인공지능의 분류
AI ML DL
- 인공지능(AI) : 인간의 지능을 인공적으로 만든 것
- 머신러닝(ML) : 데이터 기반 인공지능
- 딥러닝(DL) : DNN을 활용한 인공지능
- 머신러닝이 아닌 인공지능 : 규칙 기반 알고리즘
인공신경망
AI가 학습한다 = 적절한 weight와 bias를 찾는다
weight(중요도) 곱하고 bias(민감도) 더해서 activation
- weight : 신경 부위 별 중요도
- bias : 신경 활성화 여부에 대한 민감도 조절
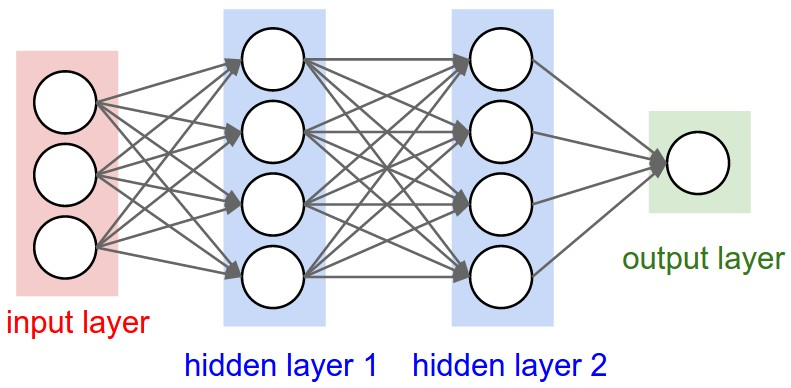
input layer : input data(3)
hidden layer 1 : output from input layer(3) + weight(12) + bias(4) + activation function(4)
hidden layer 2 : output from hidden layer 1(4) + weight(16) + bias(4) + activation function(4)
output layer : output from hidden layer 2(4) + weight(4) + bias(1) + activation function(1)
Self-Supervised Learning
- 적은 데이터로도 효과적으로 학습이 가능하기 때문에 여러 분야에 활용되고 있다.
- 데이터 수집에는 많은 비용이 필요하기 때문에 효율적인 학습을 위해 자기지도 학습이 중요하다.
자기지도학습 과정
-
pretext task를 학습하여 pre-training
: 진짜 문제를 학습하기 이전에 가짜 문제를 연구자가 새롭게 정의하여 사전 학습- 연구자가 정의한 인위적인 문제(pretext task)를 통해 모델이 데이터의 기본적인 특징을 학습하도록 한다.
- 예를 들어, 이미지의 일부를 가리고 나머지 부분으로 가려진 부분을 예측하거나, 문장 내의 단어 순서를 섞은 후 원래 순서를 맞추는 등의 task를 설정할 수 있다.
- 이 단계에서는 실제 목표(downstream task)와는 직접적인 관련이 없지만, 모델이 데이터의 전반적인 구조와 패턴을 이해하는 데 도움을 준다.
-
downstream task를 풀기 위해 transfer learning
: 진짜 문제를 풀기 위해 전이 학습- Pre-training 단계에서 학습된 모델의 지식을 실제 목표 문제(downstream task)에 전이하여 학습한다.
- 일반적으로 pre-trained 모델의 일부 레이어만 fine-tuning하거나, pre-trained 모델을 feature extractor로 사용하여 downstream task를 위한 별도의 모델을 학습시킨다.
- Pre-training을 통해 얻은 지식은 downstream task의 성능 향상과 학습 속도 개선에 기여할 수 있다.
대표적인 자기지도 학습
Context Prediction (2015)
이미지에서 3×3개의 patch 추출
가운데 patch와 다른 임의의 patch 1개를 모델에 입력
입력받은 임의의 patch의 위치를 맞추는 방식으로 학습

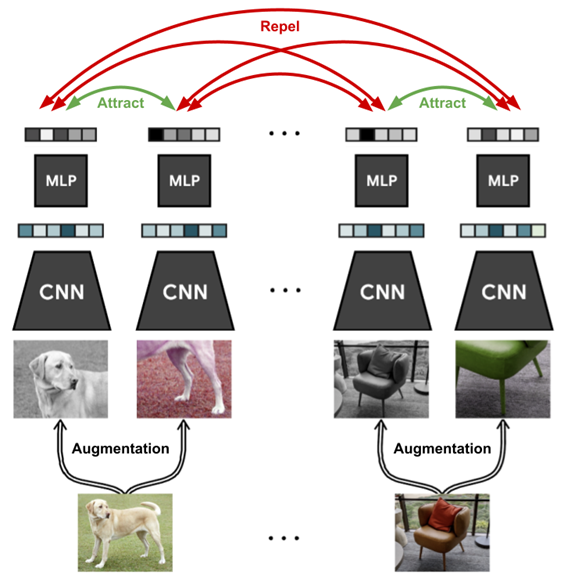
Contrastive learning (2020)
유사한 이미지는 가깝게 임베딩되고, 다른 이미지는 멀게 임베딩되도록 학습
딥러닝 학습
Loss
AI 학습은 최적의 weight와 bias를 찾는 과정이다.
Loss는 최적의 weight와 bias를 찾는 수단이다.
Loss는 일반적으로 AI의 예측값과 실제값의 차이로 정의한다.
Loss를 최소화하는 weight와 bias 탐색한다.
Gradient descent
경사 하강법
Gradient : 기울기
weight와 bias의 초기값은 랜덤으로 정한다.
현재의 weight, bias의 위치에서 Loss를 줄이는 방향으로 나아간다.
수학적으로 Gradient는 항상 가파른 방향을 가리킨다. (Loss를 올려주는 방향)
Gradient의 반대 방향으로 가면 Loss의 최소값을 향해 갈 수 있다.
weight 초기화
초기값은 균등분포나 정규분포를 활용하여 랜덤하게 0 근처로 설정한다.

Learning Rate
Gradient는 학습에 사용하기에 크기가 너무 크다.
Learning Rate를 곱해서 학습에 사용한다.
보편적으로 0.001을 많이 사용한다.
경사 하강법의 단점
- 모든 데이터를 고려하여 Loss를 구한다.
- local minimum에 빠질 수 있다.
Stochastic Gradient descent
확률적 경사 하강법
경사 하강법은 모든 데이터를 활용하여 Loss를 만든다.
확률적 경사 하강법은 데이터 중에 하나씩 랜덤으로 뽑아서 Loss를 만든다.
Loss 미분 과정에서 계산 복잡성이 줄어들어 더 빨리 수렴한다.
비복원 추출이고, 모든 데이터를 사용하면 1 epoch이다.
확률적 경사 하강법의 장점
- 데이터를 하나씩 고려하여 Loss를 구하기 때문에 계산이 빠르다.
- local minimum으로부터 탈출의 기회가 되기도 한다.
가장 가까운 local minimum의 방향으로 곧장 가지는 않기 때문이다.
Mini-Batch Gradient descent
미니배치 경사 하강법
데이터 중에서 Batch size만큼 랜덤으로 뽑아서 Loss를 만든다.
Batch size = 1 : 확률적 경사 하강법
Batch size = Data size : 경사 하강법
GPU 병렬 연산의 발전으로 경사 하강법이 느리다는 문제는 해결되었지만, local minimum에 빠지는 것을 어느정도 막을 수 있기 때문에 미니배치 경사 하강법을 사용한다.
Batch Size 결정
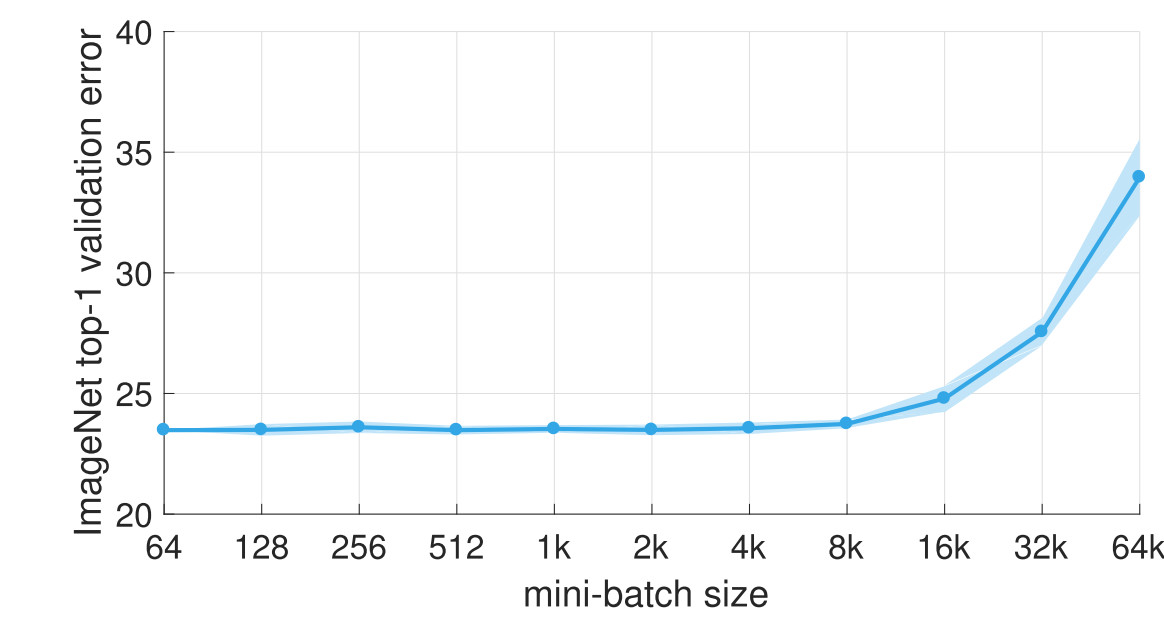
실험을 통해 Batch size를 키울수록 성능이 하락한다는 사실이 알려져있다.
Batch size가 클수록 경사 하강법에 가까워지므로, 랜덤하게 시작한 위치에서 가까운 local minimum에 빠지는 경향이 있다.
Batch size를 키우고 싶으면 Learning rate를 조정하면 된다.
Batch size는 Learning rate를 조정하면 ImageNet 데이터 기준으로 8k까지가 적당하다.
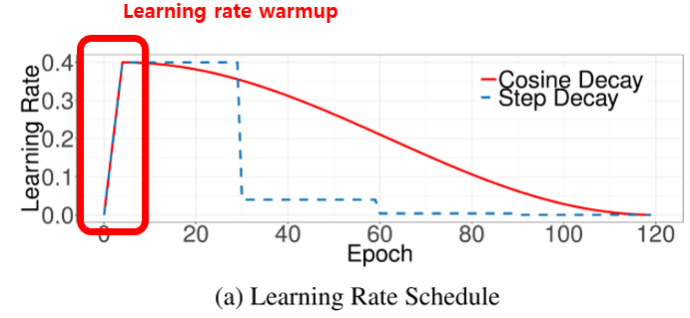
- Batch size를 키우는만큼 Learning rate도 같이 키우기
- warmup 사용하기
Batch size를 키울 때, Learning rate도 같이 키우는 것이 좋다.
Batch size를 2배 키우면 Learning rate도 2배 키워야 균형이 맞는다.
-
Batch size가 32일때, 64개의 데이터로 weight를 업데이트하는 상황
-
Batch size가 64일때, 64개의 데이터로 weight를 업데이트하는 상황
warmup은 학습 초기에 Learning rate를 0부터 증가시키는 기법이다.
cf) 익숙한 이 그림에서 확률적 경사 하강법은 왜 정방향으로 가지 않을까?
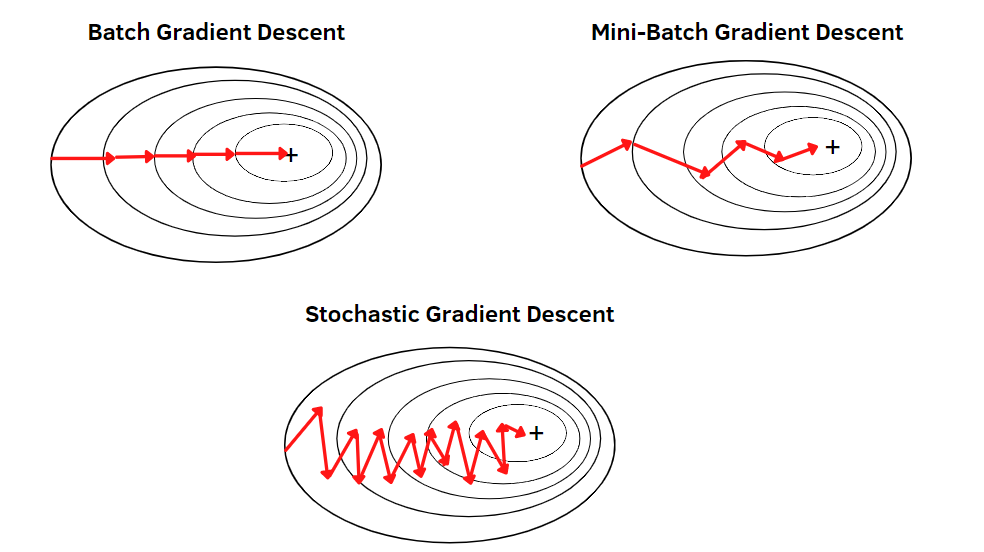
그림의 등고선은 전체 데이터를 고려한 Loss에 대한 것이다.
화살표는 전체 데이터를 고려한 방향이 아니라 랜덤으로 추출한 하나의 데이터에 대한 Loss이다.
따라서 전체 데이터를 고려한 Gradient의 반대 방향은 아니지만 여러번 반복되면 결국 목적지에 도착한다.
딥러닝 학습 용어
Epoch : 전체 데이터를 몇번 반복해서 볼거냐
Batch size : 몇개씩 볼거냐
Learning rate : 얼만큼 업데이트 할거냐
Parameter : AI가 스스로 알아내는 변수 ex) weight, bias ...
Hyperparameter : 사람이 정해줘야하는 변수 ex) Epoch, Batch size, Learning rate, Initial weight, Model architecture, Loss function, Optimizer ...
