
NLP 업계를 보고 있자면 우리가 모두 알만한 내놓라 하는 기업들은 서로 앞다투어 거대언어모델(LLM)을 발표하기 바쁜 것 같습니다. 얼마 전 구글에서 공개된 PaLM(Pathways Language Model)은 GPT-3(1,750억개)보다 약 3배나 큰 파라미터(5,400억개)를 가지고 있다고 합니다.
무튼 몇년새 자연어 처리 분야는 이제 이러한 사전훈련언어모델(Pretrained Language Model)이 기본이 되었고 필수가 되어버렸습니다.
대부분 gpu 연산이 요구되는 모델링을 할 때 Colab을 많이 사용하고 있을 것 입니다. (그나마 저는 회사 계정으로 GCP의 gpu 인스턴스를 멋대로 사용하고 있지만 아무래도 양심상 눈치를 보고 있습니다. 👀 )
하지만 무료계정일 경우 낮은 성능의 gpu 및 적은 vram, session 시간 제한으로 아무래도 불편합니다. (Colab Pro로 올리면 조금 낫습니다만, 이것도 on-demand는 아니고 session 제한이 존재합니다)
이번 포스팅에서는 무료로 Google의 Cloud-TPU를 활용하는 방법에 대해 알아보고자 합니다.
그리고 Cloud-TPU를 통해 개인 PC/Colab으로는 도저히 접근하기 힘든 KorQuAD2 데이터셋을 KoBigBird모델을 활용하여 finetuning하는 방법에 대해 소개합니다.
1. TRC(TPU Research Cloud)
TRC(TPU Research Cloud)를 신청하면 누구나 Cloud TPU를 사용할 수 있습니다. 두 번 신청을 해보았는데 신청 후 최종 승인까지는 약 2~3시간 소요되었습니다.
1.1. TRC 신청하기
TRC 홈페이지에서 Apply now 버튼을 클릭하여 신청할 수 있습니다. 간단한 작성 폼이 나타나며 내용 작성 후 제출하면 1차적으로 신청 완료입니다.
1.2. GCP project 생성 및 TPU API 활성화
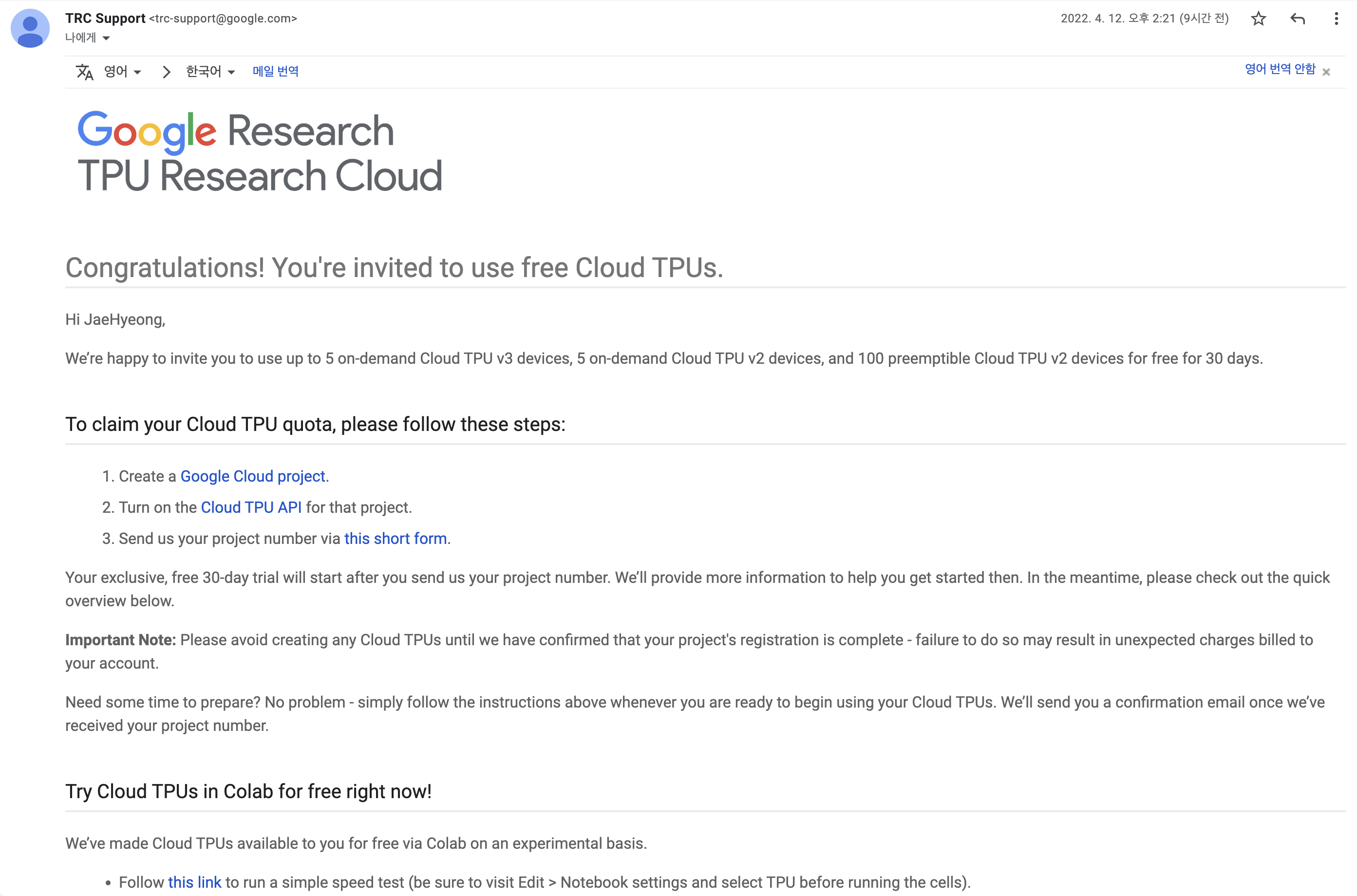
신청 후 좀 기다리시다보면 아래와 같은 메일이 오게 되며, Cloud TPU 사용을 위한 몇가지 절차를 알려주고 있습니다.
-
Google Cloud project 생성
본인의 GCP 콘솔에 가져서 프로젝트를 새로 생성하시면 됩니다. 프로젝트를 생성하면 프로젝트 번호(Project number)가 보이는데 추후 3번 폼에 작성해야 할 내용입니다. -
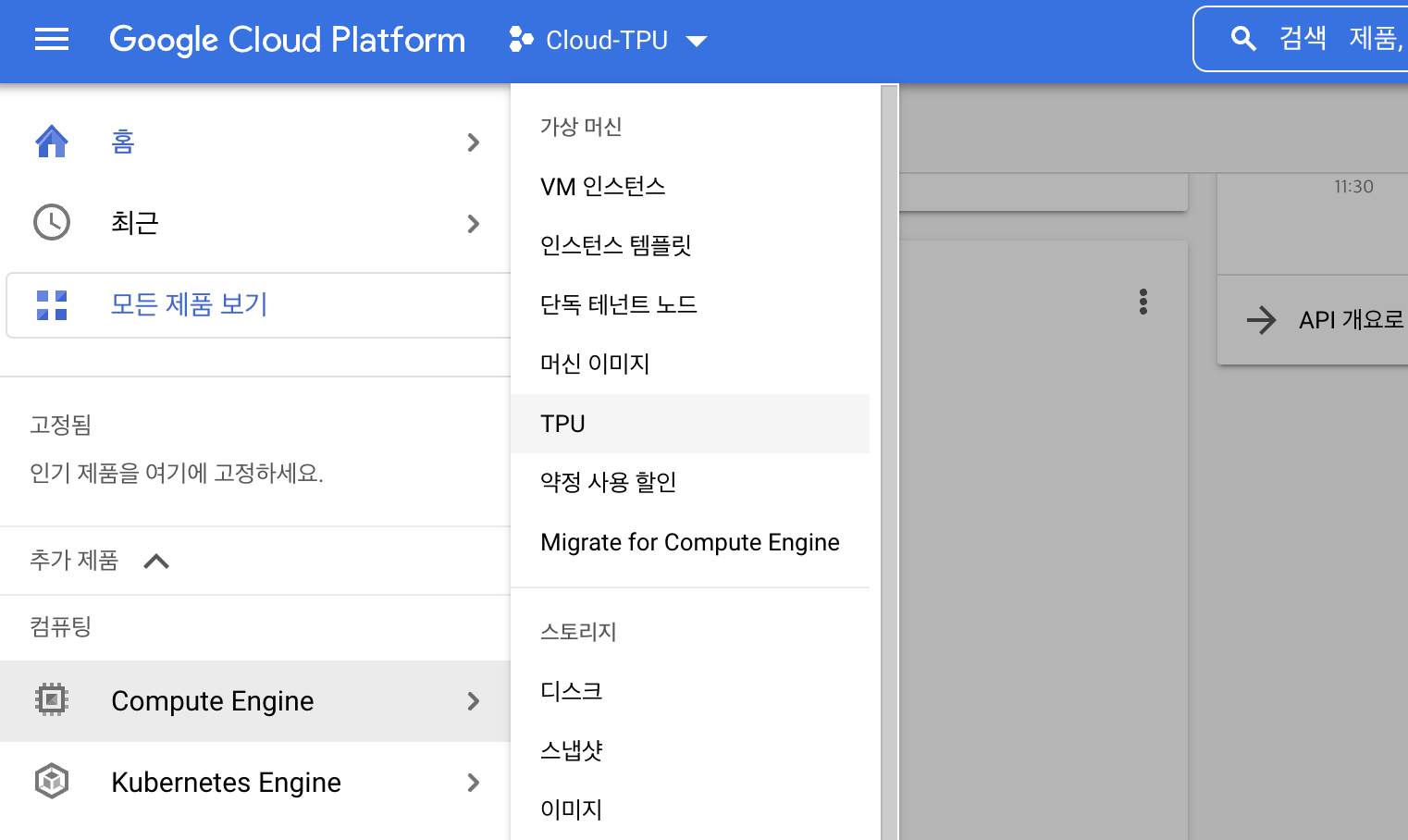
Cloud TPU API 활성화
GCP console → Compute Engine → TPU로 가셔서 TPU API를 활성화합니다.
-
폼에 프로젝트 번호 작성해서 제출
1번에서 생성한 project의 프로젝트 번호를 링크 폼에 작성하여 제출합니다.
제출 후 다시 기다리다보면 아래와 같은 또 하나의 메일이 날아옵니다. 이 메일이 왔다면 이제 Cloud TPU를 사용할 수 있게 된 것입니다!
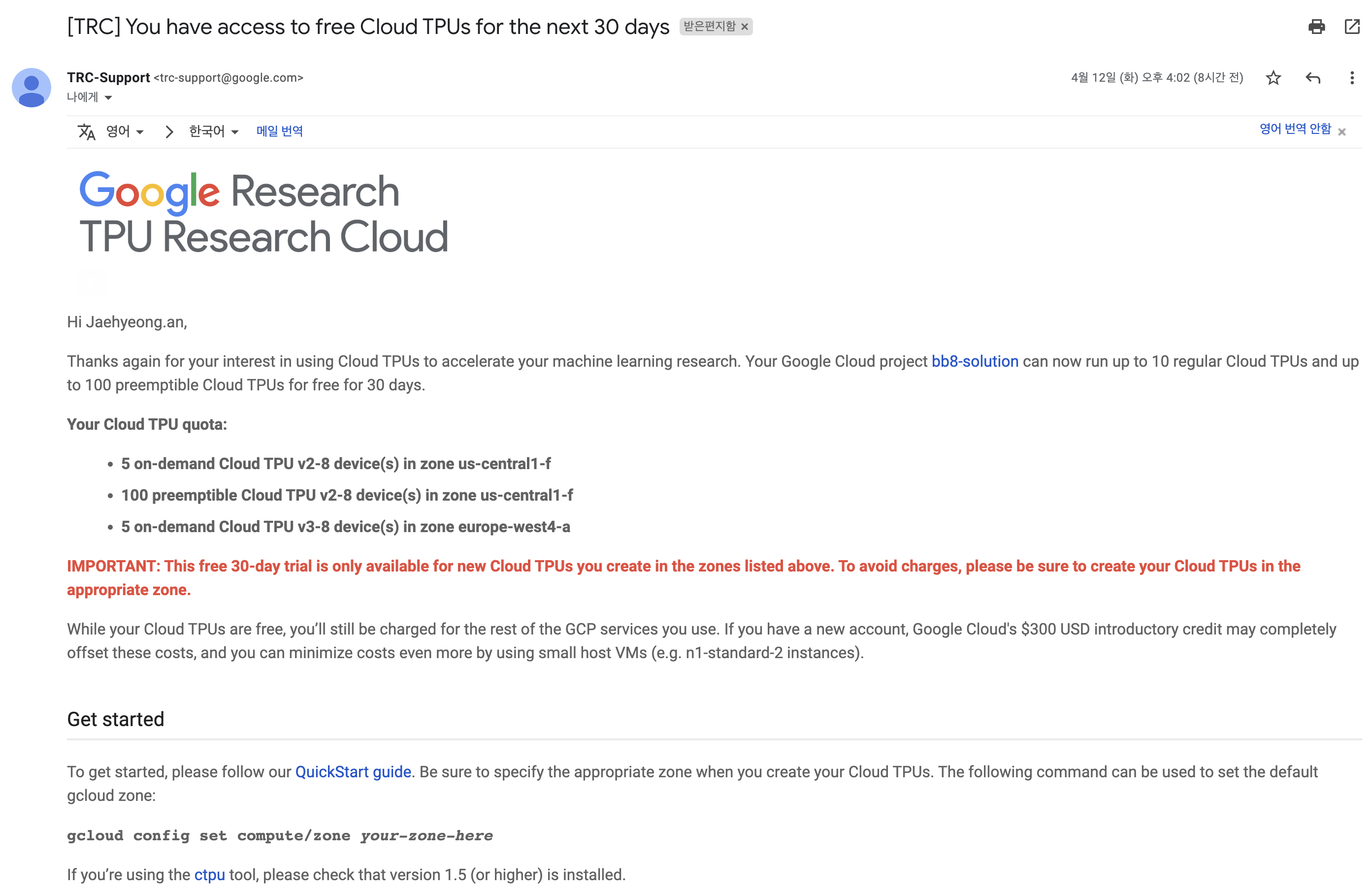
여기서 주의할점은 이 30일 무료 기간에서 사용할 수 있는 TPU 노드는 아래 3개라는 것입니다.
- 5 on-demand Cloud TPU v2-8 device(s) in zone us-central1-f
- 100 preemptible Cloud TPU v2-8 device(s) in zone us-central1-f
- 5 on-demand Cloud TPU v3-8 device(s) in zone europe-west4-a
이후 생성할 VM instance와 TPU 노드 모두 위 3개의 정보에 맞게 설정해야합니다.
(TPU 타입과 영역에 대한 내용은 해당 링크를 참고하세요.)
2. Cloud TPU 설정
2.1. VM 인스턴스 및 TPU 노드 생성
🔥 Warning!🔥
TRC는 TCP 서비스에 대해서만 무료를 지원하는 것이며, vm 인스턴스 생성 시 vm인스턴스 사용에 대한 과금이 발생하게 됩니다!
본 포스팅에서는 KorBigBird finetuning을 위해 KorBigBird github의 실험환경과 동일한 구성을 위해 TPU v3.8을 사용합니다.
VM 인스턴스와 TPU 노드를 직접 console에서 생성 할수도 있지만 gcloud shell을 통해 간단하게 명령어로 생성할 수 있습니다. (참고: Run a calculation on a Cloud TPU VM by using PyTorch)
# Create Compute Engine VM instance
gcloud compute instances create jaehyeong-tpu-research-vm \
--zone=europe-west4-a \
--machine-type=n1-standard-16 \
--image-family=torch-xla \
--image-project=ml-images \
--boot-disk-size=200GB \
--scopes=https://www.googleapis.com/auth/cloud-platformTPU v3.8을 위해서는 zone을 europe-west4-a 으로 설정해주어야 하며, 원할한 테스트를 위해 machine type은 최소 n1-standard-16을, boot disk는 최소 200GB를 권장합니다.
# Create TPU node
gcloud compute tpus create jaehyeong-tpu-research-node \
--zone=europe-west4-a \
--network=default \
--version=pytorch-1.8 \
--accelerator-type=v3-8TPU 노드의 zone도 마찬가지로 europe-west4-a 로 지정해주었으며, accelerator-type을 v3-8로 지정해주었습니다.
위 과정이 완료되면, console에서 아래와 같이 VM 인스턴스와 TPU에 각각 등록된 것을 확인할 수 있습니다.
2.2. VM 인스턴스에 TPU 연결 설정
아직 VM 인스턴스와 TPU 노드가 각기 존재하고 있으니, VM 인스턴스에게 TPU의 존재를 알려주어야 합니다.
그렇게 되면 TPU와 관련된 모든 연산들은 VM 인스턴스가 아닌 TPU 노드에서 이루어지게 됩니다.
- VM 인스턴스 접속
아래 명령어를 통해 위에서 생성한 VM 인스턴스에 접근합니다.gcloud compute ssh {vm 인스턴스 명} --zone=europe-west4-a - TPU node ip
TPU 노드의 ip를 vm 인스턴스에게 알려주어야 하므로 ip address를 조회합니다.
명령어 수행 시 나온 출력값의ipAddress값을 확인합니다.gcloud compute tpus describe {TPU 노드 명} --zone=europe-west4-a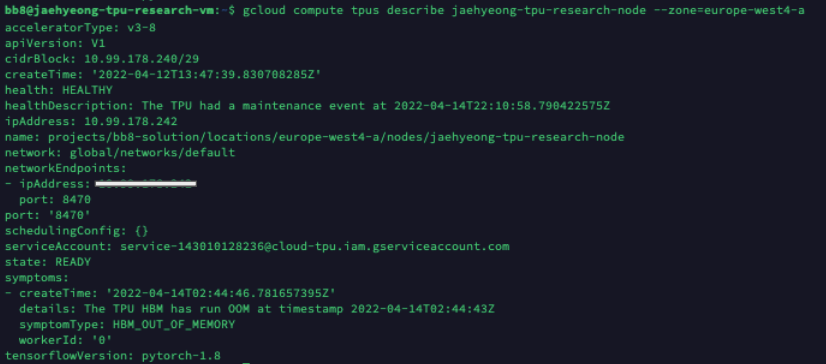
- TPU IP address 설정
torch-xla-1.8.1 venv를 활성화 후, 위에서 확인한ipAddress를 환경설정에 등록합니다.
conda activate torch-xla-1.8.1
export TPU_IP_ADDRESS={ipAddress}
export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"- TPU check
TPU가 제대로 연결되었는지 체크해보기 위해 아래 간단한 스크립트를 수행합니다.
import torch
import torch_xla.core.xla_model as xm
dev = xm.xla_device()
t1 = torch.randn(3,3,device=dev)
t2 = torch.randn(3,3,device=dev)
print(t1 + t2)만약 에러없이 아래와 같은 출력값이 나왔다면 정상적으로 TPU연산이 진행된 것입니다.
tensor([[-0.2121, 1.5589, -0.6951],
[-0.7886, -0.2022, 0.9242],
[ 0.8555, -1.8698, 1.4333]], device='xla:1')3. KorQuAD 2.0 Finetuning by KorBigBird
3.1. BigBird
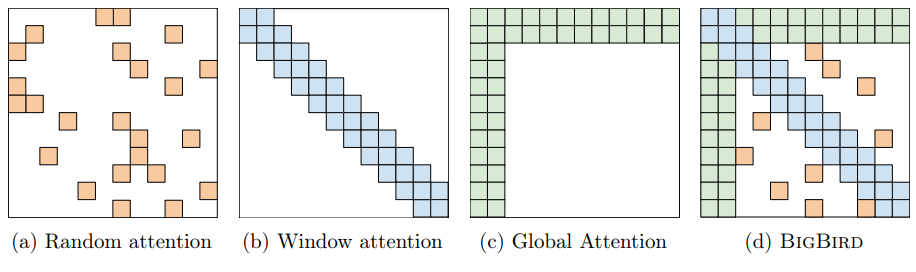
일반적으로 BERT 계열의 모델은 최대 512개의 입력 시퀀스를 입력 받습니다.
그 이유는 Transformer 모델의 self-attention연산의 경우 전체 입력 시퀀스를 참조하며 연산되는 full-attention기반이기 때문에 언제나 연산량이 입력 시퀀스 길이의 제곱에 비례하기 때문입니다. 따라서 512토큰보다 큰 텍스트가 들어올 경우 512토큰을 넘는 토큰에 대해 Truncation을 하는 것이 일반적입니다.
하지만 전체 컨텍스트를 바탕으로 답변을 도출해야하는 MRC 태스크에 있어 위와 같은 방법을 적용할 경우, 답변이 포함된 부분이 잘리는 문제가 발생할 수 있습니다. 그렇기에 이런 경우 전체 문서를 훑기 위해 최대 입력 시퀀스 만큼 stride를 하게 됩니다. (예를 들어 1,024 토큰 길이의 문서가 입력될 경우 최대 입력 시퀀스가 512인 모델은 해당 문서를 두번 stride하게 됩니다.)
BigBird 모델은 위와 같은 한계를 어느정도 극복하기 위해 제안된 모델입니다.
BigBird 모델은 BERT의 8배인 최대 4,096개의 토큰을 입력 시퀀스로 받을 수 있습니다. 이럴 수 있는 이유는 BigBird는 full-attention이 아닌 Spare-attention을 기반으로 동작하기 때문입니다.
3.2. KoBigBird finetuning
많은 연구자들이 사용하는 KoELECTRA 모델을 공유해주신 monologg님께서 KoBigBird모델도 포팅해주셨습니다.
우선 KoBigBird 모델을 clone해줍니다.
git clone https://github.com/monologg/KoBigBird.git이후 KoBigBird/finetune 디렉토리로 이동합니다. 해당 디렉토리에는 KoBigBird모델을 plm으로 하여 Classification 및 QuestionAnswering 태스크를 수행할 수 있는 데이터 및 학습코드가 존재하고 있습니다.
-
우선 필요한 패키지를 설치합니다.
pip install -r requirements.txt -
아래 스크립트를 실행하여 QuestionAnswering관련 데이터셋 다운로드 작업을 수행합니다.
(TyDi QA 및 KorQuAD2.1 데이터셋이 다운됩니다.)bash download_qa_dataset.sh -
KoBigBird/finetune/scripts디렉토리에는 각종 데이터셋에 대한 finetuning 스크립트 파일이 존재합니다. 여기서는 KorQuAD finetuning을 위해run_korquad_2.sh파일을 실행합니다.
(꽤나 시간이 오래 소모되는 작업이기 때문에 background running으로 수행하여 결과값을 중간중간 살펴보는 것이 좋을 것 같습니다.)bash scripts/run_korquad_2.sh
- 학습이 완료되면
KoBigBird/finetune/output디렉토리로 모델이 저장됩니다.
.jpeg)