1. Spark 파일 포맷 종류
Unstructured - Semi-Structured - Structured.
- Text - JSON,XML,CSV - PARQUET,AVRO,ORC,SequenceFile
- Structured는 사람의 눈으로 읽을 수가 없음. 바이너리 파일.
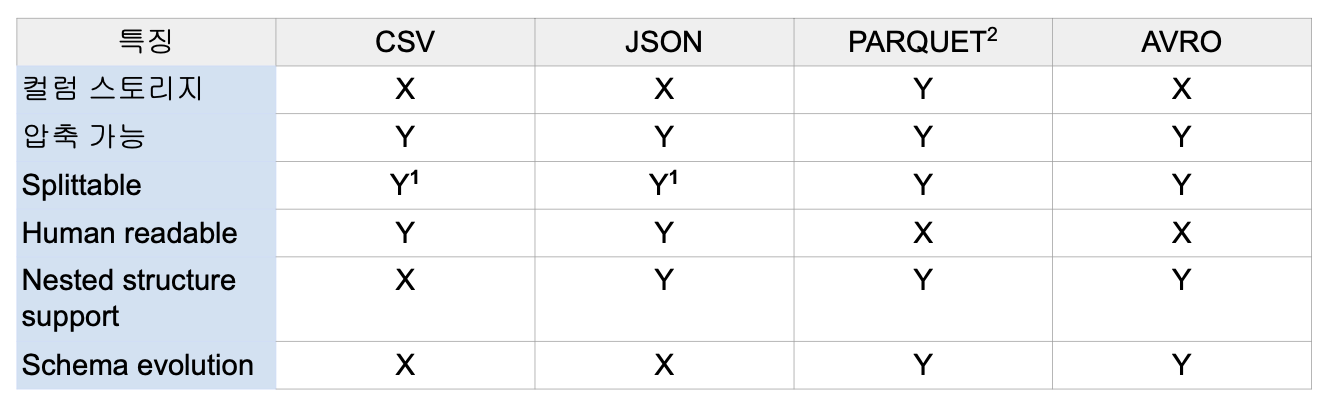
Parquet.
- Spark의 기본 파일 포맷.
- 하나의 데이터 블록은 하나의 row group으로 구성.
실습 1. DataFrame을 다른 포맷으로 저장하기.
- sparkSession을 생성 시,
.config("spark.jars.packages", "org.apache.spark:spark-avro_2.12:3.3.1")처럼 avro 컨피그를 별도로 지정.df2 = df.repartition()으로 데이터프레임의 파티션 수 나누기 가능.df3 = df2.coalesce()으로 데이터프레임의 파티션 수 합치기 가능.df.write.format("avro")....처럼 파일 포맷 지정하여 저장 가능.- 파티션 수에 맞춰서 파일 수가 나눠서 저장됨.
실습 2. Parquet 파일로 Schema Evolution 실습.
spark.read.parquet("")처럼 parquet 파일을 데이터프레임으로 읽어 올 수 있음.spark.read.option("mergeSchema", True).parquet("*.parquet")처럼 스키마가 다른 모든 parquet 파일을 하나로 통합하여 읽을 수 있음. 레코드가 빈 곳에는 null 값이 자동으로 들어 감.
2. Spark 내부 동작
Execution Plan.
spark.read.option("header", True).csv("test.csv").where("gender <> 'F'").select("name", "gender").groupby("gender").count().show()해당 데이터프레임을 기준으로.- 위 데이터프레임의 수행 순서는 다음과 같음. WHERE(Narrow) -> SELECT(Narrow) -> GROUP BY(Wide) -> COUNT(Narrow) -> SHOW(Action).
- Action이 실행되어야만 그 앞의 순서들이 실제로 실행됨. 그 전에는 실행 X.
- Action 전 과정은 Transformation이라고 부름.
- 최적화를 위해서 오퍼레이션 실행을 최대한 늦춤.
Transformation.
- Narrow Transformation: 독립적인 파티션 작업. select, filter, ..
- Wide Transformation: 셔플링 필요한 파티션 작업. group by, ...
Jobs, Stages, Tasks.
- Action은 Job을 하나 만들어 내며, 코드가 실제로 실행됨.
- Job은 하나 이상의 Stage로 구성됨. json read 시에도 하나이 잡이 생성됨.
- Stage는 셔플링이 발생하는 경우에 생기며, DAG의 형태로 구성된 Task들로 구성됨.
- Task는 가장 작은 실행 유닛으로 Executor에 의해 실행됨.
2. Bucketing과 FS Partitioning
Bucketing, File System Partitioning.
- 둘 다 Hive 메타스토어 사용이 필요함: saveAsTable.
- 둘 다 데이터 저장을, 이후 반복 처리에 최적화된 방법으로 하는 것. 리소스와 시간 단축.
- Bucketing은 셔플링을 최소화하는 것이 주 목적. Aggregation 등이 많이 사용되는 칼럼 데이터를 특정 칼럼 기준으로 테이블을 저장함.
- File System Partitioning.
- Hive에서 많이 사용됨.
- 데이터의 특정 칼럼을 기준으로 폴더 구조를 만들어 데이터 저장을 최적화함.
- 해당 칼럼들을 Partition Key라고 부름.
Bucketing.
- DataFrame을 특정 칼럼을 기준으로 나눠서 테이블로 저장.
- DataFrameWriter.bucketBy(버킷 수, 기준 칼럼)을 통해 사용.
- 데이터의 톡성을 명확히 이해하고 있는 상황에서 최적화를 위해 사용.
File System Partitioning.
- 데이터를 Partition Key 기반 폴더 구조로 나눠서 저장하는 방법. (Hive의 partitioning 개념과 동일)
- 굉장히 큰 로그 파일을 어떻게 저장할까? -> 로그 파일은 시간 단위로 처리를 많이 하기에 처음부터 데이터를 연도/월/일의 폴더 구조로 저장함. -> 데이터 읽기 과정을 최적화. -> 데이터 관리에도 유리함(Retention Policy).
- DataFrameWriter의 partitionBy.
- Partition Key를 기준으로 디렉토리를 생성함.
- Partition Key는 cardinality가 낮은 것을 기준으로 잡아야 함.

천천히, 그리고 꾸준히.