4장 스파크 SQL과 데이터 프레임: 내장 데이터 소스 소개
스파크 SQL과 데이터 프레임이 어떻게 상호 작용하는지 알아보는 장이다.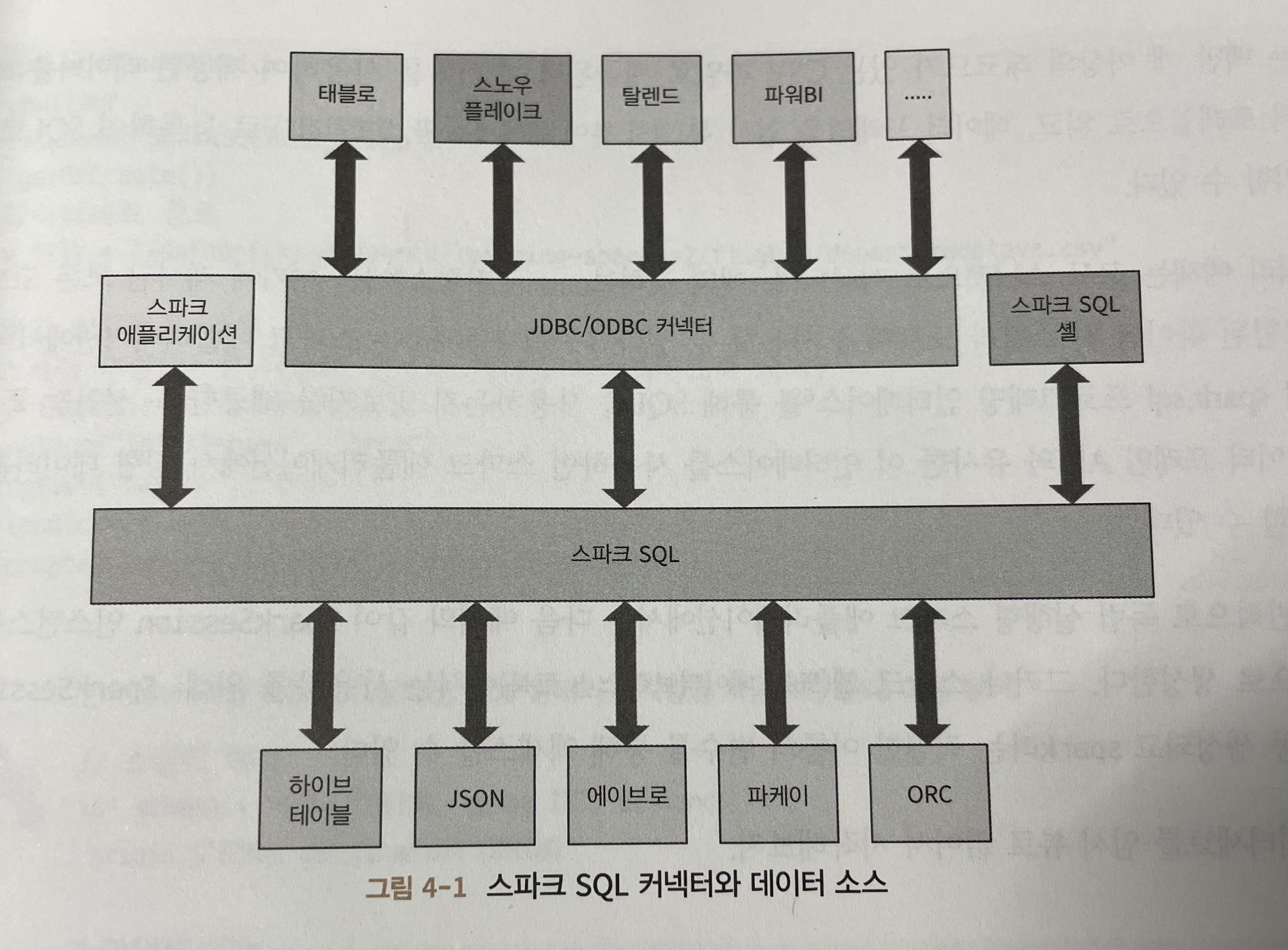
스파크 애플리케이션에서 스파크 SQL 사용하기
SparkSession을 사용하여 쉽게 클래스를 가져오고 코드에서 인스턴스 생성이 가능하다.
SQL 쿼리를 실행하기 위해선 SparkSession 인스턴스에서 spark.sql("SELECT * FROM myTableName")과 같은 sql() 함수를 사용한다.
이러한 방식으로 실행된 모든 spark.sql 쿼리는 원하는 경우 추가 스파크 작업을 수행할 수 있도록 데이터 프레임을 반환한다.
SQL 테이블과 뷰
스파크는 스파크 테이블만을 위한 별도 메타스토어를 생성하지 않고 기본적으로는 /user/hive/warehouse에 있는 아파치 하이브 메타스토어를 사용하여 테이블에 대한 메타데이터를 유지한다.
스파크 구성 변수 spark.sql.warehouse.dir을 로컬 또는 외부 분산 저장소로 설정하여 다른 위치로 기본 경로를 변경할 수 있다.
관리형 데이블과 비관리형 테이블
스파크는 관리형과 비관리형이라는 두 가지 유형의 테이블을 만들 수 있다.
-
관리형 테이블 : 스파크가 메타데이터와 파일 저장소의 데이터를 모두 관리한다. (로컬 파일 시스템, HDFS, Amazon S3, Azure Blob)과 같은 객체 저장소일 수도 있다.
-
비관리형 테이블 : 스파크가 메타데이터만 관리하고 카산드라와 같은 외부 데이터 소스에서 데이터를 직접 관리한다.
실습 코드는 나중에 올리겠습니다...

Learning bunch, mostly computer and language