속객체는 merge가 될까? 된다. 왜냐하면 PK가 있기 떄문이다.
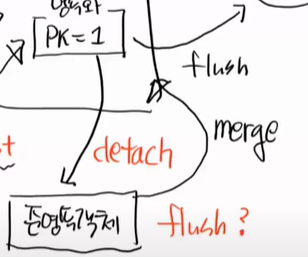
merge를 한다는 것은 1번으로 스스로의 PK존재여부를 확인한다.
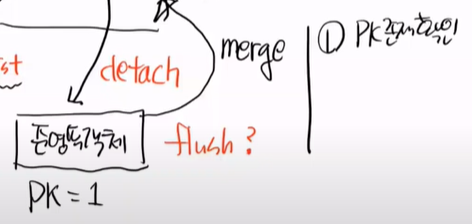
있으면, 2번으로는 해당 PK로 DM내부를 조회한다. 진짜 있는지 없는지 확인 하기 위해서이다.
왜 조회하는지 생각해보자

일단 순수한 객체가 있고 그것을 우리는 set해서 강제로 id = 3으로 만들 수 있다.
이상태에서 merge를 하면, DB에 조회를 해보고 없기 때문에 터지게 된다.

detach를 해서 준영속객체를 만들고 바꾸면, PK존재 확인, DB 조회, 3번으로는 트렌젝션 종료시점에 flush를 한다.

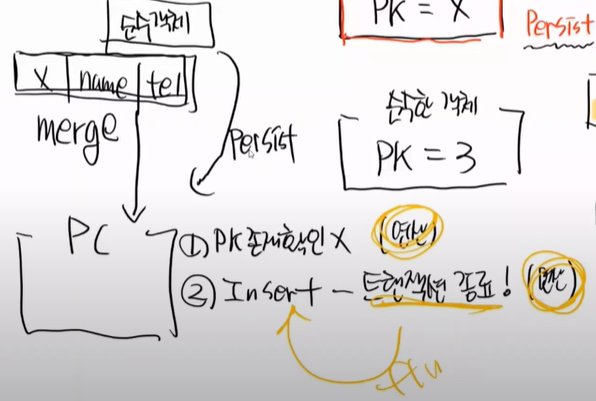
merge는 다른 일도 한다. 먼저 그림을 보자
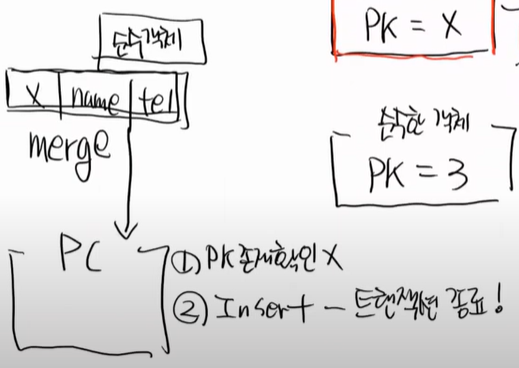
먼저 PK 존재를 하고, 없으면 바로 insert를 한다.
즉, merge는 2가지 일을한다.
PK가 있는 준영속 객체를 merge를 하면 PK 존재여부 확인, DB존재여부 확인, 마지막에 트렌젝션 종료시점에 update를 한다.
근데 PK가 없는 순수한 객체를 merge를 하면 PK존재여부 확인, 트렌젝션 종료시에 insert를 한다.
이제 코드를 보자
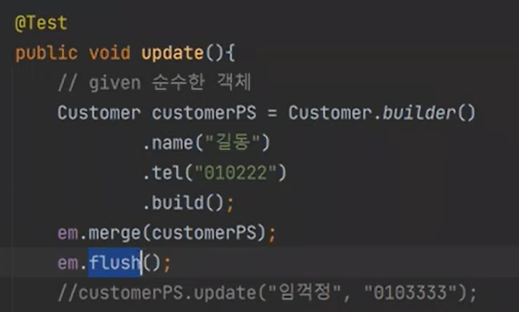
PK가 없기 떄문에 아주 순수한 객체이다.
merge를 하고 flush를 하면 insert가 된다. 먼저 beforeach로 실행한 구문이 보인다. 그다음에 insert를 한다.
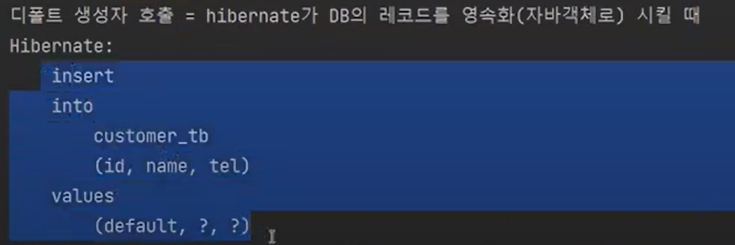
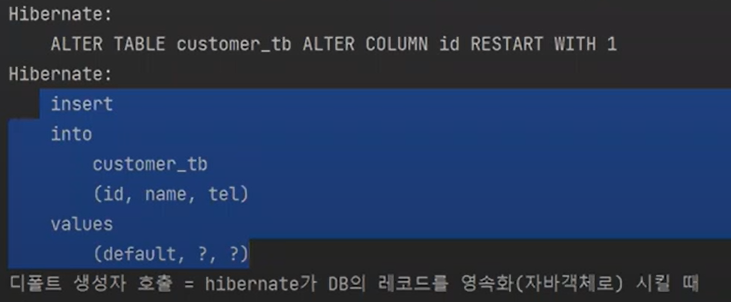
merge는 update or insert를 하는 것이다.
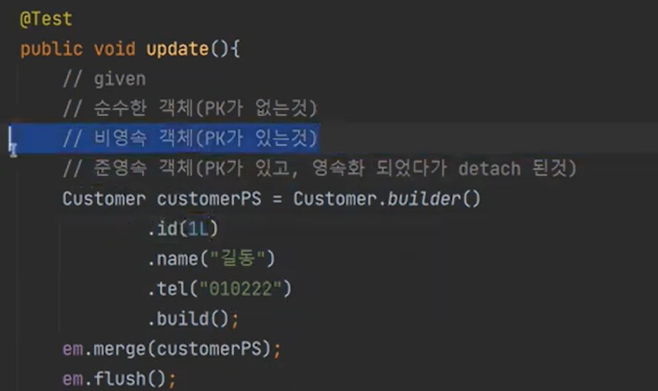
지금은 순수한 객체가 아니라 비영속 객체이다.
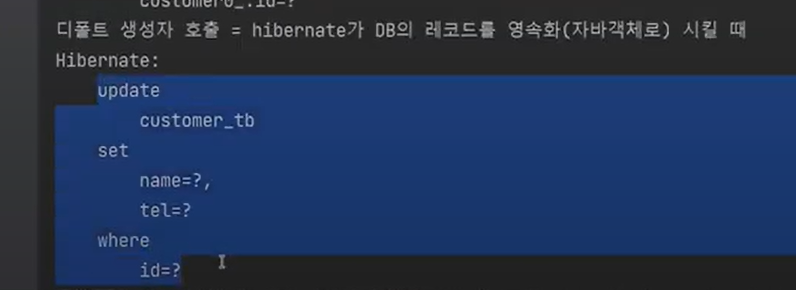
update가 날라간다.
보면 전부 트렌젝션 종료시점에 날라간다. 그래서 쿼리가 날라가는 것이다.
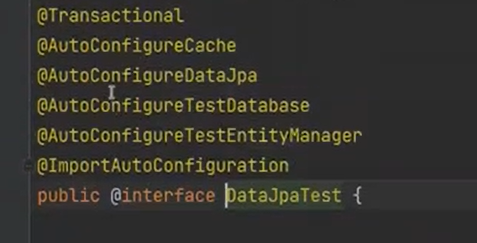
DataJpaTest는 내부적으로 트렌젝션을 가지고 있다. 그래서 단위 테스트를 할 떄마다 마지막에 무조건 rollback이 된다.
그래서 제대로 할려면 직접 flush를 터트려야 한다. 아니면 테스트를 제대로 하지 못한다.
그리고 영속객체가 무엇일까?
영속성 컨텍스트 안에있는 것이다. PK O + 영속화 된것

merge는 2가지 일을 한다. PK가 있는지 없는지를 판단하는 연산을 하고, 트렌젝션 종료시점에 연산을 한다. 쓸데없는 연산이 2개나 있다.
이 순수한 객체를 merge하지 않고 persist를 하면? 그냥 영속성 컨텍스트에 들어가고 flush가 되어서 DB에 저장이 된다.
쓸데없이 연산을 2번 하면 안된다.
즉, 순수한객체는 Persist를 날리고, 영속객체는 수정시
예를 들어 이렇게 변경해달라고 컨트롤러가 받았다.
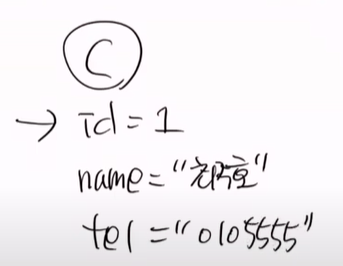
우리들은 이것을 그대로 비영속 객체로 만들 수 있다. 왜냐하면 우리가 PK를 알기 떄문이다.
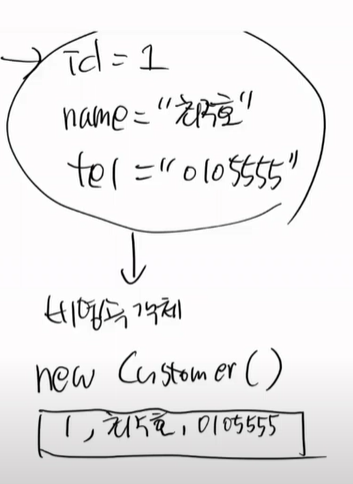
이렇게 new Customer()를 해서 변경하고자 하는 값을 넣으면 그만이다.
비영속 객체는 순수한 객체에서 PK만 들고 있는 상태이다. 영속화가 단 한번도 되지 않은 것을 의미한다.
비영속 객체는 신뢰할수 없는 객체이다. 왜냐하면 DB에 1번이 없을수도 있기 떄문이다.
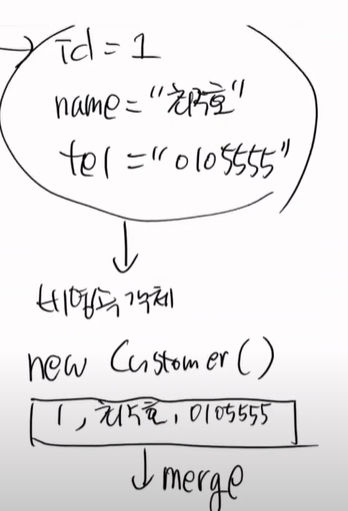
다음과 같은 상태에서 merge를 하면, PK 존재 확인, DB 존재확인 -> 이부분에서 터지게된다.
비영속객체는 만들지 말자
따라서 변경해달라는 요청이 오면, 먼저 영속화를 시켜야한다. 즉, 조회를 먼저 해야하는 것이다.

3번이라는 것을 먼저 DB에서 영속화 컨테이너로 넣어야하는 것이다.
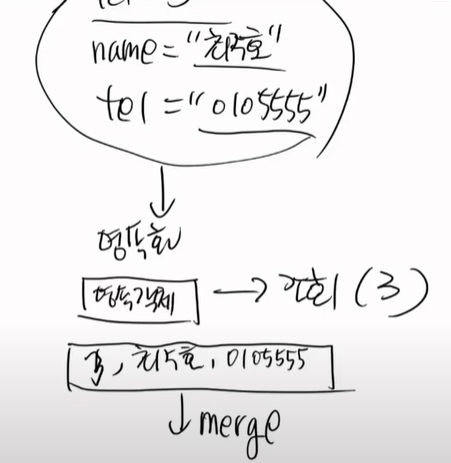
이게 신뢰할 수 있는 데이터이다.
여기서 알 수 있는 점은 영속객체가 있다는 것은 DB에 있다는 것이고, 영속객체가 없으면 DB에 없다는 것을 의미한다. 따라서 merge를 터트릴 필요도 없는 것이다.
그래서 update는 조회를 가장 먼저하고, 있으면 수정을 하고, flush를 하면된다.
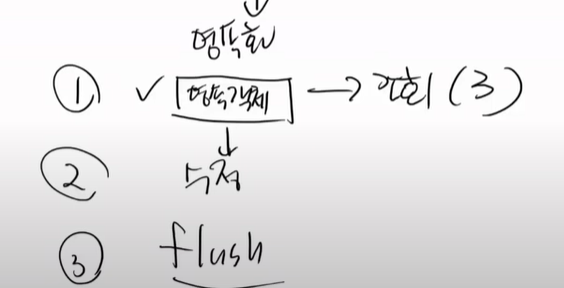
그냥 merge는 쓰지말자, 개념만 이해하면 된다
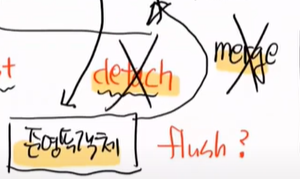
detach랑 merge는 사용할 일이 거의 없다.
정리하면 save할 떄는 persist를 사용한다. 이 persist가 되는 객체는 순수한 객체만 가능하다.
PK가 있는 비영속객체를 만들 필요가 있을까? 없다 신뢰할 수 없기 때문에
update의 경우
id = 1이 날라오면, 조회를 먼저하고, 영속객체로 만들고, 영속객체를 수정하고, flush하면 된다. merge를 할 필요가 없다.
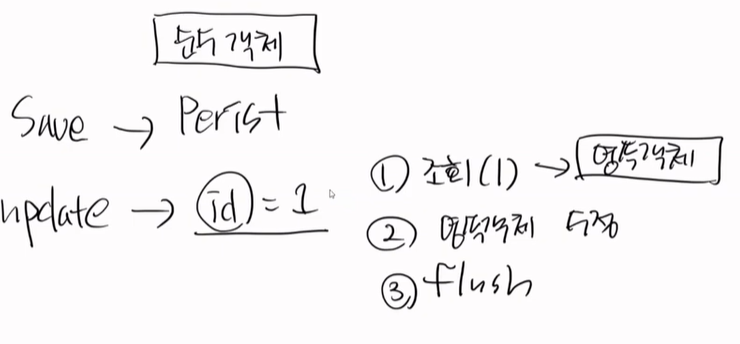
잠시 트렌젝션 맛을 보자
원하는 곳에 붙이면

포인트는 마지막에 변경이 감지되는 경우만 flush를 해준다는 것이다. 그럼 누구의 변경을 의미할까? 영속객체의 변경을 의미한다.
정리하면 save는 persist, update는 2번의 조회 후, flush를 한다. 그리고 flush는 트렌젝션 종료시에 일어난다.
하지만 테스트를 할때는 하나하나 잘 돌아가나 확인을 해봐야한다. 그래서 em.clear 또는 em.flush를 사용해보는 것이다.

내 입장에서는 이 부분은 트렌젝션을 종료하는 부분을 의미한다. 변경감지는 테스트코드일 떄 개발자가 스스로 하는 것이다.
예를 들어
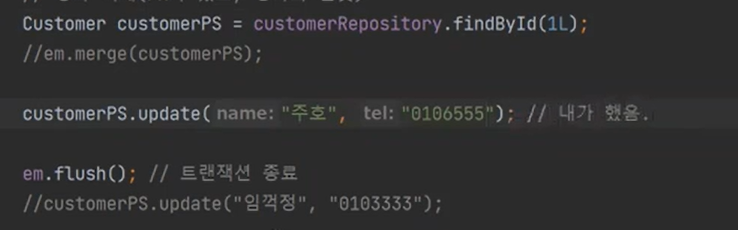
다음과 같이 findById로 영속화를 시키고, update를 하는 것 모두 내가 한것이다.
따라서 개발자 입장에서는 변경감지가 있었으니까 flush를 하는 것이다.
이런식으로 테스트를 해보는 것이다.
전체적으로 돌 경우는 이렇게 된다.
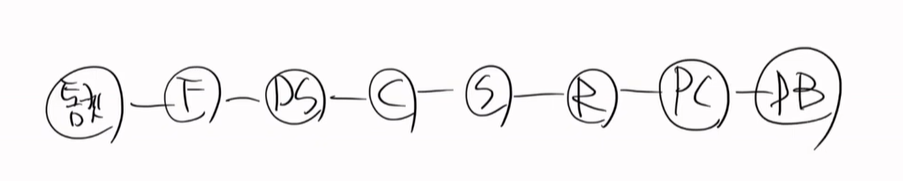
트렌젝션의 시작시점과 종료시점은
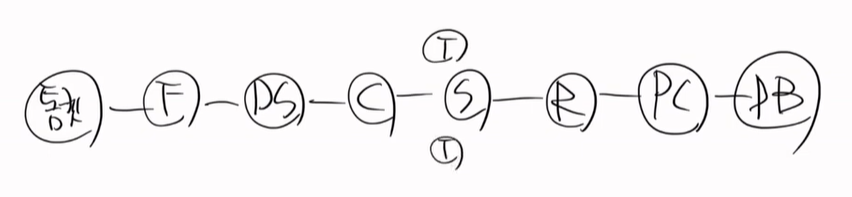
DB 세션의 시작은
종료 시점은

우리는 배울게 많이 남았어서, 트렌젝션떄문에 머리를 아파하지 말자.
나중에 OSIV를 설명할때 알게 될 것이다.

일단은 트렌젝션은 해당 부분에서 열고 닫힌다고 생각을 하자
우리가 JDBC 할때는 적을게 많았다. 나중에 join을 계속하면 난리가 난다.
근데 이 똑같은 코드들이 hibernate로 오는 순간 매우 짧아진다.
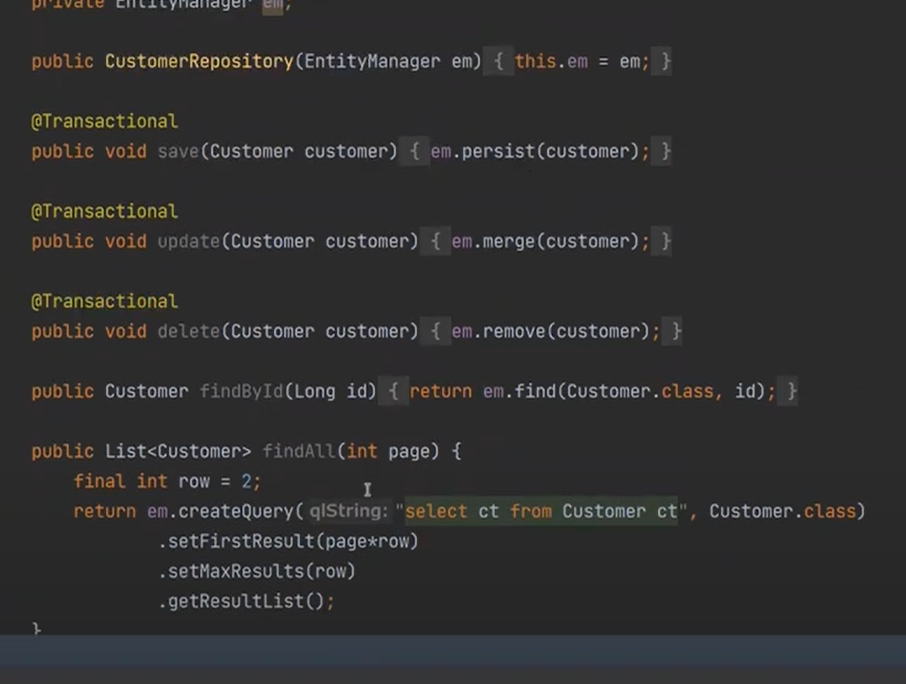
근데 이것을 nativequery로도 작성이 가능하다.
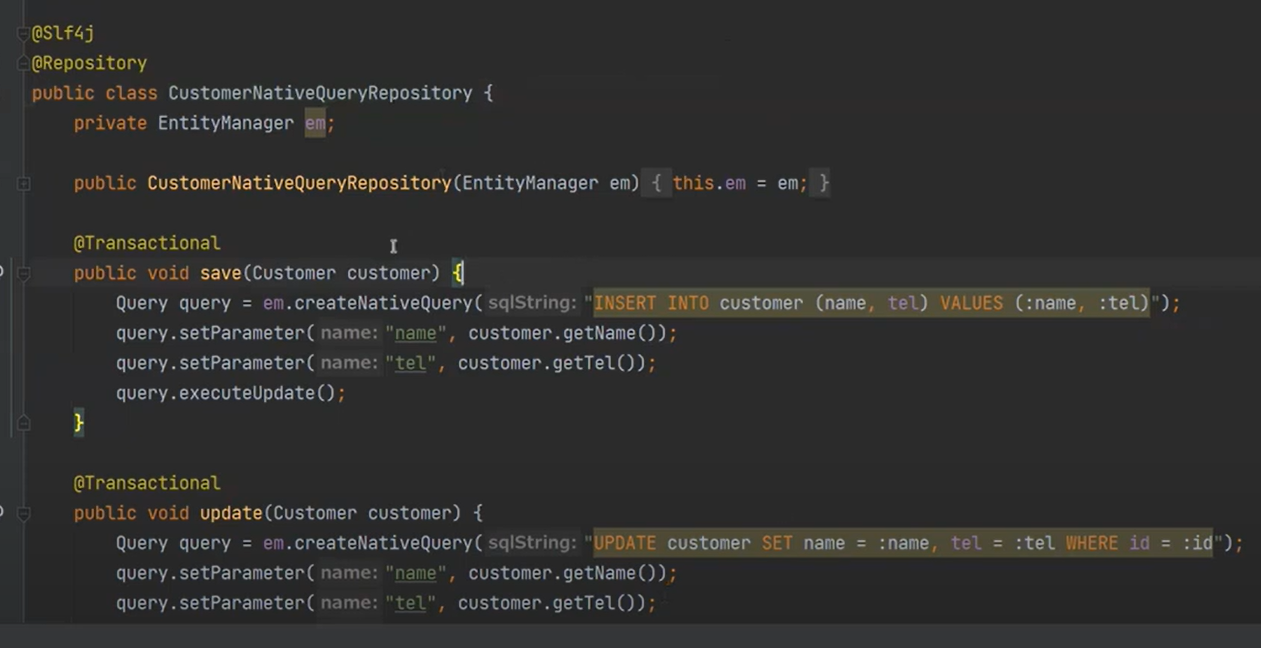

실제 쿼리를 적고, 쿼리를 리턴받고, :name, :tel 부분을 setParameter로 설정(바인딩)을 해준다.
그리고 마지막에는 executeUpdate(insertm delete update에만 사용)를 한다.
update도 마찬가지이다.

JDBC랑 똑같다.
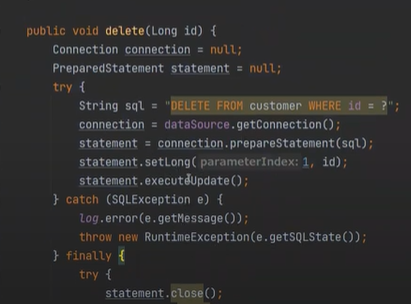
delete도 똑같다

findById를 보면

em.findById를 하지 않았다. createNativeQuery로 직접 쿼리를 만들었다. 단지 마지막에 1건만 return한다는 것을 적는다 그리ㅗ 다운케스팅을 해야한다.

findAll

이거는 모두 사용할 일이 있다. 예를들어 복잡한 통계 쿼리를 짤때 native쿼리를 짜는데, 하이버네이트와 JPQL을 사용하지 않을 때 사용한다.
쿼리를 알아야 JPA를 할 수 있다.
길이를 비교해보자, JDBC
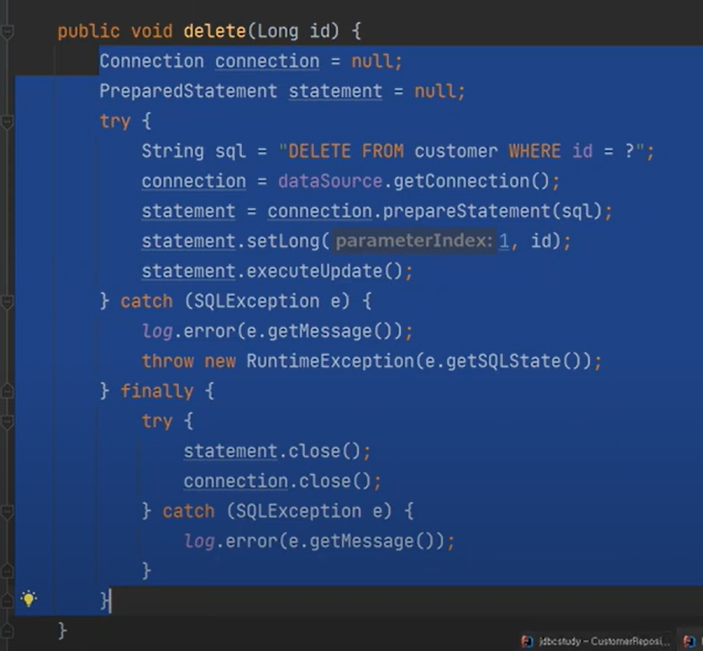
NativeQuery

뭐가 생략된 것일까? 비교해보자
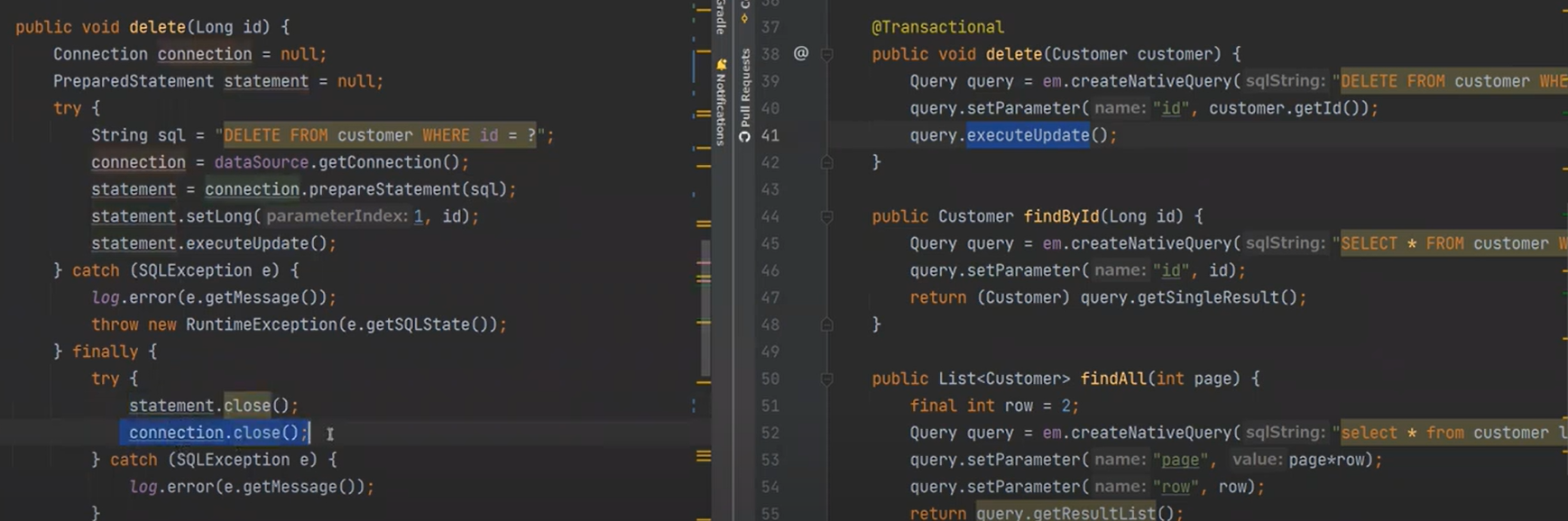
하지만 hibernate를 보자, 정말 간단하다
이것보다 짧은 것을 2교시때 해볼 것이다.
📕 2교시

하이버네이트는, repo, datebase 사이에서 자바와 BD 세상을 단절시키는 역할을 한다.
Orm은 이해해야할것이 많기 떄문에 패스~

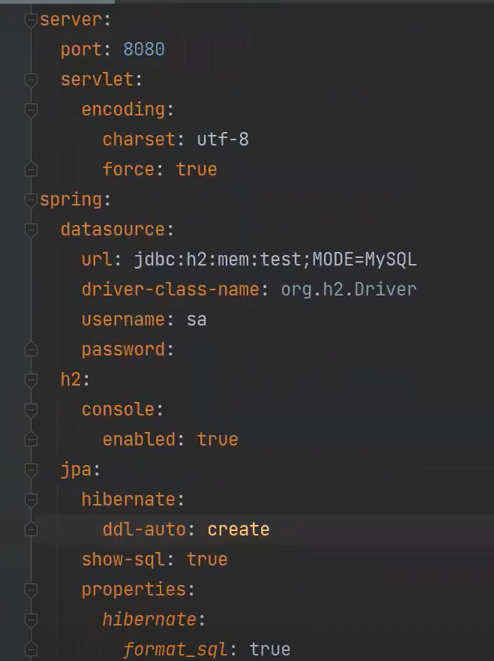
의존성은 h2를 사용하는 이유 인메모리데이터여서


application.yml -> 모드 변경이 가능하다, 따라서 h2가 편하다
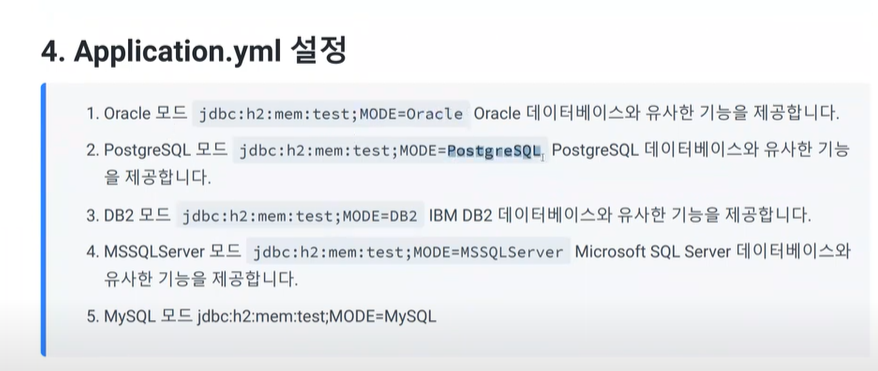
이러한 것들을 방언 이라고한다. 사투리이다. 형태는 비슷하다
방언설정


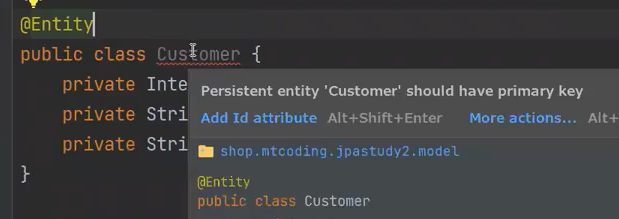
Entity를 붙이면 하이버네이트가 관리하고, ddl-auto가 create로 설정되어있으면 테이블이 설정되는데 테이블을 만들려면 PK가 필요하다
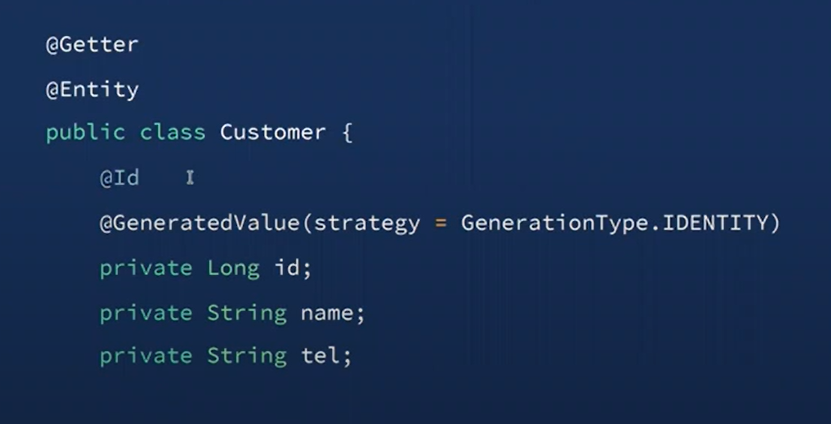
다른 것들을 사용하고 싶으면

지금은 공부하지 말자, 형태는 비슷하기 때문에
그리고 네이티브 쿼리를 짤 수 있다. JDBC 보다 훨씬 편하다.
하지만 쿼리를 작성하는 게 숙련이 되어있으면, JPQL을 사용안할 이유가 없다.

JPQL은 기본적으로 CRUD에서는 사용하지 않고, findAll 할때만 사용하면 된다.
나머지는 하이버네이트에서 제공해주는 것들이다.
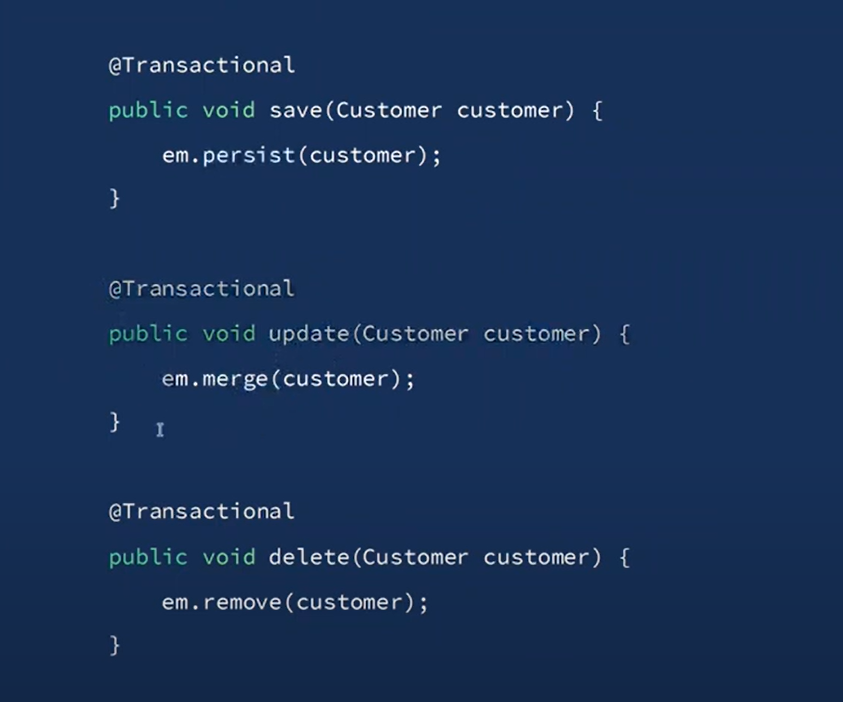
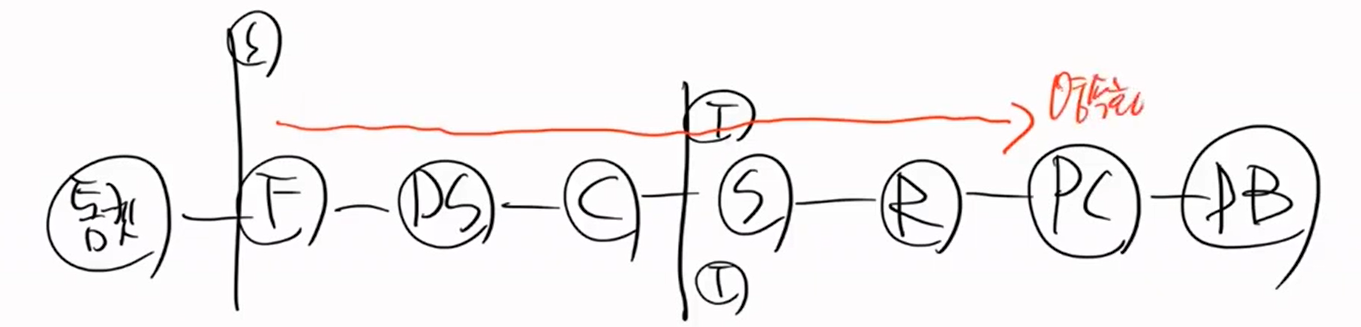
영속화


순수한 객체는 PK가 없는 것, 비영속객체는 PK가 있을수도, 없을 수도 있다.

비영속 객체는 내가 직접 new한 것이다. 비영속 객체 사용 X
준영속 객체는?

방법에는

다음에는 영속객체


영속화는 됬지만 flush가 되지 않았다는 것이다. 즉, 동기화 되지 않았다는 것이다.
아직 DB에는 들어가지 않았다. flush가 되야 DB에 들어간다. flush 전까지는 PK가 존재하지 않는다.(없을 수도 있다)
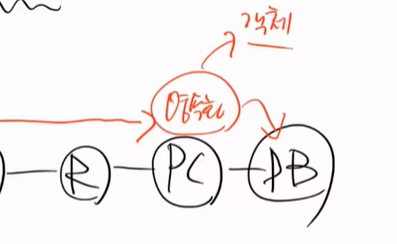
나중에 배울 내용이지만
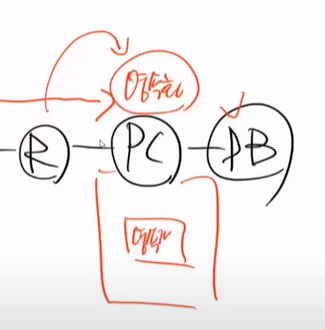
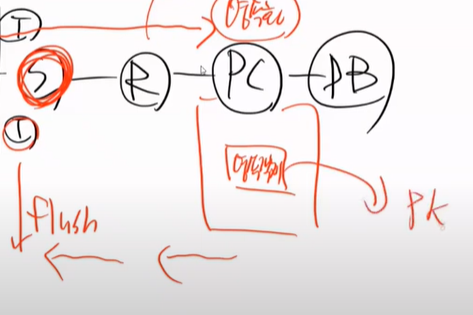
영속화가 되면 DB로 가지도 않는다. Repo로 바로 돌아간다. 마지막 트렌젝션 종료시에 flush가 되고 그때 pK가 생기게 된다.

모든 영속성 컨테이너에서 전부 제거하는 것
save -> persist / update -> 영속화 -> flush (기억)
new 해서 비영속 객체를 만들 수 있다. 이상태에서 persist를 하면 영속화가 된다. 영속화가 됬다고해서 DB에 들어간 것은 아니기 때문에 flush를 해야한다.
flush를 하지 않으면 insert 쿼리가 날라가지 않는다.
여기서 clear, persis, flush는 꼭 기억하자!
clear(한방에), detach(골라서, 준영속 객체)
RepoTest 코드
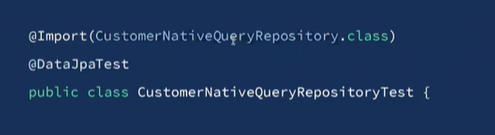
DataJpaTest를 붙이면 내가 만든 Repo.class 는 메모리에 뜨지 않는다. 따라서 Import해서 넣어야 한다.
DataJpaTest 내부에는 트렌잭션이 붙어있다. 이 디폴트 속성은 테스트하나가 실행될 떄마다 roll back이 실행된다. 테스트마다 격리가 되는 것이다.
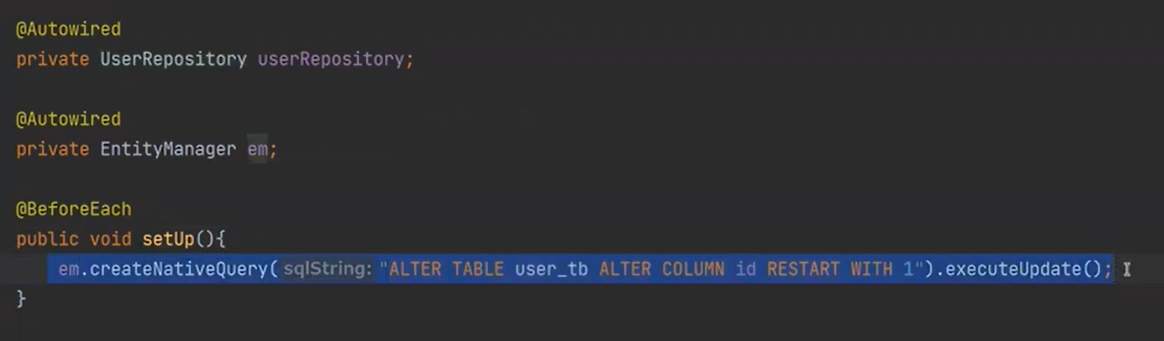
하지만 안되는 것이 하나가 있는데, auto-increment가 되지 않는다.
그래서 해당 코드를 적는다.

네이티브 쿼리로 작성을 한다. auto-increment 초기화
BeforEach는 각 테스트가 실행되기전에 매번 실행이 된다
자 이제 JPA를 해보자. 우리는 JPA로 프로젝트를 할 것이다.

구조를 보면 컨트롤러는 없다.
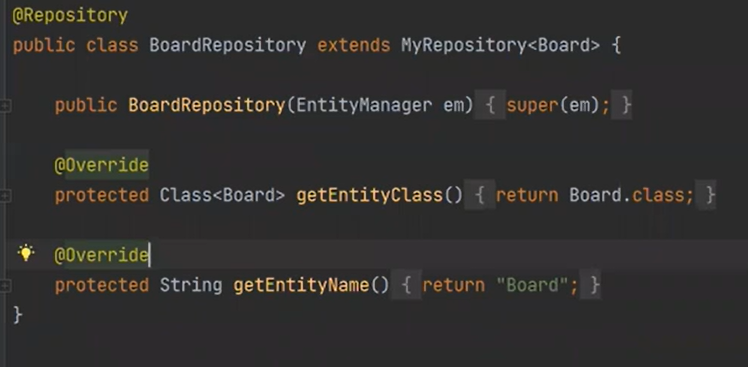
보드 레포지토리를 보면
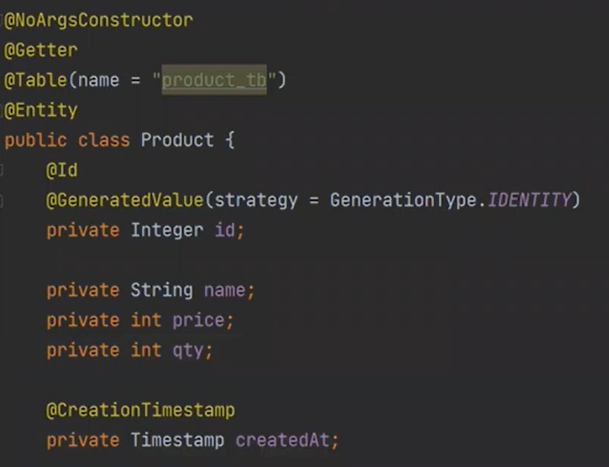
일단 Product를 만들자

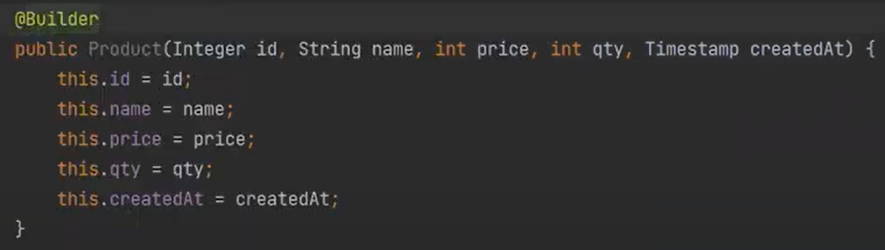
하고 풀 생성자를 하나 만들고 Builder를 붙인다
이제 ProductRepo를 만들자
이전에 우리는 다음과 같이 만들었다 간단하다. 하지만 더 간단하게 만들 예정이다.

이렇게 작성을 하자
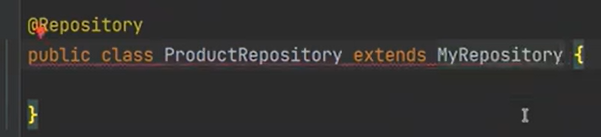
그리고 Product를 넣자
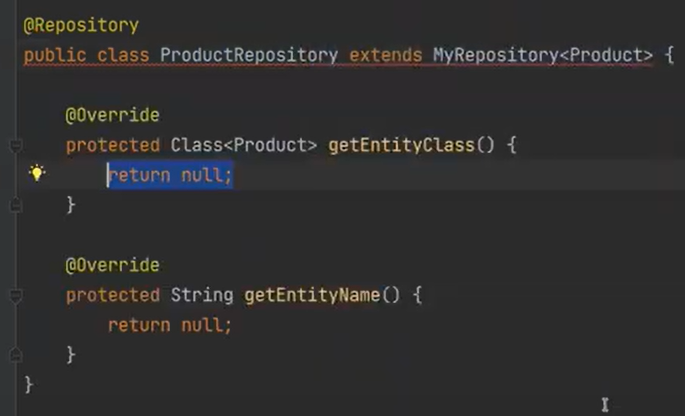
이제 슈퍼 생성자를 만들자
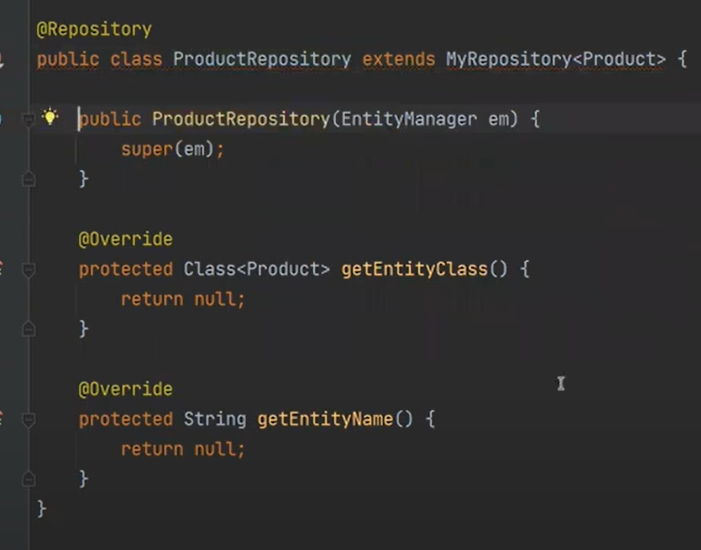
@Repository가 있으니까 Conponent Scan을 할 때 ProductRepo가 new 가 된다.
근데 보니까 ProductRepo는 디폴트 생성자를 가지고 있지 않다.
그레서 IocContainer에 의해서 아래의 코드가 new가 된다.

근데 매개변수로 EntityManeger를 받는다. EntityManeger는 IocContatiner에 있기 떄문에 해당 매개변수로 주입을 해준다.
의존성 주입을 해주고, 자기는 들지 않고 부모에게 넘긴다.
이제 코드를 바꿔보자
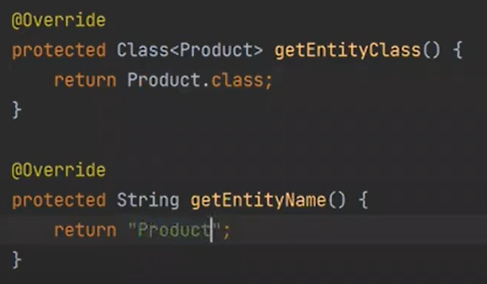
진화를 한것이다.
JDBC - hibernate - generic 으로 짠것이다.(CRUD클래스)

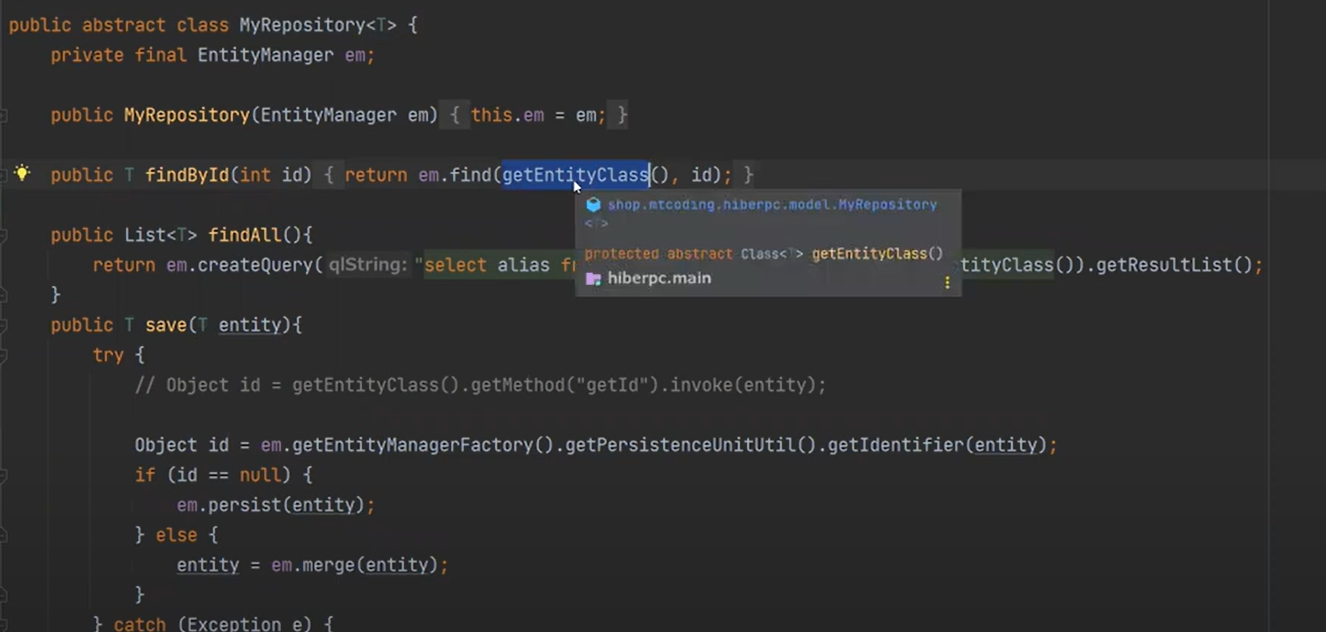


T 에는 Procudt가 들어오게 된다.
이 부분을 보면 동적 바인딩이 되서 자식의 Entity 클래스가 실행이 된다. (오버라이드 부모꺼 말고 자식꺼가 실행)
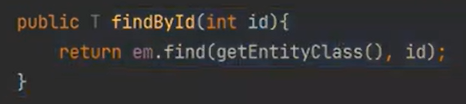
이제 findAll을 보자


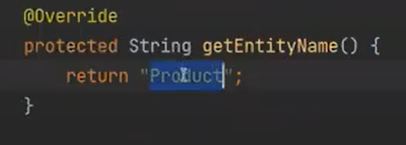
T에는 Product가 들어오고, getEntityName()에는 ProRepo에 있는 것이 들어가게 된다. 동적바인딩이 된 것이다.(부모 X 자식 O)
잘만들었다.
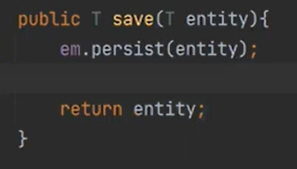
이제 save를 보자
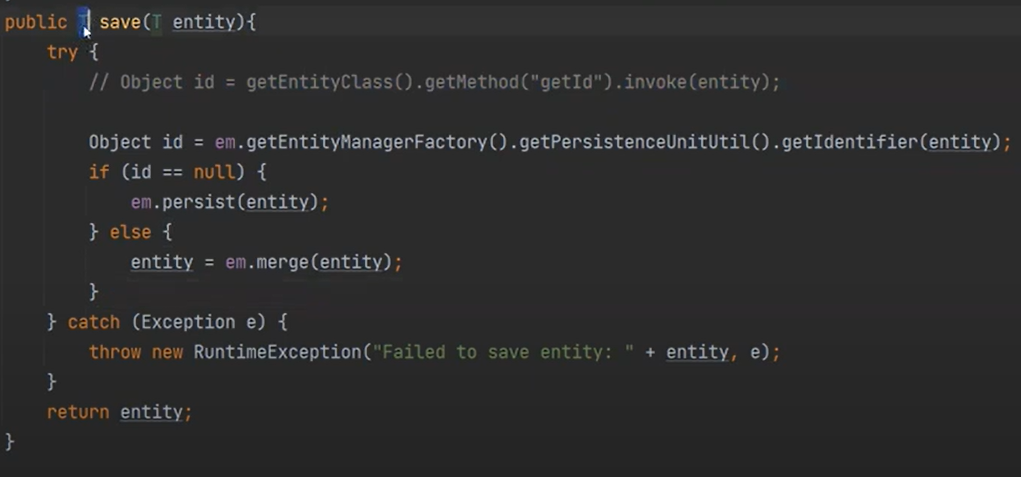
id가 없으면 persist() 하고
있으면 Db에 동일한것이 있는지 확인하고 update를 한다. 존재하지 않으면 insert를 한다.


이 코드는 id를 찾는 코드이다. 영속된 객체중에서 id를 찾는 것이다.(캐싱된 것중에)
즉, 영속석 컨텍스트에서 같은 객체를 찾아내는 것이다.
중요하지 않다. 우리가 짤 일이 없기 떄문이다.

이코드는 리플렉션을 하는 코드이다. invoke는 호출하다라는 의미이다. 만약 getMethod시 해당 값이 없으면 아무것도 호출되지 않는다. 순수한 객체라는 것이다.
근데 그냥 이렇게 짜도 된다
제네릭으로 설정하면 편하다.
이제 테스트를 해보자. user 먼저 보자

쿼리 테스트를 하자
auto-increment를 초기화하고 있다
보면 MyDummyEntity가 있는데 이 부분은 다음과 같다.
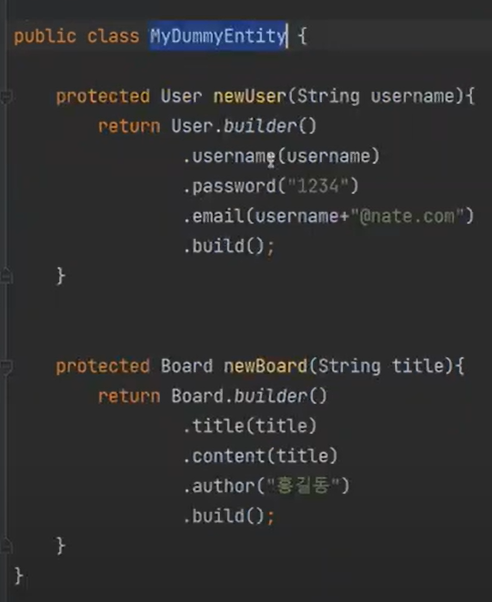
보니까 protected가 걸려있으니까, 상속했을때만 사용이 가능하다
그래서 save테스트 코드를 다음과 같이 만들수 있는 것이다.
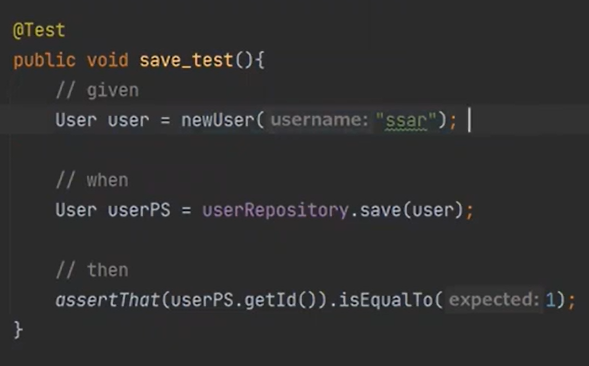

save를 하면 내부적으로는
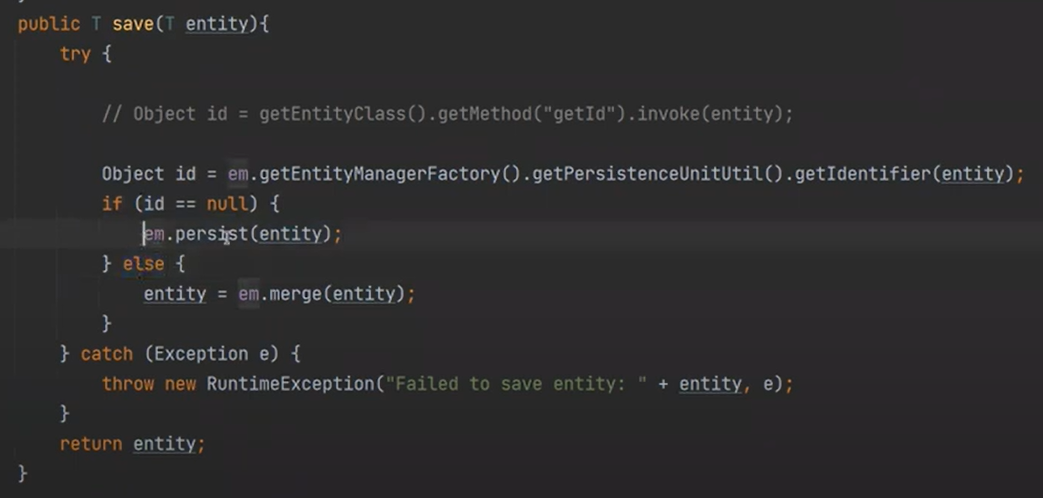
persist가 일어난다.
마지막은 검증을한다. 테스트를 해보자
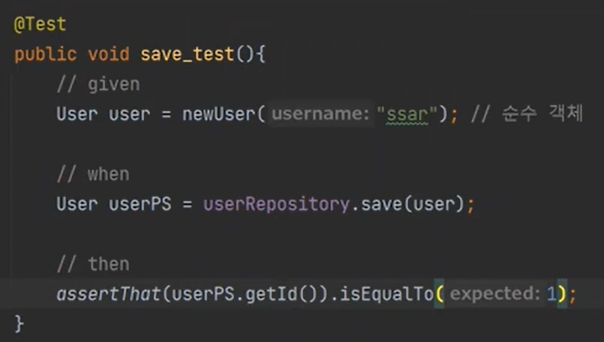
정상적으로 작동한다.
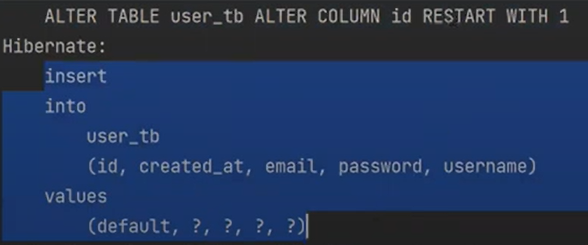
이제 findById를 해보자

영속화가 되어있었는데 준영속이 되었다.

detach도 가능하다. 하지만 clear하면 되기떄문에 하지 않는다.

캐싱이 안되어서 그럼 이부분에서 조회쿼리가 발동할 것이다.

이제 update를 보자
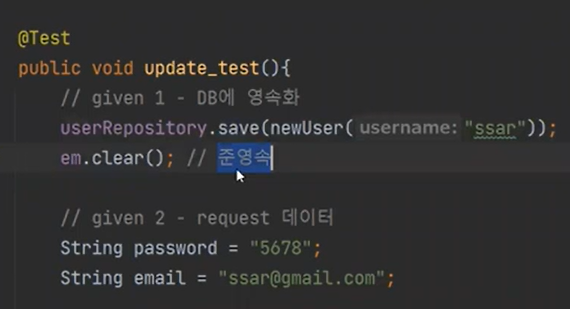
영속화 된것을 받아서 수정(데이터 수정)
그리고 save를 한다. 이때 save는 PK를 가지고 있다.
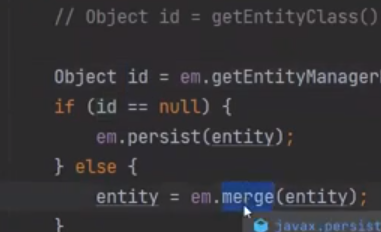
merge가 일어난다. PK가 있는 게 merge로 들어오면 값의 변경이 있을 때만 update를 한다.
이 변경을 하이버네이트가 감지를 한다.
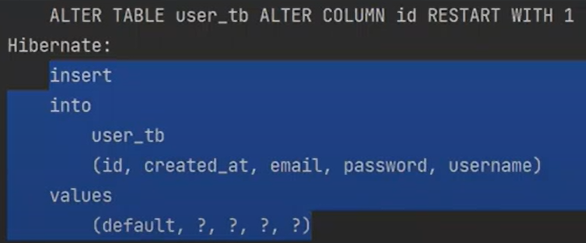
검증을 하면 가장먼저 insert가 하나 된다.
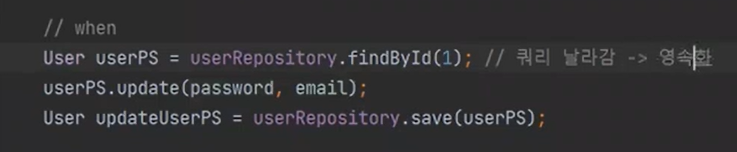
그다음에 준영속으로 바뀐다.
그리고 findById가 되면서 조회(영속화)가 된다.
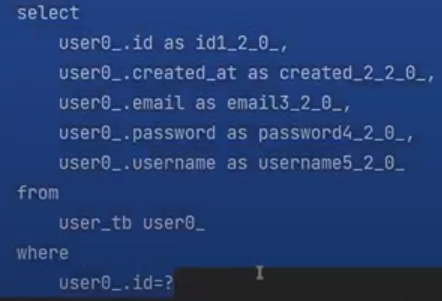
조회가 되고나서 데이터 변경이 되었으니까
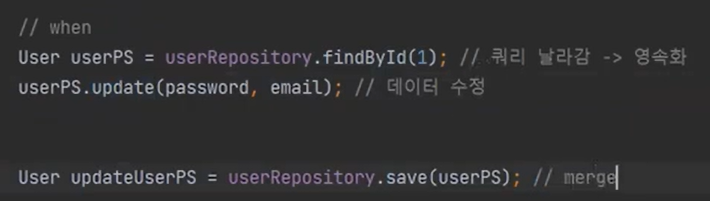
내부적으로는 save가 일어나서 merge가 발생한다.
왜나하면PK가 있어서다. 하지만 update 쿼리가 없다. 실제 코드에서는 된다. 하지만 여기서는 매번 테스트를 할 떄마다 roll back이 되기때문에 되지 않는다.
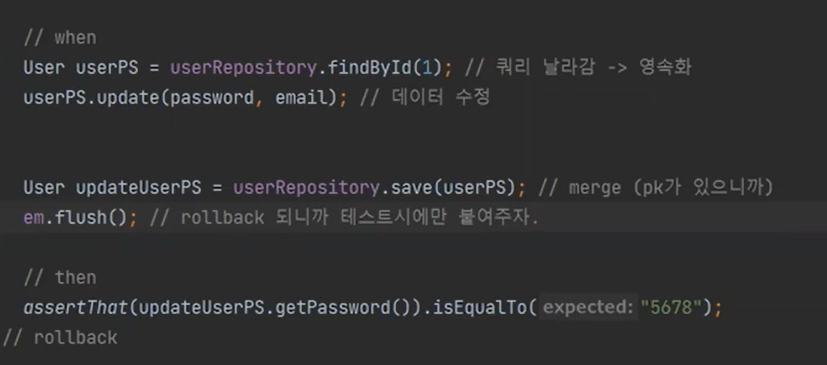

그래서 이렇게 flush를 걸어주자, 아니면 테스트를 제대로 하지 못한다.
만약 진짜 변경감지를 하는지 확인을 하고 싶으면 데이터 수정부분을 주석으로 바꾸자
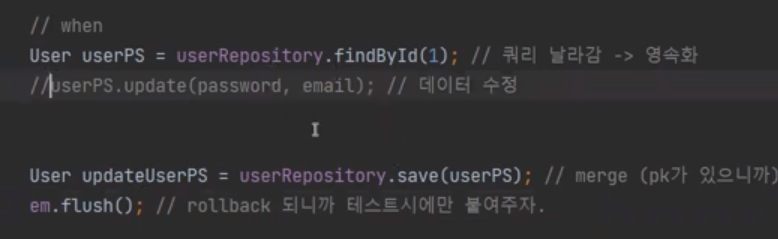
그리고 실행을 하면
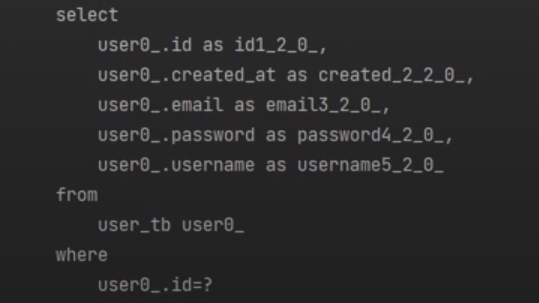
update가 없다. 왜냐하면 하이버네이트가 변경감지를 느끼지 못했기 때문이다.

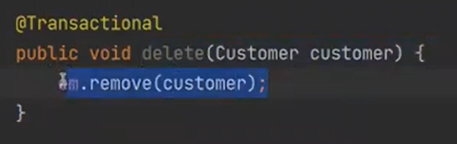
delete를 보자
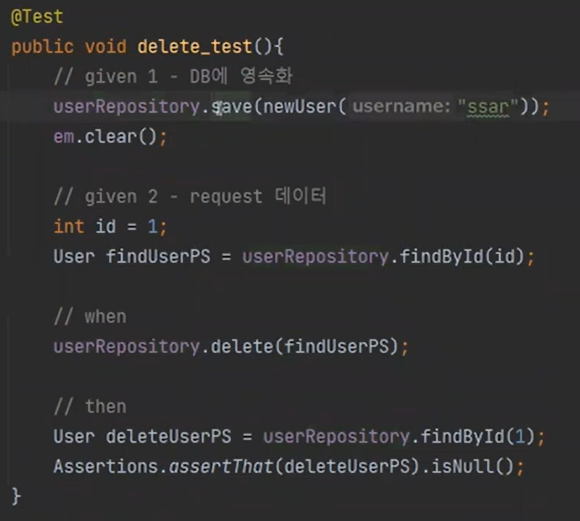
save를 했고, 영속화가 됬다. 그리고 em.clear를 하면 준영속이 된다.
근데 왜 조회를 하고 delete를 할까? 왜냐하면 하이버네이트의 메커니즘은 모든 것을 영속화 시켜서 하는 것이기 때문이다.
하이버네이트는 영속화 되어있는 것만 관리를 해준다

이렇게 delete도 조회를 해줘야한다. 만약 조회를 하지않고 delete를 했는데, 없으면 터지기 때문이다.
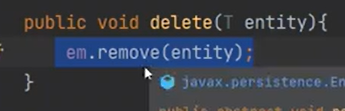
remove, 완전 비영속으로 바꾸는 것이다.
DB는 read할 때보다, write할 떄 다른 사람들이 멍떄리고 있다.
예를 들어서 슈퍼에와서 보는 것은 100명이 와도 괞찮다. 하지만 계산은 1명만 가능하다. 최대한 계산을 하는 시간을 줄여야한다.
따라서 조희를 함으로써 계산을 하는 시간을 줄이는 것과 같은 것으로 보면 된다.
실행해보자
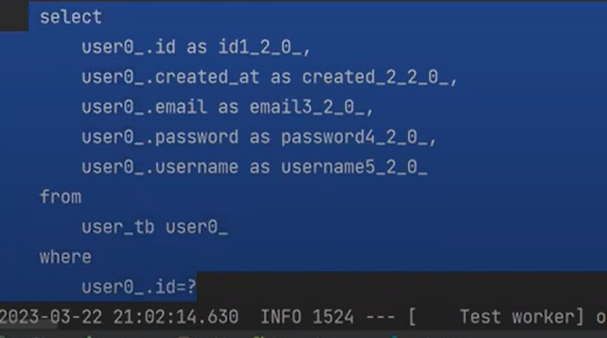
이것 또한 트렌젝션과 롤벡과 관련이 있기 떄문에 delete가 나오지 않는다.
이 부분에 대한 설명은 나중에 설명을 하겠다.
다음 교시에는 자바 JPA를 배우자
📕 3교시
스프링 부트 JPARepo 가 있다. CRUD 를 제공을 해준다. 사실 우리는 아무것도 할 필요가 없다.
내부적으로는 리플렉션으로 되어있기 떄문이다.
save라는 메소드는 entity를 저장하고 반환을 한다. 즉, persist 하고 동기화된 것을 반환하는 것이다.
보면 한방에 하는 것도 있다.

findById는 em.findById 이다.

delete

보면 deleteById는 터질 가능성이 있을까? 있다
이 부분은 try-catch에서 터지는 것이 아니라

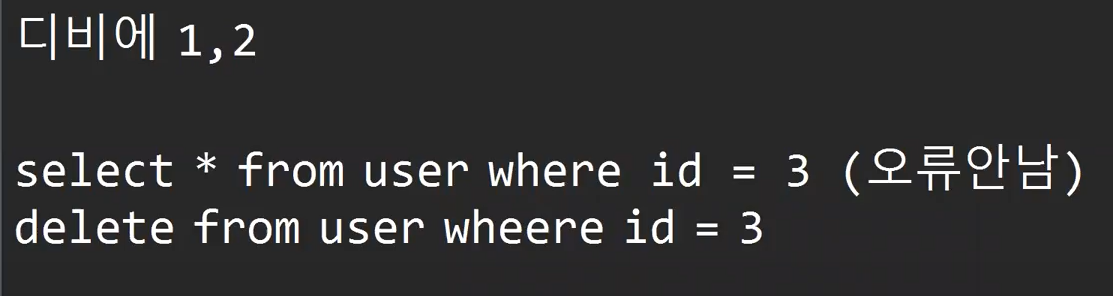
조회는 되지만 오류는 나지 않는다.
따라서 우리가 직접 오류를 잡아야한다.
헨들러에게 throw로 던져야한다.
이제 만들어보자
웹개발자에게는 DB가 어렵다. 따라서 이것저것 많이 해보자!
yaml
회원 사이트가 21억이 넘을 것 같으면 Long 아니면 Integer로 하면된다

주의할 것은 int로 하면 0이 되기때문에 Integer은 null이거나 비교를 할 수 있기 때문이다.
하이버네이트가 관리하게 하고
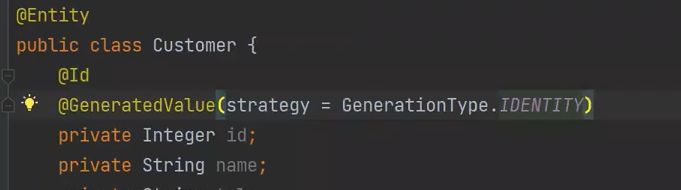
PK와 auto-increment를 장착한다.
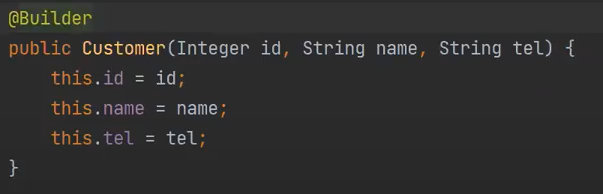
AllArgConsturctor를 쓰지 말자, 테스트 할 떄 다 터진다.

아직도 오류가 뜬다. 보면 디폴스 생성자가 필요하다는 것인데, 하이버네이트가 감지를 하고 알려주는 것이다.
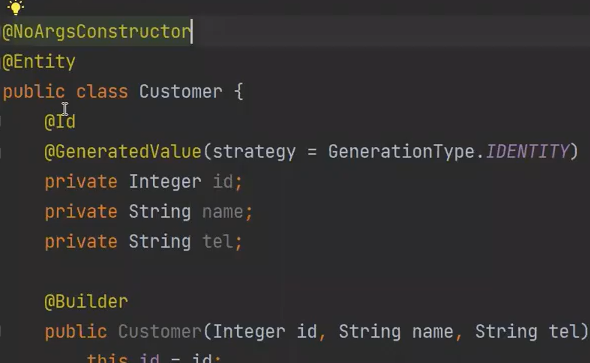
이 디폴트 생성자는 하이버네이트가 사용하기 위해서 띄운것이지 개발자가 사용하기 위해서 띄운것은 아니다.
그러면 하이버네이트는 어떻게 사용을 할까?? new를 해서 사용을한다. 즉, 리플렉션을 사용하는 것이다.
그래서 다음과 같이 내가 new 해서 사용하지 못하도록 적는다.(혹시 무의식적으로 할 수 있으니까)

디폴트 생성자 -> 하이버네이트를 위해
풀 생성자 + 빌더 -> 비영속 객체를 만들 때
Getter 추가한다

Interface 로 CusRepo를 만든다.

2번째에는 Integer를 넣어주자

보면 CustomerRepo는 new를 하지 못한다. 그렇기 떄문에 IocContainner에 나오지 못한다.

extends를 JPA 상속한다. Spring은 어떻게 new를 할까?

JPA를 부모로 해서 new 한다. 동적으로
그럼 Component Scan을 할 떄 JPA를 상속하고 있는 모든 것들을 쭉 Scan을 할 것이다.(리플렉션을 하면서 전부 뒤진다.)
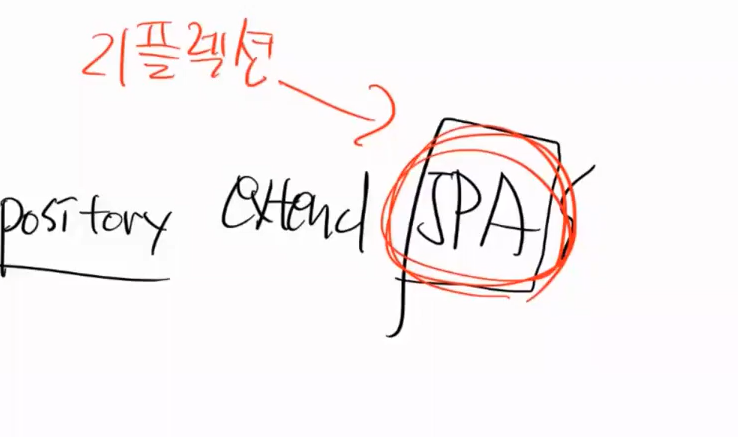
그러면 클래스를 만든다.

이렇게 되면 IocContainer에는 A가 올라가게 된다.

내가 DI를 할 때, 우리입장에서는 A가 있는지 모른다.
따라서 DI를 할떄 우리는 private custoRepo cs를 찾으려고 할 것이다.

그러면 IocContainer에서 CustomerRepo를 찾는데 A가 있으니까 찾게 된다.
즉, Component Scan은 동일한 타입뿐만 아니라 부모타입까지 전부 찾는다.
이것 또한 DIP이다. 추상적인 것에 의존하게 한다.
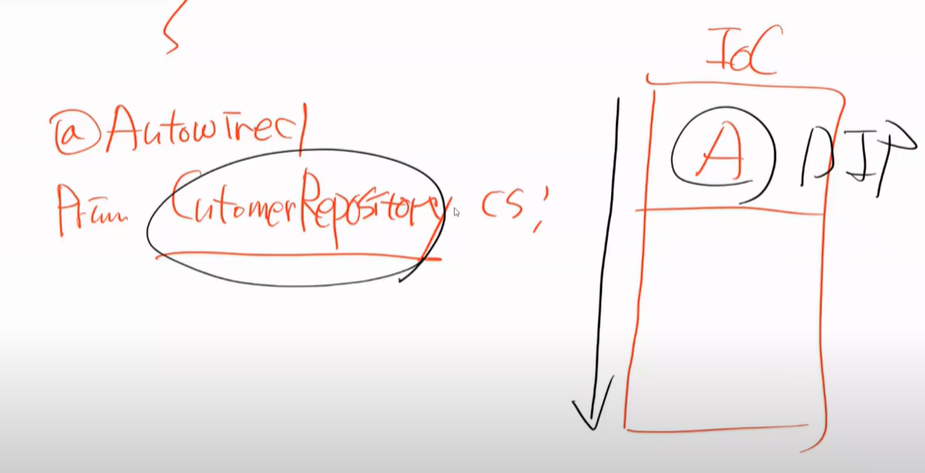
즉, 내부적으로 CustomerRepo를 어떤 클래스가 구현을 해서 IocContanier에 띄운 것이다.
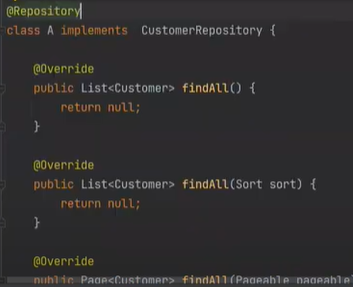
이것을 스프링이 대신 해준것이다.
이제 본 코드로 테스트를 해보자, JPA의 기본 메소드는 테스트할 필요가 없다.
왜냐하면, 잘 만들어져 있기 떄문이다. 추가로

테스트를 할때는 DataJpaTest만 붙이면 된다.
우리는 한번 봐야하니까 컨트롤러를 만들자

의존성을 주입하자
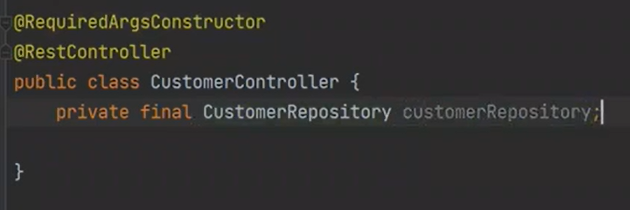
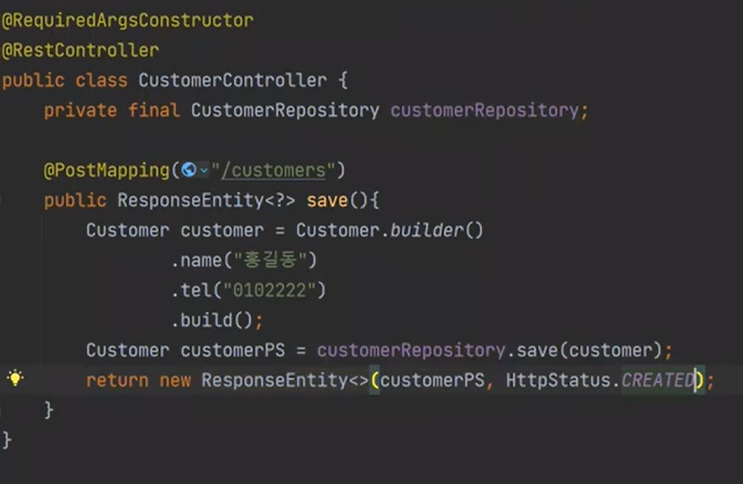
서버를 실행하고 포스트맨으로 실행하면
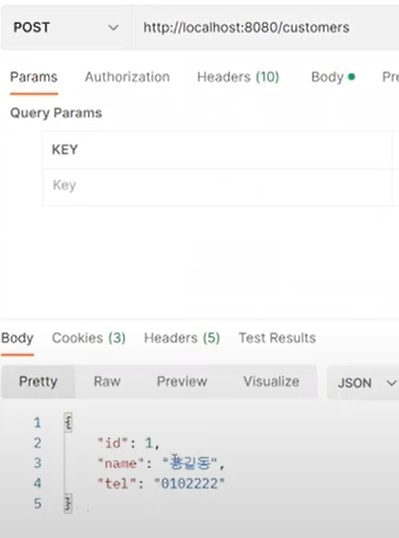
한번 더 누르면
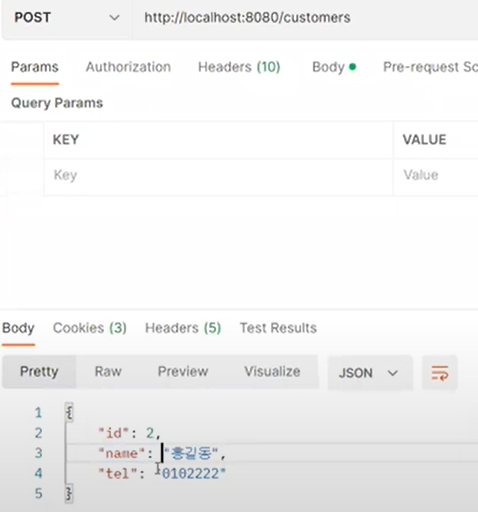
쿼리를 보면 insert되는 것이 보인다
findAll 해보자
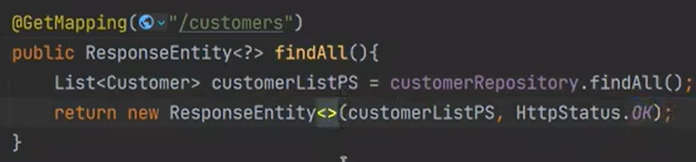

수업 끝
