1. Redshift 특징
특징 1)
- AWS의 클라우드 기반 빅데이터 웨어하우스.
- 2PB의 데이터까지 처리 가능. (최소 160GB로 시작하여 점진적으로 용량 증감 가능)
- Still OLAP. (프로덕션 DB로 사용 X. 느린 속도, 큰 용량.)
- 칼럼 기반 스토리지. (칼럼별 압축이 가능하여 칼럼 추가 및 삭제가 아주 빠름.)
특징 2)
- 벌크 업데이트 지원. (레코드 파일을 S3로 복사 후, COPY 커맨드로 Redshift에 일괄 복사 가능.)
- 기본: 고정 요량/비용 SQL 엔진.
- 추가: 가변 비용 옵션 제공. (Redshift Serverless)
- 데이터 공유 기능. (다른 AWS 계정과 데이터 공유 가능. Snowflake의 기능 카피.)
- 다른 데이터 웨어하우스와 마찬가지로 pk uniqueness를 보장하지 않음.
특징 3)
- PostgreSQL 8.x와 SQL이 호환됨. (대부분의 기능 지원.)
- PostgreSQL 8.x를 지원하는 툴이나 라이브러리 액세스 가능. (JDBC/ODBC)
- SQL이 메인 언어. (따라서, 데이터 모델링이 매우 중요함.)
특징 4)
- 용량이 부족해질 때마다 새로운 노드(서버)를 추가하는 방식으로 스케일링 (Scale Out)
- Scale Out(서버 추가) vs. Scale Up(서버 추가X. 대신 사양을 높임.)
- Scale Out은 Resizing 옵션을 활성화하여 Auto Scaling 설정이 가능함.
- 가변 비용 옵션: Redshift Serverless. 혹은 Snowflake, BigQuery
- 가변 비용 옵션의 단점: 비용 예측이 불가능함.
특징 5)
- Redshift 최적화는 매우 복잡함.
- Redshfit는 노드의 수가 다수가 되면, 한 테이블의 레코드들을 저장할 때, 어느 노드로 저장할 지 등을 개발자가 지정해 줘야 함.
- 분산 저장이 되어야 함.
1-1. Redshift의 레코드 분배와 저장 방식
- Redshift가 두 대 이상의 노드로 구성되면 그 시점부터 테이블 최적화가 중요해짐.
- 한 테이블의 레코드들을 어떻게 다수의 노드로 분배할 것인지..
- Distkey, Diststyle, Sortkey 라는 세 개의 키워드를 알아야 함.
- Diststyle: 레코드 분배가 어떻게 이루어지는지를 결정. (all, even, key. default=even. all은 모든 노드에 전체 카피됨, even은 round-robin 방식으로 공평하게 카피, key는 Distkey)
- Distkey: 레코드가 어떤 칼럼을 기준으로 배포되는지를 나타냄. (Diststyle이 key인 경우에만 사용.)
- Sortkey: 레코드가 한 노드 내에서 어떤 칼럼을 기준으로 정렬되는지를 나타냄. (보통 타임스탬프 필드를 기준으로 함.)
만약 Diststyle이 key인 경우 칼럼 선택이 잘못되면?
- 레코드 분포에 Skew가 발생 -> 분산 처리의 효율성 문제.
- BigQuery나 Snowflake는 알아서 최적화를 해줌.
SQL 예)
CREATE TABLE table_name (
column1 INT,
col2 VARCHAR(50),
...
) DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3);
-- table_name의 레코드들은 col1을 기준으로 분배되고,
-- 노드 내에서 col3을 기준으로 정렬됨.1-2. Redshift의 벌크 업데이트 - COPY SQL
- Data source -> Airflow -> S3 -> RedShift(By COPY SQL)
1-3. Redshift의 데이터 타입
기본)
- SAMLLINT, INTEGER, BIGINT, DECIMAL
- REAL, DOUBLE PRECISION
- BOOLEAN
- CHAR, VARCHAR, TEXT, Redshift의 CHAR는 Byte 단위.
- DATE, TIMESTAMP
고급)
- GEOMETRY
- GEOGRAPHY
- HLLSKETCH
- SUPER
2. Redshift Serverless 설치
- Amazon Redshift 서비스에서 Redshift Serverless 생성.
Google Colab에서 연동하기 위해 다음과 같이 설정.
위 이미지에서 작업 그룹 선택.
선택 후, 엔드포인트를 복사.
- 연결 방법에는 두 가지 방식이 있다.
- 어드민을 세팅한 후 연결.
- IAM을 통해서 별도의 계정으로 연결.
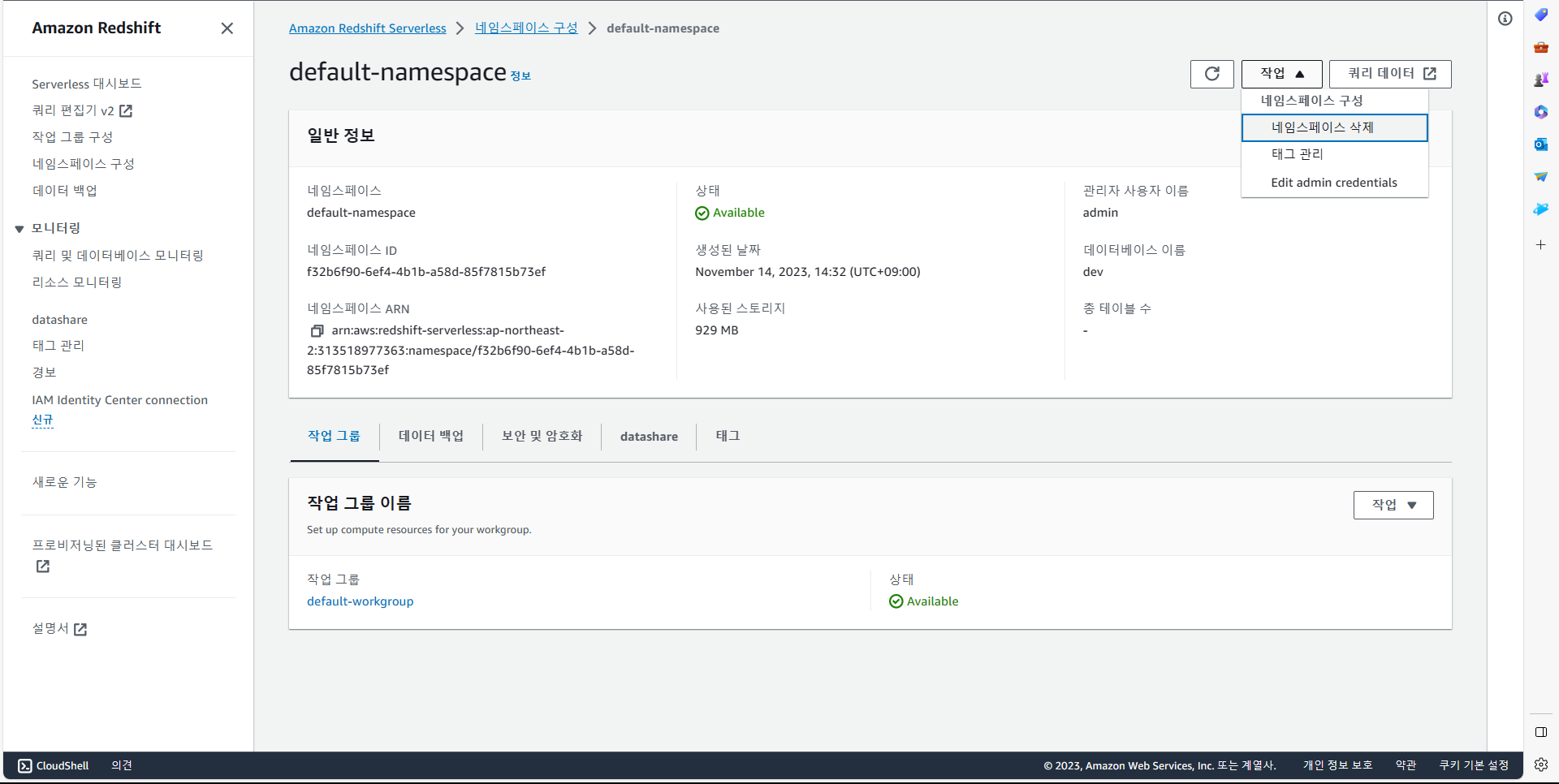
위 이미지에서 네임스페이스를 선택 후, 작업에서 Edit admin credentials 선택.
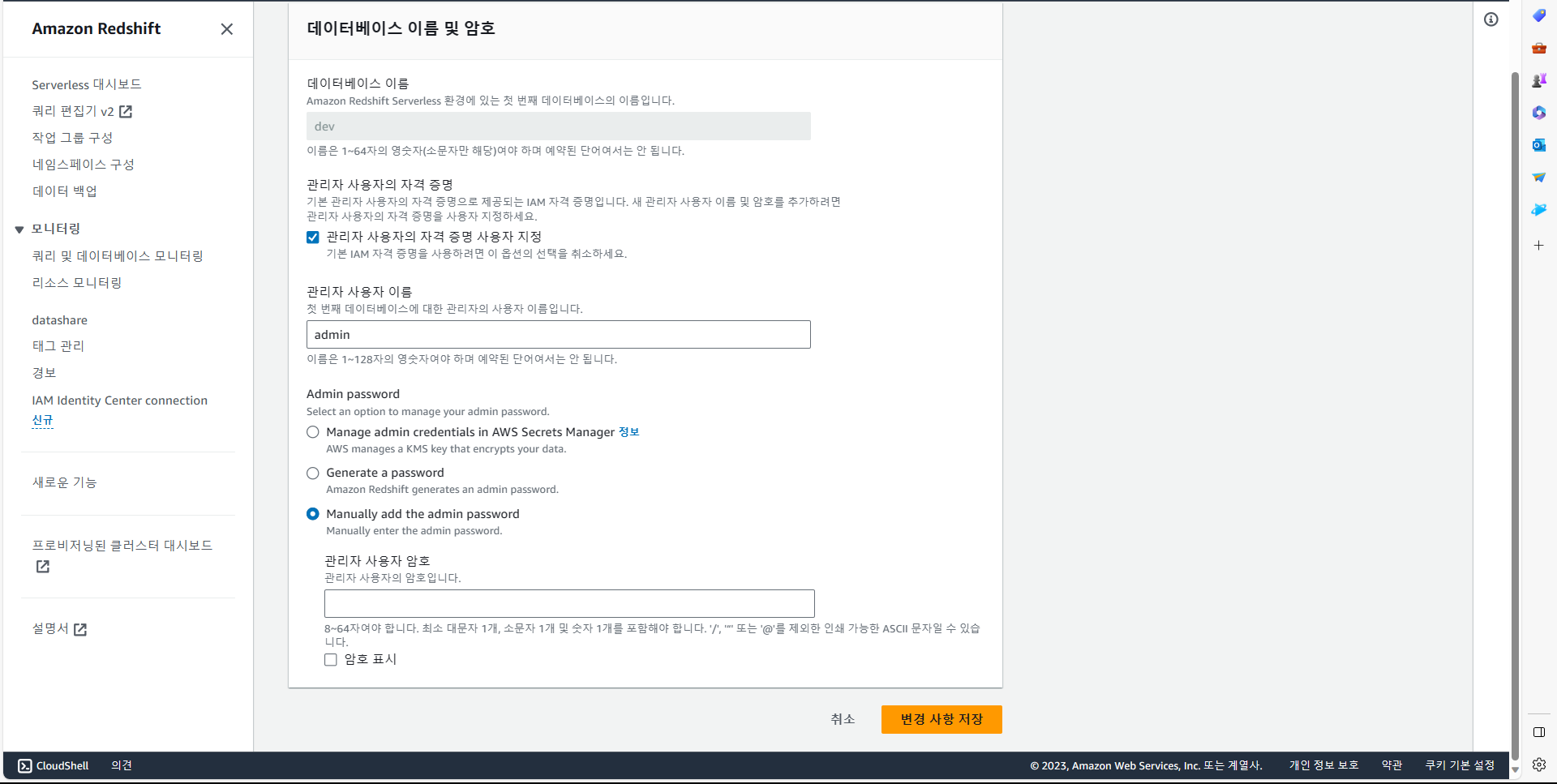
Manually add the admin password를 통해, admin 계정 사용자 암호를 설정.
Google Colab 연결을 위해서 아래 세 가지의 정보와 두 작업 필요.
- 엔드포인트
- 유저네임
- 패스워드
- 작업 그룹 퍼블릭 엑세스 허가.
- 작업 그룹의 VPC 보안 그룹의 인바운드 규칙에서 인바운드 규칙 편집에서 다음과 같이 추가.
Google Colab 연결)
1. %load_ext sql로 sql 설정.
2. %sql postgresql://ID:PW@호스트이름:5439/dev로 노드 연결. * 이때, 만약 connection time out 에러가 발생한다면 public access 활성화 및 VPC 보안 그룹의 인바운드 규칙이 있는지 확인.
3. Redshift 초기 설정 (스키마, 그룹, 유저)
3-1. 스키마(카테고리 폴더)
-
raw_data: ETL 결과가 들어감.
-
analytics: ELT 결과가 들어감.
-
adhoc: 테스트용 테이블이 들어감.
-
pii: 개인 정보가 들어감.
-
(admin 권한이 부여된 상태에서) 다음 코드를 실행하여 위 스키마 생성.
%%sql CREATE SCHEMA raw_data; CREATE SCHEMA analytics; CREATE SCHEMA adhoc; CREATE SCHEMA pii;- 결과 확인
%%sql select * from pg_namespace;
3-2. 사용자(User)
-
사용자(User) 생성.
%%sql CREATE USER username PASSWORD '*****';- 결과 확인.
%%sql select * from pg_user;
3-3. 그룹(역할)
-
보통 권한을, 스키마별로 권한을 부여하거나 그룹별로 권한을 부여하는 식으로 관리함.
-
한 사용자는 다수의 그룹에 속할 수 있음.
-
그룹은 (객체 지향처럼) 계승이 안 된다는 문제가 있음.
-
예시 그룹:
- analytics_users : 데이터 활용하는 개인을 위한 그룹.
- analytics_authors : 데이터 분석가를 위한 그룹.
- pii_users : 어드민을 위한 그룹. 개인 정보 엑세스 가능.
-
그룹 생성.
%%sql CREATE GROUP analytics_users; CREATE GROUP analytics_authors; CREATE GROUP pii_users; -
사용자에게 그룹에 대한 권한 부여.
%%sql ALTER GROUP analytics_users ADD USER username; ALTER GROUP analytics_authors ADD USER username; ALTER GROUP pii_users ADD USER username; -
결과 확인.
%%sql select * from pg_group; -
역할은 그룹과 달리 계승 구조를 만들 수 있음.
-
역할 생성.
%%sql CREATE ROLE staff; CREATE ROLE manager; CREATE ROLE external; -
사용자에게 역할에 대한 권한 부여.
%%sql GRANT ROLE staff TO username; -- staff의 역할 권한을 username의 유저에게 부여. GRANT ROLE staff TO ROLE manager; -- staff의 역할의 기능을 새로운 역할인 manager에게 부여. -
결과 확인.
%%sql select * from SVV_ROLES;
4. Redshift COPY 명령으로 테이블에 레코드 적재하기
4-1. 세팅
크게 다음과 같은 순서로 진행함.
- CSV 파일 -> S3 -> Redshift.
- AWS console에서 S3 bucket을 만들고, csv 파일을 업로드하기.
- raw_data 테스트 테이블 만들기.
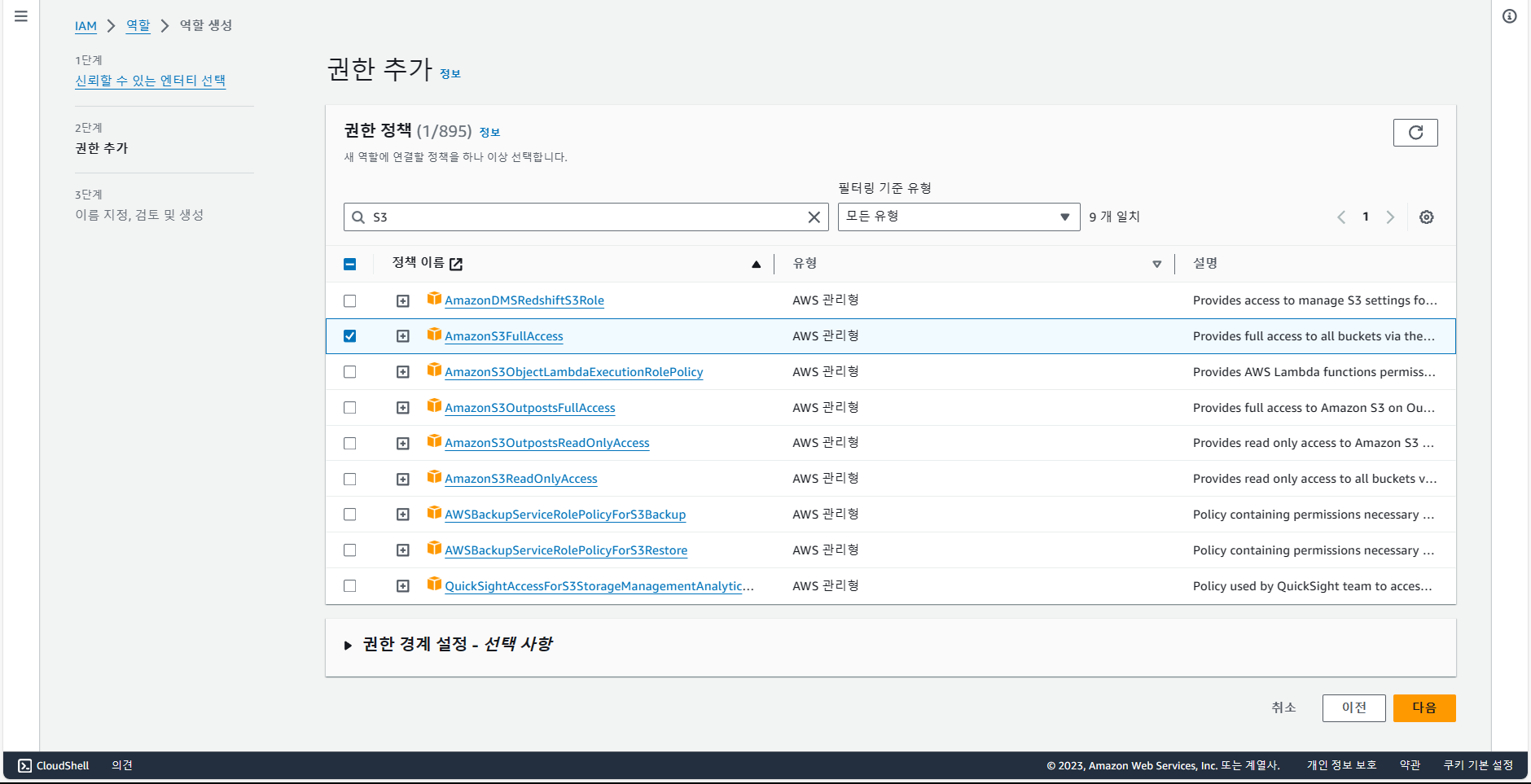
- S3 버킷에 대한 접근 권한 부여하기.
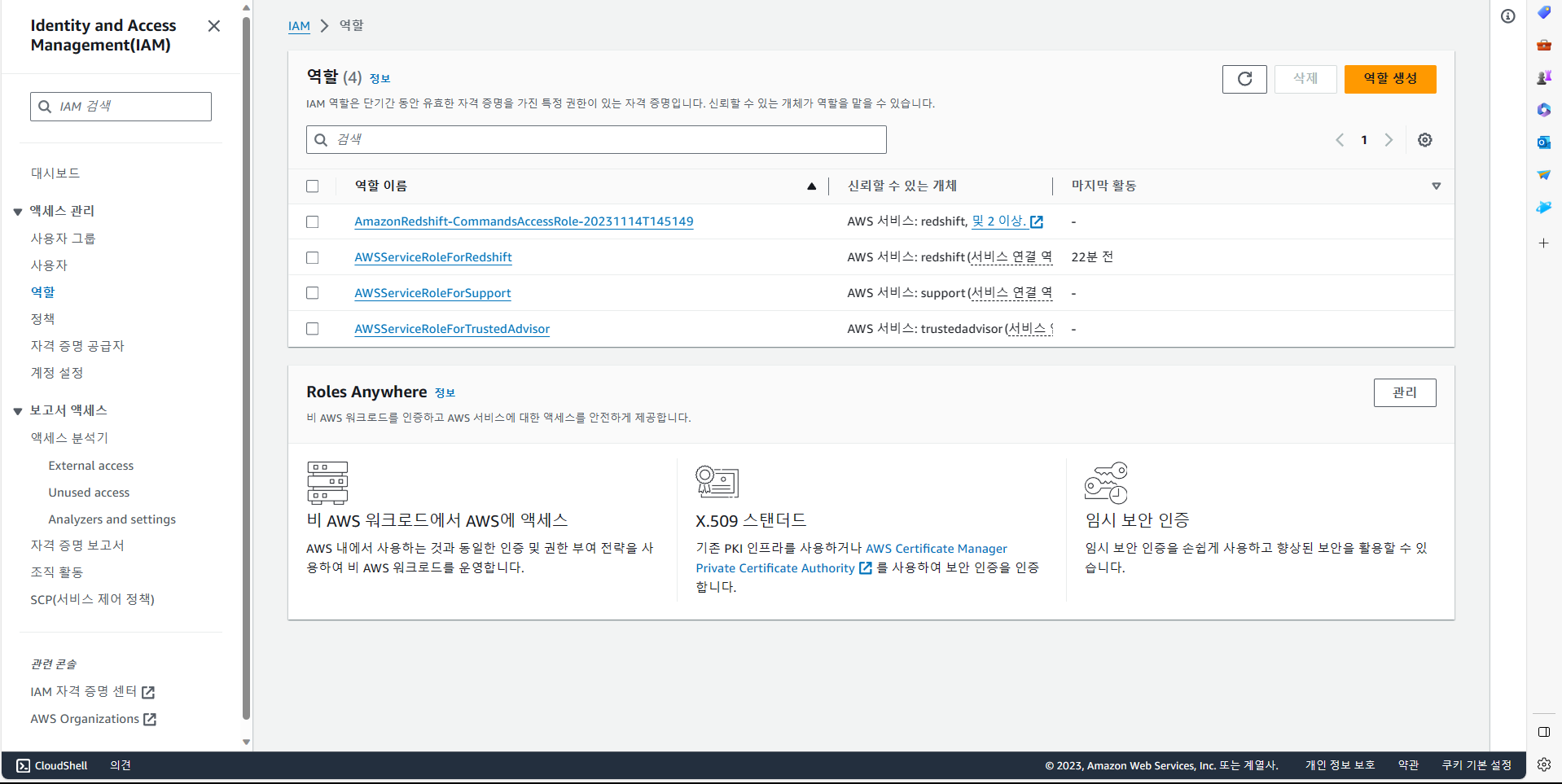
위 화면에서 역할 생성 선택.
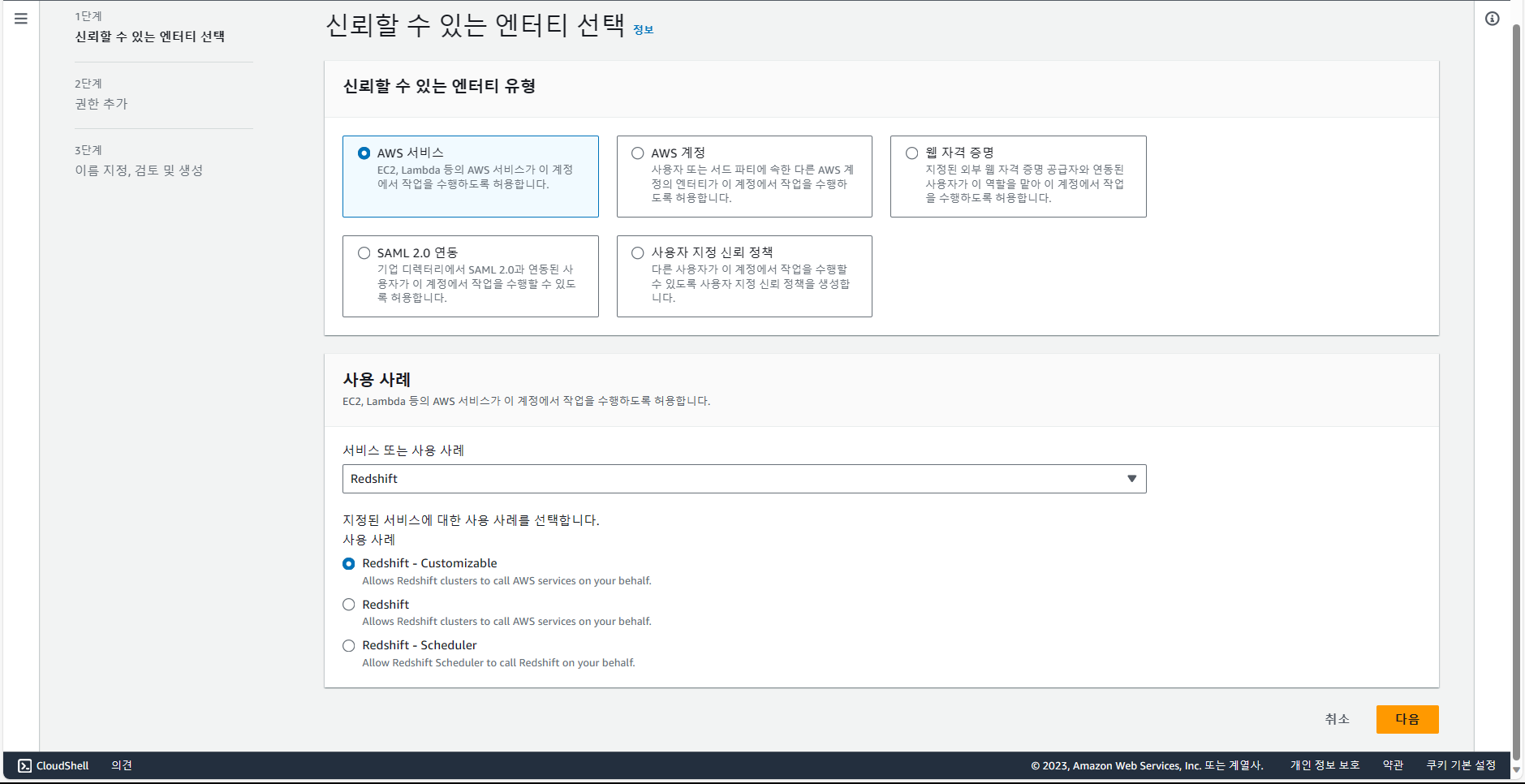
redshift 선택 후, 다음.
S3FullAccess를 선택 후, 다음.
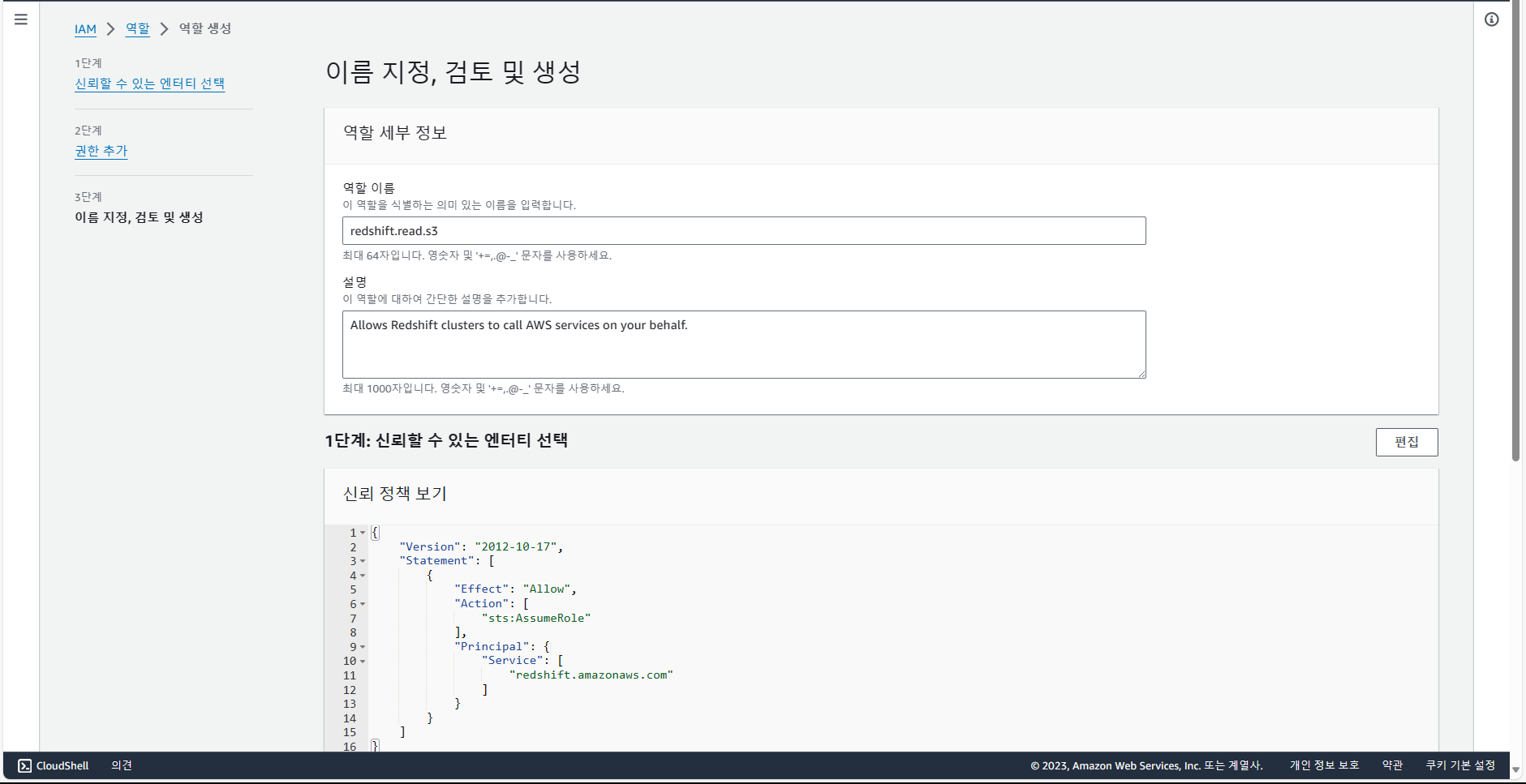
역할 이름을 "redshift.read.s3"로 작성한 다음, 생성.
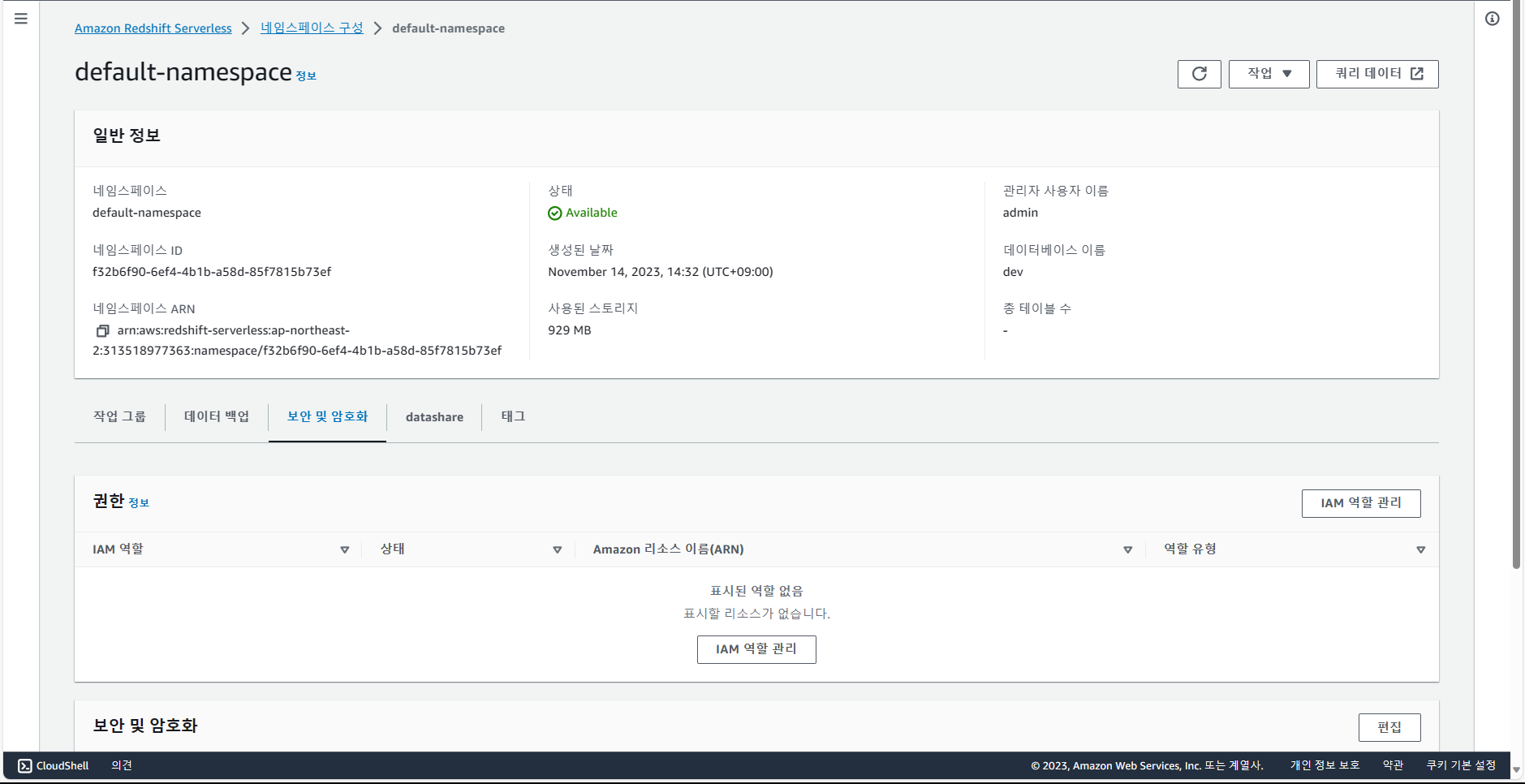
redshift에서 네임스페이스 선택 후, 보안 및 암호화 탭에서 IAM 역할 관리 선택.
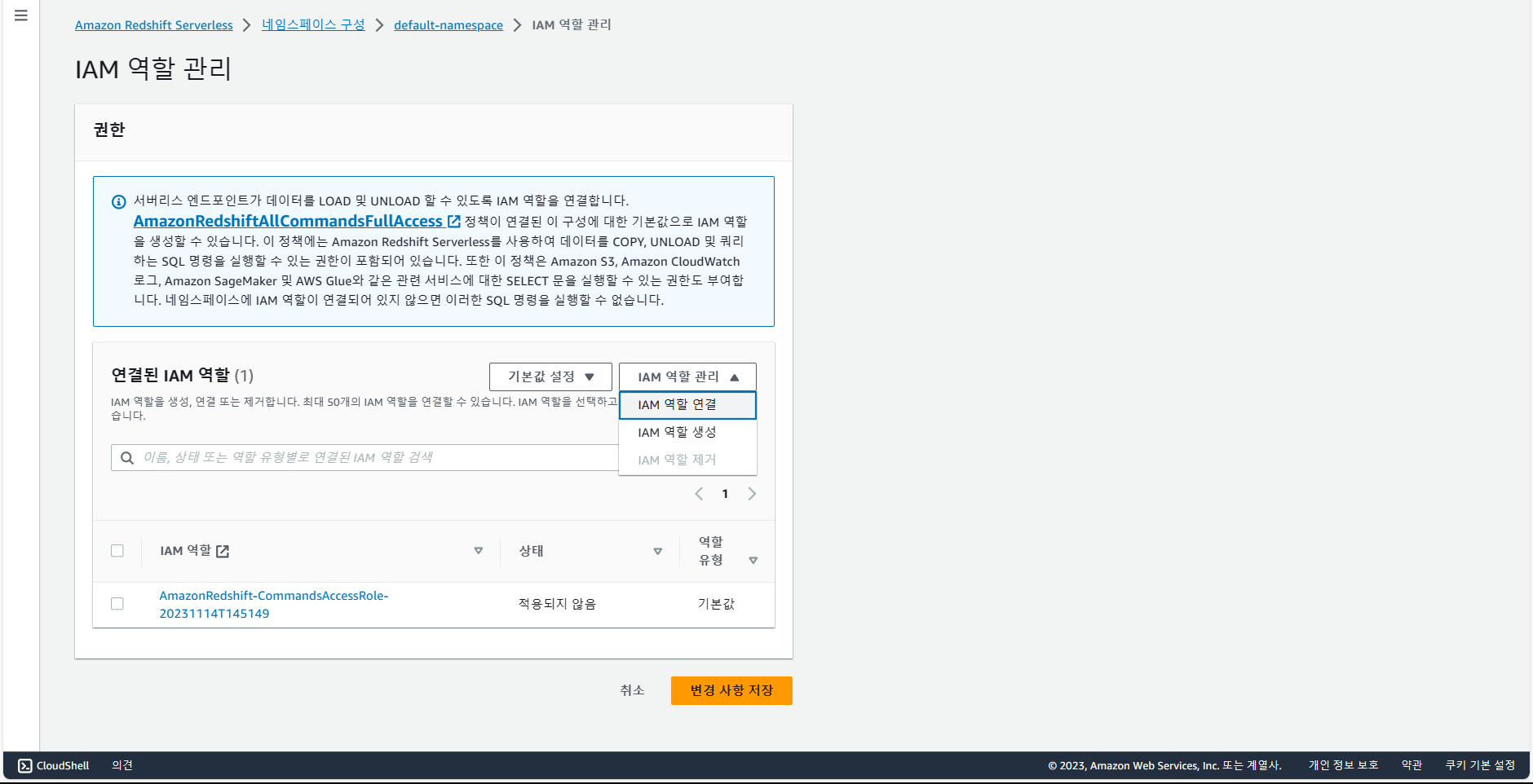
IAM 역할 연결을 선택 후, "redshift.read.s3"에 대해서 연결 및 변경 사항 저장.
-
COPY 명령어 예시)
%%sql -- 아래 쿼리에서 aws_iam_role의 값은 각자 Redshift cluster에 지정한 S3 읽기 권한 ROLE의 ARN을 지정 -- raw_data라는 스키마의 u_s_c 테이블을 목적지로 지정함. COPY raw_data.user_session_channel -- 파일이 저장되어 있는 곳으로부터 FROM 's3://username-test-bucket/test_data/user_session_channel.csv' -- 권한을 확인. aws_iam_role 키 값에 적합한 값을 지정. -- arn 값은 IAM의 역할에서 확인 가능. credentials 'aws_iam_role=arn:aws:iam::xxxxxxx:role/redshift.read.s3' -- csv 파일이니, 구분자는 ','로 지정하고, 첫 번째 라인은 무시한다. -- 그리고 quotes(따옴표)를 무시하고 데이터를 입력한다. -- 그리고 date와 time 포맷은 redshift가 알아서 지정한다. delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes; -
COPY 명령 실행 중 에러가 났을 경우, 에러 로그 확인)
-- 가장 최근의 에러부터 확인.
SELECT * FROM stl_load_erros ORDER BY starttime DESC;4-2. 실습
- table 생성)
%%sql
CREATE TABLE raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
);
CREATE TABLE raw_data.session_transaction (
sessionid varchar(32) primary key,
refunded boolean,
amount int
)- COPY 실행)
%%sql
COPY raw_data.user_session_channel
FROM 's3://jaeho-test-bucket/test_data/user_session_channel.csv'
credentials 'aws_iam_role=arn:aws:iam::xxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;
COPY raw_data.session_timestamp
FROM 's3://jaeho-test-bucket/test_data/session_timestamp.csv'
credentials 'aws_iam_role=arn:aws:iam::xxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;
COPY raw_data.session_transaction
FROM 's3://jaeho-test-bucket/test_data/session_transaction.csv'
credentials 'aws_iam_role=arn:aws:iam::xxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;