BERT: Pre-training of Deep Bidirectional Transformer for Language Understanding
개요, Abstract
BERT라는 새로운 언어 표현 모델을 소개한다. Bindirectional Encoder Representations from Transformers의 약자로, 최신의 언어 표현 모델들과는 달리 BERT는 모든 층에서 양방향으로 텍스트를 읽고 pre-train(이하 사전 학습 or 훈련) 되도록 설계되었다. 그 결과, 사전 훈련된 BERT 모델은 fine-tuning(이하 미세 조정) 할 수 있게 됐고 여러 task(질의 응답, 언어 추론 등)에서 sota를 기록하는 모델이 되었다.
소개, Introduction
언어 모델에 사전 학습은 자연어 처리 과제에서 좋은 성능을 보였었다. 문장 단위의 언어 추론과 의역과 같은 과제에서 마찬가지였다. 이 과제들의 goal은 문장들을 전체적으로 분석해서 이들의 관계를 예측하는 것이다. NER(개체명 인식)과 질의 응답 같은 token 단위의 과제에서도 같다. 이러한 과제에서는 모델은 token level에서의 세밀한(fine-grained) 출력을 요구된다.
사전 학습 언어 표현은 두 개의 방법이 있다: feature-based(이하 특징 기반)과 미세 조정이다. ELMo와 같은 특징 기반 방법은 task는 사전 학습 표현에 추가된 특징들에 맞춰진 구조를 사용했다. GTP와 같은 미세 조정 방법은 task에 최소한으로 맞춰진 parameter들을 사용하고 사전 학습된 모든 파라미터들을 미세 조정하는 작업을 했다. 이 두 방법은 사전 학습에서 같은 목표 함수를 갖고, 범용적인 언어 포현은 학습하기 위한 방향이 없은 (undirectional) 언어 모델이다.
본고는 현 기술력이 사전 학습 표현을 하기에는 제한이 있다고 주장한다, 특히 미세 조정 기법에서. 가장 큰 한계점은 통상적인 언어 모델들은 undirectional하고, 이는 사전 학습에 사용될 구조들은 제한한다. 예시로 GPT에서 저자는 왼쪽에서 오른쪽 구조를 사용한다. 이는 transformer의 self-attention 층에서 모든 token들이 그 이전 token에만 attention할 수 밖에 없다. 미세 조정 방법을 사용하는 문장 level의 task 에서 이러한 구조는 굉장히 치명적이다. 이 때문에 양방향으로 문맥 파악이 더 중요한 것이다.
본고에서는 BERT를 제안함으로써 미세 조정 기반 방법을 보완한다. BERT는 MLM(Masked Language Model)을 사용함으로서 전에 말했던 문제들을 완화한다. MLM은 입력 token에서 임의적으로 가린(masks) 다음 가려진 어휘 id를 문맥으로 예측하는 것이다. 좌-우 언어 모델 사전 학습과는 달리, MLM은 왼쪽과 오른쪽 문맥 표현을 읽는것을 가능케한다. 즉, deep bidirectional Transformer를 사전 훈련할 수 있게 된 것이다. 또한, text-pair 표현과 같이 사전 학습되는 next sentence prediction을 사용했다.
본고가 기여한 점은 다음과 같다:
-
저자는 언어 표현에서 양방향 사전 학습의 중요성을 보여줬다. BERT는 MLM을 사용해 심층 양방향 표현을 가능하게 했다.
-
사전 훈련에 필요했던 모델 구조에 맞게 필요한 많은 공학적 작업들을 줄였다. BERT는 과제 맞춤형 구조들보다 문자 level이나 token level에서 우월한 sota 성능을 보인 첫 미세 조정 기반 표현 모델이다.
-
BERT는 11가지 자연어 처리 과제에서 sota를 달성했다. https://github.com/google-research/bert. 에서 모델 사용이 가능하다.
관련 연구, Related Work
범용 언어 표현의 사전 훈련에는 긴 역사가 있다. 가장 널리 사용된 방법들을 여기서 간단히 알아본다.
비지도 특징 기반 방법
단어의 표현의 넓게 적용 하기 위한 연구 분야는 non-neural(Brown et al., 1992;
Ando and Zhang, 2005; Blitzer et al., 2006)과 neural(Mikolov et al., 2013; Pennington et al.,
2014)방법을 포함해 몇 십년간 연구되었다. 사전 학습된 word embeddings은 현대 NLP 체계에 필수적인 요소이고, 처음부터 embedding을 시작하는데(Turian et al., 2010) 큰 보완점이 되었다. 단어 embedding 벡터를 사전 훈련하기 위해선, left-to-right 언어 모델링들이 사용 됐었다.(Mnih and Hinton, 2009) 왼편과 오른편의 문맥의 정답과 오답을 분별하는 분야 또한 마찬가지다(Mikolov et al., 2013).
이러한 접근들은 coarser granularities(https://lastyouth.tistory.com/4 ; 참고)을 범용화 시켰다. 이러한 예시로는 문장 embeddings (Kiros et al., 2015; Logeswaran and Lee, 2018) 문단 embedding (Le and Mikolov, 2014)이다. 문장 표현을 훈련시키기 위해서는, 다음 문장의 후보 랭크를 매기거나(Jernite et al., 2017; Logeswaran and Lee, 2018) 이전 문장이 주어졌을 때 다음 문장 단어의 left-to-rigt 생성(Kiros et al., 2015)이나 오토인코더에서 파생된 노이즈제거(Hill et al., 2016) 등의 예전의 방식을 사용했다.
ELMo 와 이 전 연구(Peters et al., 2017, 2018a)는 다른 차원에서의 전통적인 단어 embedding 범용화했다. 이들은 context-sensitive한 특징들을 left-to-right 또는 right-to-left 언어 모델에서 추출했다. 각 token의 문맥적인 표현은 left-to-right 또는 right-to-left의 연속적인 표현이다. 이미 존재하는 과제 특화적인 구조들에 문맥적 단어 embedding을 통합(integrating)시키면 ELMo는 주요한 NLP benchmark에서 향상된 sota를 만들었다. (Peters et al., 2018a), 질의응답(Rajpurkar et al., 2016), 감성 분석(Socher et al., 2013), 개체명 인식(Tjong Kim Sang and De Meulder, 2003)을 포함한다. . Melamud et al. (2016)은 왼편과 오른편의 문맥을 LSTM을 사용해 예측하는 과제를 문맥적 표현을 훈련하는 방식을 제안했다. ELMo와 비슷하게, 이들은 특징 기반이고 심층 양방향이 아니다. . Fedus et al. (2018)가 빈칸 채우기 과제는 텍스트 생성 모델을 강건함(robustness)를 보완하는 것을 보여줬다.
비지도 미세 조정 방법
특징 기반 방법과 같이, 라벨링 없는 텍스트를 파라미터를 단어 embedding 방향성으로만 사전 학습하는 초기 연구가 있었다 (Collobert and Weston, 2008).
좀 더 최근에는, 라벨링 없는 텍스트나 supervised downstream task의 미세 조정에 사용되는 사전 학습을 문맥적 token 표현에 단어나 문서 인코더를 사용한다(Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). 이 방법에 장점으로는 처음부터 시작할 때 적은 데이터만 사용해도 된다는 것이다. 이런 장점 때문인지 OpenAI GPT(Radford et al., 2018)는 문장 단위 과제들, GLUE benchmark (Wang et al., 2018a)에서 sota를 달성한다. left-to-right 언어 모델링이나 오토 인코더 과제들은 이러한 모델들을 사전 학습에 사용했다(Howard and Ruder, 2018; Radford et al., 2018; Dai and Le, 2015).
지도 데이터의 전이 학습
자연어 추론(Conneau et al., 2017)이나 기계 번역(McCann et al., 2017) 같은, 큰 데이터셋에 지도 학습을 하는 과제에 효과적인 전이 방식이 연구되었었다. CV 연구에서도 전이 학습의 학습에 중요성이 드러났다. 효과적인 선례로는 ImageNet(Deng et al., 2009; Yosinski et al., 2014)에 사전 학습한 미세 조정된 모델을 사용하는 것이다.
모델, BERT
이 장에서는 BERT와 자세한 구현을 소개한다. 이 프레임워크는 두 가지 단계가 있다: 사전 학습과 미세 조정이 그것이다. 사전 학습 중에는 모델은 라벨링 되지 않은 다른 과제들의 사전 학습으로 학습된다. 미세 조정은 BERT는 사전 학습된 파라미터들로 시작하고, 모든 파라미터들은 downstream 과제에서 라벨링 된 데이터 미세 조정 된다. 똑같은 사전 학습된 파라미터들로 시작되었어도, downstream 과제는 각자 다르게 미세 조정된 모델들이다. fig1에 질의 응답 예시는 이 섹션에서의 예시가 된다.
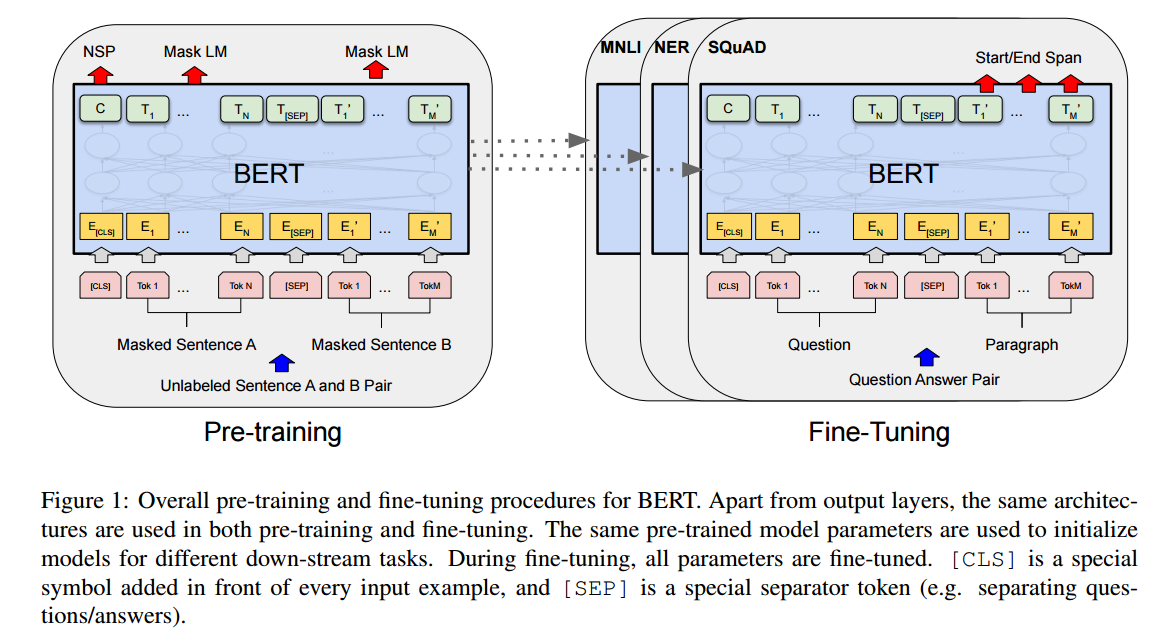 Figure 1
Figure 1
BERT의 독특한 특징은 다른 작업들에 확일화된 구조이다. 사전 학습 구조와 마지막 downstream 구조 사이에는 아주 작은 차이가 있다.
Model Architecture
BERT의 모델 구조는 Vaswani et al. (2017)에서 기술된 원래 구현에 기초한 다층 양방향 트랜스포머 인코더이다. 그리고 tensor2tensor 라이브러리에 출시 됐다. 트랜스포머의 사용이 일반화되고, 본고의 구현이 거의 같은 이유 때문에, 기초 모델 구조와 ref 자료에 대한 설명 Vaswani et al. (2017)은 생략한다. 또 아주 훌륭한 가이드인 "The Annotated Transformer"도 생략한다.
이 논문에서는 층의 개수는 로, 은닉층 크기는 , self-attention head의 개수는 로 표기한다. 본 논문은 두개의 다른 크기의 모델에 대해 서술한다: BERT BASE (L=12, H=768, A=12, Total Parameters=110M) and BERT LARGE (L=24, H=1024, A=16, Total Parameters=340M).
BERT BASE는 비교를 위해 OpenAI GPT와 같은 모델 사이즈를 같는다. 여기서 중요한 점은 BERT Transformer는 양방향 self-attention을 사용하고, GPT Transformer는 왼편의 token에서만 attend 할 수 있는 제약된 self-attention을 사용한다.
Input/Output Representations
여러 down-stream 과제에서 BERT를 사용하기 위해, 입력 representation은 한 개의 문장 token에 한 문장이나 두 개의 paired 된 문장 (e.g. Question, Answer) 둘 다 모호한 표현을 허용한다. 이 작업에서 '문장'은 연속적은 텍스트의 임의적인 span이 될 수 있다. '시계열'은 BERT에 넣을 입력 token 시계열이고, 이는 한 개의 문장이나 포장된 두 개의 문장이다.
이 논문에서는 30,000개의 token vacabulary를 WordPiece embedding(Wu et al., 2016)에서 사용한다. 모든 시계열의 첫 번째 token은 항상 a special classification
token ([CLS])이다. 마지막 은닉 단계과 일치하는 이 token(CLS)는 분류 작업을 위한 시계열 표현 합계에 사용된다. 두 개의 문장은 한 개의 시계열로 포장되어 있다. 이 논문에서 문장을 두 가지 방법으로 구분한다. 첫 번째는, special token(SEP)로 나누는 것이고, 두 번째는 A 문장인지 B 문장인지 알려주는 학습된 embedding을 모든 token에 추가하는 것이다. Fig 1 에서 볼 수 있듯이, 입력 embedding은 , special(CLS) token의 마지막 은닉 벡터은 , 입력 token을 위한 마지막 은닉 벡터는 으로 표기했다.
주어진 token의 입력 표현은 corresponding(동일한) token, segment, position embedding의 합계로 입력 representation이 설계했다. 이 설계의 시각화는 Fig 2에 있다.
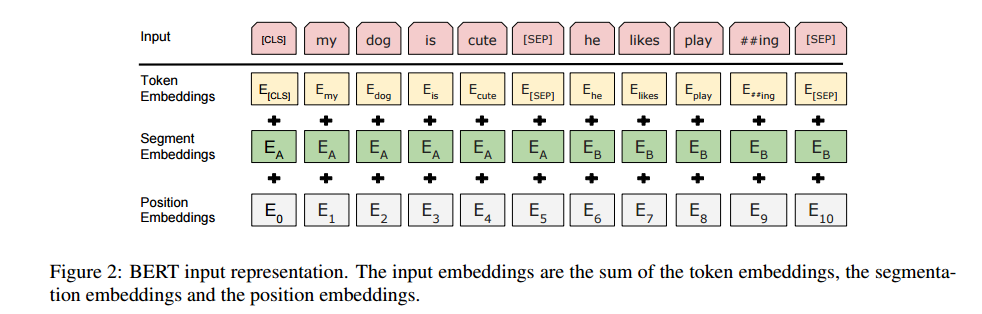 Figure 2
Figure 2
3.1 Pre-training BERT
Peters et al. (2018a) and Radford et al. (2018) 과는 다르게 이 논문에서는 left-to-right, right-to-left 언어 모델을 사용해 BERT를 사전 학습하지 않았다. 그 대신, 밑에 후술되는 세션으로 BERT를 사전 학습했다. 이 단계는 Fig 1에 왼쪽편에 나와있다.
Task #1: Masked LM
직관적으로, left-to-right 모델이나 얕은 left-to-right과 right-to-left 모델들을 합친 모델보다 깊은 양방향 모델이 더 강력하다고 보는 것이 합리적이다. 불행히도, 평균의 조건부 언어 모델은 left-to-right이나 right-to-left로 밖에 학습이 안된다. 양뱡항 조건은 각 단어를 간접적(indirectly) 스스로를 기억하고(see itself), 모델은 다층 문맥의 단어를 하찮은 수준으로 예측하니 말이다.
심층 양방향 표현을 학습하기 위해서, 저자는 몇개의 입력 token에 임의적으로 mask(이하 마스킹)작업을 했고, 이 가려진 부분을 예측했다. 저자는 이 단계를 'Masked LM'(MLM)이라고 칭한다. 이 작업은 자주 문학 과제에 Cloze (Taylor, 1953) 작업이라고도 한다. 이 경우, 마지막 은닉 벡터, 마스킹된 token과 동일한, 는 일반적인 LM으로 소프트맥스 출력에 들어간다. 우리의 모든 실험에서 각 시계열의 임의적으로, 단어 조각(WordPiece)의 15%를 마스킹했다. 잡음을 없애는(denoising) 오토 인코더(auto-encoders)(Vincent et al., 2008)와는 대조적으로 저자는 입력을 구조화하기 보다 오로지 마스킹 된 단어들만 예측했다.
이런 작업은 양방향 사전학습 모델을 얻을 수 있게 하지만, 마스크된 토큰은 미세 조정중엔 나오지 않기 때문에, 사전 학습과 미세 조정간에 매치가 맞지 않는다.(mismatch) 이를 완화하기 위해, 항상 마스킹된 단어를 실제 마스킹된 토큰(actual mask token)과 전치하진 않는다. 훈련 데이터 생성기는 예측을 위한 15%의 임의적인 token 위치를 고른다. 만약 -th token이 선택됐다면, -th 토큰과 (1) 80%는 마스킹된 토큰과 (2) 10%는 임의적인 토큰과 (3) 10%는 바뀌지 않는 -th 토큰으로 바꾼다. 그리고 는 cross entropy loss로 원래의 token을 예측한다. 저자는 이런 여러가지 상황을 비교하는 단계를 부록 C.2.에 기록했다.
Task #2: Next Sentence Prediction (NSP)
아래는 문장 간의 관계를 이해하는 것이 언어 모델링에서 직접적으로 포착되지 않기 때문에, 질문 답변(QA) 및 자연어 추론(NLI)과 같은 많은 중요한 하위 작업들이 이를 기반으로 합니다. 문장 관계를 이해하는 모델을 훈련시키기 위해, 모든 단일 언어 말뭉치에서 쉽게 생성할 수 있는 이진화된 다음 문장 예측 작업에 대한 사전 훈련을 진행합니다. 구체적으로, 각 사전 훈련 예제에 대해 문장 A와 B를 선택할 때, 50%의 경우 B는 A 다음에 실제로 따라오는 다음 문장입니다 (IsNext로 레이블링됨), 나머지 50%의 경우 말뭉치에서 임의의 문장입니다 (NotNext로 레이블링됨). 그림 1에 나와있는 것처럼, C는 다음 문장 예측(NSP)에 사용됩니다. 이러한 간단한 방법에도 불구하고, 섹션 5.1에서 보여주는 바와 같이 이러한 작업을 향한 사전 훈련은 QA 및 NLI에 매우 유용하다는 것을 입증합니다. NSP 작업은 Jernite et al. (2017) 및 Logeswaran과 Lee (2018)에서 사용된 표현 학습 목적과 관련이 있습니다. 그러나 이전 작업에서는 문장 임베딩만 하위 작업으로 전달되었지만, BERT는 모든 매개 변수를 전달하여 최종 작업 모델 매개 변수를 초기화합니다.
Pre-training data
사전 훈련 절차는 언어 모델 사전 훈련에 대한 기존 문헌을 크게 따릅니다. 사전 훈련 말뭉치로는 BooksCorpus(800M 단어) (Zhu et al., 2015)와 영어 위키백과(2,500M 단어)를 사용합니다. 위키백과에서는 목록, 표, 헤더를 제외하고 텍스트 문장만 추출합니다. 긴 연속적인 시퀀스를 추출하기 위해 Billion Word Benchmark (Chelba et al., 2013)와 같이 섞인 문장 수준 말뭉치가 아니라 문서 수준 말뭉치를 사용하는 것이 중요합니다.
3.2 Fine-tuning BERT
Transformer 내의 self-attention 메커니즘 덕분에 fine-tuning은 간단합니다. 적절한 입력과 출력으로 대체하여 BERT가 많은 하위 작업을 모델링할 수 있습니다. 텍스트 쌍이 포함된 응용 프로그램의 경우, Parikh et al. (2016) 및 Seo et al. (2017)와 같이 양방향 교차 어텐션을 적용하기 전에 텍스트 쌍을 독립적으로 인코딩하는 것이 일반적인 패턴입니다. 그러나 BERT는 이러한 두 단계를 통합하기 위해 self-attention 메커니즘을 사용합니다. 이는 두 개의 문장 사이에서 양방향 교차 어텐션을 효과적으로 포함하면서 연결된 텍스트 쌍을 인코딩합니다. 각 작업에 대해 BERT에 작업별 입력 및 출력을 단순히 연결하여 모든 매개 변수를 미세 조정하여 엔드 투 엔드로 작업을 수행합니다. 입력에서는, 사전 훈련에서의 문장 A와 문장 B는 (1) 다의어 처리에서의 문장 쌍, (2) 함의에서의 가설-전제 쌍, (3) 질문-통과 쌍에서의 질문-통과 쌍, (4) 텍스트 분류나 시퀀스 태깅에서의 감소된 텍스트-∅ 쌍과 유사합니다. 출력에서는 토큰 표현이 시퀀스 태깅이나 질문 답변과 같은 토큰 수준 작업을 위해 출력 레이어로 공급되며, [CLS] 표현은 entailment나 감성 분석과 같은 분류 작업을 위해 출력 레이어로 공급됩니다.
사전 훈련과 비교하여 fine-tuning은 비교적 저렴합니다. 논문의 모든 결과는 동일한 사전 훈련 모델을 사용하여 최대 1시간 이내의 단일 Cloud TPU에서 또는 몇 시간 이내의 GPU에서 재현할 수 있습니다. 해당 작업 세부 정보는 섹션 4의 해당 하위 섹션에서 설명합니다. 추가 정보는 부록 A.5에서 찾을 수 있습니다.
실험, Experiments
실험 결과는 걍 보세용
소거 실험, Ablation Studies
이 섹션에서는 BERT의 여러 측면에 대한 더 나은 이해를 위해 소거 실험을 수행합니다. 추가적인 소거 연구는 부록 C에서 찾을 수 있습니다.
5.1 Effect of Pre-training Tasks
우리는 BERT의 깊은 양방향성의 중요성을 평가하기 위해 BERTBASE와 정확히 동일한 사전 훈련 데이터, 미세 조정 방법 및 하이퍼 파라미터를 사용하여 두 가지 사전 훈련 목표를 평가합니다.
- No NSP: NSP 작업 없이 "masked LM" (MLM)을 사용하여 훈련된 양방향 모델입니다.
- LTR & No NSP: MLM 대신 표준 좌측에서 우측 방향 (LTR) LM을 사용하여 훈련된 좌측 문맥 전용 모델입니다. 미세 조정에서도 좌측만 사용하도록 제약 조건이 적용되었습니다. 이는 사전 훈련/미세 조정 불일치를 도입하여 하위 작업 성능을 저하시키기 때문입니다. 또한 이 모델은 NSP 작업 없이 사전 훈련되었습니다. 이는 OpenAI GPT와 직접 비교할 수 있지만, 우리의 더 큰 교육 데이터셋, 우리의 입력 표현 및 미세 조정 방법을 사용합니다.
우선 NSP 작업이 가져온 영향을 검토합니다. 표 5에서, NSP를 제거하면 QNLI, MNLI 및 SQuAD 1.1에서 성능이 크게 저하되는 것을 보여줍니다. 그다음 "No NSP"와 "LTR & No NSP"를 비교하여 양방향 표현을 훈련하는 데 영향을 평가합니다. LTR 모델은 모든 작업에서 MLM 모델보다 성능이 낮으며 MRPC와 SQuAD에서 큰 저하가 있습니다. SQuAD에서는 LTR 모델이 토큰 예측에서 성능이 낮을 것으로 직관적으로 이해할 수 있습니다. 이를 보완하기 위해 우리는 무작위로 초기화된 BiLSTM을 추가하여 LTR 시스템을 강화하려고 노력했습니다. 이것은 SQuAD에서 결과를 크게 개선하지만, 사전 훈련 된 양방향 모델의 결과보다는 여전히 훨씬 나쁩니다. BiLSTM은 GLUE 작업에서 성능을 저하시킵니다.
우리는 LTR 및 RTL 모델을 개별적으로 훈련하고 각 토큰을 두 모델의 연결로 나타낼 수도 있습니다.
5.2 Effect of Model Size
이 섹션에서는 미세 조정 작업 정확도에 대한 모델 크기의 영향을 탐색합니다. 우리는 이전과 동일한 하이퍼파라미터 및 훈련 절차를 사용하면서 다른 레이어 수, 은닉 유닛 수 및 어텐션 헤드 수를 가진 여러 개의 BERT 모델을 훈련했습니다.
선택한 GLUE 작업의 결과는 표 6에 나와 있습니다. 이 표에서는 미세 조정의 5개 무작위 재시작에서 평균 개발 세트 정확도를 보고합니다. 우리는 더 많은 레이어를 가진 모델이 모든 네 데이터 세트에서 엄격한 정확도 향상을 이끌어냄을 볼 수 있습니다. 심지어 MRPC에서도, 이는 라벨이 지정된 훈련 예제가 3,600개 뿐이며, 사전 훈련 작업과 크게 다릅니다. 기존 문헌과 비교했을 때 이미 상당히 큰 모델에 대한 개선을 이루어 냈음에도 놀랍게도 이러한 유의미한 개선을 얻을 수 있었습니다.
예를 들어, Vaswani et al. (2017)에서 탐색한 가장 큰 Transformer는 인코더의 파라미터가 100M이며 (L=6, H=1024, A=16)이고, 우리가 문헌에서 찾은 가장 큰 Transformer는 235M 파라미터를 가진 (L=64, H=512, A=2)입니다 (Al-Rfou et al., 2018). 반면에, BERTBASE는 110M 파라미터를 포함하고 BERTLARGE는 340M 파라미터를 포함합니다.
기존 문헌에서는 모델 크기를 늘리면 기계 번역 및 언어 모델링과 같은 대규모 작업에서 지속적인 개선이 있을 것으로 알려져 왔습니다. 이는 표 6에 나와 있는 훈련 데이터에서의 언어 모델 퍼플렉서티로 나타내어졌습니다. 그러나 우리는 이것이 사전 훈련된 모델이 충분히 훈련된 경우 극단적인 모델 크기로 확장하는 것이 매우 작은 규모의 작업에서도 큰 개선을 이끌어내는 것을 처음으로 설득력 있게 입증했다고 믿습니다.
Peters et al. (2018b)는 사전 훈련된 이중 언어 모델의 크기를 2에서 4개 레이어로 늘리는 것의 하향 작업 영향에 대한 혼합된 결과를 제시했으며, Melamud et al. (2016)는 200에서 600으로 숨겨진 차원 크기를 늘리는 것이 도움이 된다는 것을 언급했지만 1,000으로 더 크게 늘리는 것은 추가 개선을 가져오지 않았습니다. 이전 연구들은 특징 기반 접근 방식을 사용했으므로 매우 작은 규모의 작업에서도 큰, 더 표현력 있는 사전 훈련된 표현으로부터 이점을 얻을 수 있다는 가설을 제기할 때 이러한 모델이 작업별 모델링을 위해 추가로 무작위로 초기화된 매개 변수를 매우 적게 사용할 때, 이러한 모델이 이미 충분히 사전 훈련된 표현을 사용하여 작은 규모의 작업에서 이점을 얻을 수 있다고 믿습니다.
5.3 Feature-based Approach with BERT
지금까지 제시된 모든 BERT 결과는 downstream 작업에서 단순한 분류 레이어를 사전 훈련된 모델에 추가하고 모든 매개 변수를 동시에 fine-tuning하는 fine-tuning 접근 방식을 사용했습니다. 그러나 사전 훈련된 모델에서 고정된 특징을 추출하는 feature-based 접근 방식은 특정 이점이 있습니다. 첫째, 모든 작업이 Transformer 인코더 아키텍처로 쉽게 표현될 수 있는 것은 아니며, 따라서 작업별 모델 아키텍처가 추가되어야 합니다. 둘째, 비싼 표현을 한 번 사전 계산하고 이 표현 위에 저렴한 모델로 여러 실험을 실행하는 것은 계산상의 이점이 큽니다.
이번 섹션에서는 BERT를 CoNLL-2003 Named Entity Recognition (NER) 작업 (Tjong Kim Sang and De Meulder, 2003)에 적용하여 두 가지 접근 방식을 비교합니다. BERT에 대한 입력에서 우리는 case-preserving WordPiece 모델을 사용하고 데이터에서 제공하는 최대 문서 컨텍스트를 포함합니다. 일반적인 방법에 따라 이를 태깅 작업으로 구성하지만 출력에는 CRF 레이어를 사용하지 않습니다. NER 레이블 세트에 대한 토큰 수준 분류기의 입력으로 첫 번째 하위 토큰의 표현을 사용합니다.
Fine-tuning 접근 방식을 분석하기 위해 BERT의 어떤 매개 변수도 fine-tuning하지 않고 하나 이상의 레이어에서 활성화를 추출하여 feature-based 접근 방식을 적용합니다. 이러한 문맥적 임베딩은 무작위로 초기화된 두 개의 768-차원 BiLSTM 레이어 이전의 입력으로 사용됩니다.
결과는 Table 7에 제시됩니다. BERTLARGE는 최첨단 방법과 경쟁적인 성능을 발휘합니다. 가장 성능이 우수한 방법은 사전 훈련된 Transformer의 상위 네 개의 히든 레이어에서 토큰 표현을 연결한 것이며, 전체 모델을 fine-tuning하는 것과 비교하여 0.3 F1 만큼 뒤쳐집니다. 이는 BERT가 fine-tuning 및 feature-based 접근 방식 모두에 효과적임을 보여줍니다.
결론, Conclusion
최근 언어 모델의 전이 학습을 통한 경험적인 개선 사례는, 깊은 단방향 아키텍처에서도 깊이 있고 무언의 사전 학습이 매우 중요함을 보여주었습니다. 특히, 이러한 결과는 저자들이 제안한 뉴럴 네트워크 모델에 제한된 자원을 가진 작업에 대해서도 적용이 가능하다는 것을 보여줍니다. 이 글의 주요 기여는, 이러한 발전을 양방향 심층 아키텍처에 일반화하는 것입니다. 이를 통해, 동일한 사전 학습 모델이 다양한 자연어 처리 작업을 성공적으로 처리할 수 있게 되었습니다.
