.png)
Intro
오늘은 초기 Object Detection 발전에 가장 많은 영향을 미친 논문인 Ross Girshick의 Rich feature hierarchies for accurate object detection and semantic segmentation 즉, R-CNN에 대한 논문 리뷰를 간단히 하고자 한다.
우선 Obejct Detection이란 이미지가 무엇인지 판단하는 Classification과 이미지 내의 물체의 위치 정보를 찾는 Localization을 수행하는 것을 말한다. 이를 통해 영상 내의 객체가 사람인지 동물인지 물건인지 등을 구별하여 각 객체가 어디에 위치하는지 표시하는 것이 가능하다.
Abstract
지난 몇 년 동안 PASCAL VOC 데이터셋에서 Object Detection의 가장 좋은 성능을 내는 것은 high-level context의 복잡한 앙상블 모델이었다. 하지만 이 논문에서는 VOC 2012 데이터를 기준으로 이전 모델에 비해 mAP(mean average precision)가 30%이상 향상된 더 간단하고 확장 가능한 detection 알고리즘을 소개하였다.
이 알고리즘은 크게 두 가지 핵심 인사이트를 가지고 있는데 다음과 같다.
- 객체를 localize 및 segment하기 위해 bottom-up방식의 region proposal(지역 제안)에 Convolutional Neural Network를 적용
- domain-specific fine-tuning을 통한 supervised pre-training을 적용
저자는 해당 모델을 R-CNN(Regions with CNN features)이라고 명시하였으며, 그 이유는 CNN과 Region proposal이 결합되었기 때문이라고 한다.
1. Introduction
지난 10년간 다양한 visual recognition 작업에서는 주로 SIFT와 HOG(gradient 기반의 특징점 추출 알고리즘)가 가장 많이 사용되었는데, 이는 2010 ~ 2012년의 PASCAL VOC obeject detection에서 일반적으로 인정되는 방법이었다. 하지만 이후 back-propagation이 가능한 SGD(Stochastic Gradient Descent)기반의 CNN(Convolutional Neural Networks)이 등장하기 시작하였고 SIFT와 HOG와 같은 알고리즘과 비교하여 PASCAL VOC object detection에서 굉장한 성능을 보이게 되었다.
Image Classification과 다르게 detection은 이미지내에서 객체를 localizing하는 것이 요구되는데 이를 위해, 논문의 모델은 sliding-window 방식을 적용하였고, 높은 공간 해상도(high spartial resolution)을 유지하기 위해 5개의 Convolutional 레이어를 적용하였다.
우선 간단하게 R-CNN은 아래와 같은 프로세스로 작동한다.
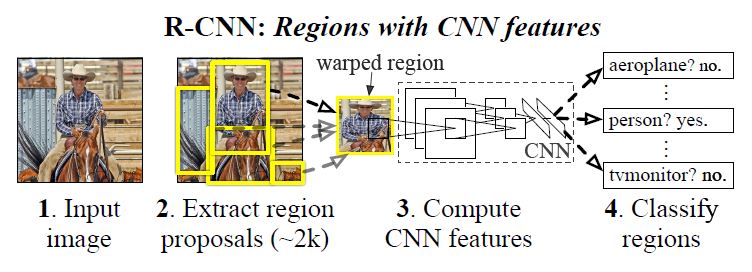
R-CNN 프로세스
1. Input 이미지로부터 2,000개의 독립적인 region proposal을 생성
2. CNN을 통해 각 proposal 마다 고정된 길이의 feature vector를 추출(CNN 적용 시 서로 다른 region shape에 영향을 받지 않기 위해 fixed-size로 이미지를 변경)
3. 이후, 각 region 마다 category-specific linear SVM을 적용하여 classification을 수행
2. Object detection with R-CNN
이 논문의 object detection은 크게 3가지 모듈로 구성되어 있다.
1. category-independent한 region proposals를 생성
2. 각 region으로부터 feature vector를 추출하기 위한 large CNN
3. classification을 위한 linear SVMs
이제 아래에서 본격적으로 각 모듈에 대해 설명하고 PASCAL VOC2010-12에 대한 결과를 소개한다.
Region proposals
카테고리 독립적인 region proposal을 생성하기 위한 방법은 여러가지가 있는데 해당 논문에서는 이전 detection 작업들과 비교하기 위하여 Selective Search라는 최적의 region proposal를 제안하는 기법을 사용하여 독립적인 region proposal을 추출하였다. selective search는 아래와 같은 프로세스로 이루어진다.
Selective Search
1. 이미지의 초기 세그먼트를 정하여, 수많은 region 영역을 생성
2. greedy 알고리즘을 이용하여 각 region을 기준으로 주변의 유사한 영역을 결합
3. 결합되어 커진 region을 최종 region proposal로 제안
Feature extraction
우선 위에서 언급한 Selective Search를 통해 도출 된 각 region proposal로부터 CNN을 사용하여 4096차원의 feature vector를 추출한다. 이후, feature들은 5개의 convolutional layer와 2개의 fully connected layer로 전파되는데, 이때 CNN의 입력으로 사용되기 위해 각 region은 227x227 RGB의 고정된 사이즈로 변환되게 된다.

Training
학습에 사용되는 CNN 모델의 경우 ILSVRC 2012 데이터 셋으로 미리 학습된 pre-trained CNN(AlexNet)모델을 사용한다.
Domain-specific fine-tuning
Classification에 최적화된 CNN 모델을 새로운 Detection 작업 그리고 VOC 데이터셋에 적용하기 위해 오직 VOC의 region proposals를 통해 SGD(stochastic gradient descent)방식으로 CNN 파라미터를 업데이트 한다. 이후 CNN을 통해 나온 feature map은 SVM을 통해 classification 및 bounding regreesion이 진행되게 되는데, 여기서 SVM 학습을 위해 NMS(non-maximum suppresion)과 IoU(inter-section-over-union)이라는 개념이 활용된다.
IoU는 Area of Overlap(교집합) / Area of Union(합집합)으로 계산되며, 간단히 말해 전체 bounding box 영역 중 겹치는 부분의 비율을 나타내는데 NMS 알고리즘이 이 IoU 점수를 활용하여 겹치는 박스를 모두 제거하고 가장 적합한 박스만 남기게 된다. NMS의 과정을 간단히 살펴보면 아래와 같은 프로세로 진행된다.
NMS(Non-maximum suppresion)
1. 예측한 bounding box들의 예측 점수를 내림차순으로 정렬
2. 높은 점수의 박스부터 시작하여 나머지 박스들 간의 IoU를 계산
3. IoU값이 지정한 threhold보다 높은 박스를 제거
4. 최적의 박스만 남을 떄까지 위 과정을 반복
해당 논문에서는 SVM 학습을 위한 라벨로서 IoU를 활용하였고 IoU 가 0.5이상인 것들을 positive 객체로 보고 나머지는 negative로 분류하여 학습하게 된다. 각 SGD iteration마다 32개의 positive window와 96개의 backgroud window 총 128개의 배치로 학습이 진행된다.
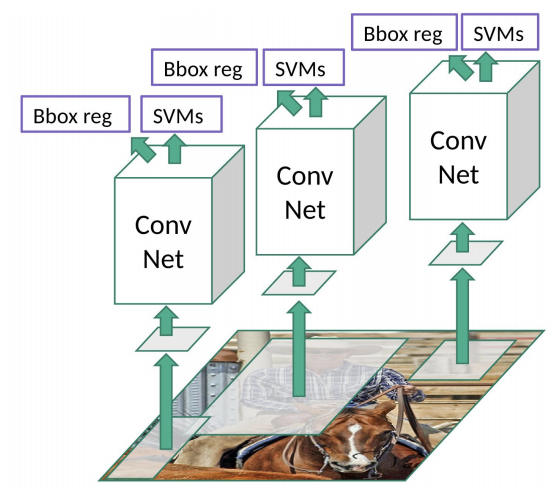
3. Results on PASCAL VOC 2010-12
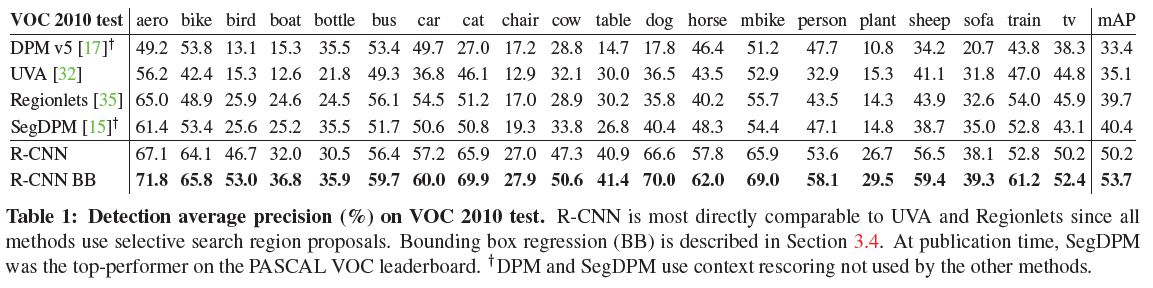
위 테이블은 VOC 2010 테스트 데이터에 대한 각 모델별 결과이다. 맨 오른쪽에서 mAP를 확인할 수 있는데, 논문에서는 결과를 비교하는데 같은 region proposal 알고리즘을 적용한 UVA모델과 mAP를 비교한다.
위 표를 보면 UVA 모델의 mAP는 35.1%이고, R-CNN의 mAP는 53.7%인 것을 확인할 수 있으며 이것은 높은 증가율이라고 저자는 말한다. 또한 VOC 2011/12 데이터 셋 또한 53.3% mAP 높은 성능을 나타냈다.
4. Problems
R-CNN의 가장 큰 문제는 복잡한 프로세스로 인한 과도한 연상량에 있다. 최근에는 고성능 GPU가 많이 보급 되었기 때문에 deep한 neural net이라도 GPU연산을 통해 빠른 처리가 가능하다. 하지만 R-CNN은 selective search 알고리즘를 통한 region proposal 작업 그리고 NMS 알고리즘 작업 등은 CPU 연산에 의해 이루어 지기 때문에 굉장히 많은 연산량 및 시간이 소모된다.
또한 SVM 예측 시 region에 대한 classification 및 bounding box에 대한 regression 작업이 함께 작동하다 보니 모델 예측 부분에서도 연산 및 시간이 많이 소모되어 real-time 분석이 어렵다는 단점이 있다.
R-CNN의 이러한 한계들로 인해, 추후 프로세스 및 연산 측면에서 보완된 모델이 나오게 되는데 그것이 바로 Fast R-CNN과 Faster R-CNN이다.
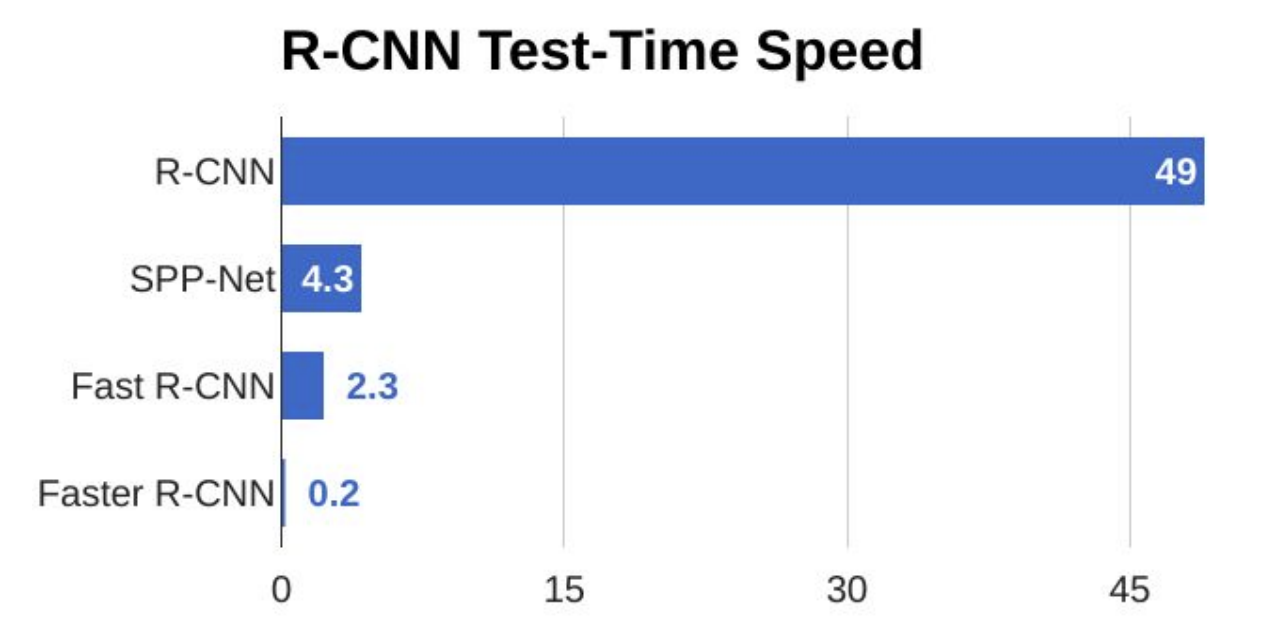
위 그림은 R-CNN, SPP-Net, Fast R-CNN, Faster R-CNN의 실행 속도 차이를 나타내는데 Faster R-CNN이 이전 모델보다 비교가 안될 정도로 훠얼씬 빠르다는 것을 알 수 있다. (성능도 더 좋아졌다.)
아래에서 Fast R-CNN과 Faster R-CNN에 대해 간단하게 집고 넘어가 보도록 한다.
5. Fast R-CNN & Faster R-CNN
Fast R-CNN
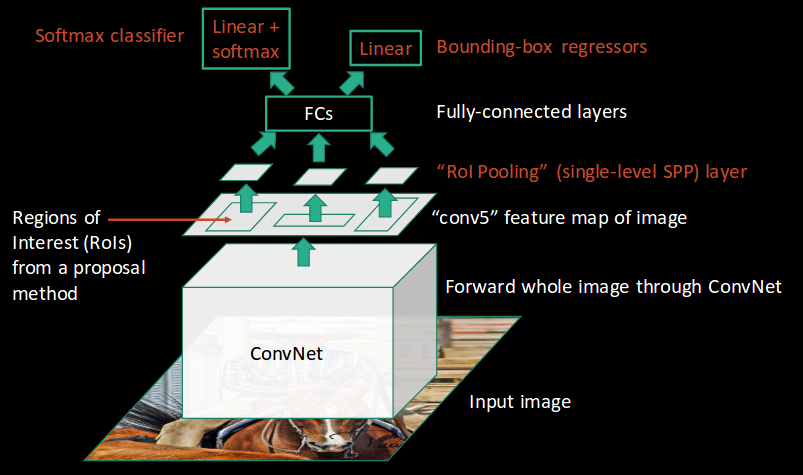
Fast R-CNN의 R-CNN의 문제를 해결하기 위해 나온 모델이다.
동작 방식은 R-CNN과 유사하게 region proposal이 작동하지만, RCNN과 다르게 Fast R-CNN은 먼저 전체 이미지가 ConvNet의 input으로 입력이 된다. 이미지는 ConvNet을 통과하며 feature map을 추출하게 되고, 이 feature map은 selectice search 기반의 region proposal을 통해 RoI(Regions of Interest)를 뽑아낸다.
이후 선택 된 Region들은 RoI Pooling layer를 거치게 되는데, 이 과정은 추후 예측을 위해 region들을 다운 사이즈하여 모두 같은 고정된 크기로 변환해주는 역할을 한다. 마지막 과정으로 fully connected layer를 거치며 Softmax Classification과 Bounding Box Regression이 수행된다.
위의 과정은 하나의 ConvNet모델에 의해 동시에 수행이 되기 때문에 RCNN에 비하여 훨씬 빠르게 작동하는 장점이 있다. 하지만 결국 Fast RCNN 또한 많은 연산을 필요로 하는 Selective Search 기법이 작동을 하므로 큰 데이터 셋에 적용하는데는 한계가 있다.
Faster R-CNN
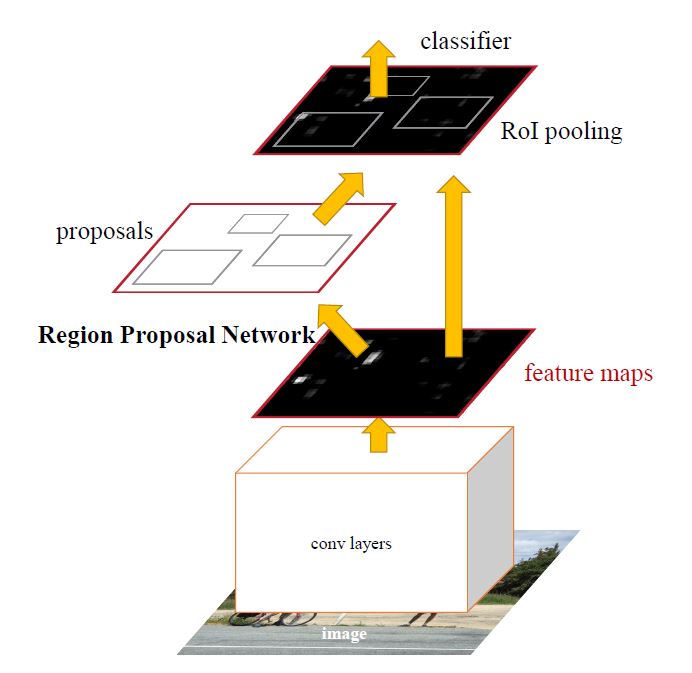
Faster R-CNN은 R-CNN과 Fast R-CNN이 region proposal로 인한 과도한 연산 문제를 해결하기 위해 나온 모델이다. 기존 region proposal에 사용되었던 selective search는 연산량을 늘리고 시간을 많이 소모하는 주요 원인이었다. 그래서 Faster R-CNN에서는 selective search 알고리즘을 없애고 Region Proposal Networks(RPN)라는 뉴럴 네트워크를 추가하여 region proposal을 예측하도록 했다.
그 후, 예측된 region proposal은 Fast R-CNN과 유사하게 RoI Pooling layer를 거치며 모든 region을 같은 크기로 고정 후, Classification 및 Bounding Box Regreesion이 수행된다.
References
paper
- R-Rich feature hierarchies for accurate object detection and semantic segmentation(https://arxiv.org/abs/1311.2524)
- Fast R-CNN(https://arxiv.org/abs/1504.08083)
- Faster R-CNN(https://arxiv.org/abs/1506.01497)
blog
.jpeg)