정렬은 Comparisons 방식과 Non-Comparisons 방식으로 나뉜다.
아래 구현한 sort 함수들의 base code는 다음과 같다. (merge, quick sort의 경우 약간의 수정이 요구된다.)
#include <iostream>
using namespace std;
int N;
int* arr;
int* tmp_arr;
void print_arr(){
for (int i=0; i<N; i++)
cout << arr[i] << ' ';
cout << '\n';
}
void sort(){
//implement here
}
int main(){
cin >> N;
arr = new int[N];
tmp_arr = new int[N];
for (int i=0; i<N; i++)
cin >> arr[i];
cout << "before sort:\n";
print_arr();
cout << "\nafter sort:\n";
sort();
print_arr();
return 0;
}비교 정렬 (Comparison)
Bubble Sort
서로 인접한 두 원소의 대소관계를 검사하여 정렬한다. 즉 만약 오름차순으로 정렬한다면, 가장 큰 수가 마지막으로 오고, 그 후 두번째로 큰 수가 마지막에서 2번째로 오고, ...의 순으로 정렬된다.
과정
코드
void sort(){
for (int i=0; i<N; i++){
for (int j=0; j<N-i; j++){
if (arr[j-1] > arr[j]){
int tmp = arr[j-1];
arr[j-1] = arr[j];
arr[j] = tmp;
}
}
}
}시간복잡도
최선, 평균, 최악의 경우와 관계없이 모두 O(N2)의 비교 횟수
교환은 최선의 경우 (이미 정렬된 경우) 한 번도 일어나지 않고, 역순으로 정렬된 경우 매번 일어나야 한다.
➡️ T(N) = O(N2)
공간복잡도
in-place로 정렬을 수행한다.
➡️ O(1)
장점
구현이 쉽다.
단점
느리기 때문에 거의 쓰이지 않는다.
Selection Sort
버블 정렬이 계속해서 인접한 수를 비교 후 swap했다면, 선택 정렬은 비교 대상 값의 index를 저장 후 한 번만 바꾼다. 즉 첫번째 자리에는 가장 최솟값의 index를 저장 후 해당 index의 값과 첫번째 원소를 swap, 두번째 자리에는 남은 원소들 중 최솟값의 index를 저장 후 해당 index의 값과 두번째 원소를 swap, ... 순으로 정렬된다.
과정
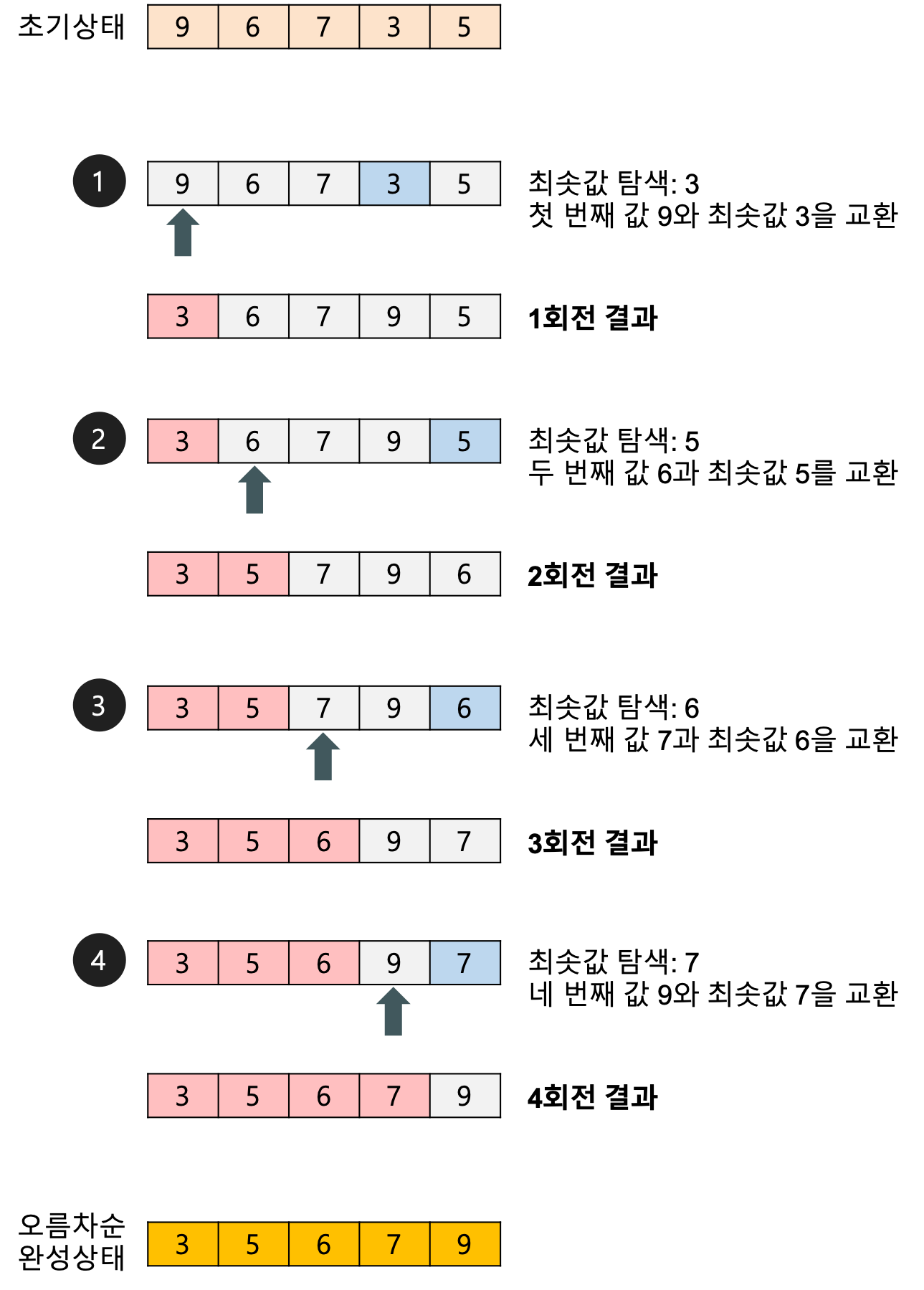{kind=link}
코드
void sort(){
for (int i=0; i<N; i++){
int idx = i;
for (int j=i+1; j<N; j++){
if (arr[idx] > arr[j])
idx = j;
}
int tmp = arr[idx];
arr[idx] = arr[i];
arr[i] = tmp;
}
}시간복잡도
최선, 평균, 최악의 경우와 관계없이 모두 O(N2)의 비교 횟수
그러나 버블 정렬에 비해 교환의 횟수가 적다.
➡️ T(N) = O(N2)
공간복잡도
in-place로 정렬을 수행한다.
➡️ O(1)
장점
구현이 쉽다. 버블 정렬에 비해서는 swap 횟수가 적어 빠르다.
단점
불안정하다. 즉, 같은 값일 때 정렬 후 순서가 바뀔 수 있다. 구체적 예시로, 만약 a < b,B < c 이고, 현재 상태가 B b a c라면, 선택 정렬 후 a b B c가 되어 b와 B의 순서가 바뀐다.
느리다.
Insertion Sort
원소를 첫번째부터 마지막까지 원소들을 차례대로 자신의 위치에 끼워넣는 방식으로 정렬한다. 즉, 0부터 i-1번째 원소까지는 정렬이 됐다고 가정하고, i번째 원소를 i-1부터 0번째 원소까지 순서대로 비교를 하며 정렬 순서가 바꼈을 경우 swap을 해주고, 정렬 순서가 올바르다면 i+1번째 원소에 대해 같은 작업을 진행한다.
과정
{kind=link}
코드
void sort(){
for (int i=1; i<N; i++){
int tmp = arr[i];
int j;
for (j=i-1; j>=0; j--){
if (arr[j] > tmp)
arr[j+1] = arr[j];
else break;
}
arr[j+1] = tmp;
}
}시간복잡도
최선의 경우(이미 정렬되어 있을 경우), N번의 원소에 대해 swap없이 1번의 비교만 수행된다.
➡️ T(N) = O(N)
그러나 평균 또는 최악(역순으로 정렬)의 경우 N개의 원소에 대해 각각의 자리까지 swap이 이루어져야 한다.
➡️ T(N) = O(N2)
공간복잡도
in-place로 정렬을 수행한다.
➡️ O(1)
장점
원소들의 대부분이 정렬된 경우 좋은 성능을 보인다.
원소의 수가 적을 경우 간단한 알고리즘으로 다른 복잡한 정렬들에 비해 유리할 수 있다.
단점
역시 버블정렬에 비해는 좋은 성능을 보이지만, 대체적으로 많은 자리 이동이 요구되므로 성능이 좋지 않다.
Merge Sort
분할 ➡️ 정복 ➡️ 결합의 과정을 통해 정렬된다. 구체적으로, 더 이상 나뉘지 않을 때까지 절반으로 분할한다. 이후, 더 이상 나뉘지 않는 배열, 즉 원소가 하나인 배열에 대해서는 해당 원소를 반환한다. 두 개의 sub-배열을 결합하는 과정에서 비교를 통해 임시 배열에 정렬하여 저장한다. 최종적으로 모든 sub-배열을 결합하여 원래 배열 크기의 정렬된 배열이 완성된다.
❓어차피 하나 남을 때까지 분할하는데, 바로 안하고 절반씩 분할하는 이유?
❗️재귀적 구현을 위하여.
과정
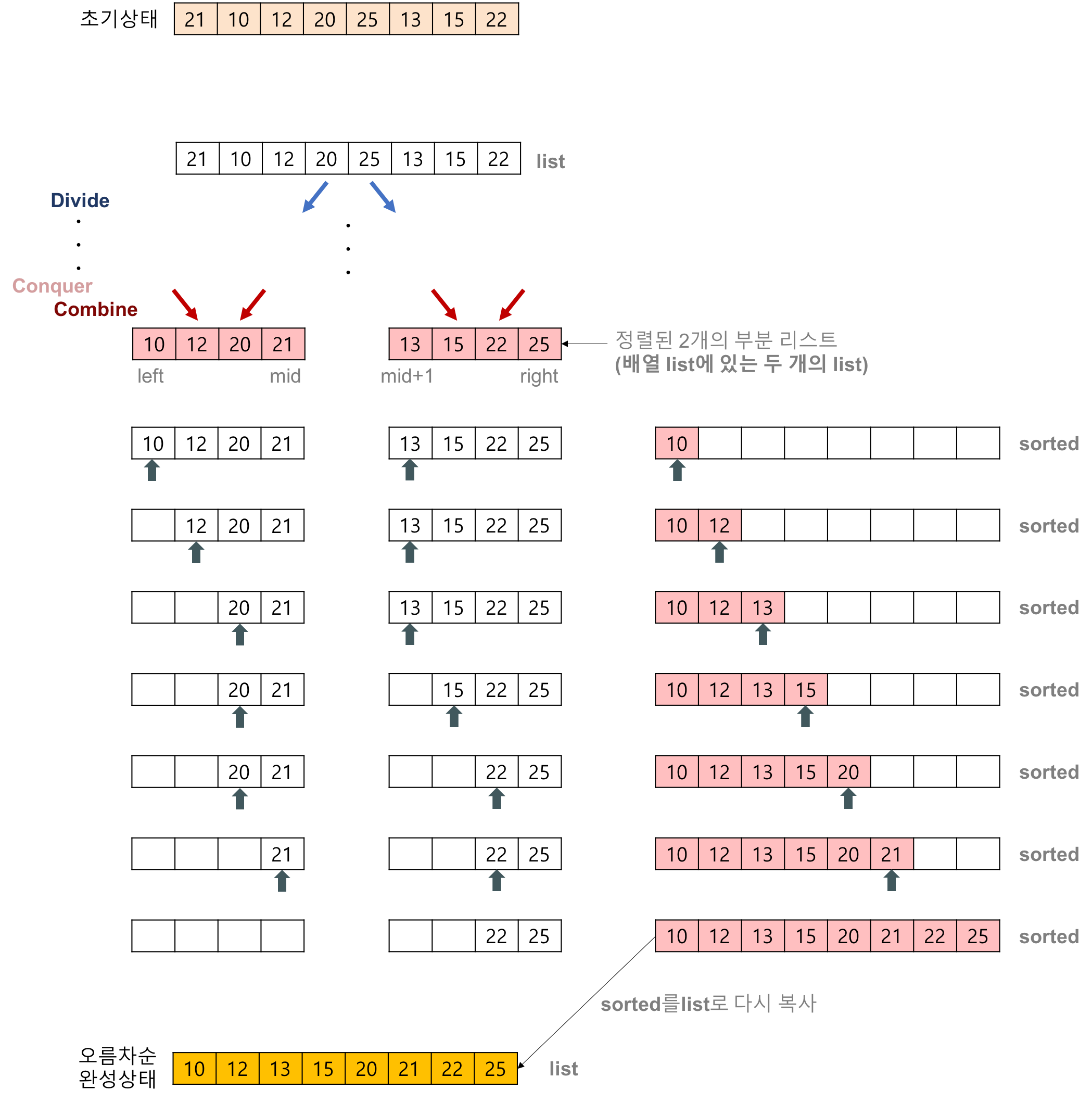{kind=link}
코드
void merge(int left, int mid, int right){
//sub-array merge (with sort)
int i, j, k;
i = left;
j = mid+1;
k=left;
while(i<=mid || j<=right){
if (j>right || (i<=mid&&arr[i] <= arr[j]))
tmp_arr[k++] = arr[i++];
else tmp_arr[k++] = arr[j++];
}
for (int itr=left; itr<=right; itr++)
arr[itr] = tmp_arr[itr];
}
void merge_sort(int left, int right){
if (left < right){
int mid = (left+right)/2;
//divide
merge_sort(left,mid);
merge_sort(mid+1, right);
merge(left,mid,right);
}
}시간복잡도
분할 ➡️ 별도의 비교/이동 연산이 요구되지 않는다.
합병 ➡️ 1개, 2개, 4개, ..., N/2개 크기의 sub-array들이 이진트리를 이루고 있다고 가정할 수 있다. 이 때 트리의 높이는 log2N 이다. 또한 트리의 각 레벨에서 최대 N번의 비교 연산이 요구된다. 따라서 비교 연산은 Nlog2N 이 요구된다. 이동 연산의 경우, 임시 배열 (코드에서 tmp_arr)에 정렬 후 원본 배열로 다시 복사가 이루어진다. (2N) 또한 트리의 높이만큼 이러한 작업들이 이루어지므로, 2Nlog2N 이 요구된다.
➡️ T(N) = O(Nlog2N)
모든 레벨에 대해 N/2번의 비교 연산이 무조건 요구되기 때문에(예를 들어 배열1이 배열2보다 모두 크다고 해도 적어도 N/2번 비교가 이루어진 후에야 배열2를 모두 복사할 수 있다), 후 정렬이 이루어지기 때문에, 최악, 최선, 평균의 경우 모두 O(Nlog2N)이 된다.
공간복잡도
N 크기의 추가적인 임시배열이 요구된다.
➡️ O(N)
장점
최악, 평균의 경우 Bubble, Selection, Insertion 정렬보다 빠르다.
단점
in-place 정렬에 비해 추가적인 임시 공간(배열)이 필요하다.
레코드들의 크기가 큰 경우 이동 횟수가 많기 때문에 (임시 배열로 정렬하면서 복사 후 다시 원본으로 복사) 비효율적이다.
Heap Sort
힙을 활용한 정렬. 정렬 대상 레코드들을 힙에 삽입하고, 하나씩 꺼내면서 저장하면 정렬이 된다.
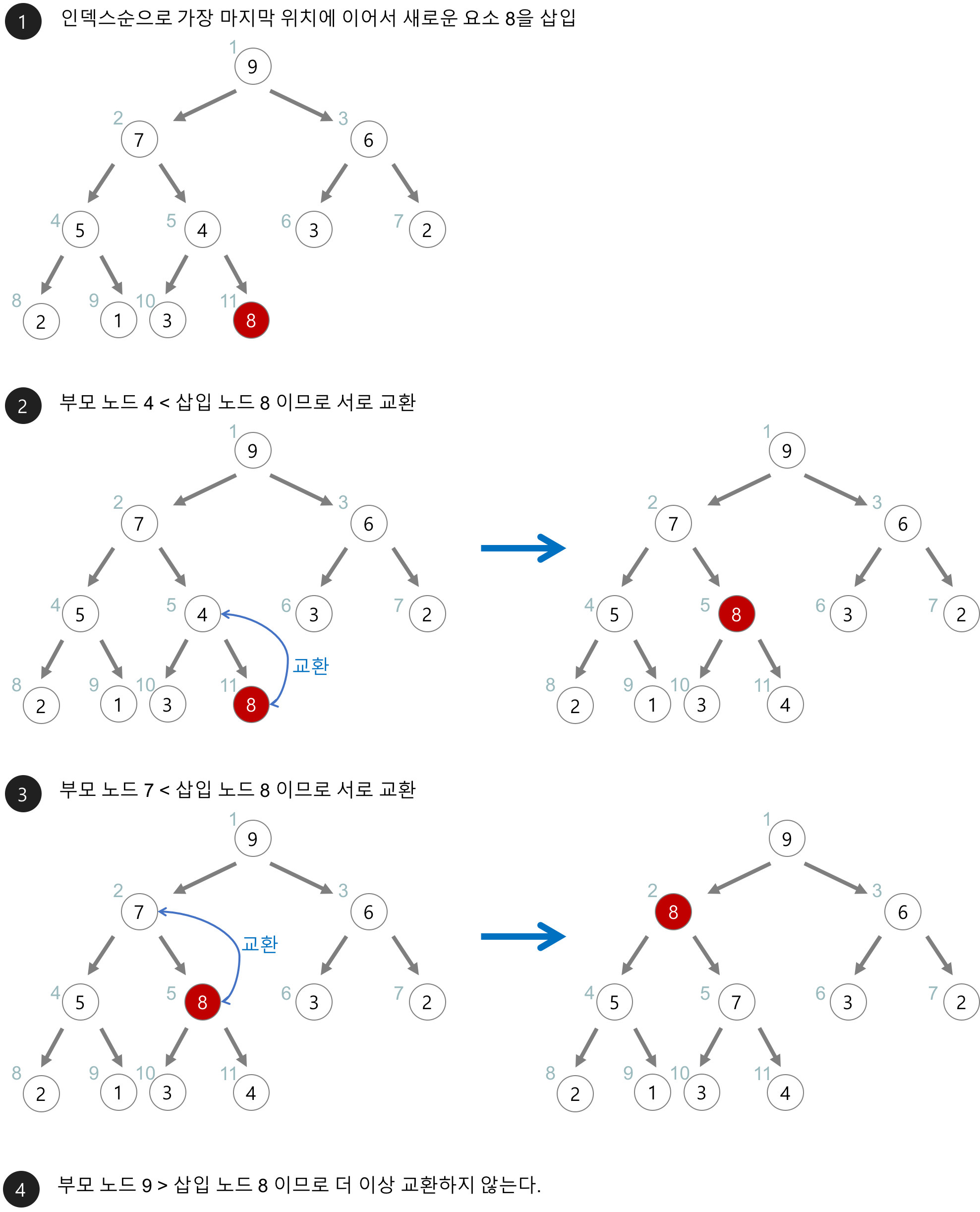{kind=link}
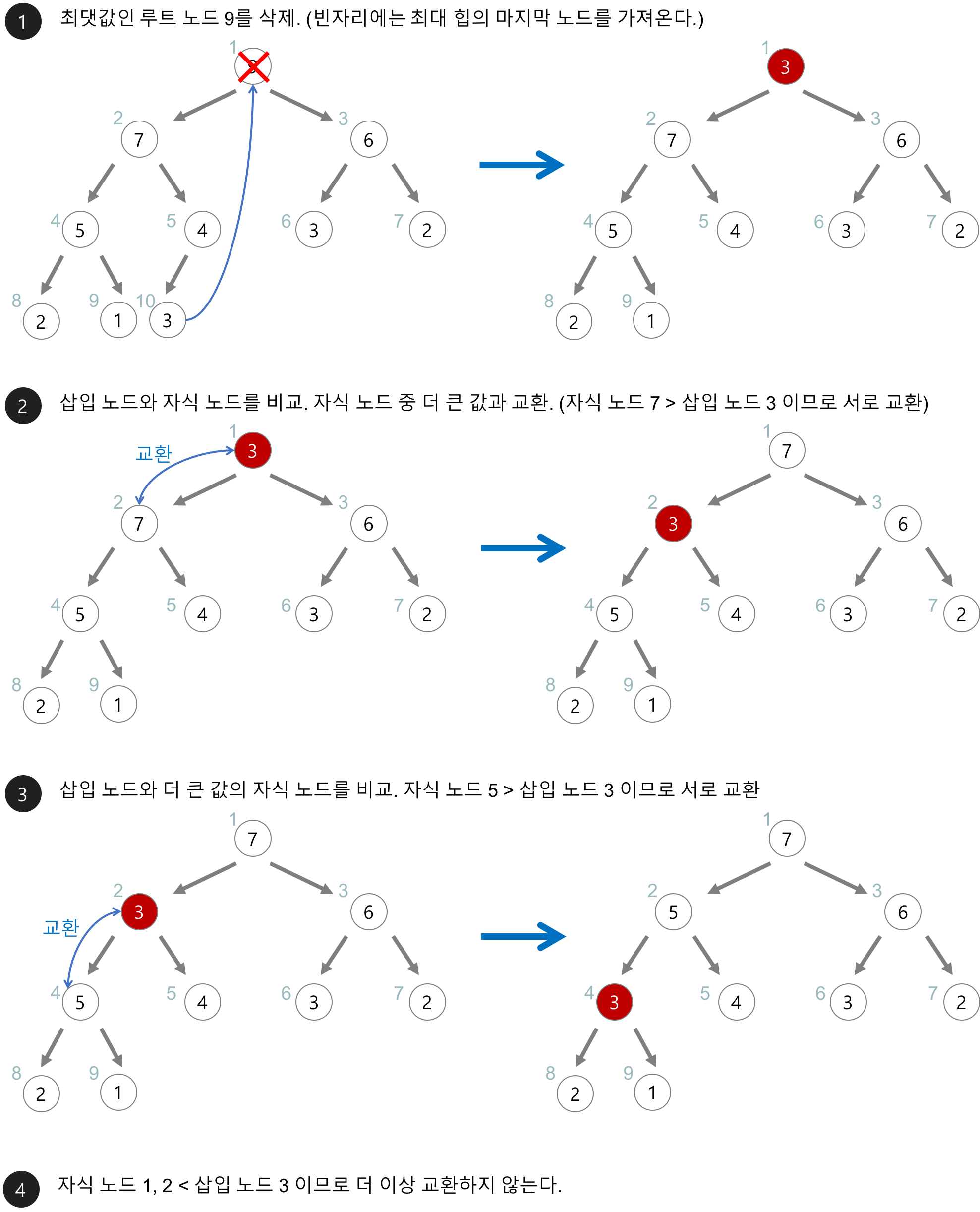{kind=link}
코드
void sort(){
priority_queue<int, vector<int>, greater<int>> pq; //최소힙
for (int i=0; i<N; i++)
pq.push(arr[i]);
for (int i=0; i<N; i++){
arr[i] = pq.top();
pq.pop();
}
}시간복잡도
힙에 N개의 원소를 삽입하는 시간 ➡️ O(Nlog2N)
힙에서 N개의 원소를 꺼내는 시간 ➡️ O(Nlog2N)
➡️ T(N) = O(Nlog2N)
공간복잡도
추가적인 힙을 위한 공간을 사용한다면 O(N)이 필요하지만, 기존 배열 내에서 heapify한다면 O(1)로 가능하다.
➡️ O(1) or O(N)
장점
시간복잡도가 효율적이다.
전체 정렬이 아닌, 가장 큰 값 (또는 가장 작은 값) 몇 개만 필요할 때 유용하다.
단점
불안정하다.
Quick Sort
합병정렬과 같이 분할 ➡️ 정복 ➡️ 결합의 과정을 통해 정렬된다. 차이점은, 퀵정렬은 배열을 비균등하게 분할한다.
- pivot 원소를 선택한다.
- pivot 이하의 원소를 pivot 왼쪽, pivot보다 큰 원소를 pivot 오른쪽으로 옮긴다.
- 왼쪽 sub-array와 오른쪽 sub-array에 대해 같은 작업을 반복한다.
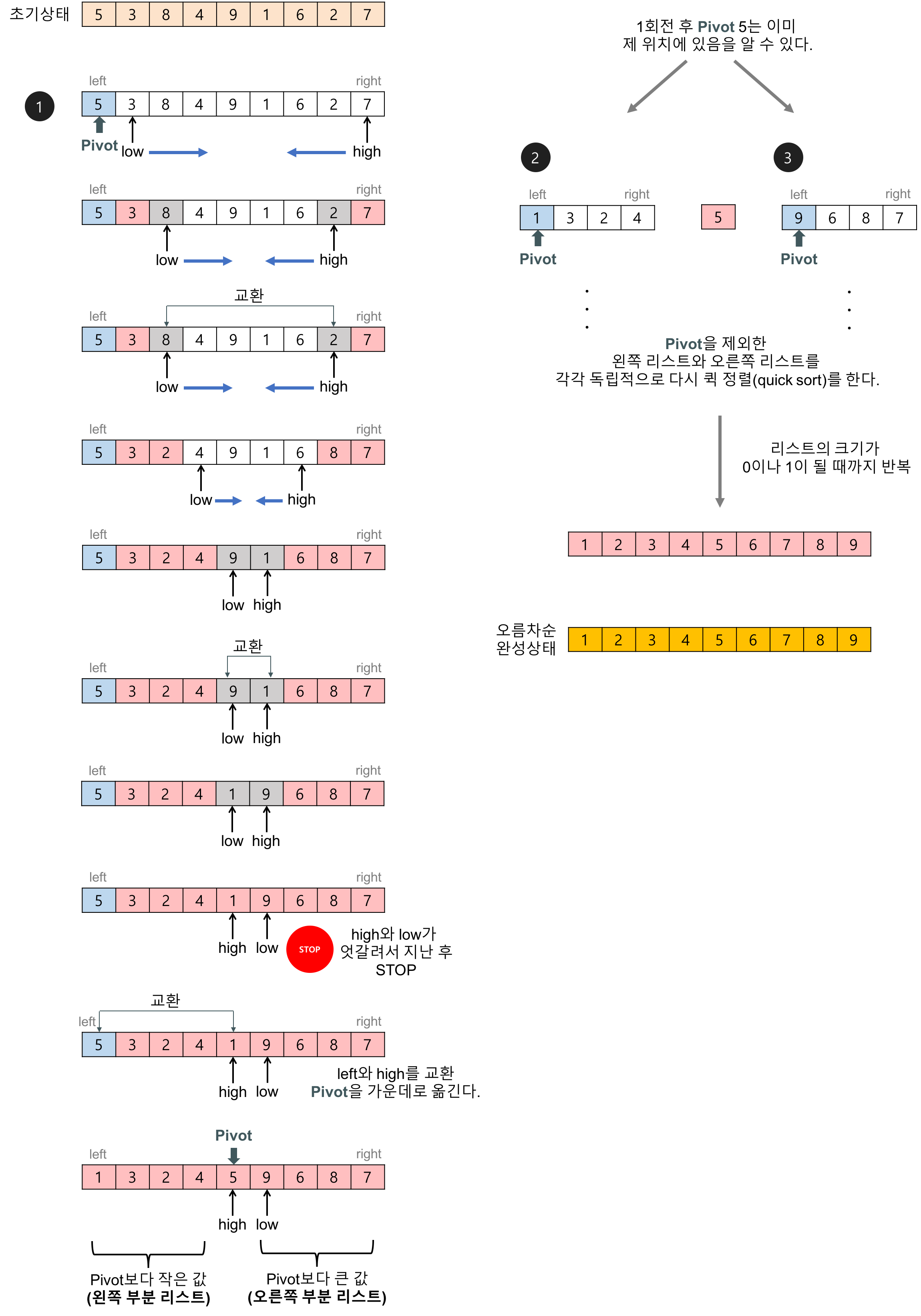{kind=link}
코드
int partition(int left, int right){
int pivot = arr[left];
int l_idx = left;
int r_idx = right;
while(1){
while (arr[l_idx]<=pivot)
l_idx++;
while (arr[r_idx] > pivot)
r_idx--;
if (l_idx < r_idx){
int tmp = arr[l_idx];
arr[l_idx] = arr[r_idx];
arr[r_idx] = tmp;
}
else break;
}
arr[left] = arr[r_idx];
arr[r_idx] = pivot;
return r_idx;
}
void sort(int left, int right){
//implement here
if (left < right){
int pivot_idx = partition(left,right); //pivot의 index
sort(left,pivot_idx-1);
sort(pivot_idx+1,right);
}
}시간복잡도
최선의 경우는, pivot으로 리스트가 절반씩 계속하여 나뉘는 경우다. 이 경우, 트리의 높이가 log2N 이 된다. 각 높이 별로 평균 N번의 비교가 이루어지기 때문에
➡️ T(N) = O(Nlog2N)
최악의 경우는, pivot이 리스트의 최대/최소 값으로 계속하여 선택되는 경우다. 즉 이미 정렬된 경우 최악의 효율을 보일 수 있다. 이 경우, 트리의 높이가 N이 되며, 각 레벨에서 비교 역시 N, N-1, N-2, ..., 1번까지 이루어지기 때문에
➡️ T(N) = O(N2)
평균적으로 pivot을 극단적이지 않게 잘 선정한다면
➡️ T(N) = O(Nlog2N) 이 가능하다.
불필요한 데이터의 이동이 적고, 먼 거리의 데이터를 swap하며 한 번 결정된 pivot은 다음 재귀에서는 제외되기 때문에 다른 O(Nlog2N) 의 정렬들보다도 빠르다. (즉 상수 계수가 낮다.)
❓효율적인 pivot 선정?
❗️pivot을 배열의 첫번째 원소로 선정한다면, 이미 정렬된 경우 최악의 시간복잡도가 된다. 따라서 첫번째 원소와 중간값을 swap해준다면 평균적인 시간복잡도로 개선 가능하다. 물론 이러한 방법은 최악을 피할 확률을 높이는 것이지 보장하는 것이 아니기 때문에 최악의 경우는 O(Nlog2N)이 된다.
❗️또는 pivot을 리스트의 중간값으로 선정하는 방법이 있다.
❗️특정 위치의 원소를 pivot으로 설정하는 것이 아닌, 임의의 random 원소를 pivot으로 설정하면 평균의 성능을 얻을 확률이 높다.
공간복잡도
재귀적 호출로 인한 O(log N)이 요구된다. 따라서 이 역시 최악의 경우 O(N)까지 악화될 수 있다.
➡️ O(log N) or O(N)
장점
평균적으로 매우 빠르다. 다른 O(Nlog2N)의 정렬들 중 가장 빠르다.
O(N)의 공간을 요구하는 Merge Sort보다 적은 O(log N)의 공간을 요구한다.
단점
최악의 경우 시간복잡도가 O(N2)까지 악화된다.
불안정하다.
비교 정렬 알고리즘 비교
| 정렬 | Best | Avg | Worst | Space |
|---|---|---|---|---|
| Bubble | n^2 | n^2 | n^2 | 1 |
| Selection | n^2 | n^2 | n^2 | 1 |
| Insertion | n | n^2 | n^2 | 1 |
| Merge | n log n | n log n | n log n | n |
| Heap | n log n | n log n | n log n | 1 |
| Quick | n log n | n log n | n^2 | log n |
안정 vs 불안정
| 안정 | 불안정 |
|---|---|
| Bubble, Insertion, Merge | Selection, Heap, Quick |
[참고 사이트]
https://gmlwjd9405.github.io/
