Go 1.24에서 주목할 만한 변화 중 하나는 내장 map 타입의 새로운 구현입니다. 이번 글에서는 최근 공식 Golang Blog에 올라온 Faster Go maps with Swiss Tables 내용을 소개하고, 실제로 성능 향상이 얼마나 일어나는지 알아보겠습니다.
해시 테이블: 오래됐지만 여전히 발전 중
해시 테이블은 키(key)와 값(value)을 빠르게 저장하고 검색할 수 있는 자료구조로, Go에서는 map 타입으로 구현되어 있습니다. 70년 가까운 역사를 가진 이 자료구조는 언뜻 보기에 더 이상 개선할 것이 없어 보일 수 있지만, 컴퓨터 과학 연구는 계속해서 기본 알고리즘을 발전시키고 있습니다.
2017년, Google에서는 "Swiss Tables"라는 새로운 해시 테이블 디자인을 발표했고, Go 1.24에서 이 디자인을 기반으로 한 새로운 맵 구현이 도입되었습니다.
기존 해시 테이블의 작동 방식
전통적인 'Open Addressing(오픈 어드레싱)' 해시 테이블은 다음과 같이 작동합니다:
- 모든 항목은 하나의 배열에 저장됩니다(각 자리를 '슬롯'이라고 부릅니다)
- 키가 어디에 저장될지는 해시 함수가 결정합니다
- 충돌이 발생하면(해시 함수가 이미 차 있는 슬롯을 가리키면), 다음 빈 슬롯을 찾을 때까지 순차적으로 이동합니다(이를 '선형 탐색'이라고 합니다)

예를 들어, 해시 함수가 키 25를 슬롯 3에 저장하라고 했는데 슬롯 3이 이미 차 있다면, 슬롯 4, 5를 확인하고 빈 슬롯 6을 찾아 거기에 저장합니다.
이 방식은 배열이 많이 차게 되면 성능이 저하됩니다. 왜냐하면 배열에 빈 슬롯이 하나만 있는 경우, 최악의 경우 탐색 복잡도는 O(N)을 가지게 됩니다. 즉, 전체 배열을 순회해야 할 수도 있습니다. 따라서 대부분의 해시 테이블은 배열이 70-90% 차면 크기를 두 배로 늘립니다.
Swiss Tables
Swiss Tables도 기본적으로는 오픈 어드레싱 해시 테이블이지만, 성능을 크게 개선하는 몇 가지 핵심 아이디어가 있습니다:
- 배열의 그룹화: 전체 배열을 N개 슬롯씩 묶어 '그룹'으로 관리합니다.
- 제어 워드(Control Word): 각 그룹마다 64비트(8바이트) 메타데이터를 유지합니다.
- 해시 값 분할: 키의 해시를 두 부분으로 나눕니다:
상위 57비트(h1): 그룹 선택에 사용
하위 7비트(h2): 제어 워드에 저장
원문의 예시를 보면 두 개의 그룹이 있고, 몇 개의 키가 저장되어 있습니다:
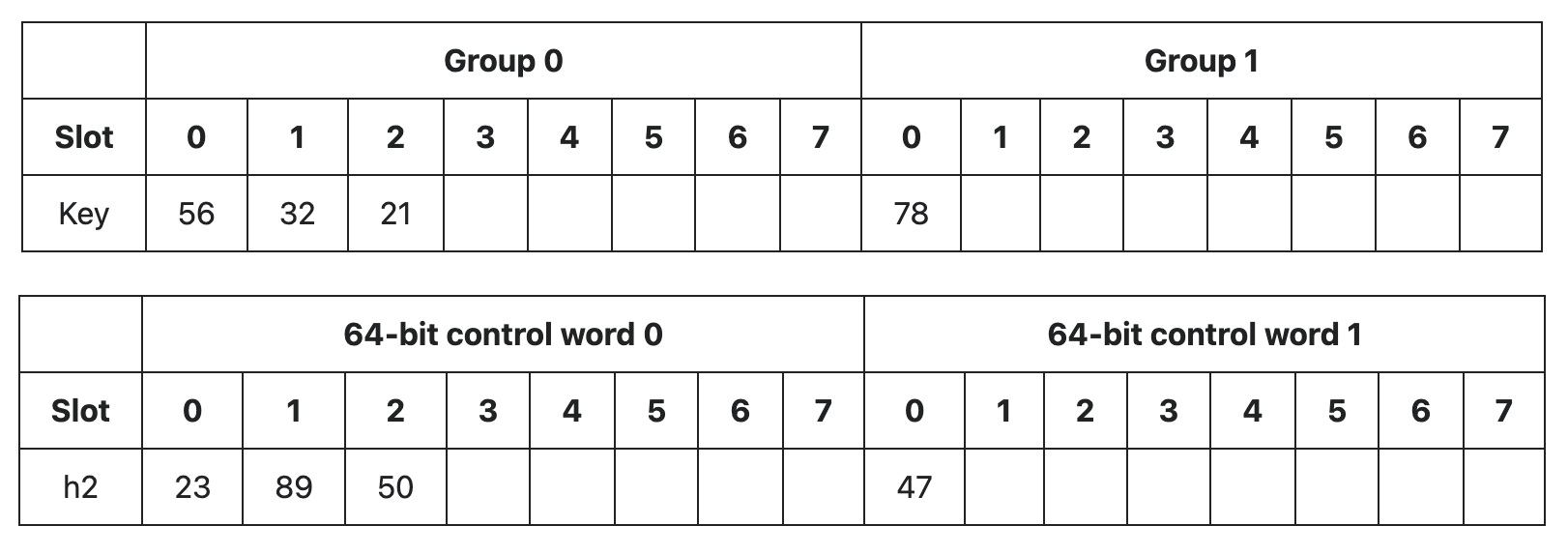
그룹 0의 슬롯 0, 1, 2에는 키 56, 32, 21이 저장되어 있습니다.
그룹 1의 슬롯 0에는 키 78이 저장되어 있습니다.
각 슬롯에 해당하는 제어 워드에는 hash(key) 값의 하위 7비트(h2)가 저장되어 있습니다.
Swiss Table의 삽입 과정
키-값 쌍을 삽입하는 과정은 다음과 같습니다:
- 해시 계산 및 분할:
키의 해시 값을 계산합니다: hash(key)
상위 57비트(h1)와 하위 7비트(h2)로 나눕니다.
- 그룹 선택:
h1 % 그룹 수를 계산하여 시작 그룹을 결정합니다.
예시에서는 그룹이 2개이므로 h1 % 2를 사용합니다.
- 그룹 내 검색:
선택된 그룹 내에서 키가 이미 존재하는지 확인합니다.
제어 워드를 사용해 효율적으로 검색합니다(뒤에서 설명).
- 빈 슬롯 찾기:
키가 존재하지 않으면 그룹 내에서 빈 슬롯을 찾습니다.
빈 슬롯에 키-값을 저장하고 제어 워드를 업데이트합니다.
- 다음 그룹으로 이동:
그룹에 빈 슬롯이 없으면 다음 그룹으로 이동하여 과정을 반복합니다.
Swiss Table의 검색 과정과 "마법"
Swiss Table의 가장 큰 혁신은 제어 워드를 사용한 효율적인 검색 방식입니다. 블로그 포스트에서 "Swiss Table magic happens"라고 표현한 부분입니다.
전통적인 해시 테이블에서는 각 슬롯을 하나씩 검사해야 하지만, Swiss Table에서는 제어 워드를 이용해 한 번에 8개 슬롯을 동시에 검사할 수 있습니다:
- 제어 워드 비교:
그룹의 제어 워드와 바이트별로 비교합니다.
예를 들어, 키 32를 찾는 경우(h2 = 89):
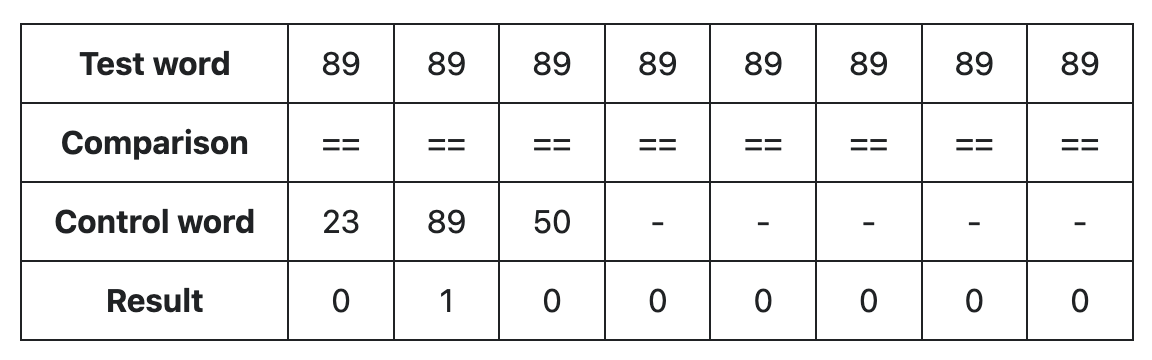
이 비교 연산이 바로 "Swiss Table 마법"의 핵심입니다. 이 연산은 단일 명령어로 여러 데이터 처리를 수행하는 SIMD(Single Instruction Multiple Data) 기술을 활용합니다.
비교 결과는 일치하는 위치만 1로 표시된 비트 마스크가 됩니다. 위 예시에서는 인덱스 1(두 번째 슬롯)만 h2 값이 89로 일치하기 때문에 결과 마스크는 01000000이 됩니다.
-
후보 슬롯 확인:
결과에서 1로 표시된 슬롯만 검사 대상이 됩니다.
다른 슬롯은 h2 값이 다르므로 확실히 원하는 키가 아니라고 판단하여 건너뜁니다. -
실제 키 비교:
h2가 일치하는 슬롯에서만 실제 키를 비교합니다.
이 예시에서는 슬롯 1에 저장된 키(32)가 찾고 있는 키와 같은지 확인합니다.
키가 일치하면 해당 슬롯의 값을 반환합니다.
키가 일치하지 않으면 다음 그룹으로 이동하여 검색을 계속합니다.
이 방식의 장점은 여러 가지입니다:
병렬 비교: 한 번의 연산으로 그룹 내 모든 슬롯(8개)을 동시에 체크합니다.
필터링 효과: 7비트 해시(h2)의 일치 확률은 약 1/128이므로, 대부분의 슬롯은 실제 키 비교 없이 건너뛸 수 있습니다.
메모리 효율성: 제어 워드는 연속된 메모리에 저장되어 캐시 효율이 높습니다.
이러한 최적화를 통해 Swiss Table은 평균적으로 필요한 비교 횟수를 크게 줄이고, 이는 조회와 삽입 속도를 높이는 데 중요한 역할을 합니다.
이 방식의 장점은 여러 가지입니다:
- 병렬 비교: 한 번의 연산으로 그룹 내 모든 슬롯(8개)을 동시에 체크합니다.
- 필터링 효과: 7비트 해시(h2)의 일치 확률은 약 1/128이므로, 대부분의 슬롯은 실제 키 비교 없이 건너뛸 수 있습니다.
- 메모리 효율성: 제어 워드는 연속된 메모리에 저장되어 캐시 효율이 높습니다.
실제 성능 측정
Go 언어에서 각 버전에 따른 맵(map) 자료구조의 성능을 측정하기 위한 벤치마크 테스트를 진행하였습니다. 주요 맵 연산(삽입, 조회, 반복)에 대한 성능을 측정합니다.
Test Code
package benchmark
import (
"strconv"
"testing"
)
// BenchmarkMapInsertion 벤치마크는 일정 개수의 요소를 map에 삽입하는 작업의 성능을 측정합니다.
func BenchmarkMapInsertion(b *testing.B) {
for i := 0; i < b.N; i++ {
m := make(map[string]int, 100000)
for j := 0; j < 100000; j++ {
key := "key_" + strconv.Itoa(j)
m[key] = j
}
}
}
// BenchmarkMapLookup 벤치마크는 이미 채워진 map에서 조회 작업의 성능을 측정합니다.
func BenchmarkMapLookup(b *testing.B) {
m := make(map[string]int, 100000)
for j := 0; j < 100000; j++ {
key := "key_" + strconv.Itoa(j)
m[key] = j
}
b.ResetTimer() // 초기화 후, 실제 측정 시작
for i := 0; i < b.N; i++ {
key := "key_" + strconv.Itoa(i%100000)
_ = m[key]
}
}
// BenchmarkMapIteration 벤치마크는 map의 모든 항목을 반복(iterate)할 때의 성능을 측정합니다.
func BenchmarkMapIteration(b *testing.B) {
m := make(map[string]int, 100000)
for j := 0; j < 100000; j++ {
key := "key_" + strconv.Itoa(j)
m[key] = j
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
for key, value := range m {
_ = key
_ = value
}
}
}
go@1.22
$ go test -bench=.
goos: darwin
goarch: arm64
pkg: benchmark
BenchmarkMapInsertion-8 157 7229873 ns/op
BenchmarkMapLookup-8 19009912 60.29 ns/op
BenchmarkMapIteration-8 1532 784913 ns/op
PASS
ok benchmark 4.725sgo@1.23
$ go test -bench=.
goos: darwin
goarch: arm64
pkg: benchmark
cpu: Apple M1 Pro
BenchmarkMapInsertion-8 158 7385071 ns/op
BenchmarkMapLookup-8 18329238 61.84 ns/op
BenchmarkMapIteration-8 1588 750383 ns/op
PASS
ok benchmark 4.501sgo@1.24
$ go test -bench=.
goos: darwin
goarch: arm64
pkg: benchmark
cpu: Apple M1 Pro
BenchmarkMapInsertion-8 184 6352783 ns/op
BenchmarkMapLookup-8 24802206 44.65 ns/op
BenchmarkMapIteration-8 2146 551209 ns/op
PASS보신 벤치마크 결과에서 Go 1.24 버전이 전반적으로 map 연산에서 개선되었음을 확인할 수 있습니다. 각 벤치마크별로 살펴보면:
삽입 (BenchmarkMapInsertion)
- Go 1.22: 7,229,873 ns/op
- Go 1.23: 7,385,071 ns/op
- Go 1.24: 6,352,783 ns/op
→ Go 1.24에서는 삽입 시간이 약 12~16% 단축되었습니다.
조회 (BenchmarkMapLookup)
- Go 1.22: 60.29 ns/op
- Go 1.23: 61.84 ns/op
- Go 1.24: 44.65 ns/op
→ 조회 작업은 Go 1.24에서 약 25~28% 빨라진 것을 볼 수 있습니다.
반복 (BenchmarkMapIteration)
- Go 1.22: 784,913 ns/op
- Go 1.23: 750,383 ns/op
- Go 1.24: 551,209 ns/op
→ 반복 작업에서도 Go 1.24가 30% 정도 더 빠릅니다.
결론
Go 1.24에서 Swiss Table을 이용한 Map 성능 향상에 대해 알아보았고, 실제 성능 테스트를 통해 더욱 체감할 수 있었습니다.
CNCF 오픈소스 대부분이 Go로 만들어졌기 때문에, 추후 Go 1.24로의 업데이트가 진행된다면 성능 향상이 유의미하게 이루어질 것 같다는 생각이 듭니다.
또한, Go로 백엔드 서버를 만들었다면 1.24로 버전업을 진행하고 성능 테스트를 진행하는 것도 괜찮을 것 같다고 생각합니다.
