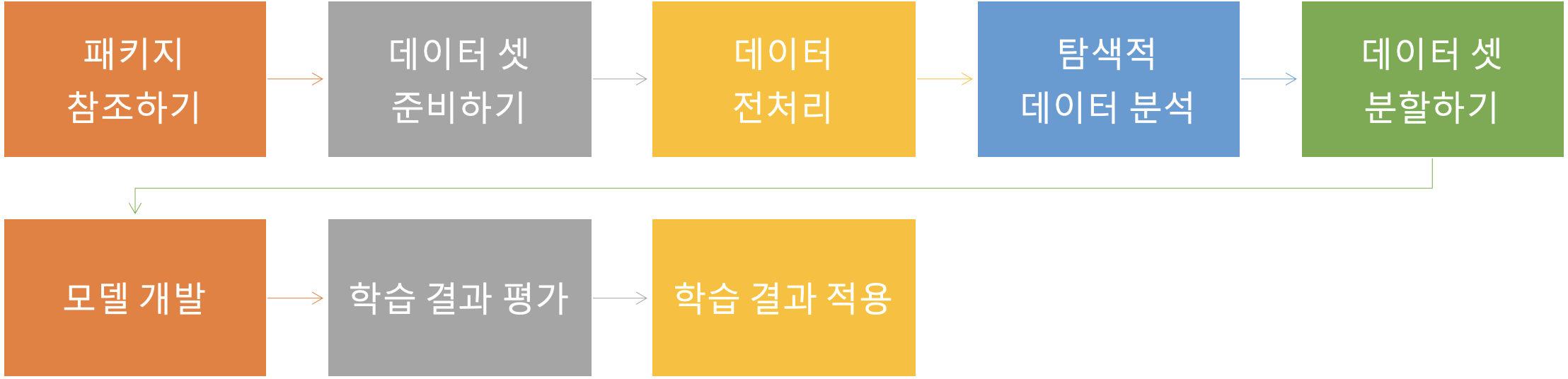
Tensorflow 지도학습 구성
| 구분 | 모델 | 활성화 함수 | 옵티마이저 | 손실함수 | 평가지표 | 대표예제 |
|---|---|---|---|---|---|---|
| 논리연산 | 단층퍼셉트론 | linear | SGD | mse | acc | OR, AND Gate |
| 논리연산 | 다층퍼셉트론 | relu, sigmoid | RMSprop | mse | acc | XOR Gate |
| 회귀 | 단순선형회귀 | relu, linear | adam | mse | mae | |
| 회귀 | 다중선형회귀 | relu, relu, linear | adam | mse | mae | 보스턴 집값 예측 |
| 분류 | 이항분류(로지스틱 회귀) | [relu,] sigmoid | rmsporp | binary_crossentropy | acc | 타이타닉 생존률 예측 |
| 분류 | 다항분류(소프트맥스 회귀) | [relu, ...] softmax | adam 혹은 rmsprop | categorical_crossentropy | acc | iris 분류 |
통계는 데이터의 경향을 설명, 머신러닝은 미래의 값을 예측하는 것이 목적
Tensorflow를 사용한 회귀분석
- 시각화 및 연산
matplotlib, seaborn, numpy
Tensorflow 단순 선형 회귀 (학습성능개선)
텐서플로우의 학습성능을 개선하기 위해 아래의 기능을 사용할 수 있음
- 데이터 표준화 : 학습률 향상에 도움을 줌
- 콜백함수 : 모델의 학습 방향, 저장 시점, 학습 정지 시점 등에 관한 상황을 모니터링 하기 위한 도구
데이터 정규화(Normalization, 표준화)
1) 데이터 정규화의 이해
데이터 정규화란?
모든 데이터가 동일한 정도의 스케일(중요도)로 반영되도록 해 주는 처리
정규화를 해야 하는 이유
머신러닝 알고리즘은 데이터가 가진 feature(특성)들을 비교하여 데이터의 패턴을 찾는다.
이 때, 데이터가 가진 feature의 스케일이 심하게 차이가 나는 경우 수많은 학습 단계를 거쳐서 최적값에 도달하게 된다.
데이터에 정규화 처리를 적용하면 쉽게 최적값에 도달할 수 있으며 학습률을 상대적으로 높여서 사용할 수 있기 때문에 빠르게 훈련시킬 수 있다.
성능과 속도 개선을 위해 표준화를 진행
2) 데이터 정규화 방법
주로 standardscaler을 사용(상황에 따라서 더 좋은 패키지를 선택)
standardscaler은 범위가 아닌 분산 조정
minmax는 범위 조정
최소-최대 정규화 (Min-Max Normalization)
모든 feature에 대해 각각의 최소값 0, 최대값 1로, 그리고 다른 값들은 0과 1 사이의 값으로 변환.
예를 들어 어떤 특성의 최소값이 20이고 최대값이 40인 경우, 30이라는 데이터가 있을 경우,
20은 0, 40은 1로 환산되기 때문에 30은 중간치인 0.5로 변환됨.
표준화를 거치면
numpy배열 형태로 객체가 변경(1차원 배열) -> [0]로 열 길이 출력 가능
표준화를 진행하지 않으면DataFrame 형태(2차원 형태) -> iloc[0]로 열 길이 출력 가능
콜백함수
모델의 학습 방향, 저장 시점, 학습 정지 시점 등에 관한 상황을 모니터링하기 위한 도구
콜백함수 사용 방법
콜백 정의
callbacks = [ 콜백1, 콜백2, ... 콜백n ]학습을 위한 fit() 함수에서 callbacks 파라미터에 미리 정의한 리스트를 지정
callbacks = [콜백1, 콜백2, ... , 콜백n]
model.fit(x_train, y_train, validation_data = (x_val, y_val), epochs = 500, callbacks = callbacks)혹은
model.fit(x_train, y_train, validation_data = (x_val, y_val), epochs = 500, callbacks = [
콜백1, 콜백2, ... , 콜백n
])콜백함수 종류
1) EarlyStopping()
모델 학습 시에 지정된 기간 동안 모니터링하는 평가지표에서 더 이상 성능 향상이 일어나지 않은 경우 학습을 스스로 중단
EarlyStopping의 patience를 통해 epochs 제한 - epochs가 쓸데없이 많으면 오차 범위가 증가
EarlyStopping(monitor='평가지표', patience=10, verbose=1)patience: 지정한 수만큼의 기간에서 평가지표의 향상이 일어나지 않을 경우 학습을 중단 (기간이라 함은 에폭을 의미)
예를 들어 patience=10일 때,10에폭 동안 성능 향상이 일어나지 않으면 학습을 중단. 즉, 10회 이상 성능향상이 발견되지 않으면 중단함verbose: 콜백의 수행 과정 노출 여부를 지정.- 0: 아무런 표시 하지 않음(기본값)
- 1: 프로그래스바로 표시
- 2: 매 에폭마다 수행과정을 자세하게 출력함.
2) ReduceLROnPlateau()
EarlyStopping 콜백과 같이 patience 인자를 지정하여, 지정된 기간 동안 평가지표에서 성능 향상이 일어나지 않으면 학습률을 조정하는 콜백
ReduceLROnPlateau(monitor='평가지표', factor=0.1, patience=10, min_lr=0, verbose=1)factor: 학습률 조정에 사용되는 값 (새로운 학습률 = factor * 기존 학습률)- patience: 지정한 수만큼의 기간에서 성능 향상이 일어나지 않을 경우, 학습률을 조정
min_lr: 학습률의 하한을 지정verbose: 콜백의 수행 과정 노출 여부를 지정.
3) ModelCheckpoint()
지정한 평가지표를 기준으로 가장 뛰어난 성능을 보여주는 모델을 저장 할 때 사용
ModelCheckpoint(filepath, monitor='평가지표', verbose=1, save_best_only=True|False, save_weights_only=False)filepath: 모델의 저장 경로를 지정save_best_only: True인 경우, 가장 성능이 뛰어난 모델만 저장. 그보다 좋지 않은 모델의 경우는 덮어쓰지 않는다.save_weights_only: 모델의 가중치만 저장
