pretrained 된 모델이나, 저장한 모델을 불러올 경우 발생하는 문제점(?)에 대해 정리하고자 한다.
먼저 요즘 나오는 대부분의 논문들의 경우
torch.nn.DataParallel(model)
이런 식으로 병렬로 프로그래밍을 한다. 이렇게 할 경우 모델이 저장될 때
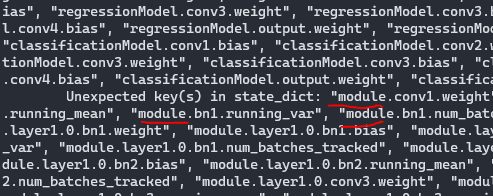
이런식으로 layer 이름 앞에 module이 붙게 된다.
이 경우 대부분 single GPU에서 load 하거나 따로 지정해주지 않는 경우 모델을 불러올 때 문제점들이 발생한다.
그래서 이 경우
torch.load( 저장된 모델).state_dict() #를 하는 것이 아니라
torch.load( 저장된 모델).module.state_dict() # .module을 추가해주면 해당 부분에 대한 파라미터만 가져올 수 있게 된다.

저장된 모델이 어떻게 저장되어 있는지에 따라 조금 다를 수 있으니 그 부분은 다른 곳에서 조금 찾아보고 하면 좋을 것 같다.
