1. Spark 실습
-
터미널에서
pyspark으로 실행. -
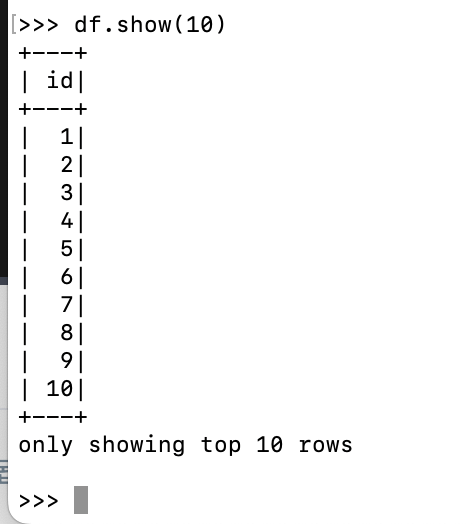
df = spark.range(1, 1000000).toDF("id"): 1부터 999,999들의 값들은 갖는 레코드로 구성이 된 RDD를 만든 후, DF으로 바꾸면서 필드명은 id로 줌. -
df.show(10): df의 10개의 레코드를 보여 줌. id 칼럼에 값들이 입력된 것을 확인 가능. -
df10 = df.repartition(10): 테스트를 위해 파티션을 10개로 만듦. -
from pyspark.sql.functions import expr: expr 함수를 임포트. -
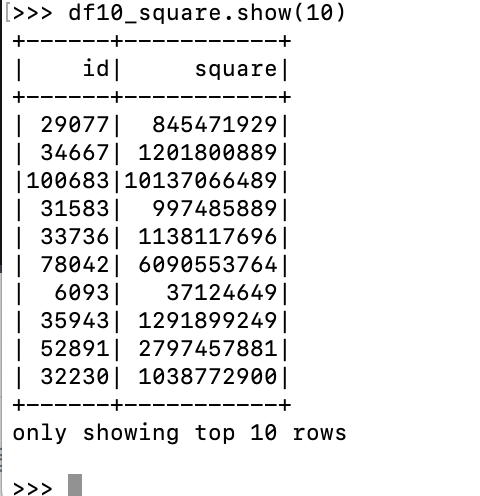
df10_square = df10.withColumn("square", expr("id*id")): expr 함수를 통해서 기존의 id 칼럼들의 제곱을 "square"라는 새로운 필드로 갖는 df10_square 데이터프레임을 만듦. -
df10_square.cache(): 캐시 확인.
- localhost:4040 Web UI의 Storage에는 아직 아무런 정보가 없는데, 아직 메모리에 올라간 캐싱된 데이터프레임이 없기 때문.
-
df10_square.take(10): 10개 만큼 데이터를 드라이브로 갖고 옴.
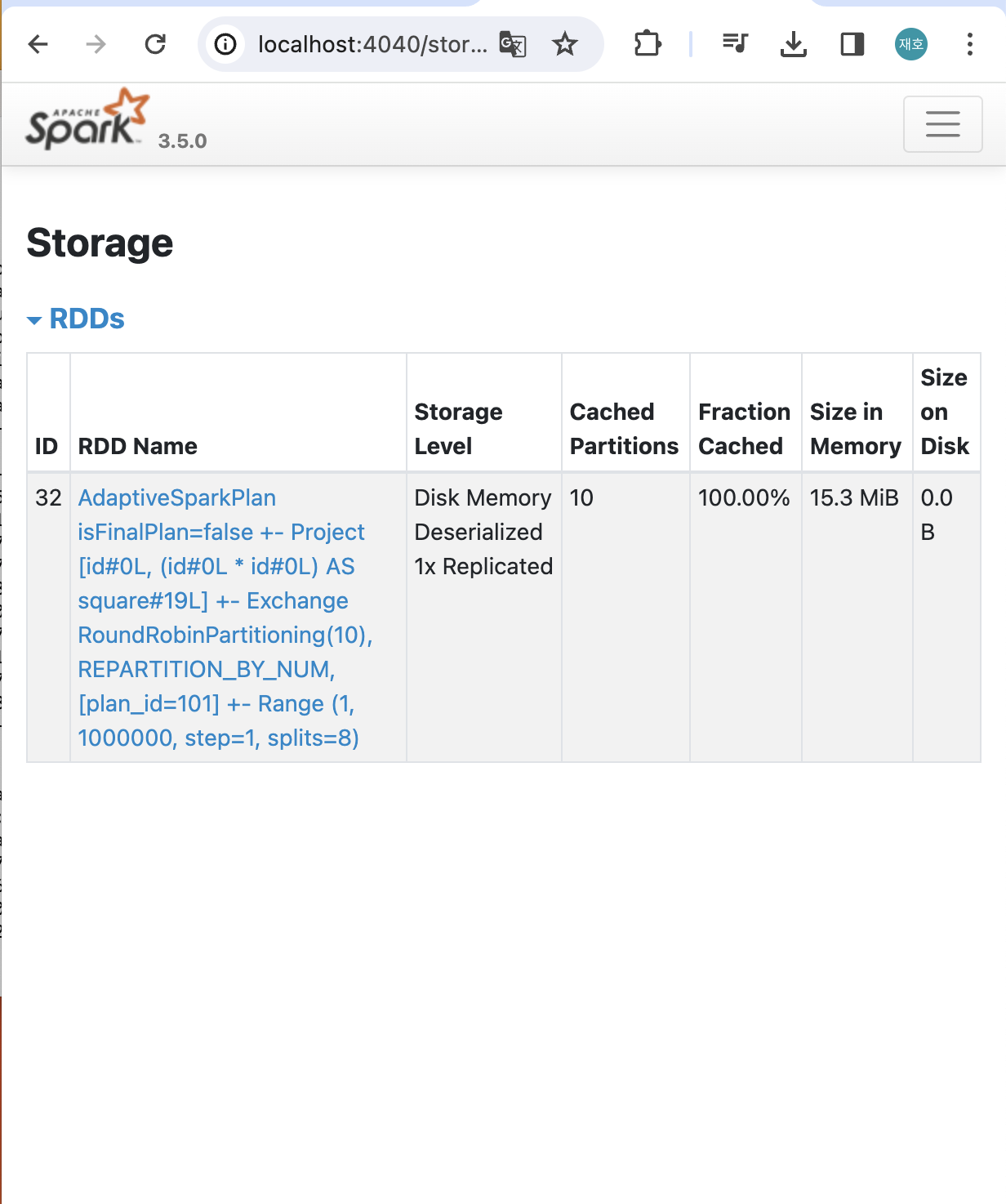
- 10개 중 1개의 파티션이 캐싱된 것을 확인 가능.
-
df10_square.count(): 모든 엔트리들을 메모리에 올라가도록 작업.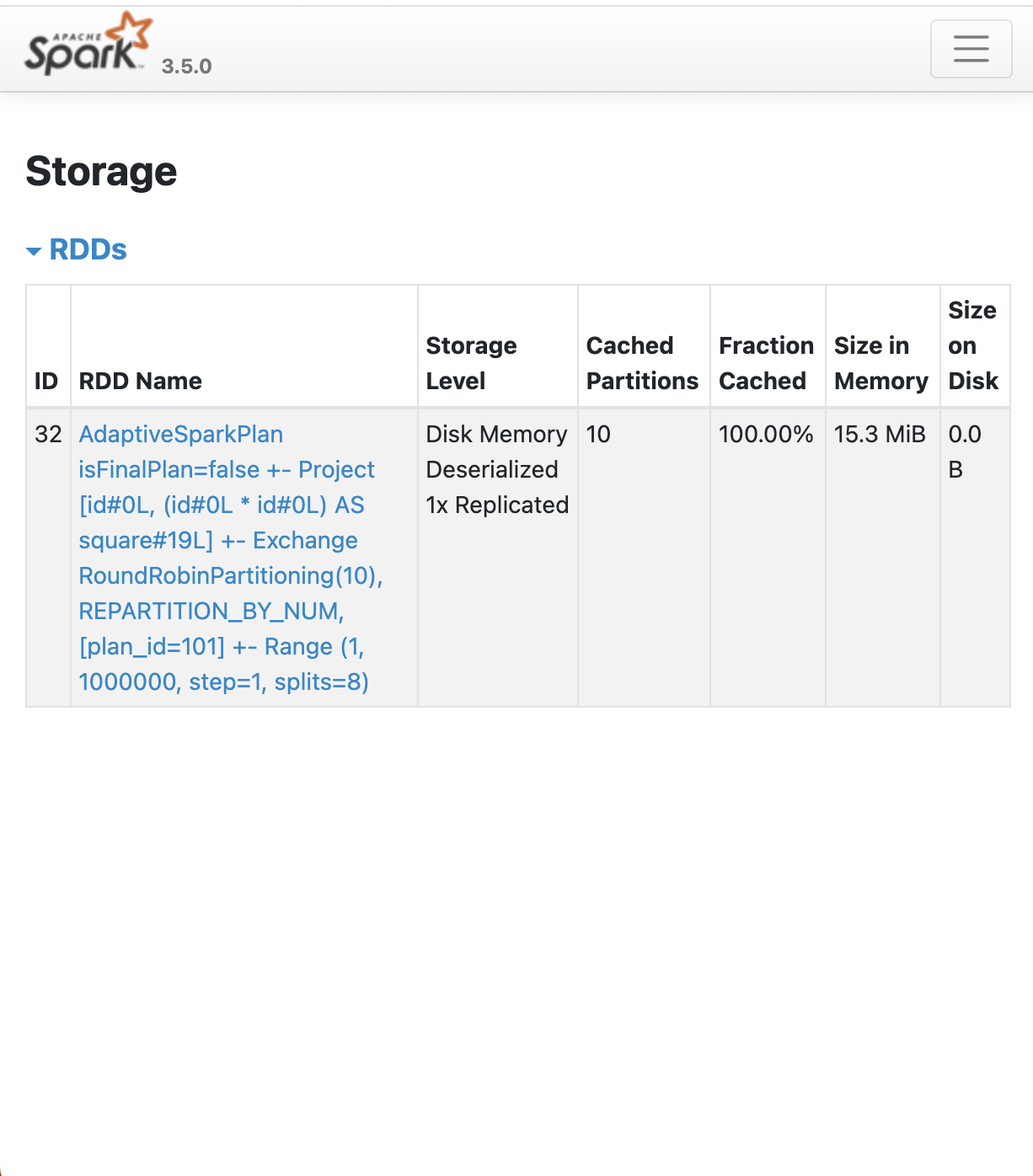
- 모든 파티션 10개가 올라간 것을 확인.
-
df10_square.unpersist(): 할당됐던 캐시 반환.
다음은 spark sql 방식.
-
df10_square.createOrReplaceTempView("df10_square"): df10_suare 라는 뷰 생성. -
spark.sql("CACHE TABLE df10_square"): 캐시 테이블 수행.- 이 경우, 바로 메모리로 올라감.
- 만약 바로 메모리로 올리고 싶지 않다면, LAZY를 추가.
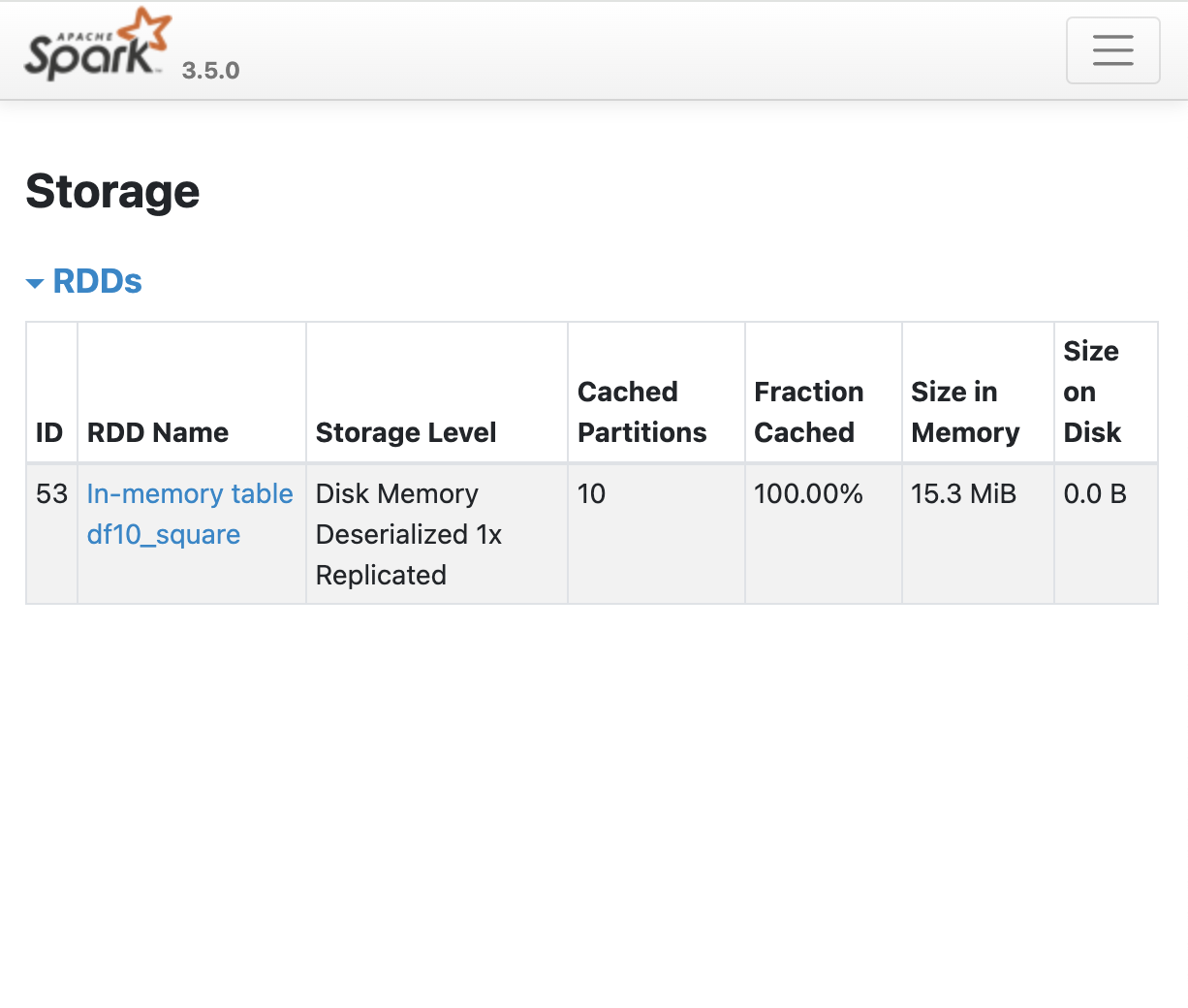
-
spark.sql("UNCACHE TABLE df10_square"): 캐시 메모리 반환. -
spark.catalog.isCached("df10_square"): 캐시되었는지 확인.
- 캐시가 안 된 것을 확인 가능.
RDD -> JVM으로 실행. 최적화를 위해 동일한 작업이 앞 단에서 활용되었는가? 확인.
-
df10_squared_filtered = df10_square.select("id", "square").filter("id > 50000").cache(): df10_square에 id가 50000 이상인 레코드들의 id와 square들을 캐싱한 것을 새 데이터프레임에 저장. -
df10_squared_filtered.count(): 메모리로 올리기 위해 작업. -
df10_square.filter("id > 50000").select("id", "square").count(): 순서를 바꿔서 실행해 보기.df10_square.filter("id > 50000").select("id", "square").explain(): 메모리로 읽었는지 확인하기. (메모리로 읽었다는 흔적 X)- 웹 UI에서 SQL / DataFrame 옵션에서 Details를 통해서 확인하기. (메모리로 읽었다는 흔적 X)
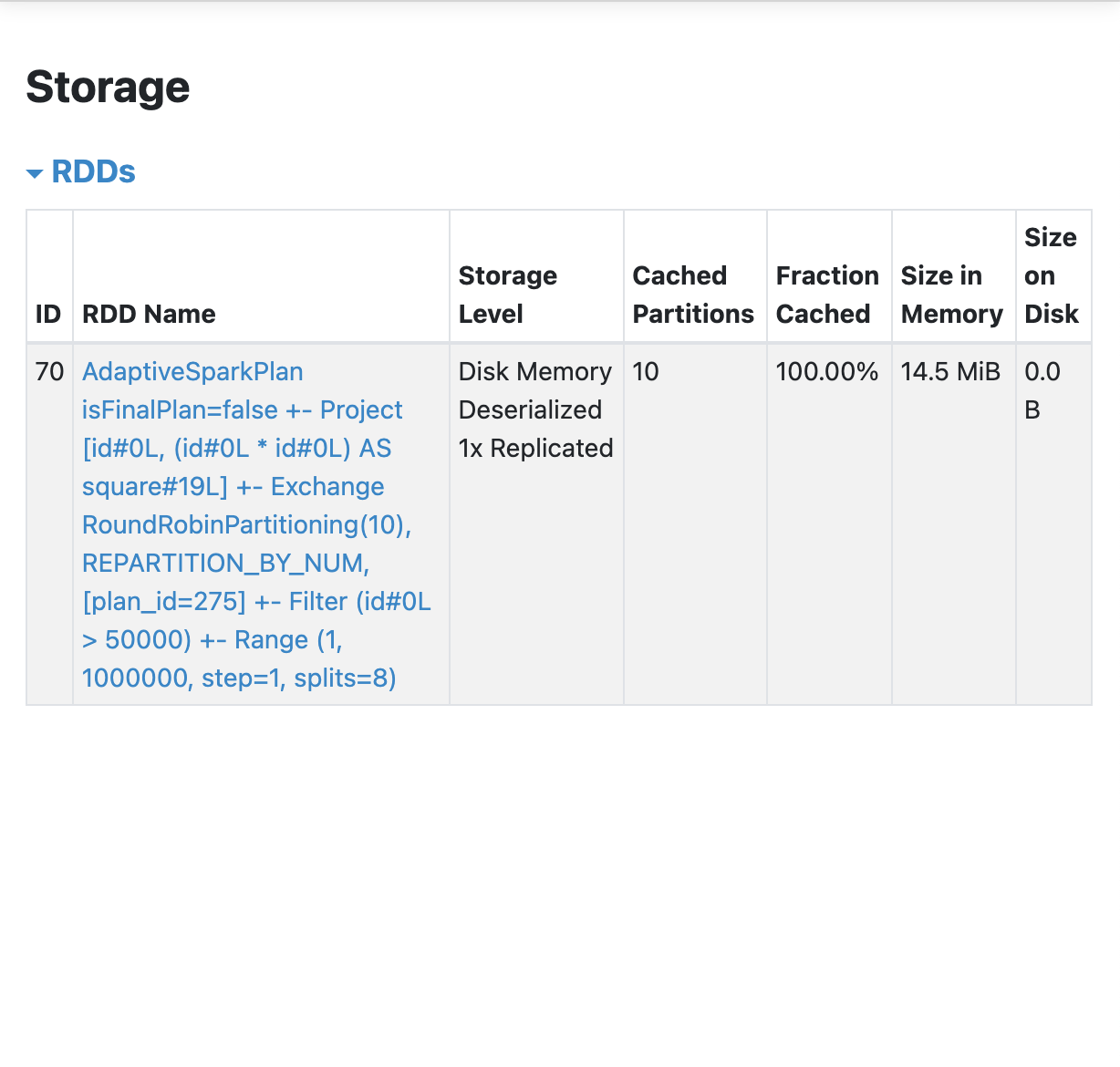
- 결론: 1처럼 새로운 데이터프레임으로 레퍼런스를 만들고, 해당 레퍼런스를 사용하는 것이 캐싱된 것을 사용하는 효율적인 방법임.
df10_squared_filterd.filter("square > 10000").count()처럼 사용할 경우, 캐싱된 것을 사용함.
persist 방식.
... pyspark.StorageLevel(False, True, False, True, 1))``` : 세밀하게 드라이브, 메모리, 등등 설정이 가능함.
정리.
- 캐싱된 데이터 프레임이 재사용되는 것을 분명하게 하기.
.
cachedDF = df.cache(): 캐시를 생성한 경우.cachedDF.select(...): 처럼 생성된 캐시를 활용하기.- 칼럼이 많다면 필요한 칼럼만 캐싱하기.
.
cachedDF = df.select(col1, col2, col3, col4).cache()- 불필요한 캐시는 uncache하기.
- 때로는 매번 새로 데이터프레임을 계산하는 것이 캐싱보다 빠를 수 있음.
.
- 대상 데이터프레임이 큰 경우. (큰 용량은 캐싱하지 않는 것이 좋음.)
- 큰 데이터셋이 Parquet과 같은 포맷으로 존재하는 경우.
- 소수의 데이터프레임만 캐싱하고, 소량의 데이터프레임만 캐싱하고, 캐싱은 너무 믿지 말자.
2. Dynamic Partition Prunning
Dynamic Partition Prunning이란,
- 비 파티션 테이블에 적용돈 필터링을 파티션 테이블에 적용하는 것.
- 예를 들어 규모가 큰 Fact 테이블 order와 규모가 작은 Dimension 테이블 date가 있다고 가정.
<!-- 비효율적인 쿼리 --> SELECT * FROM order o JOIN date d ON o.order_month = d.year_month WHERE d.year = 2022 and d.month = 1<!-- 효율적인 쿼리 --> SELECT * FROM order o JOIN date d ON o.order_month = d.year_month WHERE o.order_month = '2022-02-01'
- 방법1) 필터링을 (규모가 큰)팩트 테이블에 걸기.
- 방법2) 디멘션 테이블 자체를 브로드캐스팅하기.
3. Repartition and Coalesce
Repartition의 사용 이유.
- 파티션 수를 늘리기 위해서 사용. (병렬성 증대)
- 굉장히 큰 파티션이나 Skew 파티션의 크기를 조절하기 위해서.
- 파티션을 분석 패턴에 맞게 분배하기 위해서. (write once, read many)
.
- 어떤 데이터프레임을 특정 칼럼 기준으로 그룹핑하거나 필터링을 자주 하는 경우.
Repartition 방식.
1. 해싱
2. repartitionByRange
- 새로운 파티션을 만들기 위해서 셔플링이 발생함. 따라서 분명한 이유 없이 리파티션 사용 금지. (배보다 배꼽이 더 커진다.)
- 파티션의 수와 칼럼을 인자로 가짐.
- 칼럼이 사용되면 균등한 파티션 크기를 보장할 수 없음. (디폴트 파티션 크기 최대값: 200)
- AQE가 disabled 돼있으면 파티션의 수를 줄이는 용도로 사용이 불가능함. (spark.conf.set("spark.sql.adaptive.enalbed", "false") 처럼 설정.)
해싱 기반 파티션.
- repartition(numPartitions, *cols)의 형태로 사용.
- repartition(5, "city")
- repartition(5, "city", "zipcode")
- repartition("city")
방식 2.
- repartitionByRange(numPartitions, *cols)
- 지정된 칼럼 값의 범위를 기준으로 파티션을 나누는 방식.
- 일정하게 나누지 않음.
Coalesce가 필요한 경우.
- 파티션의 수를 줄이는 용도.
- 셔플링 발생 X, 로컬 파티션들을 머지.
- 칼럼이 사용되며 균등한 파티션 크기 보장 X.
4. DataFrame 관련 힌트
- Spark SQL Optimizer에게 Execution plan을 만듦에 있어 특정한 방식을 사용하도록 제안함. (최적화된 방식으로 변경하기 위해 사용.)
- Partitioning과 Join 관련 힌트가 존재함.
DataFrame Partitioning 관련 힌트.
- COALESCE
- REPARTITION
- REPARTITION_BY_RANGE
- REBALANCE (데이터프레임을 테이블로 저장. AQE가 필요하며 파일의 크기를 최대한 비슷하게 만들어서 저장함.)
df1.join(df2, "id", "inner").hint("COALESCE", 3)
DataFrame Join 관련 힌트. 우선 순위가 높은 순서대로 나열함.
- BROADCAST(작은 데이터프레임을 큰 데이터프레임 파티션으로 셔플링 없이 통 채로 보내는 방법.)
- MERGE
- SHUFFLE_HASH
- SHUFFLE_REPLICATE_NL
SELECT /*+ MERGE(df2) */* FROM df1 JOIN df2 ON df1.order_month = df2.year_month
DataFrame 힌트 사용.
- Spark SQL
.
/*+ hint\[, ...] */SELECT /*+ REPARTITION(3) */ * FROM TABLE: 새로운 데이터프레임을 만드는데 파티션의 수를 3개로 만들어 줘.- DataFrame API
.
- .hint 메서드 사용.
join_df = df1.join(df2, "id", "inner").hint("COALESCE", 3): 이너 조인을 하고 그 결과 데이터프레임의 파티션 수를 3개로 줄여줘.
5. AQE (Adaptivce Query Execution)
Spakr Optimization 역사.
- Spark 1.x : Catalyst Optimizer와 Tungsten Project
- Spark 2.x : CBO (Cost-Based Optimizer)
- 적은 수의 파티션은 병렬성을 낮춘다는 단점이 존재하며, 많은 수의 파티션은 테스크 스케쥴러 및 테스크 생성 관련 오버헤드가 생길 수 있다는 단점이 존재함.
- 따라서, Spark Engine Optimizer가 알아서 파티션의 수를 결정하는 방법을 모색함.
AQE란,
- Dynamic query Optimizer.
- (실시간)런타임 통계를 가지고 쿼리 실행 중간에 쿼리 플랜을 변경해 줌.
- Query -> Job -> Stage -> Task.
- Dynamically coalescing
- Dynamically switching
- Dynamically optimizing
AQE의 동작 방식.
- Stage DAG를 순차적으로 실행.
- 매번 새로운 최적화 기회가 있는 지 조사. (필요하면 다시 실행하거나 플랜 변경.)
Dynamically coalescing shuffle partitions.
SELECT k, SUM(v) FROM t GROUP BY 1 OREDER BY 2 DESC;- 최적화 전) 테이블 스캔 -> Aggregate -> Shuffle -> Aggregate -> Shuffle -> Sort
- 최적화 후) 테이블 스캔 -> Aggregate -> Shuffle -> (COALESCE) -> Aggregate -> Shuffle -> (COALESCE) -> Sort
- 내부적으로 많은 수의 파티션을 일부러 생성. (spark.sql.adaptive.coalescePartitions.initialPartitionNum(200))
- 매 스테이지가 종료될 때 필요하다면 자동으로 Coalesce 수행.
- spark.sql.adaptive.coalescePartitions.parallelismFirst=False로 할 경우, 병렬성 보장을 위해 minPartitionSize에 맞추려고 함. (이 방법을 추천)
실습.
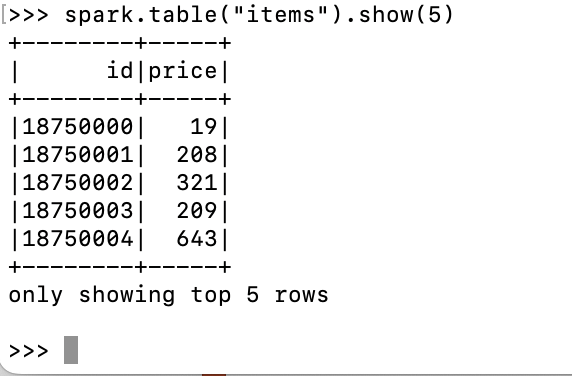
pyspark --num-executors 5 --driver-memory 2g --executor-memory 2g로 파이스팤 실행.spark.sql("CREATE DATABASE IF NOT EXISTS aqe_demo"): DB 생성.spark.sql("DROP TABLE IF EXISTS items")spark.sql("DROP TABLE IF EXISTS sales")
... USING parquet
... AS
... SELECT id,
... CAST(rand() * 1000 AS INT) AS price
... FROM RANGE(30000000);""")spark.table("items").show(5)
spark.sql("""CREATE TABLE sales
... USING parquet
... AS
... SELECT CASE WHEN rand() < 0.8 THEN 100 ELSE CAST(rand() * 30000000 AS INT) END AS item_id,
... CAST(rand() * 100 AS INT) AS quantity,
... DATE_ADD(current_date(), - CAST(rand() * 360 AS INT)) AS date
... FROM RANGE(1000000000)""")spark.table("sales").show(5)spark.conf.set("spark.sql.adaptive.enabled", False)
df_f = spark.sql("""SELECT date, sum(quantity) AS q
... FROM sales
... GROUP BY 1
... ORDER BY 2 DESC""")df_f.count(): 10초 소요df_f.rdd.getNumPartitions(): 기본값인 200이 출력된 것을 확인.spark.conf.set("spark.sql.adaptive.enabled", True)
df_t = spark.sql("""SELECT date, sum(quantity) AS q
... FROM sales
... GROUP BY 1
... ORDER BY 2 DESC""")df_t.count(): 8초 소요df_t.rdd.getNumPartitions(): 1이 출력된 것을 확인.
Dynamically switching join.
- spark.sql.join.preferSortMergeJoin (default=True): 데이터 프레임 조인시 소트 머지 조인 기본 사용.
- spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold (default=0): 해시 조인 시 파티션별로 해시맵 생성에 사용 가능한 최대 크기 지정.
- spark.sql.adaptive.autoBroadcastJoinThreshold : 브로드캐스트 가능한 데이터프레임의 최대 크기.
실습.
yspark --driver-memory 2g --executor-memory 2gspark.conf.set("spark.sql.adaptive.enabled", False): 기본값인 소트 머지로 실행될 것.
df_f = spark.sql("""SELECT date, sum(quantity * price) AS total_price
... FROM sales s
... JOIN items i ON s.item_id = i.id
... WHERE price < 10
... GROUP BY 1
... ORDER BY 2 DESC""")df_f.count(): 8분 소요.spark.conf.set("spark.sql.adaptive.enabled", True): 브로드캐스트 조인 허용.
df_t = spark.sql("""SELECT date, sum(quantity * price) AS total_price
... FROM sales s
... JOIN items i ON s.item_id = i.id
... WHERE price < 10
... GROUP BY 1
... ORDER BY 2 DESC""")df_t.count(): 1분 소요.- aqe가 적용된 방식이 1분으로 소요 시간이 더 짧다.
