Abstract
- emergent abilities : larger-scale models의 능력이 smaller-scale models에서 모두 나타나지 않는다.
- 특징 : sharpness, unpredictability
- 세 가지 방식으로 test
- make, test and confirm three predictions on the effect of metric choice using the InstructGPT/GPT-3 family on tasks with claimed emergent abilities
- make, test and confirm two predictions about metric choices in a meta-analysis of emergent abilities on BIG-Bench
- show how to choose metrics
1. Introduction
- P.W. Anderson’s “More Is Different” : 시스템의 복잡성이 증가할수록 시스템의 미시적인 세부 사항을 정확하게 예측할 수 없는 새로운 특성이 실현될 수 있다.
- LLM에서 해당 상황이 발현된 것을 "emergent abilities"라고 한다.
- "emergent abilities of LLMs" : abilities that are not present in smaller-scale models but are present in large-scale models; thus they cannot be predited by simply extrapolating the performance improvements on smaller-scale models
- GPT-3 유형들에서 처음 발견되었다.
- emergent abilities의 두 가지 특징
1. Sharpness : transitioning seemingly instantaneously from not present to present
2. Unpredictability : transistioning at seemingly unforeseeable model scales - 어떤 것이 해당 특성들을 발현하게 하는가? 어떤 것이 언제 발현하도록 조절하는가? 원하는 특성을 빨리 발현시키고 원하지 않는 것을 발현시키지 않는 방법은 무엇인가?
- 연구자가 선택한 평가 지표에 의해 나타날 수 있는 현상임. 특히, 비선형적이거나 불연속한 지표를 사용할 경우, 모델의 성늘 개선이 급격하고 예측 불가능하게 보일 수 있음.
- emergent abilities는 AI 안전성 및 정렬 (AI safety and alignment) 문제와 밀접하게 연관이 있음. 큰 규모의 모델이 원치 않는 능력을 갑자기 습득할 가능성에 대한 우려가 커짐
- 해당 논문은 emergent abilities에 대한 기존의 이해를 도전하며, 이러한 능력이 실제로 모델이 스케일링됨에 따라 발생하는 근본적인 문제가 아닌, 연구자의 분석 방식에 의해 유도된 환상일 수 있음을 본다.
2. Alternative Explanation for Emergent Abilities
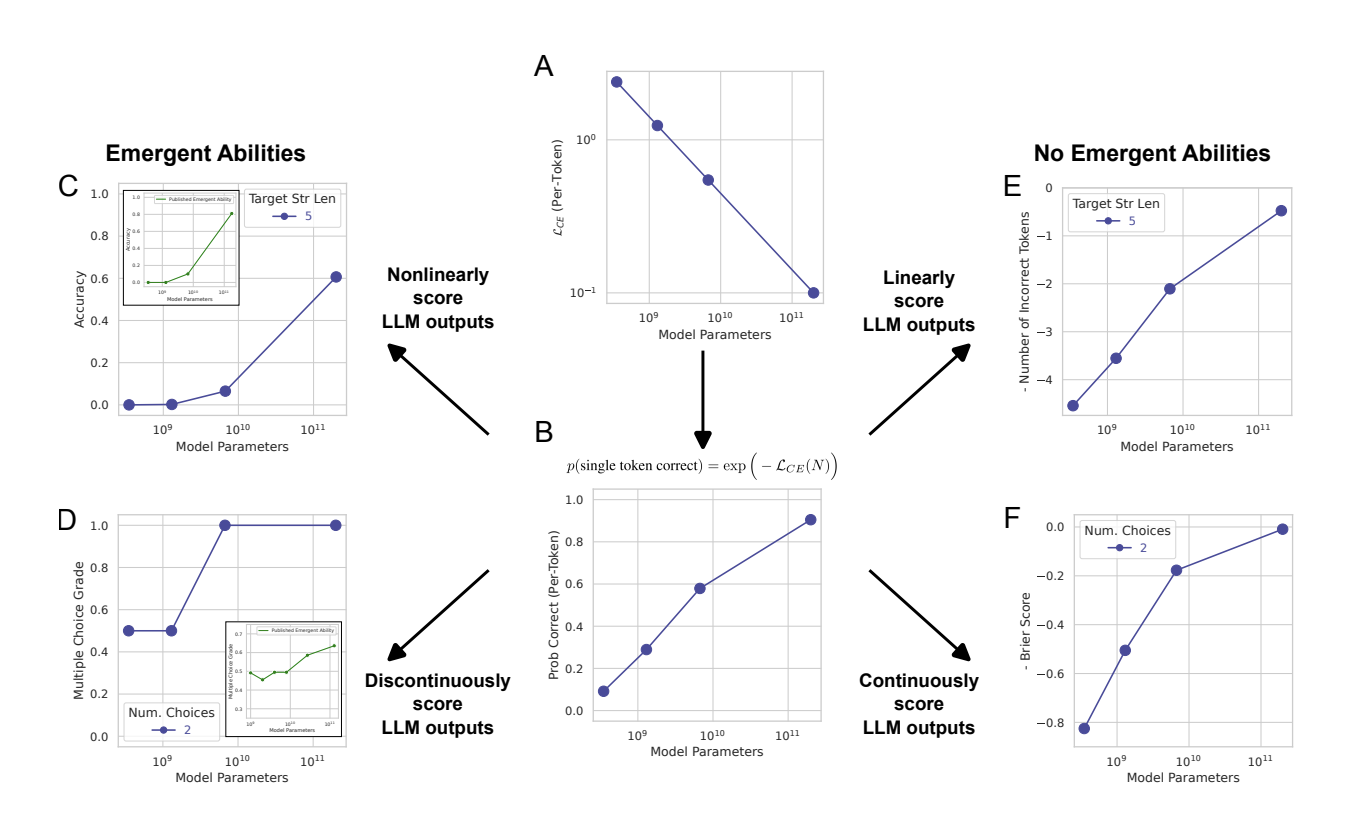
-
모델의 smooth, continuous, predictable 변화가 performance에서는 어떻게 급격하고 예측 불가능하게 나타날 수 있는가?
-
대규모 언어 모델의 성능은 일반적으로 모델 크기가 커짐에 따라 부드럽고 예측 가능하게 개선된다. 이는 Neural scaling laws과 일치하는 관찰이다. 하지만, 연구자가 사용하는 특정 지표는 이러한 부드러운 변화를 급격한 변화로 오해하게 할 수 있다.
-
그림의 A에서 각 모형의 토큰당 교차 엔트로피가 거듭제곱 법칙으로 떨어진다고 가정
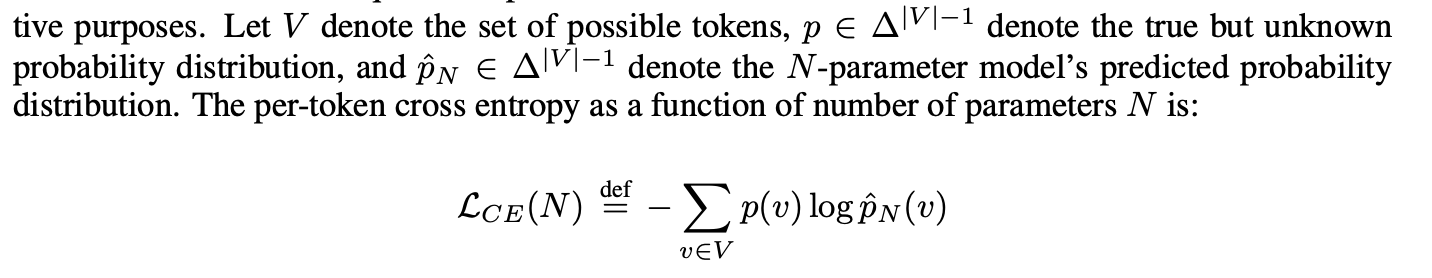
-
연구자가 어떤 지표를 사용하느냐에 따라 모델의 성능 개선이 다르게 해석될 수 있다. 예를 들어, 정확도(Accuracy)와 같은 지표는 모든 출력 토큰이 정확해야 하는 반면, 토큰 편집 거리(Token Edit Distance) 같은 지표는 부분적인 오류를 허용한다. 따라서 정확도를 사용할 경우 작은 모델의 성능이 과소평가될 수 있으며, 큰 모델에서 갑자기 높은 정확도가 나타나는 것처럼 보일 수 있다.
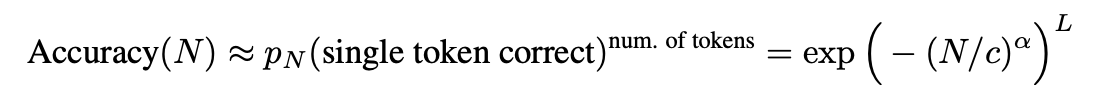
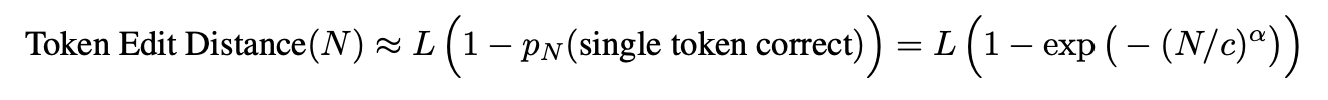
-
emergent abilities이 실제로 모델의 근본적인 변화를 반영하는 것이 아니라, 연구자의 평가 방식에 따라 다른 결과일 수 있음을 제안한다. 따라서, 연구자들은 모델의 성능을 평가할 때 다양한 지표를 고려하고, 특정 지표가 결과에 어떠한 영향을 미치는지 주의 깊게 고려해야 한다.
3. Analyzing InstructGPT/GPT-3's Emergent Arithmetic Abilities
- GPT에 집중적으로 실험을 진행
- 3가지 예측을 진행
- metric : nonlinear or discontinuous metric → linear or continuous metric
비선형 또는 불연속적 지표에서 선형 또는 연속적 지표로 변경하면 모델 성능의 개선이 부드럽고 예측 가능하게 나타날 것이다. - nonlinear metric : increasing the resoultion of measured model performance by increasing the test dataset size
비선형 지표를 사용할 경우, 테스트 데이터셋의 크기를 증가시켜 성능 측정의 해상도를 높이면, 모델 성능의 무드러운 개선이 나타날 것이다. - Regardless of metric, increasing the target string length should predictably affect the model's performance
타겟 문자열 길이가 증가함에 따라, 모델 성능이 예측 가능한 방식으로 변화할 것이다.
- 2-shot multiplication between two 2-digit integers and 2-shot addition between two 4-digit integers
4. Meta-Analysis of Claimed Emergent Abilities
- emergent abilities 과 지표와의 관계 : emergent abilities이 특정 지표에 따라 달라진다. 특히, 비선형적 또는 불연속적 지표를 사용할 경우 emergent abilities가 보고되는 경우가 많았으며, 이는 모델의 성능 변화를 과대평가하는 경향이 있음을 말한다.

- BIG-Bench 벤치마크 분석 : BIG-Bench 벤치마크에서 사용된 다양한 지표들을 분석한 결과과, 대부분의 지표에서는 emergent abilities가 보고되지 않았다. Emergent abilities가 관찰된 지표는 소수에 불과하며, 이러한 지표들은 주로 비선형적이거나 불연속적인 특성을 가지고 있었다.
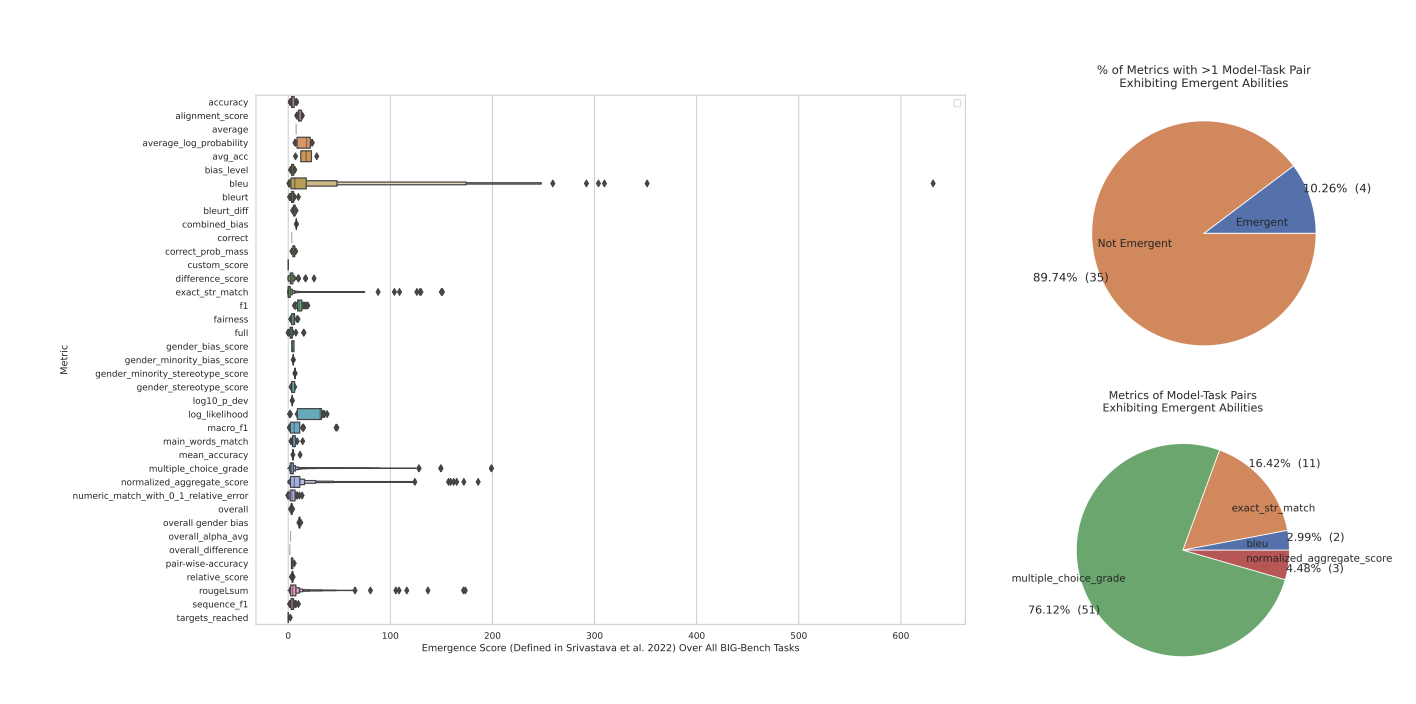
- 지표 변경에 따른 emergent abilities의 변화 : 특정 작업에서 emergent abilities가 관찰된 경우, 지표를 선형적 또는 연속적인 다른 지표로 변경했을 때 등장 능력이 사라지는 경우가 있었다. 이는 emergent abilities가 실제로 모델의 근본적인 변화를 반영하는 것이 아니라, 사용된 평가 지표에 의해 유도될 수 있음을 보여준다.

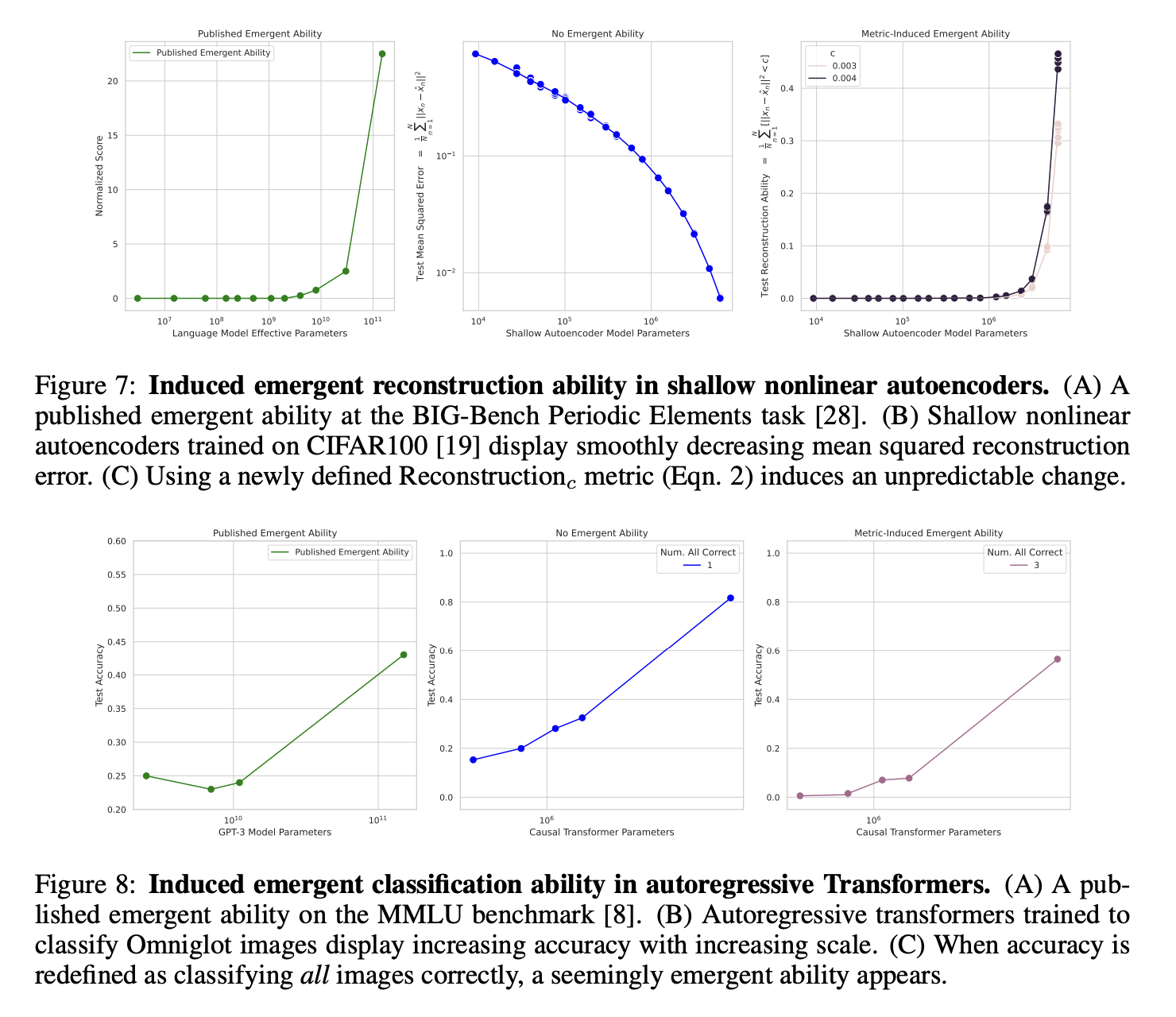
5. Inducing Emergent Abilities in Networks on Vision Tasks
- 비전작업, 특히 CIFAR100 이미지 데이터셋에서의 이미지 재구성과 같은 작업을 통해 네트워크의 능력을 평가한다.
- fully connected networks, convolutional networks, self-attention networks 등 다양한 네트워크 아키텍처를 포함한다.
- 평가 지표를 변경함으로써 네크워크에서 emergent abilites가 나타나거나 사라지게 할 수 있음을 보여준다. 예를 들어, 비선형적 또는 불연속적인 지표를 사용할 때 네크워크가 특정 작업에서 갑작스럽게 높은 성능을 보이는 것처럼 보이게 할 수 있다.
6. Related Work
...
7. Discussion
- 대규모 언어 모델에서 관찰된 등장 능력이 실제로는 평가 지표의 선택에 의해 유발된 현상일 가능성이 높다.
- 또한, AI 연구에서 모델의 성능을 평가할 때 사용하는 지표의 중요성을 재확인하며, 연구자들이 결과를 해석할 때 지표 선택이 어떠한 영향을 미치는지 인식해야 함.
- AI 모델의 설계와 평가, AI 안전성 연구에 어떤 영향을 미칠 수 있음. 모델의 스케일링에 따른 성능 변화를 이해하고 예측하는 것은 AI 기술의 발전에 중요하며, 연구자들은 이러한 변화를 정확하게 측정하고 해석하기 위해 다양한 평가 지표를 고려해야 한다.
- 논문은 연구자들이 AI 모델의 성능 평가를 위해 사용하는 지표를 신중히 선택하고, 다양한 지표를 사용하여 모델의 능력을 종합적으로 평가할 필요성을 강조.
