💬 DynamoDB
- NoSQL(Not Only SQL) 데이터베이스
- 매우 빠른 쿼리 속도
- Auto-Scaling 기능
- 데이터 양에 따라 크기가 늘었다가 줄었다가 함
- Key-Value 데이터 모델 지원
- 테이블 생성시 스키마 생성 필요 없음
- 모바일, 웹, IoT데이터 사용시 추천됨
- SSD 스토리지 사용
- Read, Write 속도가 매우 빠름
구성
- 테이블 (Table)
- 아이템(Items) - 행(row)과 개념이 비슷
- 특징 (Attributes) - 열(column)과 개념 비슷
- Key-Value (Key: 데이터 이름, Value: 데이터 자신)
- JSON, XML 형태로 많이 사용됨
Primary Keys (PK)
-
PK를 사용하여 데이터 쿼리
-
DynamoDB에는 두카지 PK 유형 존재
✓ 파티션 키 (Partition Key)- 고유 특징 (Unique Attribute)
- 실제 데이터가 들어가는 위치를 결정
- 파티션키 사용시 동일한 두개 데이터가 같은 위치에 저장 불가
✓ 복합 키 (Composite Key)
- 파티션 키(Partition Key) + 정렬키(Sort Key)
ex) 같은 고객이 다른 날짜의 다른 물건을 구매한 경우
-> 파티션 키: 고객 아이디, 정렬키: 날짜 (Timestamp)
-> 같은 파티션키의 데이터들은 같은 장소에 보관, 그 다음 정렬키에 의해 데이터가 저장
DyanamoDB 데이터 접근 관리
- AWS IAM으로 관리 가능
- 테이블 생성과 접근 권한을 부여할 수 있음
- 특정 테이블, 데이터만 접근 가능하게 해주는 특별한 IAM 역할 존재
ex) 로그인 본인에게만 관련 데이터가 보여지게 하는 경우
Index
- 특정 컬럼만을 사용하여 쿼리
- 테이블 전체가 아닌 기준점(Pivot)을 사용해 쿼리가 이루어짐
- 매우 큰 쿼리 성능 효과
- 두가지의 Index 유형 존재
- Local Secondary Index (LSI)
✓ 테이블 생성시에만 정의 가능, 생성 후 수정/삭제가 불가능
✓ 같은 파티션키를 사용하고 다른 정렬키를 사용 - Global Secondary Index (GSI)
✓ 테이블 생성 후에도 추가/변경/삭제가 가능
✓ 다른 파티션키, 정렬키 사용
- Local Secondary Index (LSI)
Query VS SCAN
🔎 Query
- Primary Key를 통해 데이터 검색
- Query 사용시 모든 데이터(컬럼) 반환
- ProjectionExpression 파라미터
- 원하는 항목만 볼 수 있도록 선택
🔎 Scan
- 모든 데이터를 불러와 필터링 (Primary Key 사용 x)
- ProjectionExpression 파라미터
-> Query가 Scan 보다 효율적이며, 사용을 추천함
병행 스캔이라는 기능을 통해 테이블 전체 데이터를 쪼개서 Scan을 수행해 그 속도를 높여줄 수는 있지만 테이블의 크기가 크지 않고, Primary Key를 사용하지 않는 Look-up 테이블의 경우 Scan을 사용함
- 테이블 생성
| cutomer_id | item_category | price | transaction_date |
|---|---|---|---|
| String | String | Integer | String |
- 사용 시나리오
- S3 버켓에 파일 업로드 -> 람다 함수 발동 -> Dynamo DB 데이터 쌓기
( + IoT -> DynamoDB 데이터 쌓기 )
-
람다 함수 생성
3.1) 권한 설정 필요하기 떄문에 IAM 추가 (IAM Console)
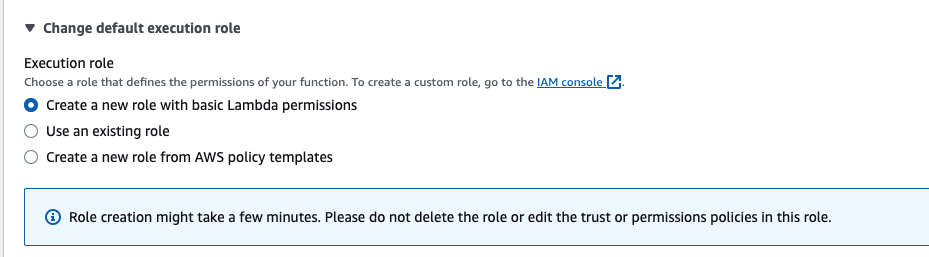
3.2) Create policy
Service - DynamoDB
Actions - Put Items
Resources - All Resources (해당 dynamoDB 테이블에 대한 모든 권한)
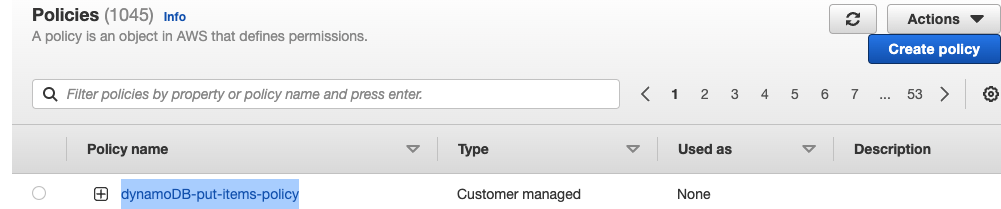
-
Roles 생성
- 생성된 정책과 연결
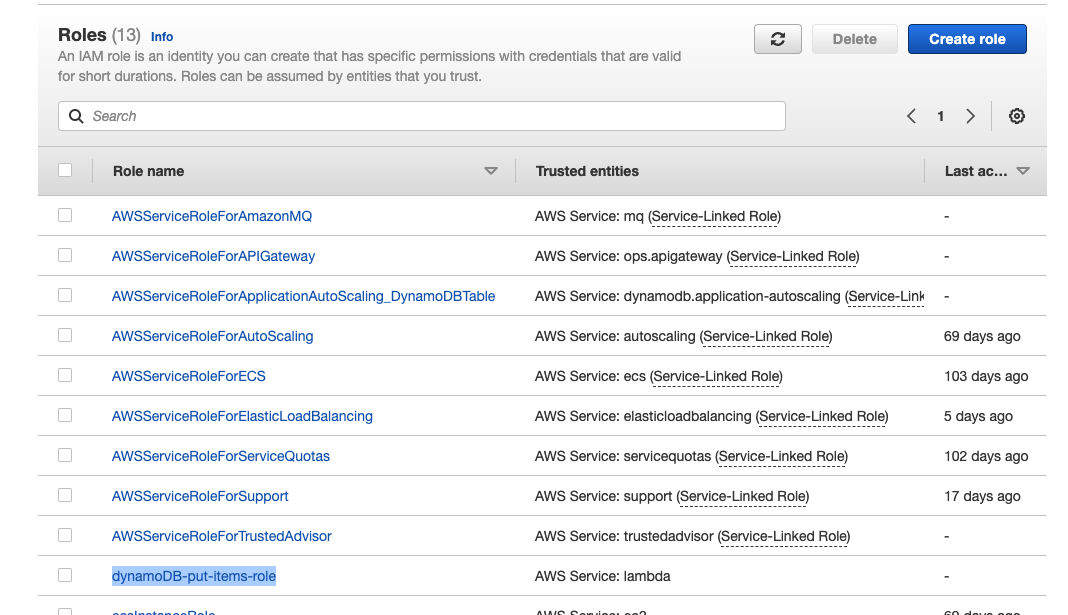
-
해당 Role에 람다 기능 사용하도록 추가
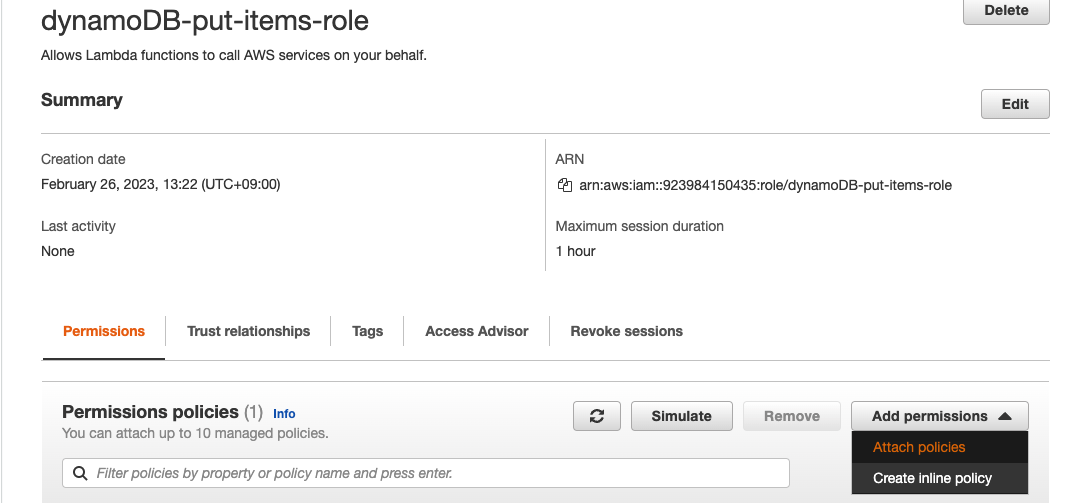
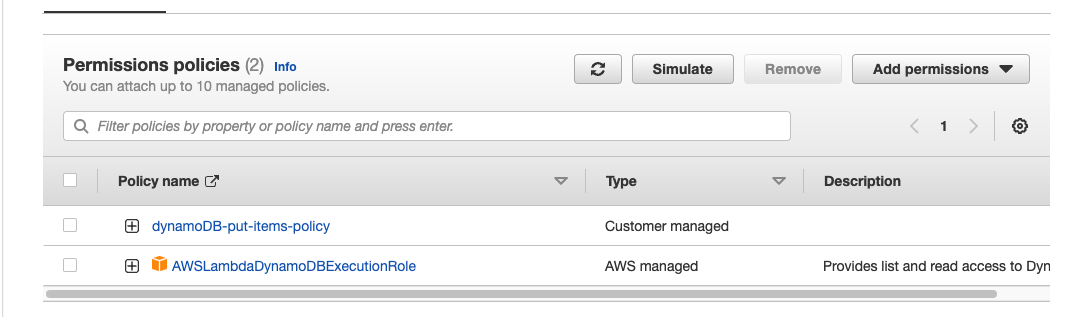
-
Role과 연결
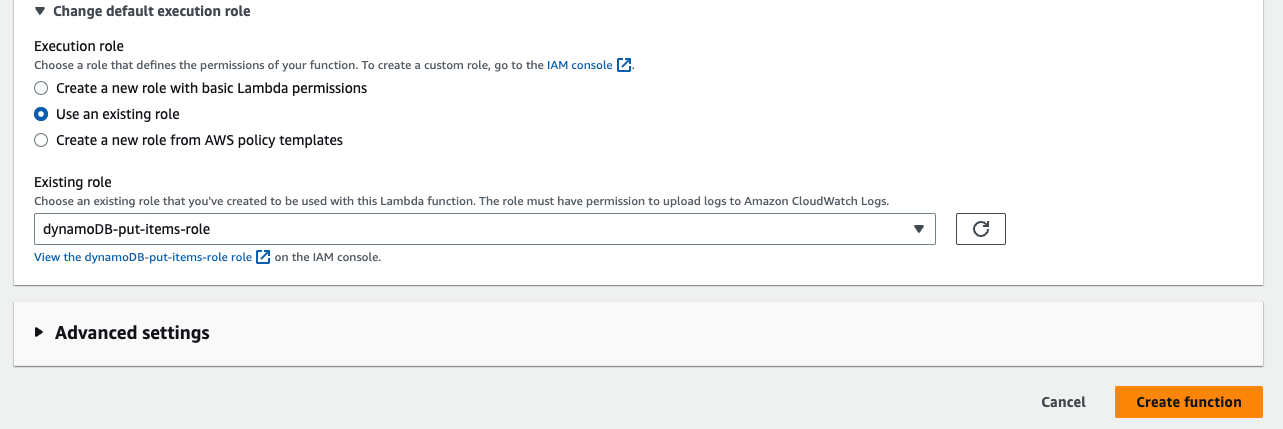
-
생성 후 람다함수 사용
